はじめに
UL Systems Advent Calendar 2018 の7日目です。
みなさん、データサイエンスしてますか?
毎日のように、ビッグデータを活用した新しいサービスやビジネスが発表されています。そろそろデータサイエンスを勉強しようかなーと考えている方も多いのではないでしょうか。
この記事では、これから学習するエンジニアのために、人気のデータサイエンス環境である**「Jupyter」を「Docker」で起動して、「R言語」でデータを可視化するまでの方法**を紹介します。
今回使用するDockerイメージは、Jupyter公式の「datascience-notebook」です。このイメージでは、R言語に加えて「Python」と「Julia」もサポートしていますので、これらの言語によるデータサイエンス環境としても利用することができます。
それでは、はじめてみましょう。
環境
本記事では、Dockerのホスト環境としてVirtualbox上のCentos7を使用しています。
WindowsやMacとは一部コマンドが異なる場合もあるかもしれませんが、読者の環境に合わせて読み替えてください。
Dockerのインストール
Docker自体がインストールされていない場合は、利用しているOSのDockerをインストールしてください。
Docker公式サイトはこちらです。
Dockerイメージを取得する
今回は、Jupyter公式のデータサイエンス用のDockerイメージ「datascience-notebook」を使用します。
Dockerファイルはこちらです。
利用するdockerイメージをpullしてください。
$ docker pull jupyter/datascience-notebook
Jupyterを起動してブラウザでアクセスする
Jupyter起動
さっそくJupyterのDockerコンテナを起動します。以下のコマンドを参考に実行してください。(名前は「notebook」です。)
ここで、永続化用のディレクトリ(~/jupyter)は、必要に応じて変更(または削除)してください。
また、追加でライブラリをインストールする場合※は --user root -e GRANT_SUDO=yesを忘れずに指定してください。
(※:DBとの接続用ライブラリや他の言語エンジンのインストールなど。)
$ docker run \
-d \
--user root \
-e GRANT_SUDO=yes \
-e TZ=Asia/Tokyo \
-p 8888:8888 \
--name notebook \
-v ~/jupyter:/home/jovyan/work \
jupyter/datascience-notebook \
start-notebook.sh
token確認
Jupyterにアクセスするためのtokenを確認します。docker logsコマンドでnotebookコンテナの実行ログを参照しましょう。
$ docker logs notebook
Set username to: jovyan
(snip)
[C 10:34:58.460 NotebookApp]
Copy/paste this URL into your browser when you connect for the first time,
to login with a token:
http://(67d1510d5673 or 127.0.0.1):8888/?token=9400eafd9f6f5a2f071134c6307ae8d9542a971799eef5e5
(snip)
ブラウザアクセス
ではJupyterにアクセスしましょう。ブラウザのURLに「localhost:8888」を入力してください。
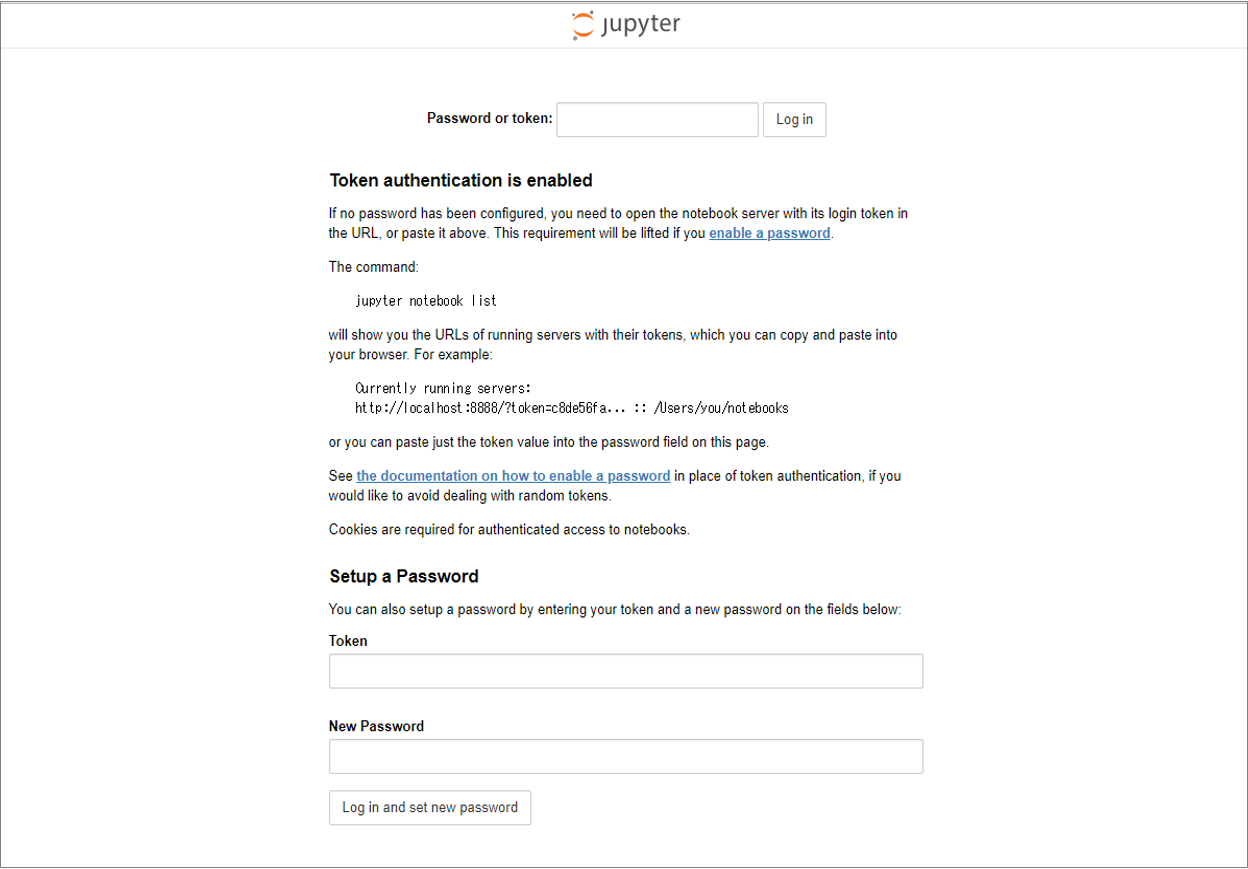
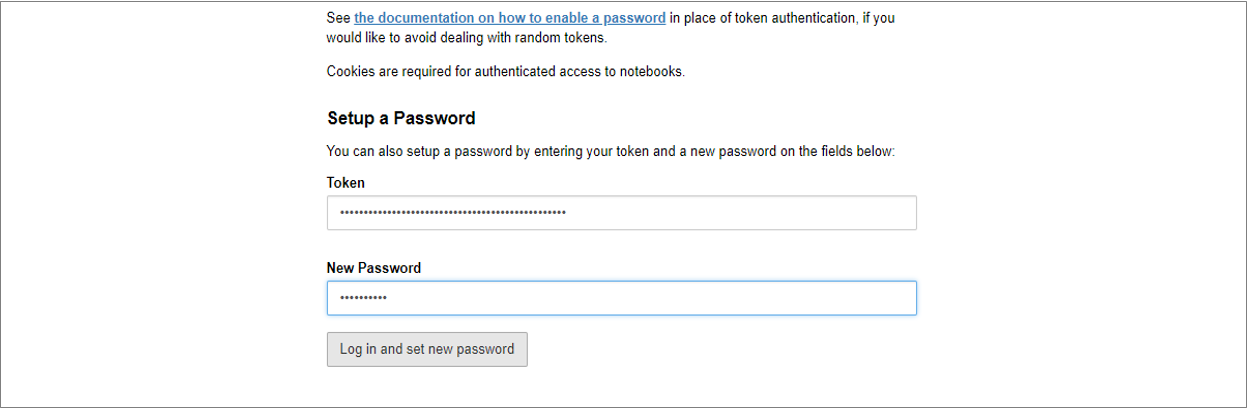
画面下部の「Setup a Password」の「Token」に先ほど確認したtokenを入力し、「New Password」に任意のパスワードを入力して「Log in and set new password」ボタンをクリックしてください。
ダッシュボード画面に遷移します。
Rでデータを可視化する
ノートブック作成
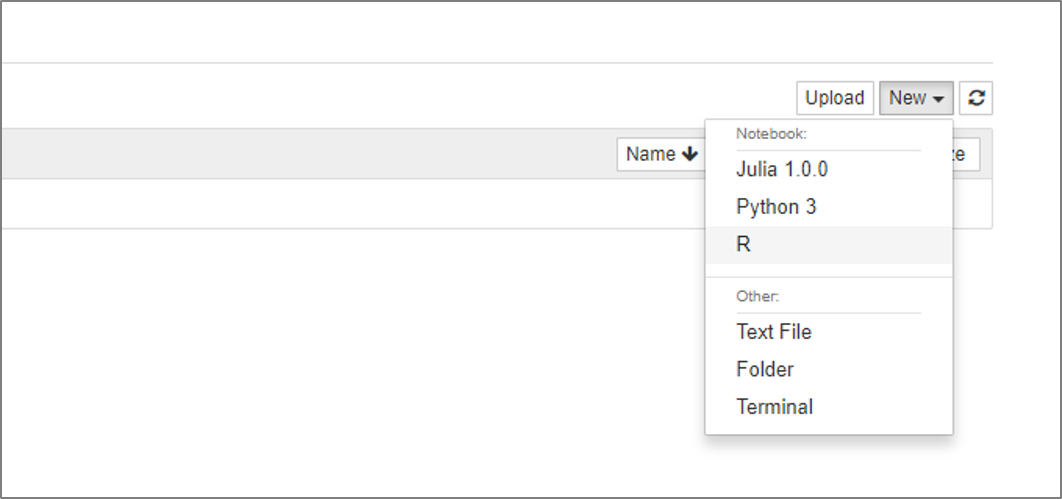
ダッシュボード画面右側の「New」ボタンをクリックして、表示されたメニューの「R」をクリックしてください。
ノートブック画面が開きます。
ライブラリ(tidyverse)のロード
デフォルトのデータセットを使用するため、ライブラリ「tidyverse」をロードしましょう。
このライブラリには説明に使用するデータセットの他に、ヘルプページや関数も含まれています。Codeセルにlibrary(tidyverse)と入力して、「Shift」+「Enter」で実行してください。(画面上部の「Run」ボタンでもOKです。)
(Jupyter自体の詳しい操作方法はオンラインマニュアル(英語)などを参照してください。)
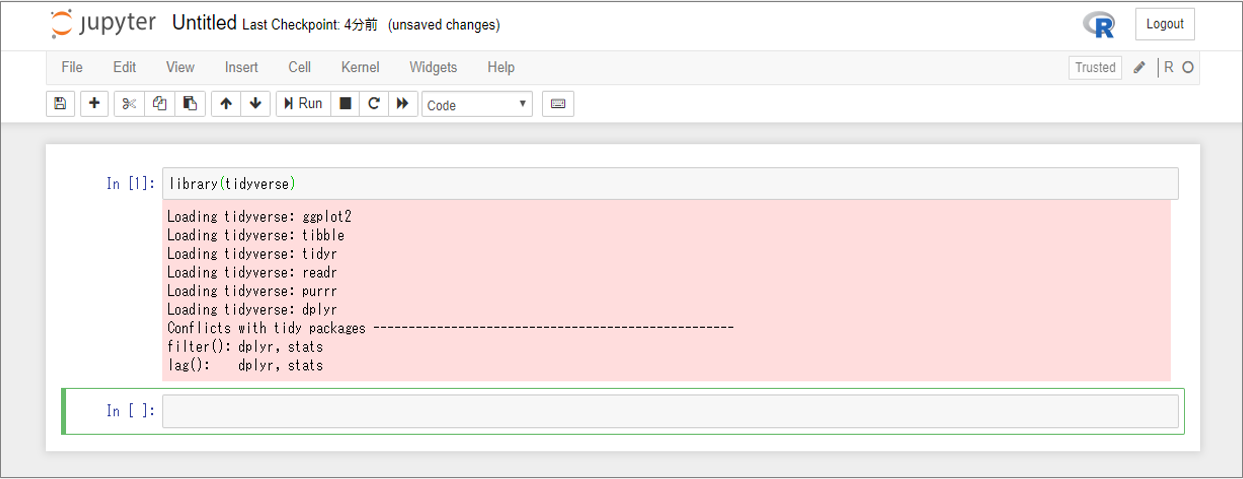
実行結果のConflictsには、デフォルトのRのパッケージに含まれる関数と衝突した関数(filter(), lag())が表示されます。衝突した関数を利用する場合はpackage::function()の形式でパッケージを明示してください。
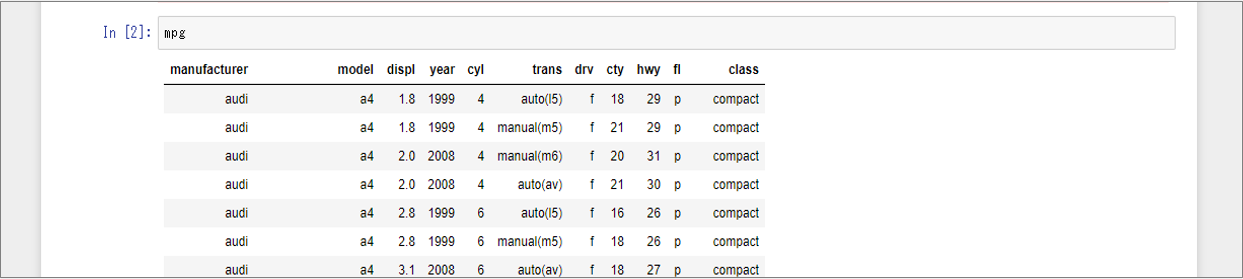
データセット(mpg)確認
今回使用するデータセット「mpg」の内容を表示します。これは、米国環境保護局がまとめた1999年と2008年の38種類の人気モデルの燃費データのデータセットです。
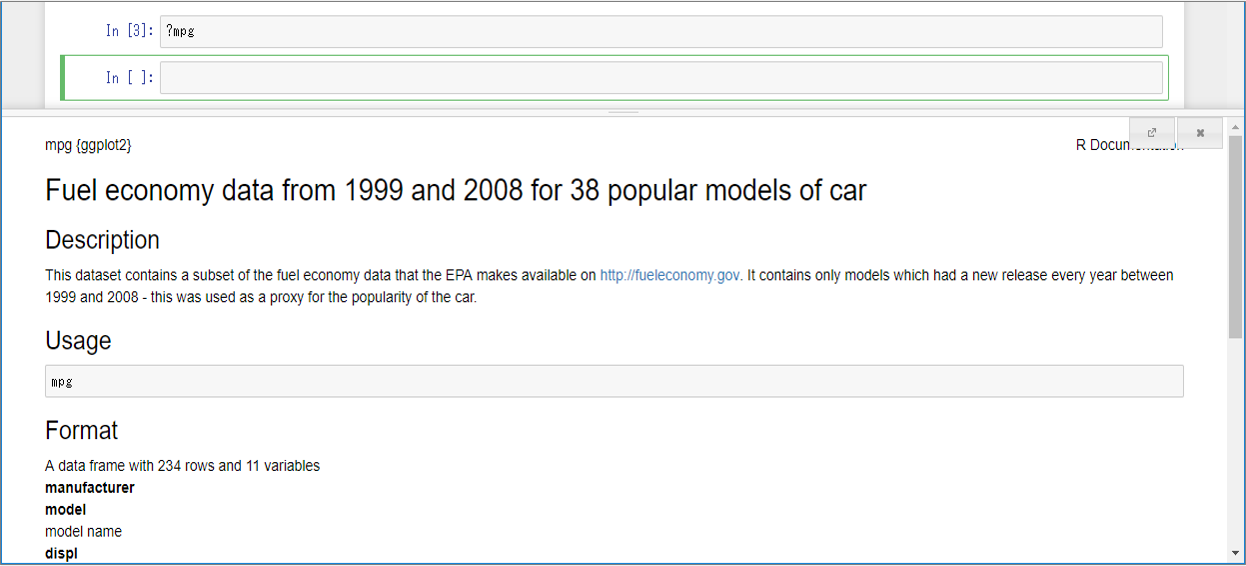
データセットの詳細は、?mpgで確認できます。Rではこれと同様に「?」に続いて名前(データセットだけでなく、関数もOK)を実行することで詳細を表示することができます。(画面の下部に表示されます。)
データの可視化
それでは可視化していきましょう。今回は、散布図と箱ひげ図を作成します。
散布図
x軸に排気量(displ)、y軸に燃費(hwy)を指定して散布図を描いてみましょう。
ggplot()で、入力として使用するデータセットを宣言し、+ geom_point()で散布図のレイヤーを追加します。(これらの関数の詳細は、?ggplot、?geom_pointで確認できます。)
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy))
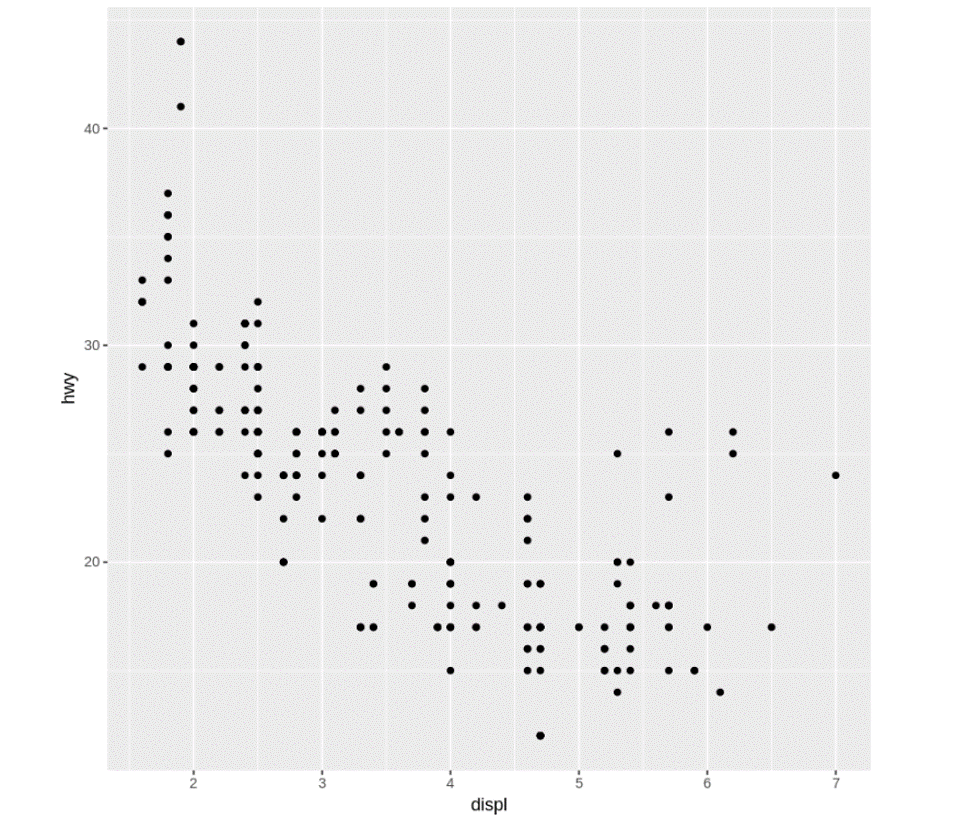
データ全体の傾向はわかりますが、もう少し詳細がわかるといいですね。
mpgには「class」という車種データもあります。このデータを使って、ポイントを車種で色分けしてみましょう。
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy, color = class))
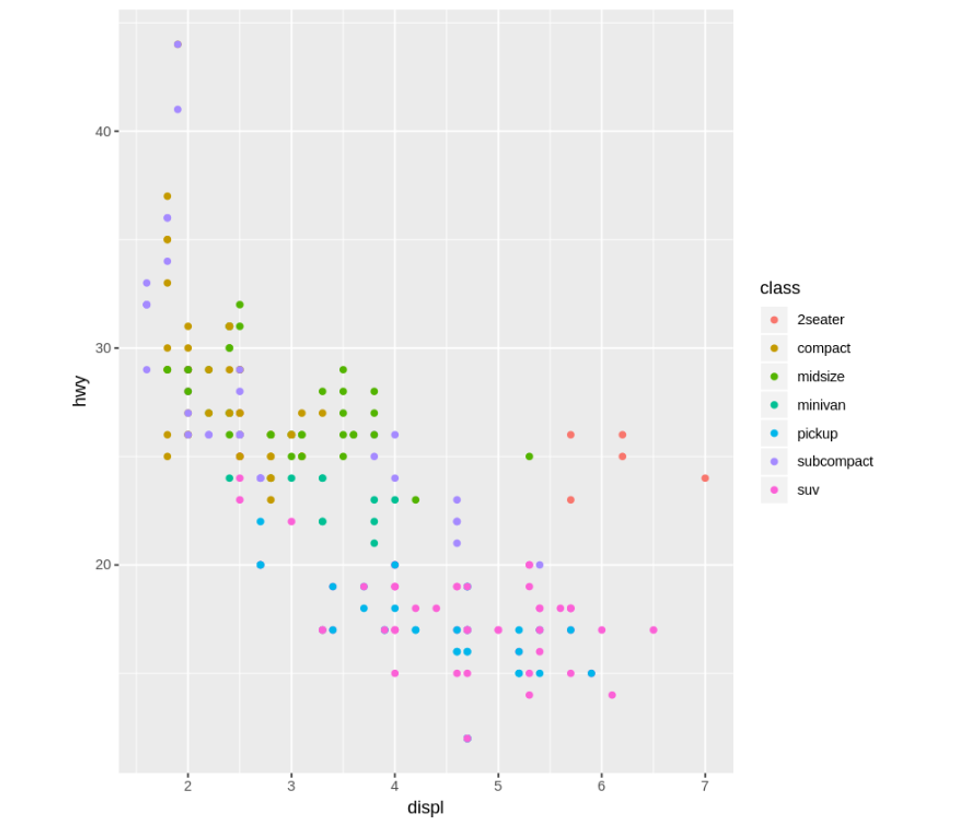
混在していることがわかりました。
次は、車種(class)ごとのグラフを表示してみましょう。facet_wrap()を使用します。
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy, color = class)) +
facet_wrap(~ class, nrow = 2)
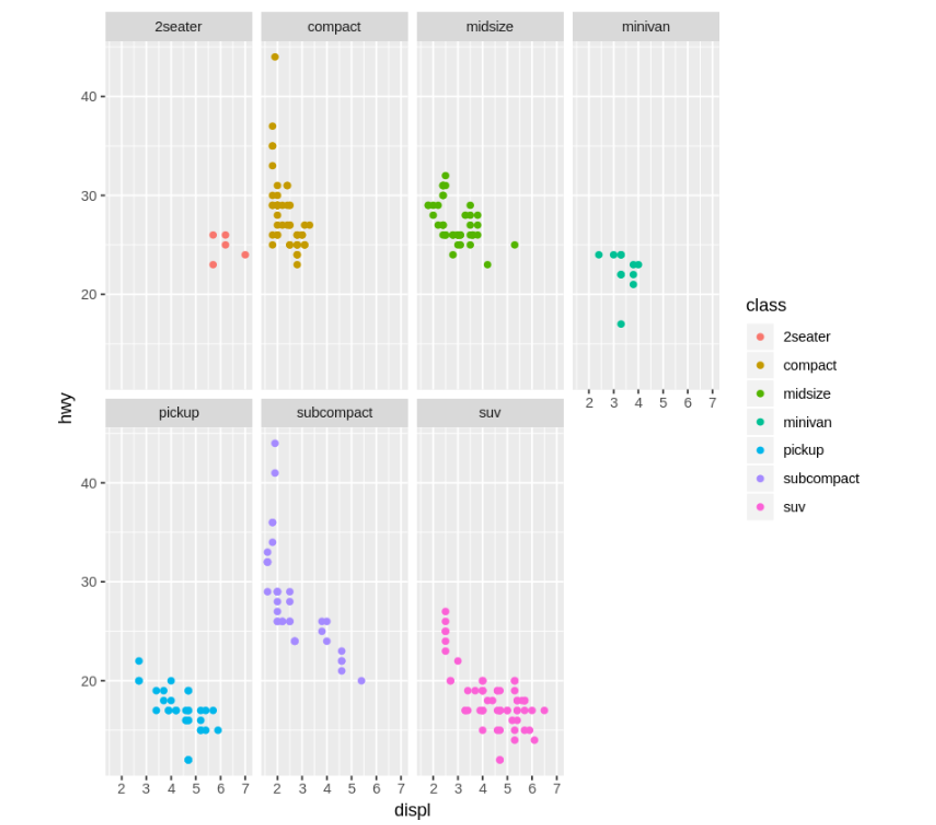
大排気量の「2seater」にUSAを感じます。
箱ひげ図
次は箱ひげ図を描いてみましょう。
車種(class)ごとの箱ひげ図を描く場合はgeom_boxplot()を指定します。
ggplot(data = mpg) +
geom_boxplot(mapping = aes(x = class, y = hwy, color = class))
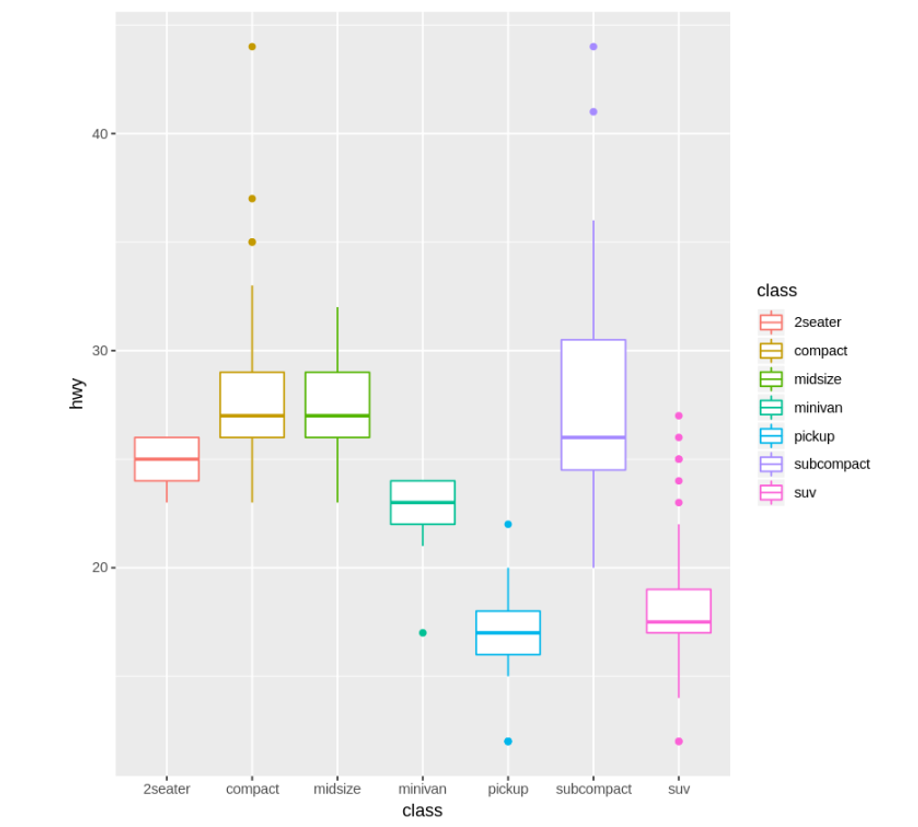
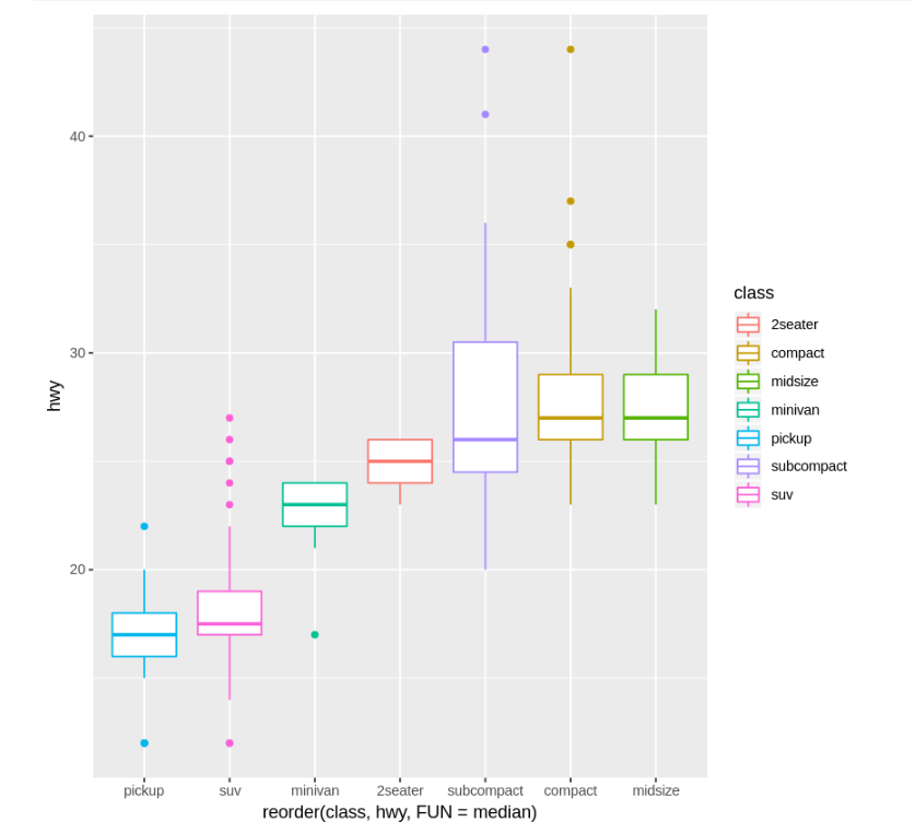
見やすくなるよう、中央値が近い順番に並び替えてみましょう。reorder()を使用します。
ggplot(data = mpg) +
geom_boxplot(mapping = aes(x = reorder(class, hwy, FUN = median), y = hwy, color = class))
まとめ
Docker+Jupyterを使用してデータサイエンス環境を構築し、R言語でデータを可視化してみました。公式のDockerイメージを利用することで簡単に構築できることと、R言語で簡単に可視化できることががわかっていただけたのではないでしょうか。
今回はデータ自体の操作※は行いませんでしたが、R言語ではこれらも非常に簡単に実現できます。
(※:列の選択(select)や追加(mutate)、条件に合ったデータの取得(filter)など)
本記事が、みなさんのデータサイエンス学習のはじめの一歩になれれば幸いです。
参考文献
もっとデータサイエンス学習を進めたい!というかたは、「Rではじめるデータサイエンス」がおすすめです。(本記事の執筆にあたっても参考にさせてもらいました。)
私も読み進めているところですので、一緒にデータサイエンスしていきましょう!