Supershipの名畑です。たくさんの思い出を生み出してくれた中野のシンボルとも言える中野サンプラザとのお別れイベントである中野サンプラザプロジェクションマッピング、とても素晴らしかったです。別れを惜しみながらも、再会を楽しみに待っております。
はじめに
前に「LambdaでBedrockのClaude 3を呼び出してみた」という記事を書きました。AnthropicによるLLMであるClaude 3をAWSのLabmdaとBedrockで呼び出すという内容でした。
今回はその続きです。
S3にアップロードした資料をデータソースとしてRAG(検索拡張生成)を実装します。
Retrieval-Augmented Generation (RAG) は、大規模言語モデル(LLM)によるテキスト生成に、外部情報の検索を組み合わせることで、回答精度を向上させる技術のこと。
また、RAGの実現のためにBedrockのナレッジベースを用います。
Amazon Bedrock のナレッジベースでは、データソースを情報のリポジトリにまとめることができます。ナレッジベースを使用すると、検索拡張生成 (RAG) を活用したアプリケーションを簡単に構築できます。RAG は、データソースから情報を取得することでモデルレスポンスの生成を強化する手法です。
AWSへのログイン時の注意
ルートユーザーでは今回の記事内容が行えないのでご注意ください。
ルートユーザーを使用してナレッジベースを作成することはできません。これらの手順を開始する前に、IAM ユーザーでログインします。
Bedrockへのモデル追加
前回の記事ではClaude 3 Sonnetのみにアクセス権限を付与しました。
今回はそれに追加してTitan Embeddings G1 - Text v1.2を用いるため、あらかじめモデルアクセスをリクエストしておきます。
まずリージョンを ua-east-1 米国東部 (バージニア北部) として、Bedrockのサイドメニューからモデルアクセスのページを開きます。
モデル二つを選んで「変更を保存」を押します。リロードをして「アクセスが付与されました」の状態になっていればOKです。

boto3のダウンロード
前回の記事ではAWSにデフォルトで用意されているboto3を用いました。
「Lambda ランタイム - AWS Lambda」によると、現在のboto3のバージョンはPython3.12の場合は以下でした。
- boto3-1.28.72
- botocore-1.31.72
しかしboto3のリリースノートを見ると、今回利用しようとしているbedrock-agent-runtimeは1.33.2で導入されています。
そのため、今回は最新のboto3をローカルにダウンロードし、それを後ほどLambdaにアップロードすることにします。
この章ではダウンロードのみを先んじて行っておきます。
まずローカルでのPythonのバージョンがLambda同様に3.12であることを確認します。
$ python --version
Python 3.12.2
次にpythonという名称のフォルダにboto3をダウンロードします。フォルダ名は必ずpythonとしてください。
$ python -m pip install -t ./python boto3
これをzip形式でboto3.zipとして固めておきます。後ほど使います。
$ zip -r boto3.zip ./python
S3へのファイルアップロード
「OpenAIのAssistants APIでRAG(検索拡張生成)を実装してみた」で作成した下記の内容のテキストファイルであるcompany.txtを流用します。
会社名:株式会社あいうえおほげ
社員数:65536人
事業内容:アニメと漫画についての話し相手になること
所在:東京都港区
社長:漫画好木
社風:静か
休日:水曜
S3を開き、バケットを作成します。バケット名はわかりやすいものにしておきます。たとえばknowledge-base-data-source-claudeのようなものです。
このバケットにcompany.txtをアップロードします。
Auroraデータベースの作成
ナレッジベースを動作させるためにはベクトルストアというものが必要となります。
デフォルトの選択肢はAmazon OpenSearch Serverlessですが、設定等にもよるでしょうが、私が試した限りでは放置状態でも1日で5ドル程度がかかるため、テスト用途としてはやや高価に感じられる方も多いかもしれません。
素晴らしいサービスであり、試すにはかなり楽ではあるのですが、今回は2024年の2月にナレッジベースでの対応が発表されたばかりのAuroraを使うことにします。設定次第では価格を半分以下に抑えられるため。
- 参考:Amazon OpenSearch Service の料金
- 参考:Amazon Aurora の料金
- 参考:Amazon Bedrock のナレッジベースで Amazon Aurora PostgreSQL および Cohere 埋め込みモデルのサポートを開始 | Amazon Web Services ブログ
以下、Auroraでのデータベース作成手順です。公式ドキュメントである「Build generative AI applications with Amazon Aurora and Knowledge Bases for Amazon Bedrock」に従った内容となります。
AuroraではなくAmazon OpenSearch Serverlessを使う場合は後述する「ナレッジベースの作成」まで飛んでください。
まずRDSを開き「データベースの作成」を押します。
そして作成するデータベースの設定を選択、入力していきます。
データベース作成方法を選択
- 標準作成
エンジンのオプション
- エンジンのタイプ:Aurora (PostgreSQL Compatible)
- 利用可能なバージョン:PostgreSQL 15.5
テンプレート
- 開発/テスト
今回は動作確認用のため開発/テストとしました。
設定
DB クラスター識別子とマスターユーザー名を入れてください。わかりやすいものにしましょう。
Credentials managementではマスターユーザーの接続認証方法を指定します。
Managed in AWS Secrets Managerを選べばSecrets Managerにあるユーザー情報と紐づきます。
紐づくユーザー情報がない場合はSelf managedを選んで、パスワードを指定します。指定したパスワードは忘れないようにしましょう。
クラスターストレージ設定
- Aurora I/O最適化
Aurora I/O最適化について詳しくは「AWS が Amazon Aurora I/O 最適化をリリース」をご参照ください。
インスタンスの設定
- Serverless v2
- 最小ACU:0.5
- 最大ACU:1
Serverless v2について詳しくは「Aurora Serverless v2 の働き」をご参照ください。
ACUはAurora Capacity Unitを意味します。今回は設定可能な最低値としています。
Aurora Serverless では、データベース容量は 1 秒あたりに請求される Aurora Capacity Unit (ACU) で測定されます。1 ACU には、対応する CPU とネットワークを備えた約 2 GiB のメモリがあり、Aurora でプロビジョンしたインスタンスで使用されているのと類似のものです。
可用性と耐久性
デフォルトのままです。
接続
「RDS Data APIの有効化」にチェックを入れます。
それ以外はデフォルトのままです。
Tags
デフォルトのままです。
Babelfishの設定
デフォルトのままです。
データベース認証
デフォルトのままです。
モニタリング
今回は動作確認までのため「Performance Insightsをオンにする」のチェックをはずしました。
追加設定
デフォルトのままです。
ここまでの入力を終え「データベースの作成」を押します。
「データベースの起動には数分かかる場合があります」とのことなので、しばらく待ちます。
作成されたデータベースの設定でARNを確認できます。このARNは後ほど使います。
クエリの実行
データベース作成完了後、同じくRDSにてクエリエディタを開きます。
「データベースインスタンスまたはクラスター」は作成したものを選択してください。
データベースユーザー名はSecrets manager ARNでの管理であれば「Secrets manager ARNと接続する」を選んで、該当のSecrets manager ARNを入力します。
データベース作成時にSelf managedを選んだ場合は、その際のユーザー名とパスワードを入れてください。ここで入力したものはSecrets Managerに自動で保存されます。
「データベースの名前」はpostgresとしてください。
入力後「データベースに接続します」を押します。
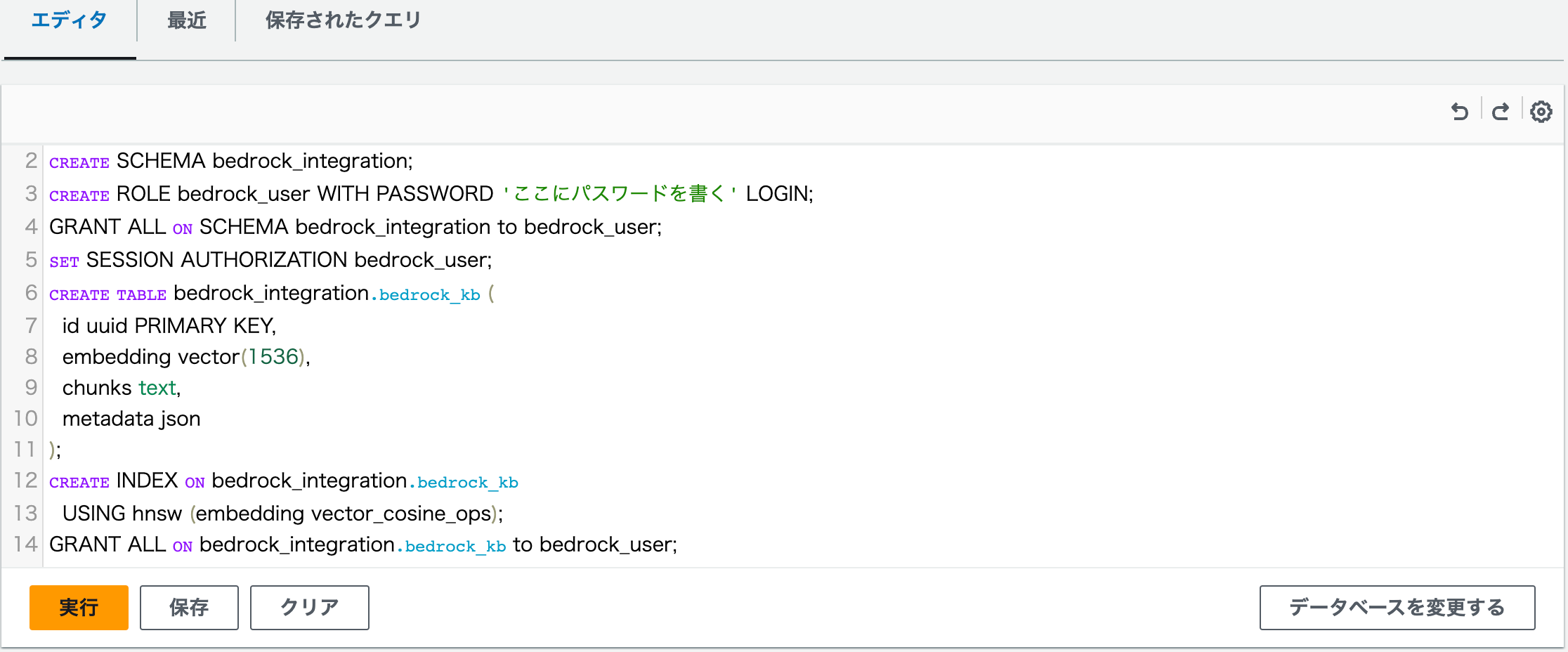
エディタが表示されますので以下のクエリを貼り付けます。「ここにパスワードを書く」のところに接続用のパスワードを書いてください。書いたパスワードで初期設定されます。後ほど使いますので忘れないようにしましょう。
CREATE EXTENSION IF NOT EXISTS vector;
CREATE SCHEMA bedrock_integration;
CREATE ROLE bedrock_user WITH PASSWORD 'ここにパスワードを書く' LOGIN;
GRANT ALL ON SCHEMA bedrock_integration to bedrock_user;
SET SESSION AUTHORIZATION bedrock_user;
CREATE TABLE bedrock_integration.bedrock_kb (
id uuid PRIMARY KEY,
embedding vector(1536),
chunks text,
metadata json
);
CREATE INDEX ON bedrock_integration.bedrock_kb
USING hnsw (embedding vector_cosine_ops);
GRANT ALL ON bedrock_integration.bedrock_kb to bedrock_user;
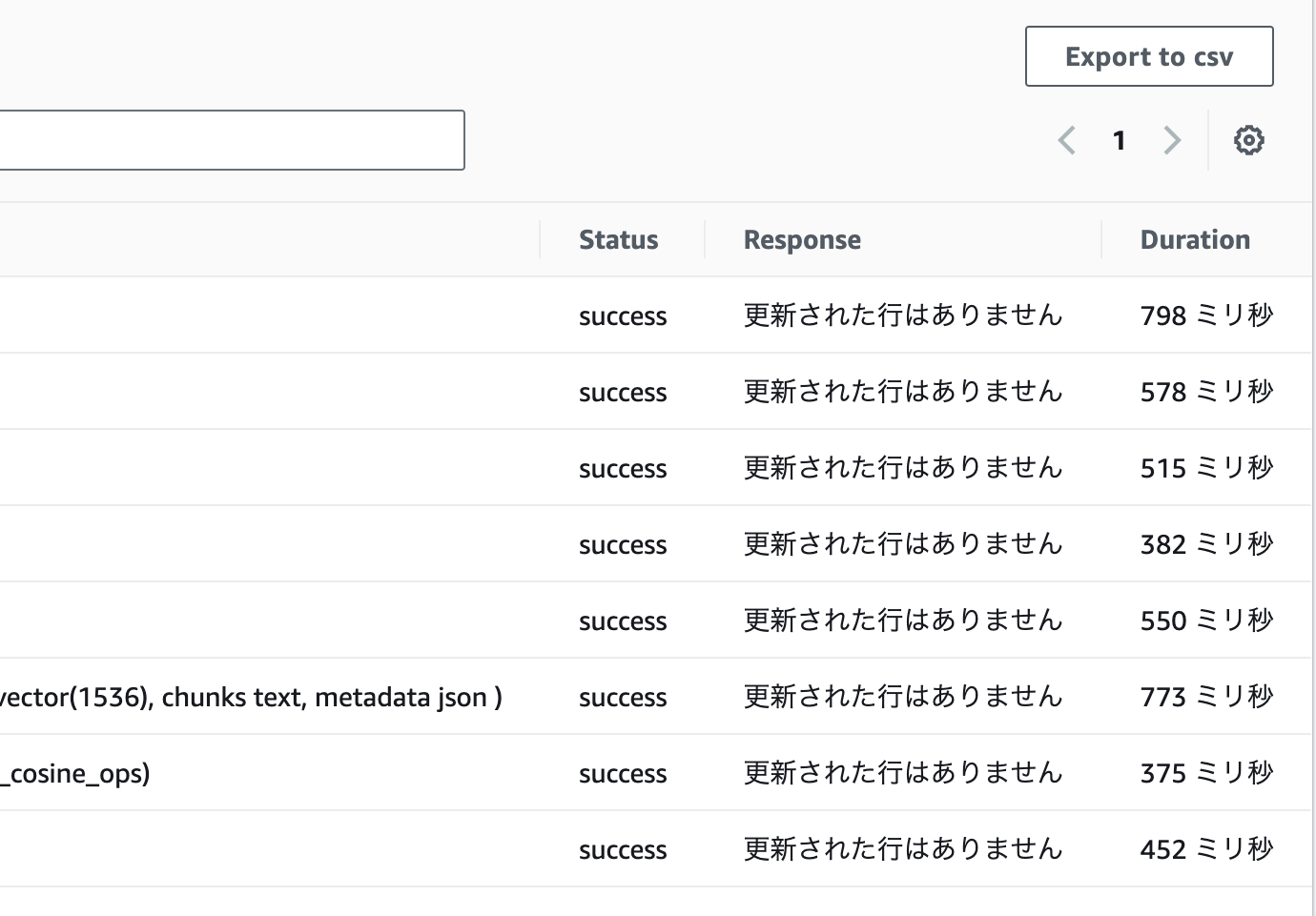
実行すると結果が表示されます。
成功していれば以下のようにStatusにsuccessが並ぶはずです。
シークレットの作成
Secrets Managerを開いて「新しいシークレットを保存する」を押します。
4ステップあります。
ステップ1 シークレットのタイプを選択
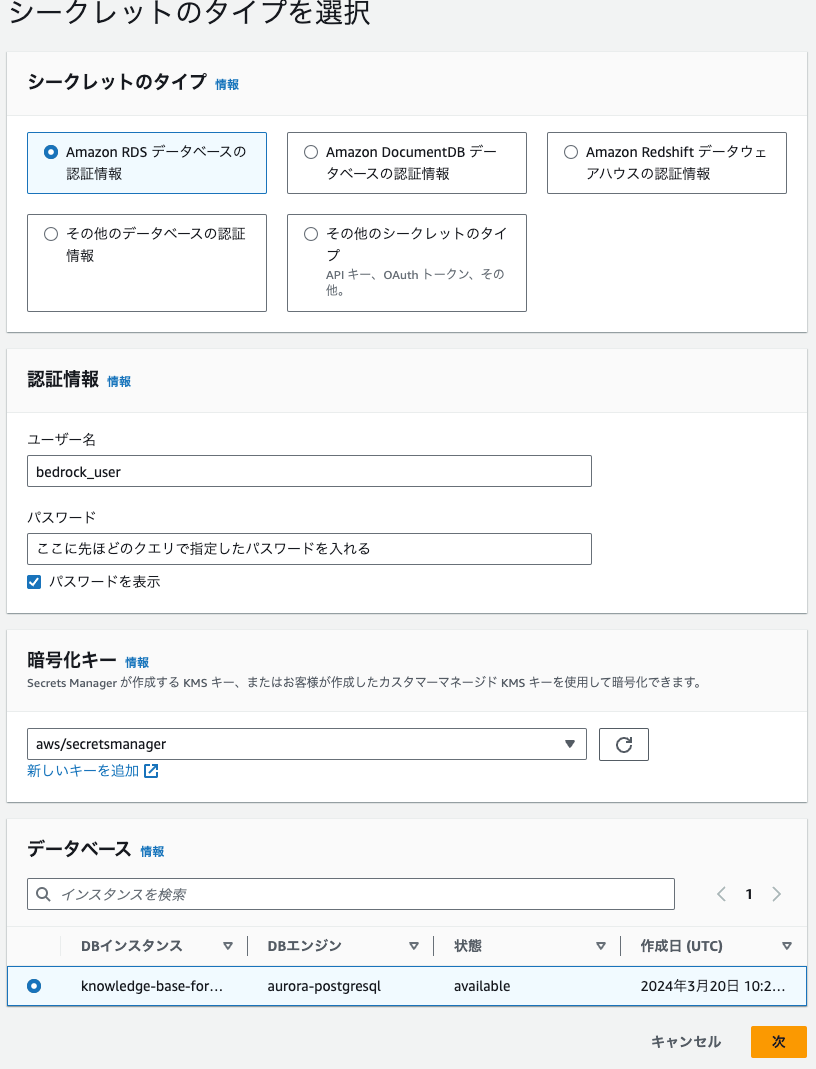
シークレットのタイプは「Amazon RDS データベースの認証情報」を選びます。
ユーザー名はbedrock_userと入れます。パスワードは先ほどのクエリで指定したパスワードを入れます。
データベースは作成済みのデータベースを指定します。
ステップ2 シークレットを設定
シークレットの名前の入力画面です。
わかりやすい名前をつけましょう
ステップ3 ローテーションを設定
今回は設定せずに次を押します。
ステップ4 レビュー
ここで内容を確認して、問題なければ保存を押します。
シークレットが作成されARNが発行されます。このARNも後ほど使います。
ナレッジベースの作成
ついにナレッジベースの作成です。
Bedrockのナレッジベースのページに移動し「ナレッジベースを作成」を押します。
4ステップあります。
ステップ1 ナレッジベースの詳細を入力
ナレッジベース名を入力してください。
IAM許可については既存のサービスロールがなければ新しいサービスロールを作成して使用を選択し、ロール名を決めてください。ロール名は AmazonBedrockExecutionRoleForKnowledgeBase_ から始める必要があります。
ステップ2 データソースを設定
データソース名を入力してください。
S3 URIについては「S3を参照」を押し、先ほど作成したS3バケットを選択します。
ステップ3 埋め込みモデルを選択し、ベクトルストアを設定する
埋め込みモデルは、ドキュメントなどのデータをベクトル埋め込みに変換します。ベクトル埋め込みは、ドキュメント内のテキストデータの数値表現です。
略
各ベクトル埋め込みは、多くの場合、埋め込みが作成された元のコンテンツへの参照などの追加のメタデータとともに、ベクトルストアに格納されます。ベクトルストアは、保存されたベクトル埋め込みにインデックスを付けて、関連データを迅速に取得できるようにします。
今回は埋め込みモデルは冒頭にてアクセス付与済みのTitan Embeddings G1 - Text v1.2とします。
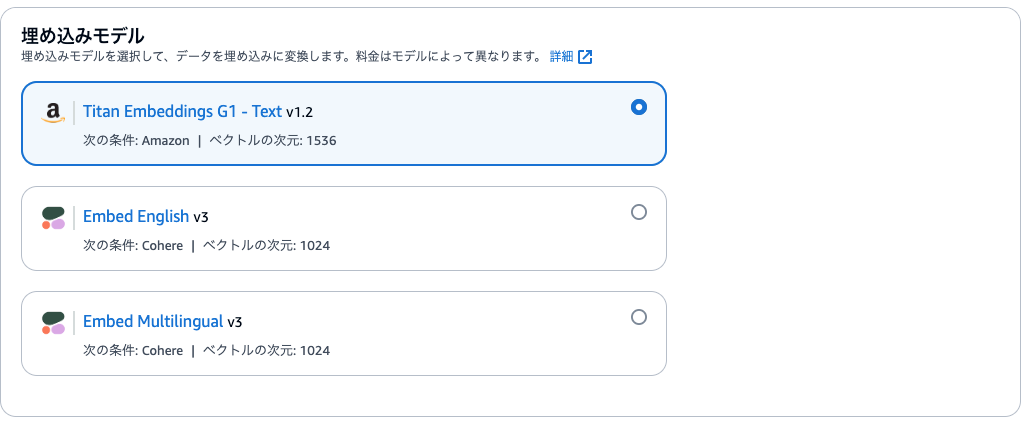
次に- ベクトルデータベースの設定項目です。
今回は作成済みのAuroraを用いるため、「ベクトルストアの作成方法を選択」としては「作成したベクトルスコア」を選んでください。仮にここで「新しいベクトルストアをクイック作成」を選んだ場合は自動でAmazon OpenSearch Serverlessのベクトルストアが作成されますので以降の設定は不要です。
選択、入力項目は以下です。ARNのみ、環境毎に異なります。それ以外は固定値です。
- 既存のデータベースを選択:Amazon Aurora
- Amazon Aurora DB クラスター ARN:作成したデータベースのARNを入れてください
- データベース名:postgres
- テーブル名:bedrock_integration.bedrock_kb
- シークレット ARN:作成したシークレットのARNを入れてください
- ベクトルフィールド:embedding
- テキストフィールド:chunks
- Bedrock マネージドメタデータフィールド:metadata
- プライマリーキー:id

ステップ4 確認して作成
内容を確認して「ナレッジベースを作成」を押します。
作成完了まで数分程度待つと
ナレッジベース「指定したナレッジベース名」が正常に作成されました。データを同期してテストを開始してください。
と出ます。
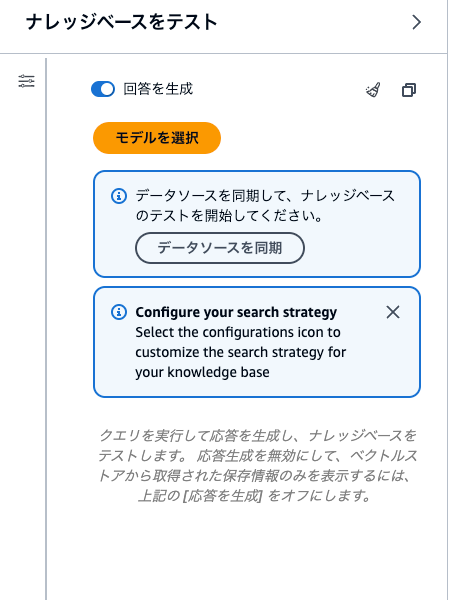
データソースを同期しましょう。
同期はデータソースであるS3のファイルを更新する度に行う必要があります。詳しくは「同期してデータソースをナレッジベースに取り込む - Amazon Bedrock」をご参照ください。
また、画面上でナレッジベースIDが確認できます。
この値はLambdaから呼び出すときに使います。
ナレッジベースをブラウザ上でテスト
作成したナレッジベースをLambdaから呼ぶ前に、ブラウザ上でテストしてみます。
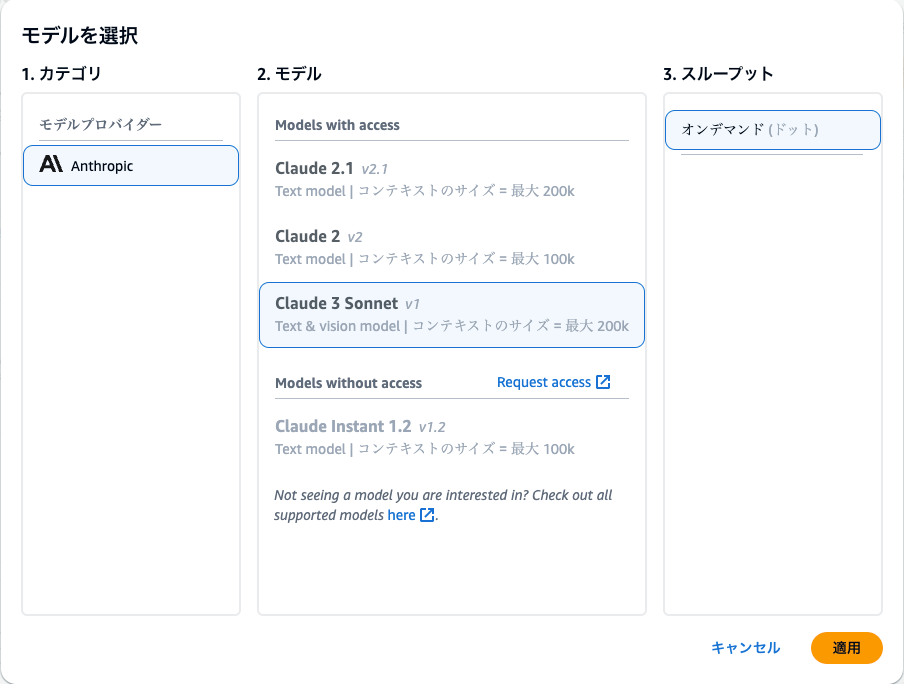
モデルの選択が必要なため、上記画像の通りClaude 3 Sonnetを選びました。
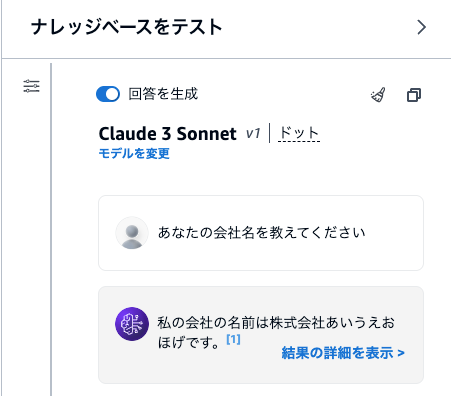
「あなたの会社名を教えてください」と質問すると「私の会社の名前は株式会社あいうえおほげです。」と答えてくれました。ちゃんと資料を参照してくれています。
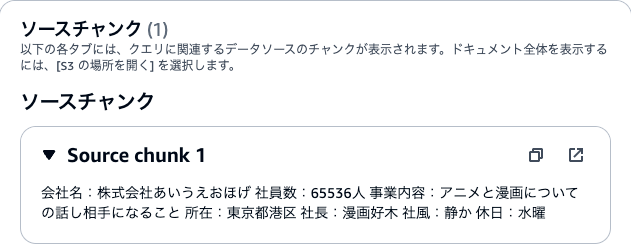
結果の詳細を表示すると、どこからデータを引っ張ってきたかも確認できます。
boto3のアップロード
ここからはLambdaの設定です。
まず、Lambdaを開き、先ほど用意したboto3.zipをアップロードします。
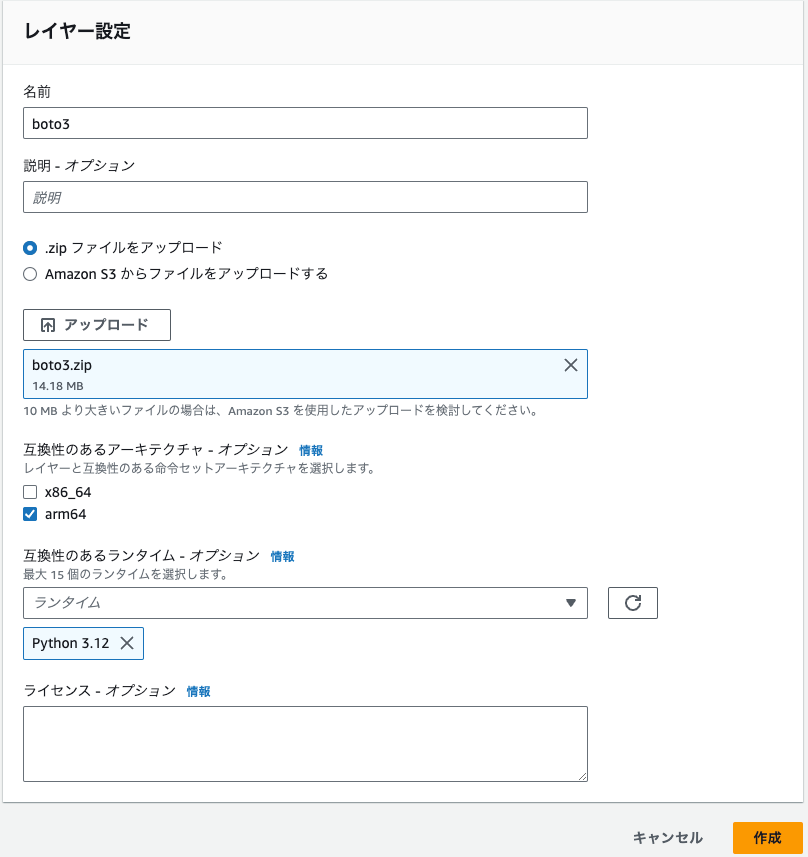
Lambdaでサイドメニューからレイヤーを選んで「レイヤーの作成」をクリックします。
名前はboto3としておきます。
boto3.zipをアップロードするファイルとして選びます。
互換性のあるアーキテクチャはLambda関数の設定に合わせてarm64を選びます。
互換性のあるランタイムも合わせてpython3.12とします。
最後に作成をクリックします。
Lambda関数にレイヤーを紐づけ
前回の記事で作成した関数LambdaToBedrockAccessのコード編集画面に移動し「レイヤーの追加」でカスタムレイヤーからboto3を選びます。
無事に追加されています。
コード
前回のコードを書き換えます。モデルはClaude 3 Sonnetを指定しています。
import json
import boto3
def lambda_handler(event, context):
bedrock_agent_runtime = boto3.client(service_name='bedrock-agent-runtime', region_name='us-east-1')
knowledge_base_Id = "作成済みのナレッジベースIDを書く"
model_arn = "arn:aws:bedrock:us-east-1::foundation-model/anthropic.claude-3-sonnet-20240229-v1:0"
response = bedrock_agent_runtime.retrieve_and_generate(
input={
'text': event.get("message")
},
retrieveAndGenerateConfiguration={
'knowledgeBaseConfiguration': {
'knowledgeBaseId': knowledge_base_Id,
'modelArn': model_arn
},
'type': 'KNOWLEDGE_BASE'
}
)
return {
'statusCode': 200,
'body': response
}
今回はboto3のretrieve_and_generateという関数を用いています。仕様について詳しくは以下あたりをご覧ください。
テスト
以下のjsonを渡して「テスト」を押し、呼び出してみます。
{
"message": "あなたの会社名を教えてください"
}
レスポンスは以下でした。
{
"statusCode": 200,
"body": {
略
"citations": [
{
"generatedResponsePart": {
"textResponsePart": {
"span": {
"end": 17,
"start": 0
},
"text": "私の会社の名前は株式会社あいうえおほげです。"
}
},
"retrievedReferences": [
{
"content": {
"text": "会社名:株式会社あいうえおほげ 社員数:65536人 事業内容:アニメと漫画についての話し相手になること 所在:東京都港区 社長:漫画好木 社風:静か 休日:水曜"
},
略
}
]
}
],
"output": {
"text": "私の会社の名前は株式会社あいうえおほげです。"
},
略
}
}
"text": "私の会社の名前は株式会社あいうえおほげです。"
期待した結果が取得できていました。
後片付け
AWSは従量課金であり、仮にお金の面を除いたとしてもセキュリティ観点などから基本的にどんなサービスであれ使用後は削除なりをすべきですが、今回は特にAuroraやS3といった使われなくても課金が発生するサービスが多いです。今回の記事に限らずではありますが、不要なものはきちんと後片付けをしましょう。
最後に
資料を元にした回答取得までがスムーズに実現できました。
至れり尽くせりですね。
宣伝
SupershipのQiita Organizationを合わせてご覧いただけますと嬉しいです。他のメンバーの記事も多数あります。
Supershipではプロダクト開発やサービス開発に関わる方を絶賛募集しております。
興味がある方はSupership株式会社 採用サイトよりご確認ください。