はじめに
本記事の対象者
・WideResNetの精度再現に苦労している方
・ResNetの基本構造を理解している方
対象でない方
・WideResNetの論文の要約が読みたい方
・WideResNetの構造の概略を知りたい方
version等は以下のgithubのREADMEに明記している通り,python3.7と自分のCudaのversionにあったpytorchである.
PytorchによるWideResNetの実装
WideResNetの元論文
コードの説明及び注意点
最高精度
今回は比較的計算時間が短く,精度も良いWRN-28-10のモデルにおいてCIFAR100の識別精度の検証を行った.
4回の実行で最高のテスト精度は81.6%であった.
データの前処理
論文にあるとおり,正規化処理,Random Crop, Horizontal Flipを行っている.また,縁に関しては元のコードではReflectを行っているため,それを再現している.
def get_data(batch_size):
normalize = transforms.Normalize(mean=[0.4914, 0.4824, 0.4467],
std=[0.2471, 0.2435, 0.2616])
transform_train = transforms.Compose([transforms.Pad(4, padding_mode = 'reflect'),
transforms.RandomCrop(32),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize])
transform_test = transforms.Compose([transforms.ToTensor(), normalize])
train_dataset = datasets.CIFAR100(root="cifar",
train=True,
download=True,
transform=transform_train)
test_dataset = datasets.CIFAR100(root="cifar",
train=False,
download=False,
transform=transform_test)
train_data = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=1, pin_memory=True)
test_data = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size, shuffle=False, num_workers=1, pin_memory=True)
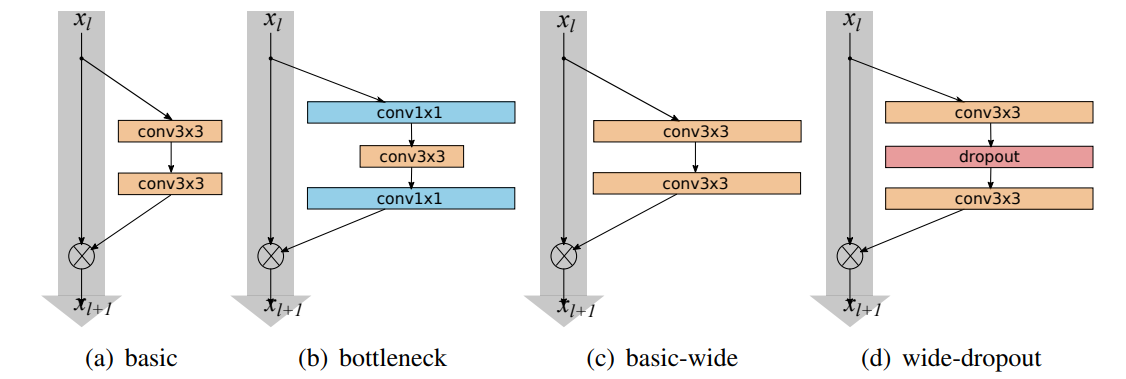
Basic Block
今回の実験では(d) wide-dropoutを用いている.また,元論文にconv-BN-ReLUよりもBN-ReLU-convの方が高速で精度も良いと報告されているため,その構造を使用した.畳み込みにおいてBias項は入れないことに注意.
また,pytorchにおいて注意が必要となるのがDropoutである.Dropout2dとDropoutは全く別物の関数である.前者は確率pで選択されたカーネルの要素が全て0になるのに対して,後者は入力テンソルの要素が確率pで0になる.
さらに,BNとDropoutの順番にも注意が必要でこの順番を逆にしても精度が落ちる.
上記の注意点を間違えるとそれぞれで1%弱程度精度が悪化する.
class BasicBlock(nn.Module):
def __init__(self, in_ch, out_ch, stride=1, drop_rate=0.3, kernel_size=3):
super(BasicBlock, self).__init__()
self.in_is_out = (in_ch == out_ch and stride == 1)
self.drop_rate = drop_rate
self.shortcut = nn.Sequential() if self.in_is_out else nn.Conv2d(in_ch, out_ch, 1, padding=0, stride=stride, bias=False)
self.bn1 = nn.BatchNorm2d(in_ch)
self.c1 = nn.Conv2d(in_ch, out_ch, kernel_size, stride=stride, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_ch)
self.c2 = nn.Conv2d(out_ch, out_ch, kernel_size, padding=1, bias=False)
def forward(self, x):
h = F.relu(self.bn1(x), inplace=True)
h = self.c1(h)
h = F.relu(self.bn2(h), inplace=True)
h = F.dropout(h, p=self.drop_rate, training=self.training)
h = self.c2(h)
return h + self.shortcut(x)
重みの初期化
畳み込み層の重みの初期化に関して.Defaultの初期化関数はmode = 'fan_in',つまり,入力のサイズによって初期化が行われる.一方でWideResNetでは出力のサイズを参照にして初期化を行っているので'fan_out'による初期化が好ましい.
念のためにkaiming_normalの参照を置いておく.Heの正規分布を参照すること.
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out')
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.bias, 0.0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Linear):
nn.init.constant_(m.bias, 0.0)