はじめに
自然言語処理って何なのか。どういう風に使えるのか、解説します。
自然言語処理って?
自然言語処理は、
コンピューターに人が日常的に使っている言葉(=自然言語)を理解してもらうために、
日本語を分解し、構造化し、ラベルを付与し、データセットとしてインプットする、
そのための技術です。
ではどのように分解するのでしょうか?
多くの自然言語処理では、以下の手順で解析を行っています。
- ①形態素解析
- 単語単位に分解し、品詞ラベルを付与する ②係り受け解析
- 文節間の関係性を分析
- ③意味解析
- 述語に対する他の文節の、意味的な役割をラベリング
これらは、自然言語を処理しやすくするための基本的な処理で、まとめて「構文解析」と呼ばれます。
それぞれどんな解析しているの?
ここでは、①~③の解析内容を具体的に説明します。
①形態素解析
形態素解析では、単語単位に分解し、品詞ラベルを付与します。
まずは、日本語の文章を「単語のひとかたまり」に分解します。
英語などと異なり、日本語は一続きの文章で、どこに区切りがあるかわかりません。
日本語の最小単位(=形態素)に分解することから解析がはじまります。
たとえば、
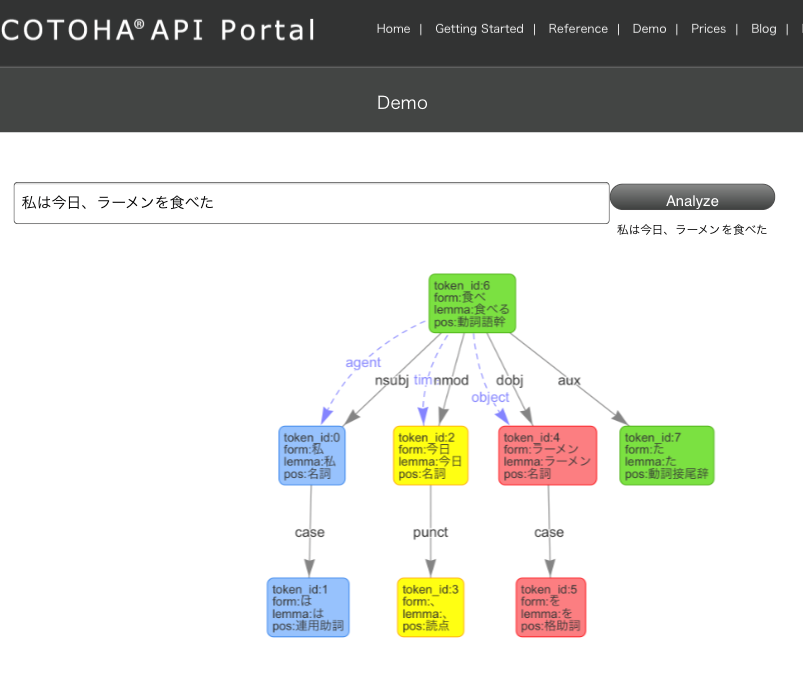
「私は今日、ラーメンを食べた」という文章は以下の形態素で分解されます。
私 / は / 今日 / 、 / ラーメン / を / 食べ / た
加えて、各形態素の品詞情報を付与します。
- 「私」→名詞
- 「は」→連用助詞
- 「今日」→名詞
- 「、」→読点
- 「ラーメン」→名詞
- 「を」→格助詞
- 「食べ」→動詞語幹
- 「た」→動詞接尾辞
結果として、こんなラベリングをします↓
私 / は / 今日 / 、 / ラーメン / を / 食べ / た
名詞 連用助詞 名詞 読点 名詞 格助詞 動詞語幹 動詞接尾辞
※品詞分類例としては、COTOHA APIの「品詞一覧」をご参考ください。
②係り受け解析
次に解析するのは、**文節同士の関係性(=係り受け)**です。
ここでは「**意味をなす最小単位」である文節がどの文節と係っているのか、「関係性の有無」**を解析します。
「私/は/今日/、/ラーメン/を/食べ/た」を文節にまとめると、
私 は 今日 、 ラーメン を 食べ た
_____________ _____________ _______________ _____________
となります。
この文章の中で係り受け関係があるのは、以下の通りです。
- ①「私は」→「食べた」
- ②「今日、」→「食べた」
- ③「ラーメンを」→「食べた」
私 / は / 今日 / 、 / ラーメン / を / 食べ / た
名詞 連用助詞 名詞 読点 名詞 格助詞 動詞語幹 動詞接尾辞
_____________ _____________ _______________ _____________
| | ③|_______________|
① | ②|_________________________________|
|________________________________________________|
この文節間の係り受け関係の有無(構造)を特定するのが、「係り受け解析」です。
この時点では、各係り受け関係にどのような意味があるのかは特定できていません。
大体の自然言語処理ツールはここまでの処理で、解析結果を出力します。
各係り受け関係の意味的役割を特定し、ラベリングをするのが、次の「意味解析」です。
③意味解析
文節のそれぞれの働きを、主語、述語、修飾語、接続語、独立語と分類するのを習ったことがあると思います。文節の中で「何がどうする」「何がどんなだ」「何がなんだ」といった文章の骨格をなす重要な働きをするのが、主語と述語です。
このうち、「述語」との関係性から各文節との係り受けの意味役割をラベリングするのが、意味解析です。
たとえば、
「私は」「食べた」の「私は」は、動作主格(agent)
「今日、」「食べた」の「今日」は、「時間格」(tim)
「ラーメンを」「食べた」の「ラーメンを」は、対象格(object)
というかたちです。
私 / は / 今日 / 、 / ラーメン / を / 食べ / た
名詞 連用助詞 名詞 読点 名詞 格助詞 動詞語幹 動詞接尾辞
_____________ _____________ _______________ _____________
| | ③object|_______________|
① | ②tim|_________________________________|
agent|________________________________________________|
※COTOHA APIの場合のラベリングは、「[意味関係ラベル一覧] (https://api.ce-cotoha.com/contents/reference-detail.html#link-list)」をご参考ください。
このような①~③の解析を実施することで、文章を構造的に処理することができます。
解析結果は以下の通りです。
■解析イメージ
なお、今回はCOTOHA APIで解析しました。
タグづけや解析結果は、各自然言語処理により異なります。
これからの章立て
自然言語処理について、引き続き解説していきます。
(予定の章立て)
・自然言語処理APIにはどんなAPIがあるか
・自然言語処理でどんなことができるか