この記事は株式会社ネクスト(Lifull) Advent Calendar 2016の6日目です。
本投稿では全文検索エンジンElasticsearchのフルマネージドサービスAWS Elasticsearch Serviceを使って海外用物件検索サイトで地域情報を検索できるようにした際の手順を書きます。
この記事を読むとElasticsearchのanalyzer, mapping, tokenizer, token filter(N-gramで解析する場合)のこと、フィルタークエリ(Filtered query)での検索方法、AWS Elasticsearch Serviceでのアクセス制御やクラスタの立ち上げから検索できるようになるまでが理解できると思います。
Elasticsearchを使い始める人の参考になれば幸いです。
要件
- 地域名の部分一致で検索したい
- ポストコード(郵便番号)でも検索したい
- 4階層になっている地域データを横断的に検索したい
- 4階層とは下記のようなイメージです(例:”千葉”と検索すると千葉県と千葉市がヒットする)
- 北海道地方、東北地方、関東地方...
- 東京、埼玉、神奈川、千葉...
- 港区、品川区...
- 港南、芝浦、白金...
今回の設定では1階層目をregion1, 2階層目をregion2と呼び、以下region3, region4
- 4階層とは下記のようなイメージです(例:”千葉”と検索すると千葉県と千葉市がヒットする)
- 's', syd', 'y', 'dny'で検索しても'Sydney'という地域名がヒットする
まずはクラスタを作成
http://docs.aws.amazon.com/ja_jp/elasticsearch-service/latest/developerguide/es-createupdatedomains.html
作成方法は上記のドキュメントを参照して下さい。
やってみるとわかるのですが、わずか数ステップでElasticsearchのクラスタが立ち上がり、エンドポイントやアクセス制限まで提供してくれます。簡単!
また、Elasticsearch Serviceでは一緒にKibanaのEndpointも提供してくれます。
アクセスポリシーの設定
今回は参照元のEC2インスタンスのIAM Roleと、データ投入や管理用のリクエストを送るためのネットワークのIPアドレスを許可しました。
※IPアドレスやロール名、ドメインなどは適当に書き換えています
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::123456789012:role/HOGE"
},
"Action": "es:*",
"Resource": "arn:aws:es:ap-southeast-1:123456789012:domain/sample-domain/*"
},
{
"Sid": "",
"Effect": "Allow",
"Principal": {
"AWS": "*"
},
"Action": "es:*",
"Resource": "arn:aws:es:ap-southeast-1:123456789012:domain/sample-domain/*",
"Condition": {
"IpAddress": {
"aws:SourceIp": "123.456.789.012/32"
}
}
}
]
}
許可したIPを持つマシンからアクセスを確認します
$ curl https://search-sample-domain-xxxxxxxxx.ap-southeast-1.es.amazonaws.com
{
"name" : "Clive",
"cluster_name" : "xxxxxxxxx:sample-domain",
"version" : {
"number" : "2.3.2",
"build_hash" : "0944b4bae2d0f7a126e92b6133caf1651ae316cc",
"build_timestamp" : "2016-05-20T07:46:04Z",
"build_snapshot" : false,
"lucene_version" : "5.5.0"
},
"tagline" : "You Know, for Search"
}
GETリクエストに成功すると上記のようなレスポンスが返ってきます。確かにElasticserachが使えるようになっています。
index, type, document
ここで用語の整理をしておきます。
Elasticsearch にはindex, type, documentというデータの単位があります。
この記事の執筆時点での公式ドキュメントがこちら。
日本語の記事は
http://dev.classmethod.jp/cloud/aws/use-elasticsearch-4-data-structure/
がわかりやすいかと思います。
入門者はRDBになぞらえて、indexはスキーマ, typeはテーブル, documentはレコードのように考えればイメージしやすいと思います。
今回は、indexをregion、typeをregion1, region2, region3, region4のように定義しました。
また、レコードは下記のようにしました。
{"name":"Australian Capital Territory","short_name":"ACT","zip":null,"country_id":36}
持っているフィールドは下記です
| フィールド名 | 意味 |
|---|---|
| name | 地域名 |
| short_name | 地域名の略称 |
| zip | 郵便番号 |
| country_id | 国コード |
別の国でも同じ機能を使えるように国コードを入れました。
国別にindexを作るかフィールドとしてcountry_idを定義するか悩んだのですが、どのようなクエリが頻繁に来るのかやこの先どのような使い方をするのかを考えると今の状態が良いと考えました。
この辺のことはまた別の機会にまとめたいと思います。
アナライザーの定義
Elasticsearchはドキュメントを登録するときに各フィールドの文字列をフィルタリングしたり分解したり分解したテキストに処理をしたりして、登録されたドキュメントを検索可能にします。
具体的には、Analyzerという機能を使ってドキュメントをインデックスする際にドキュメントの各フィールドの文字列を解析して検索できるようにします。ですが、デフォルトの解析方法(Standard Analyzer)だと単語の単位でしかマッチしてくれないため、"sydney"まで入力しないと"sydney"にマッチしません。ブログの記事やEメールの受信ボックスを検索する等であればこれでもいいかもしれませんが今回はデフォルトだと要件が満たせませんでした。なので、アナライザーの設定をいじります。
以下の図は受け取った各フィールドのデータをAnalyzerがどのように処理しているかを表した図です。
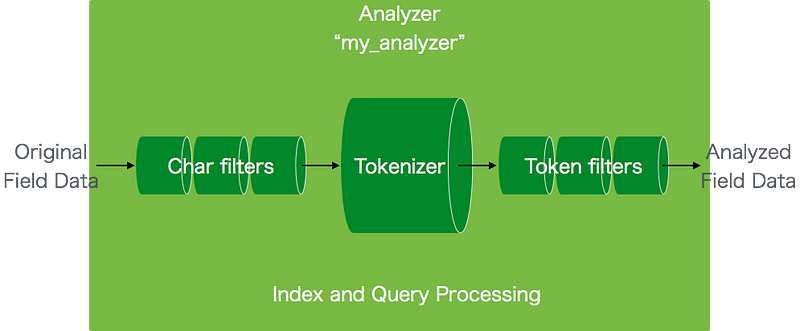
引用元:http://qiita.com/magaya0403/items/1c5976c6af2a0c04a905#analyzer%E3%81%A8%E3%81%AF
上記の図を説明すると下記のようなステップで処理しています。
- 受け取ったテキストをフィルタリング(Char filtersのところ)
HTML文章からHTMLタグを除去するなど - 1.から受け取ったテキストを解析(Tokenizerのところ)
空白区切りで単語に切り分ける、形態素解析するなど - 切り分けられた文字列たちにフィルターをかける(Token filtersのところ)
英字を小文字にする、不要なトークンを削除するなど
今回の要件を満たすためにはToken filtersで文字をN-gramを用いて分解するのと英字を小文字にする必要がありました。
その際のアナライザーをJSONで定義しました。
{
"settings": {
"analysis": {
"filter": {
"suggest_filter": {
"type": "ngram",
"min_gram": 1,
"max_gram": 20
}
},
"analyzer": {
"suggest": {
"type": "custom",
"tokenizer": "standard",
"filter": [
"lowercase",
"suggest_filter"
]
}
}
}
}
}
suggest_filterという名前のフィルターと、suggestという名前のアナライザーを定義しています。
suggestの定義ではToken filterにlowercaseとsuggest_filterの2つを使っています。
lowercaseは英字を小文字にするもの。suggest_filterはN-gramを用いて1文字〜20文字それぞれの文字数で単語を分割するように設定しています。
analyzerをElasticserachに登録する
ElasticseachのAPIで登録できます。
curl -XPUT '{host}/regions' --data-binary @regions_analyzer.json
これだけ:)
マッピングを定義する
アナライザーをElasticsearchに登録しただけではどのドキュメントのどのフィールドに設定を反映するのかという情報が足りません。
そこで先程定義したアナライザーを各Type(region1, region2, ...)に登録していきます。
公式ドキュメントを参照したい方はこの記事の執筆時点でのものがこちら
日本語のマッピングの説明はこちらの記事がわかりやすいかと思います。
https://medium.com/hello-elasticsearch/elasticsearch-9a8743746467#.g0hf0rxac
Elasticsearch におけるマッピングとは、リレーショナルDBでいうところのテーブル定義に相当します。しかし、単にデータを格納する為のフィールドを用意して型を設定するだけではありません。Elasticsearch では、フィールドの型の他に言語解析処理などのドキュメントを検索可能にする為の各種設定が可能です。
設定内容を見たほうが早いと思います。上記を踏まえた上でのマッピングの定義は以下のようになります。
{
"region1": {
"properties": {
"name": {
"type": "string",
"analyzer": "suggest",
"search_analyzer": "standard"
},
"short_name": {
"type": "string",
"analyzer": "suggest",
"search_analyzer": "standard"
},
"zip": {
"type": "string",
"analyzer": "suggest",
"search_analyzer": "standard"
}
}
}
}
region1というTypeの各フィールドに対してanalyzerに先程定義したsuggestを使うように定義しています。
これをregion1~4までそれぞれの定義を1ファイルずつに記述しました。
ファイル名はそれぞれregions_mapping1.json, regions_mapping2.json,...としました。
mappingを登録する
これもElasticsearchのAPIで登録できます。
curl -XPUT '{host}/regions/_mapping/region1' --data-binary @regions_mapping1.json
curl -XPUT '{host}/regions/_mapping/region2' --data-binary @regions_mapping2.json
curl -XPUT '{host}/regions/_mapping/region3' --data-binary @regions_mapping3.json
curl -XPUT '{host}/regions/_mapping/region4' --data-binary @regions_mapping4.json
マッピングの定義ファイルが存在するディレクトリで実行しました。
ドキュメントを登録する
bulk APIを使います。
https://www.elastic.co/guide/en/elasticsearch/reference/current/docs-bulk.html
これを使うとファイル内に定義した2つ以上のドキュメントを一度に登録できます。まず登録するドキュメントを含むファイルを作成します。
{"index":{"_index":"regions","_type":"region1","_id":361000001}}
{"name":"Australian Capital Territory","short_name":"ACT","zip":null,"country_id":36}
{"index":{"_index":"regions","_type":"region1","_id":361000002}}
{"name":"New South Wales","short_name":"NSW","zip":null,"country_id":36}
{"index":{"_index":"regions","_type":"region1","_id":361000003}}
{"name":"Northern Territory","short_name":"NT","zip":null,"country_id":36}
{"index":{"_index":"regions","_type":"region1","_id":361000004}}
…
登録先のインデックス、タイプ、ドキュメントのIDのフィールドを持ったJSONオブジェクトとドキュメントの各フィールドの値を定義したJSONオブジェクトの2つがセットになって1つのドキュメントを登録できます。
2つのJSONオブジェクトのペアを羅列しているだけのファイルです。
これをregion1~4に対してそれぞれ1ファイルずつ作りました。
JSONオブジェクトを羅列しているので正確にはJSONファイルじゃないですね。
APIを使って登録するときは下記のようなリクエストをします。
curl -s -XPOST {host}/_bulk --data-binary @es_region1.json
curl -s -XPOST {host}/_bulk --data-binary @es_region2.json
curl -s -XPOST {host}/_bulk --data-binary @es_region3.json
curl -s -XPOST {host}/_bulk --data-binary @es_region4.json
もちろん1つのファイルに全てのタイプのドキュメントが入っていればリクエストは1回ですみます。
データ作成の都合上ファイルを分けました。
これで登録完了です。
ここまでで
各種設定と、ドキュメントの登録が完了したのでやっと要件を満たす検索ができるようになりました。
検索する
'dne'という文字列で検索してレスポンスを確認してみましょう。
Filtered queryを使ってクエリを組み立ててcurlコマンドでGETして確認してみます。
https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-filtered-query.html
$ curl -XGET '{host_name}/regions/_search?pretty' -d'
{
"from": 0,
"size": 10,
"query": {
"bool": {
"filter": {
"term": { "country_id": 36 }
},
"must": {
"multi_match": {
"query": "dne",
"fields": ["name", "short_name", "zip"]
}
}
}
}
}'
レスポンスは以下のようになりました。
{
"took" : 20,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 11,
"max_score" : 7.751156,
"hits" : [ {
"_index" : "regions",
"_type" : "region4",
"_id" : "123456789",
"_score" : 7.751156,
"_source" : {
"name" : "Gairdner",
"short_name" : null,
"zip" : "6337",
"country_id" : 36
}
}, {
"_index" : "regions",
"_type" : "region4",
"_id" : "123456789",
"_score" : 6.5205054,
"_source" : {
"name" : "Lardner",
"short_name" : null,
"zip" : "3821",
"country_id" : 36
}
}, {
"_index" : "regions",
"_type" : "region4",
"_id" : "123456789",
"_score" : 6.5205054,
"_source" : {
"name" : "Sydney",
...
確かに検索結果が返ってきました。'dne'にもマッチしていそうです。:)
検索エンジンを0から構築して要件にマッチした検索を行うことができました。実際のプロダクトではAPIを一つ介して上記のクエリを組み立ててリクエストを投げています。
立ち上げが本当にかんたんである程度の管理もAWSに任せることができるので、インフラ専門部隊がいないチームでも運用することができています。ほんとうにありがとうございます。
以上です。