最初に
最近なにかと話題のレイトレーシング。下手するとリアルタイムグラフィックスよりも簡単にフォトリアリスティックな画を出すことができます。
しかし、CPUでぶん回そうとすると処理が重い。重すぎる。そこでGPUですぜ。GPGPUですぜ。
ということで、レイトレーシング超初心者かつCUDA超初心者がをレイトレーシングをCUDAで実装してみた話を簡単にまとめてみました。
ここでは、レイトレーシングの詳細は説明しません。あくまでも、CUDAで実装してみたときにどんなことしたのかを説明するだけです。
あと、書いてみて見返すとそれほどCUDAに特化した内容ではないですが、苦労話だと思って読んでもらえれば幸いです。
レイトレーシングもCUDAも超初心者なので、間違いも多数あると思いますので、気づいた方は優しく教えてくれると次へのモチベーションになります。
なぜにCUDA
NVIDIAのGPUしか手元になかったからです・・・。
NVIDIAのGPUだとOpenCLのデバッグができないので・・・。
ComputeShaderでもいいのでは?という声もありそうですが、nVidiaはバグなのかわざとなのかGeForceではNsight上ですらShaderのデバッグができないようになっています。
ということで、デバッグしようとしたら、CUDA一択となりました・・・。
まずはCPU
まずはCPUで実装しました。いきなりCUDAで実装はハードルが高すぎです。GPGPUとか言っておいて、CPUとはどういうことか、とお叱りを受けそうですが、無理です・・・。
世の中いきなりCUDAで実装できるぜ、という人もいるかもしれませんが私には無理でした・・・。
まずはCPUで実装して、それをベースにCUDAに移植?する形をとりました。
これが意外に後で助かりました。というのも、CUDAで挙動が怪しいときにまずはCPUで確実に動くものと比較できるので、デバッグがしやすかったです。
何が大変だった
CPU実装ができたあとは、ある程度コード共通化してしまえば、CUDAで動かすまでは意外に簡単でした。
が、ここからが大変でした。
とにかく性能が思ったほどでない・・・。拙作プログラムだと最初のCUDA移行後でCPUの約4倍くらいしか速くならなかったのです・・・。
さすがにこれは期待外れもいいところ。ということで、ここからが本番で、最適化がとにかく大変でした。
最適化
じつは、レイトレーシングアルゴリズム自体はあまり変更していません。
もちろん、レイトレーシングの実装の最適化も必要なのですが、CPU比で4倍しか速くなっていないので
レイトレーシングの実装よりもGPGPUならではの問題の方が大きいと考えたからです。
ここからは、私が何をしたのかを書いていきます。
うまくいったものもあれば、うまくいかなかったものもあります。
うまくいかなかったものは私の実装の問題だったりするので、単純にダメな手法というわけではありません。
どのような方法があるのかという参考になると思うので、トライした方法を挙げておこうと思います。
グローバルメモリへのアクセス
最初の実装では、レイの方向、ヒット結果など情報を管理する構造体にいろいろなデータを詰め込み、それをピクセルごとに保持する配列をグローバルメモリに確保して、カーネル間で取り回していました。
あるとき、無駄なパラメータがあるのに気づき、削除したところ、速度が改善しました。構造体のサイズが大きいため、キャッシュを外すためなのか、原因はよくわかっていません・・・。
グローバルメモリへのアクセスはコストが大きいので、できるだけ小さいサイズかつ少ない回数のアクセスにしたほうが効いてきました。
さらにアラインメントも考えるべきなのですが、そこまでは手を付けていません・・・。
テクスチャメモリ
CUDA最適化では鉄板ネタではないでしょうか。しかし、私の場合は思ったほど速度は改善しませんでした・・・。
メガカーネル
そのまま巨大なカーネルです。VRayで有名なChaosGroup様もMega Kernelいいよと言っていますし(場合によるらしいですが・・・)、最初はカーネルを分けていたのですが、くっつけてみました。しかし、これも私の場合はほとんど変化がなかったです・・・。
追記
論文名を失念してしまったので、出典元不明で申し訳ないのですが、メガカーネルにするよりはカーネルはある程度分割したほうがいいらしいです。上記でVRayでもメガカーネルしているよ、と書いていますが、メガカーネルと分割したカーネルと両方を用意して、状況により使い分けているらしいです。
Stream compaction
AMD RadeonRay SDK でもやってます。シーンにもよりますが、屋外のシーンだとだいぶ効いてきます。
ヒットしたレイのインデックスだけをまとめてカーネル呼び出しすることができるようになります。
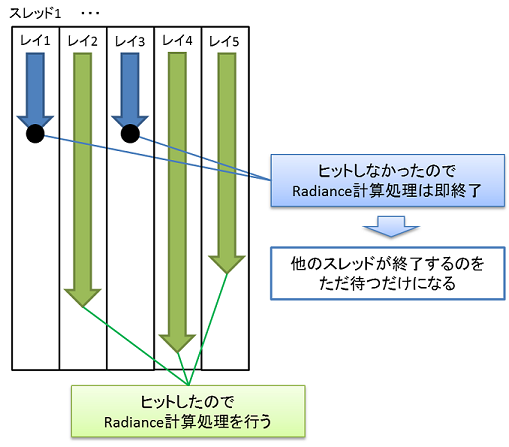
上の図は各スレッドでレイトレーシングの処理を実行したときの概念図ですが、
レイレーシングに限らず、すべてのスレッドが必ず同時に終了するわけではないので、スレッドによっては早々と処理が終了し、ただ待つだけになってしまいます。
CUDAの場合はワープ単位で処理が行われるので、できるだけ処理が行われないスレッドはまとまっていた方が効率的となります。
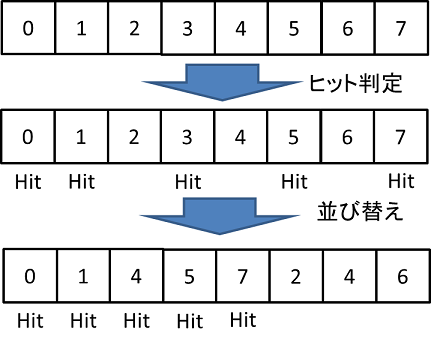
そこで、まず各ピクセルについてレイのヒット判定を行います。そして、配列を並び替えてヒットしたピクセルのインデックスだけをまとめます。あとは、このインデックスの配列を参照して処理するピクセルを選び、処理を行います。
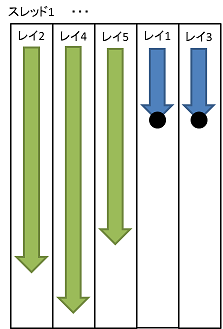
そうすることで、下の図のように処理がまとまって行われるようになります。
詳細は、GPU Gems 3 Chapter 39. Parallel Prefix Sum (Scan) with CUDAを読んでいただくのがいいかと思います。
Persistent Thread
そのまま永久スレッドという意味です。通常、レイトレーシングのCUDA実装だと1ピクセル(or レイ)の処理を1スレッドに割り当てる実装、つまり、カーネル内では1ピクセル(or レイ)の処理が終わったらカーネルも終了するような実装になると思います。ただ、それだとピクセル(or レイ)によっては処理が速く終了してスレッドの処理に偏りがでるかもしれません。そこで、ピクセル(or レイ)の処理が終わってもカーネルを終了させず、次のピクセルを処理するようにします。
例えば、単純なスレッドの実装ですと、各スレッドが分散された処理を実行して終了となりますが、もう一歩進んだ実装ですと、処理が終了したら、次の処理待ちデータを取得して、引き続き処理を行います。つまり、すべてのデータが処理されるまでスレッドが永続的に生存し続けることになります。
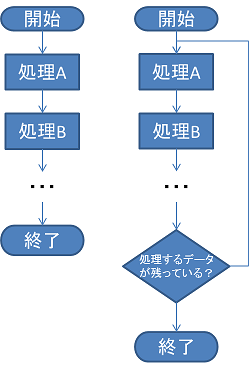
これと同じことをGPGPUでやろう、ということになります。概念的には下の図のようになります。
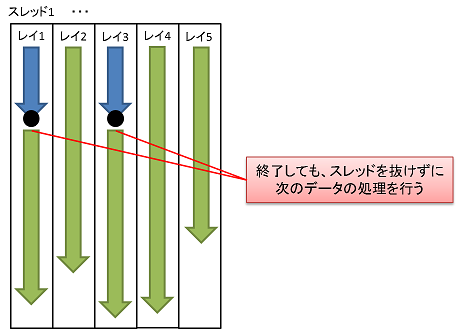
ただ、これも私の場合はあまり効果がありませんでした・・・。
実装はこちらを参考にしました。
概念的には、Path Regenerationに近いのかもしれません。
Divergent
分岐です。GPUは分岐に弱いので(この言い方だと語弊がありそうですが・・・)分岐がないに越したことはありません。しかし、レイトレーシングの実装で分岐を完全になくすのは(私には)難しく、また、Nsightで測定したところ、劇的に問題になっている分岐もなさそうだったので、簡単に削れそうな分岐処理以外はとくに最適化していません。
Woop Triangle Intersection
有名(多分)な手法らしいです。これもほとんど効果が出ませんでした・・・。しかも、ある処理のときに正しく動作しないという謎のバグが発生したため、オフってます・・・。
詳細は、Watertight Ray/Triangle Intersectionを読んでください。
アルゴリズムは完全に理解できていません・・・。ただ、コードが載っているので、実装は難しくないです。
Threaded BVH
超有名なHachisuka先生が提案された手法です。最初はスタックレスBVHを実装していたのですが、レジスタ数が多くなり、それが問題かな、と思い、違う方法を調べていたところでたどり着きました。シンプルな方法でそんなに大きな変更もなく導入できそうだったので採用しました。多少効果がありました。
より進んだMultiple-threaded BVHというものも提案されているのですが、私はそこまでやっていません。
詳細は、Implementing a practical rendering system using GLSLを読んでください。
インライン化
と、ここまでいろいろ言ってきましたが、これが一番効きました。
あるとき、ふとコードを1つのファイルにまとめて、ある関数をインライン化してみました。速くなりました。しかも、かなり。記憶があいまいですが、30msが25msになるくらい速くなりました。
正直、インライン化するだけでなぜにここまで速くなるのか理由がわかっていません・・・。関数コール時のスタックのpush、popの処理が重いのか・・・。本当はちゃんと調べるべきですが、まだ調べていません・・・。教えて偉い人。
最後に
というわけで、ここまでいろいろやってきて、図のシーン(1spp 512x512, 1sppなのでノイズがすごいですが・・・)でCPU(Core i7-6700 3.4GHz)で約650ms、CUDA(GeForce GTX 1080)で約17msとなりました。CUDA実装により約38倍高速化できました(といっても、CPU実装はOpenMP対応はしていますが、SIMD化などのごりごりの最適化はしていません・・・)。
最初は、CUDA実装でもたしか100ms近くかかっていたので、そこからでも6倍近く最適化しています。
シーンに依存するので、なんでもかんでも38倍とはいきませんが、だいぶ速くなっていると思います。これでリアルタイム化も夢ではない?
素直にOptiXでも使え、と言われそうではありますが・・・。
