結論
import java.util.concurrent.atomic.AtomicInteger;
import java.util.function.Consumer;
import java.util.function.Function;
import java.util.stream.Stream;
import org.junit.Test;
public class Test {
/**
* 単一の入力引数とインデックスを受け取って結果を返さない関数
* @param <T> 引数の型
*/
@FunctionalInterface
public interface ConsumerWithIndex<T> {
public void accept(int i, T t);
}
/**
* 1つの引数とインデックスを受け取って結果を生成する関数
* @param <T> 関数の入力の型
* @param <R> 関数の結果の型
*/
@FunctionalInterface
public interface FunctionWithIndex<T, R> {
public R apply(int i, T t);
}
/**
* 各要素をインデックスとともに処理する関数を作成します
* @param <T> オペレーションの入力の型
* @param consumer 関数
* @return 関数
*/
public <T> Consumer<? super T> enumerate(ConsumerWithIndex<? super T> consumer) {
final AtomicInteger ai = new AtomicInteger();
return t -> consumer.accept(ai.getAndIncrement(), t);
}
/**
* 各要素をインデックスとともに処理する関数を作成します
* @param <T> 要素の型
* @param <R> 戻り値の型
* @param function 関数
* @return 関数
*/
public <T, R> Function<? super T, R> enumerate(FunctionWithIndex<? super T, R> function) {
final AtomicInteger ai = new AtomicInteger();
return t -> function.apply(ai.getAndIncrement(), t);
}
@Test
public void test() {
Stream.of("A", "B", "C", "D")
.map(enumerate((i, e) -> {
System.out.println("[Map] " + i + " : " + e);
return e;
}))
.forEach(enumerate((i, e) -> {
System.out.println("[Each] " + i + " : " + e);
}));
}
}
[Map] 0 : A
[Each] 0 : A
[Map] 1 : B
[Each] 1 : B
[Map] 2 : C
[Each] 2 : C
[Map] 3 : D
[Each] 3 : D
はじめに
アドベントカレンダー初日ということで軽めの記事を。
ループ中のインデックスが欲しいことってありますよね?
ロジック上必要になることもあれば、デバッグやログとしてインデックスの情報が欲しいということもあると思います。
しかしJavaのループ処理中でインデックスを取得したくなった場合、PythonのenumerateやJavaScriptのArray#forEach と比べると書き換えのコストが高いです。
# インデックスなし
for hoge in hogeList:
# 処理
# インデックスあり
for i, hoge in enumerate(hogeList):
# 処理
// インデックスなし
hogeList.forEach(hoge => {
// 処理
});
// インデックスあり
hogeList.forEach((hoge, i) => {
// 処理
});
Javaでも同様に、新たなインターフェースとメソッドを定義することで容易にループ内でインデックスを取得する方法の解説をしたいと思います。
インデックスを得るための書き換えとその問題点
例えば、以下のようなコードがあったとします。
for (Hoge hoge : hogeList) {
// hoge に対しての処理
}
このとき、forの中でインデックスを扱いたい場合、次のように書き換える必要があります
for (int i = 0; i < hogeList.size(); i++) {
Hoge hoge = hogeList.get(i);
// hoge に対しての処理
}
int i = 0;
for (Hoge hoge : hogeList) {
// hoge に対しての処理
i++;
}
-
(1)の書き換えについて
この書き方の問題については多くは語りませんが、せっかく拡張for文が実装されているのに(通常の)for文で書くのはもったいないです。
-
(2)の書き換えについて
こちらは一見問題ないように思えますし、書き換えも比較的容易です。実際、大抵の場合はこの書き方で良いと思います。
しかし問題点もいくつかあります。- カウンタ変数(
i)のスコープがfor文内に収まっていないこと - for文内に
continueがあった場合に、カウントし忘れてカウントがずれる恐れがある
- カウンタ変数(
さらに、Javaにおいてループ処理を書く方法はfor文だけではありません。
Iterable#forEach, Stream#map, Stream#forEach など、引数に関数を受け取るメソッドを利用することも多いです。
その場合は(2)のような書き換えを行うことは難しいです。なぜなら、ラムダ式ではfinalでないローカル変数を参照することができないためです。
int i = 0;
hogeList.forEach(hoge -> {
// hoge に対しての処理
i++; // -> error: local variables referenced from a lambda expression must be final or effectively final
});
一応、ラムダ式を使わずに匿名クラスを用いることで回避は可能ですが、さすがに冗長すぎるのでナシでしょう。
hogeList.forEach(new Consumer<>() {
int i = 0;
@Override
public void accept(Hoge hoge) {
// hoge に対しての処理
i++;
}
});
解決法と解説
基本的には匿名クラスを用いた例を改善することで問題を解決します。「この例は冗長すぎるためナシ」と言いましたが、冗長性を除けばそれ以外の問題点は解決できています。
これを簡潔に書くことでひとまずの解決法とします。
いくつかのステップに分けて解説をしていきます。
関数型インターフェース
冗長性の解決は簡単で、匿名クラスを別メソッドに切ってしまえば良いです。
public <T> Consumer<? super T> enumerate() {
return new Consumer<T>() {
int i = 0;
@Override
public void accept(T t) {
// インデックスと値を使った処理
i++;
}
};
}
さて、この場合// インデックスと値を使った処理←この部分を外部から渡してあげる必要があります。
外部から処理を渡すということは関数を渡してあげれば良いわけで、今回はインデックスと値を使うので、2つの引数をとるような関数を渡せるようにしてあげます。
public <T> Consumer<? super T> enumerate(BiConsumer<Integer, ? super T> consumer) {
return new Consumer<T>() {
int i = 0;
@Override
public void accept(T t) {
consumer.accept(i, t);
i++;
}
};
}
これで次のように処理を書くことができます。
hogeList.forEach(enumerate((i, hoge) -> {
// hoge に対しての処理
}));
これでも問題はないですが、iの型がIntegerであることが気になります。これを回避するために、独自の関数型インターフェースを定義します。
@FunctionalInterface
public interface ConsumerWithIndex<T> {
public void accept(int i, T t);
}
public <T> Consumer<? super T> enumerate(ConsumerWithIndex<? super T> consumer) {
return new Consumer<T>() {
int i = 0;
@Override
public void accept(T t) {
consumer.accept(i++, t);
}
};
}
これでも十分に使えます。Stream#mapなどでも使いたい場合は、最初に示した通り、Functionを返すようなメソッドをオーバーロードしてあげれば良いです。
関数型インターフェースが全くわからないという方は、以前書いたStreamの記事を読んでみてください。これ以外にも「関数型インターフェース」で検索してみると色々な情報や実装例が見つかると思います。
[Java11] Stream まとめ -Streamによるメリット-#関数型インターフェース
AtomicInteger
さて、実は上のコードには問題点があります。それは並列処理を行った場合に起きます。
final Long count = IntStream.range(0, 1_000_000).boxed()
.map(enumerate((i, n) -> {
return i; // インデックスを返す
}))
.distinct().count();
System.out.println(count);
1000000
至極当然の結果ですが、これを並列処理にすると問題が起きます。
final Long count = IntStream.range(0, 1_000_000).boxed()
.parallel() // ← 追加
.map(enumerate((i, n) -> {
return i; // インデックスを返す
}))
.distinct().count();
System.out.println(count);
(1回目) 857839
(2回目) 886604
(3回目) 859839
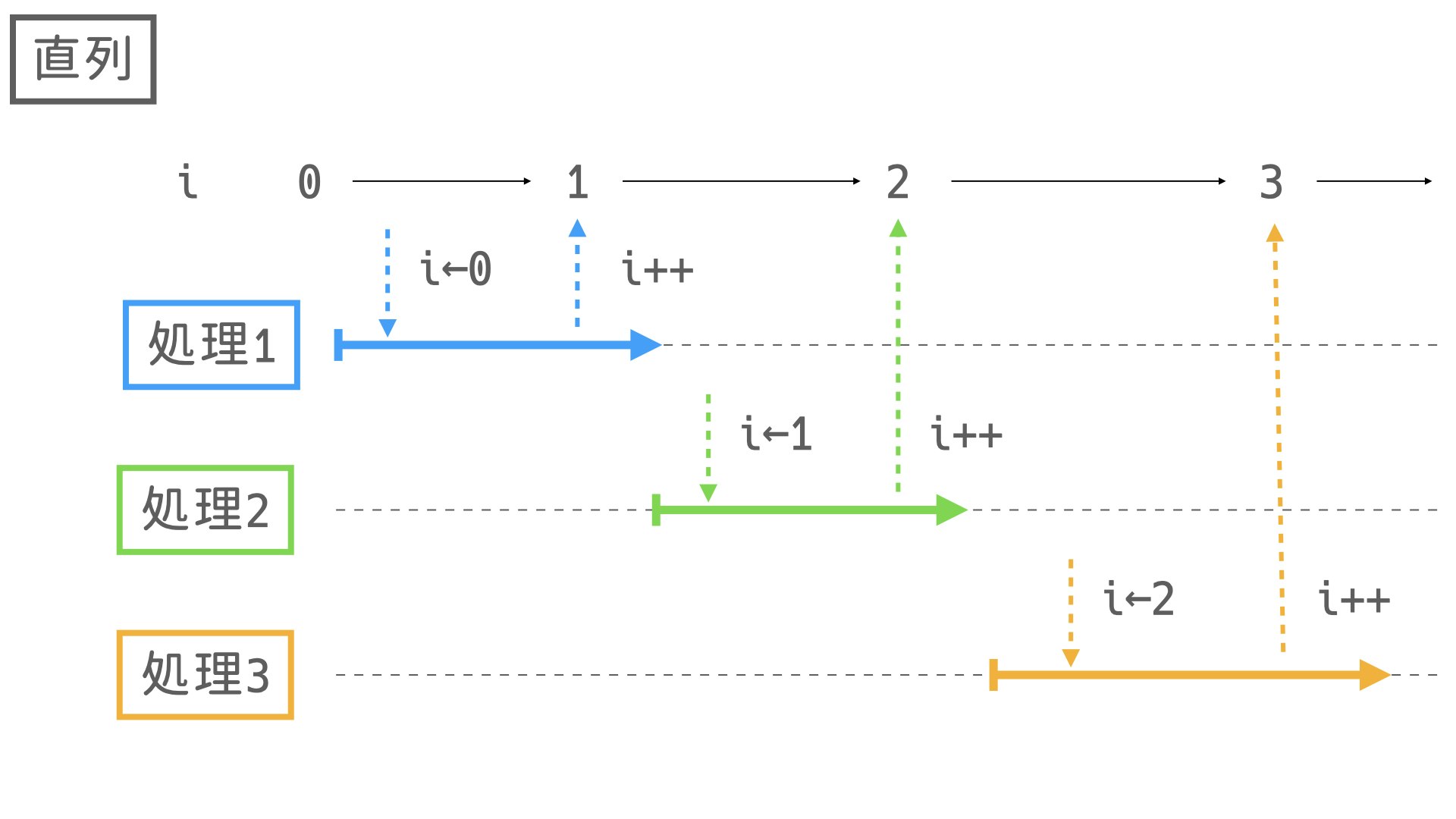
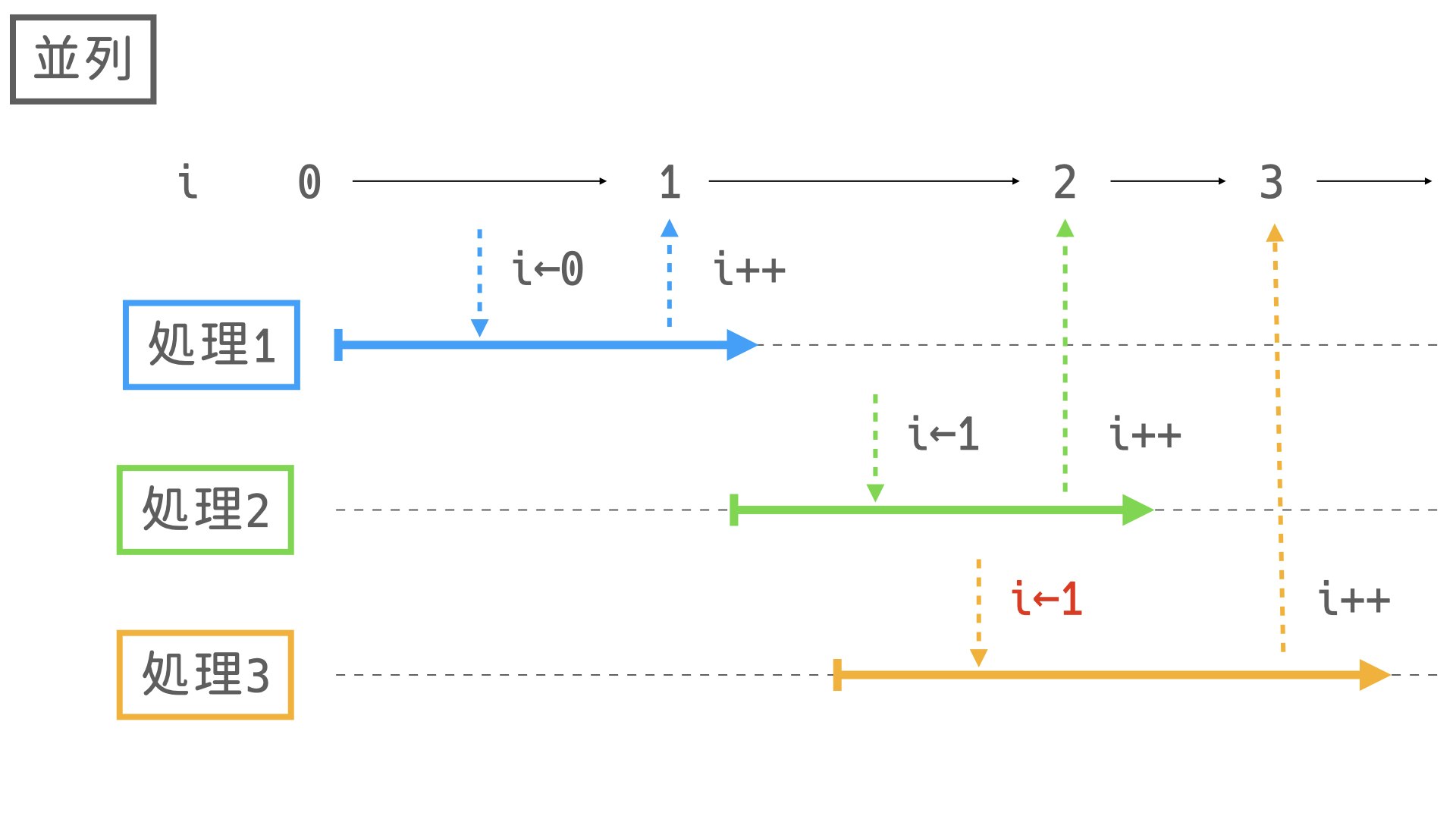
このように実行ごとに値が変わってしまいます。
これは並列処理によって、iの値を取得してからインクリメントするまでに他のスレッドによって書き換えられるために起きます。
イメージしやすいように図を用意しました。
 |
|---|
 |
|---|
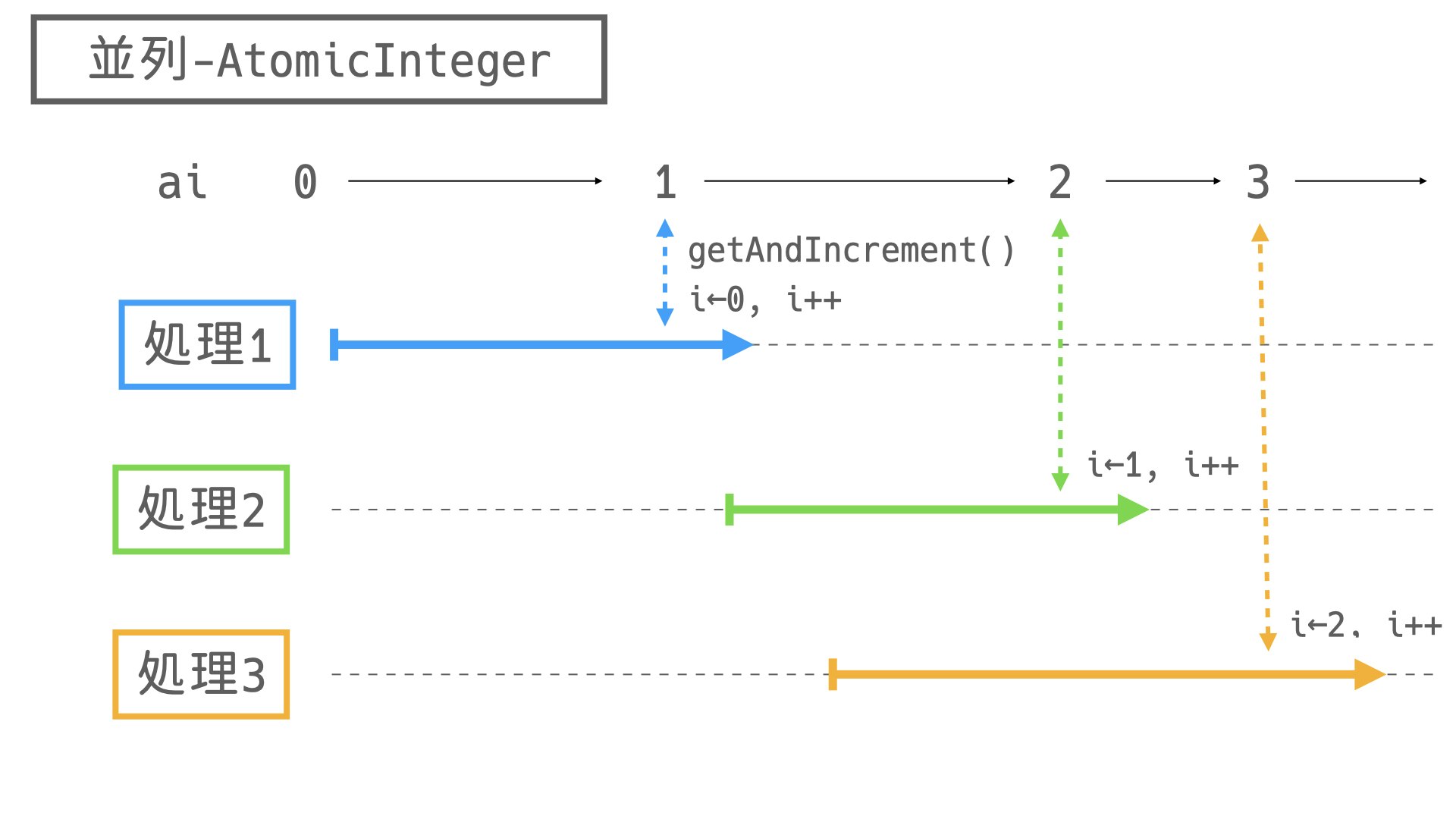
これを回避するためにAtomicIntegerを使用します。
AtomicInteger とは
原子的な更新が可能なint値です。
AtomicInteger (Java Platform SE 8 )
原子的とは「それ以上分解できない」を意味しており、今回のケースでは値の取得とインクリメントの作業が分解不可能であることを意味しています。
これにより「値を取得してからインクリメントするまでに他のスレッドによって書き換えられる」ということが起き得なくなります。
public <T> Consumer<? super T> enumerate(ConsumerWithIndex<? super T> consumer) {
return new Consumer<T>() {
final AtomicInteger ai = new AtomicInteger();
@Override
public void accept(T t) {
consumer.accept(ai.getAndIncrement(), t);
}
};
}
以下が動作のイメージです。
 |
|---|
パフォーマンス
次のコードを実行して、intとAtomicIntegerでのパフォーマンスを比較します。
final long start = System.currentTimeMillis();
for (int c = 0; c < N; c++) {
final Long total = IntStream.range(0, 1_000_000).boxed()
.map(enumerate((i, n) -> {
return i; // インデックスを返す
}))
.collect(Collectors.summingLong(i -> i));
}
final long end = System.currentTimeMillis();
System.out.println((end - start) + "ms");
| 計測結果 | N=100 | N=1,000 | N=10,000 |
|---|---|---|---|
| int | 1029ms | 7125ms | 68216ms |
| AtomicInteger | 1409ms | 10758ms | 100178ms |
AtomicIntegerが1.5倍遅いという結果になりました。
そもそもインデックスを扱う場面で並列処理をやりたいことってなくね?というツッコミはさておきこれで並列処理でも問題なく動くようになりました。
動作確認に数百件に1回だけ何か出力するとかの限られたケースでは使えるかもしれない。
クロージャ
先の修正でカウンタ変数(ai)がfinalな変数になりました。つまりラムダ式で書き換え可能になりました。
public <T> Consumer<? super T> enumerate(ConsumerWithIndex<? super T> consumer) {
final AtomicInteger ai = new AtomicInteger();
return t -> consumer.accept(ai.getAndIncrement(), t);
}
クロージャとは
クロージャは、組み合わされた(囲まれた)関数と、その周囲の状態(レキシカル環境)への参照の組み合わせです。
クロージャ - JavaScript | MDN
今回のケースでは、
(囲まれた)関数 ... t -> consumer.accept(ai.getAndIncrement(), t)
周囲の状態への参照 ... ai
ということになるため、この関数はクロージャであると言えます。
Javaのラムダ式はfinalの変数しか参照できないという制限があるためか、クロージャではないという意見もあります。
パフォーマンス的にはAtomicIntegerを使わない書き方の方が良いですが、並列処理をしたい場合やラムダ式でスッキリ書きたい場合はAtommicIntegerを使った書き方をするのが良いと思います。
最後に
軽めの記事をと思ったのですが、思ったより長くなってしまいました。
Javaは関数型プログラミングが得意な言語ではないですが、関数型プログラミングの考えを学ぶことで、より良いコードをかける場面というのはままあると思うので、関数型プログラミングを別言語で一度学んでみるのも良いかと思います。