はじめに
インデックスとはSQLのパフォーマンスを向上させる重要な機能であり、多くのデータベース設計に組み込まれています。
しかし、インデックスとは何かよくわからないまま使うと、その恩恵を得ることができません。
本記事では、インデックスの中で最も使用頻度の高いB-treeインデックスに焦点を当てて、インデックス設計を解説します。
備考
- 本記事はMySQLを例に説明しますが、他のDBMSでもB-treeインデックスは利用可能です。
- 本記事は「達人に学ぶDB設計 徹底指南書」の6章データベースとパフォーマンスの章を参考に記述しています。
B-treeインデックスとは
B-treeインデックスはその名の通り、木構造を用いてデータを索引する方式です。
B-treeインデックスは、他のインデックスタイプに比べて汎用性が高く、データベースに用いるほとんどのインデックスはB-treeインデックスと言われています。
B-treeインデックスの長所
B-treeインデックスが選ばれるのは、どの使い方をしても平均的にパフォーマンスを上げられれるためです。
その長所を3つ紹介します。
データ量の増加に比例してパフォーマンスが低下しにくい
B-treeインデックスは、パフォーマンス劣化が非常に緩やかです。
インデックスはデータの挿入、更新、削除の増加に伴い、探索の速度にばらつきが出始めます。
しかしB-treeインデックスは、データ量が増えても検索速度があまり変わらないため、長期運用に適しています。
なぜパフォーマンス劣化が緩やかなのかは、B-treeインデックスの構造にあります。
B-treeインデックスは平べったい木構造をしています。

一番上のルートから一番下のリーフまで、高さは3~5ほどです。
これは、データ量が何百万、何千万行となっても変わりません。
このように、背が低い木はルートからリーフまでの高さが低いため、データ量が増加しても検索速度は早いままでいることができます。
等価(=)の他に、不等号(>, <, =>, <=)を使ってもそこそこ早い
B-treeは、構築されるとき必ずキー値をソートします。
そのため、等号(=)だけでなく、範囲検索でもある程度パフォーマンスを上げることが可能です。
例えば、WHERE句で「3以下」という条件を指定した場合、「4以上」の値は検索対象になりません。
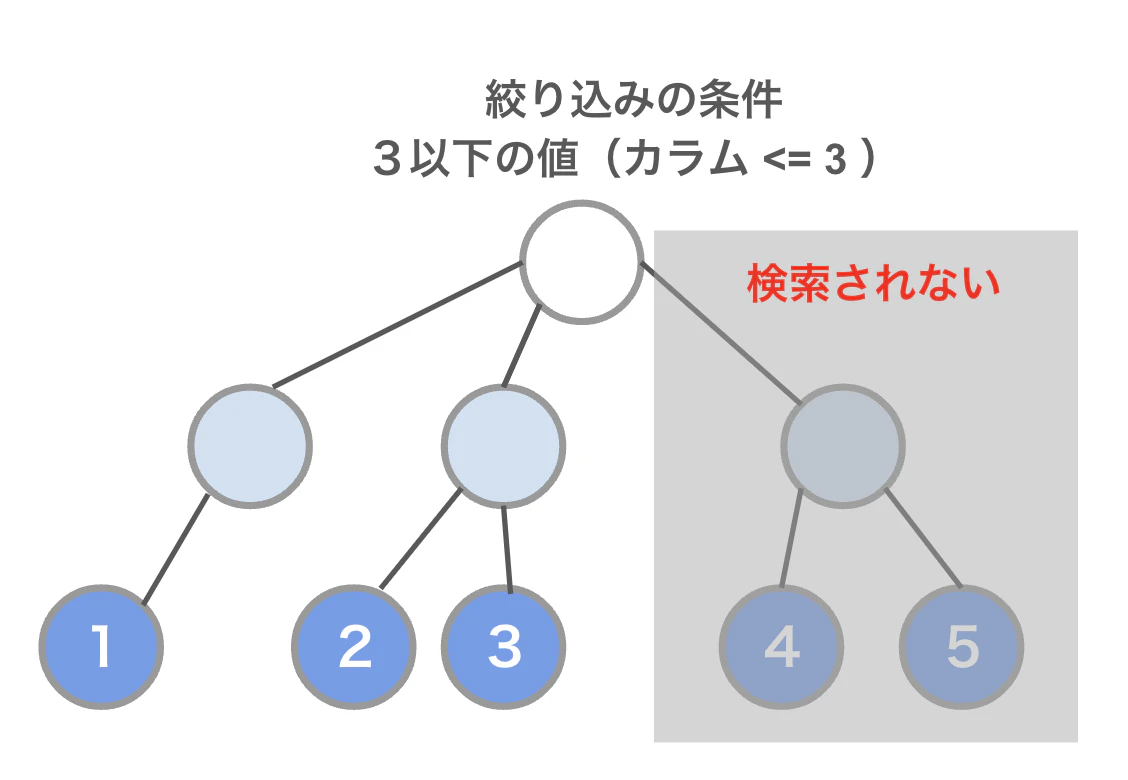
これにより、B-treeは、等号だけでなく、不等号やBETWEENを使った条件に対しても高速な検索が可能です。
これは、ハッシュインデックスにはない利点です。
-- 不等号(>, <, =>, <=)を使える
SELECT * FROM test
WHERE indexed_col > 100;
-- BETWEENも使える
SELECT * FROM test
WHERE indexed_col BETWEEN 10 AND 100;
ただ、やはり等号(=)を使った方が不等号より早いです。
また、否定条件(<>、!=)に対しては、B-treeインデックスは使えないため注意が必要です。
ソートを使う処理(GROUP BY,ORDER BY)で高速化できる
遅いSQL文によくありがちなパターンとして、巨大なソートをしている場合があります。
次のような処理をSELECT文やUPDATE文に記述したとき、暗黙的にソートが行われています。
- 集約関数(COUNT、SUM、AVG、MAX、MIN)
- ORDER BY句
- 集合演算(UNION、INTERSECT、EXCEPT)
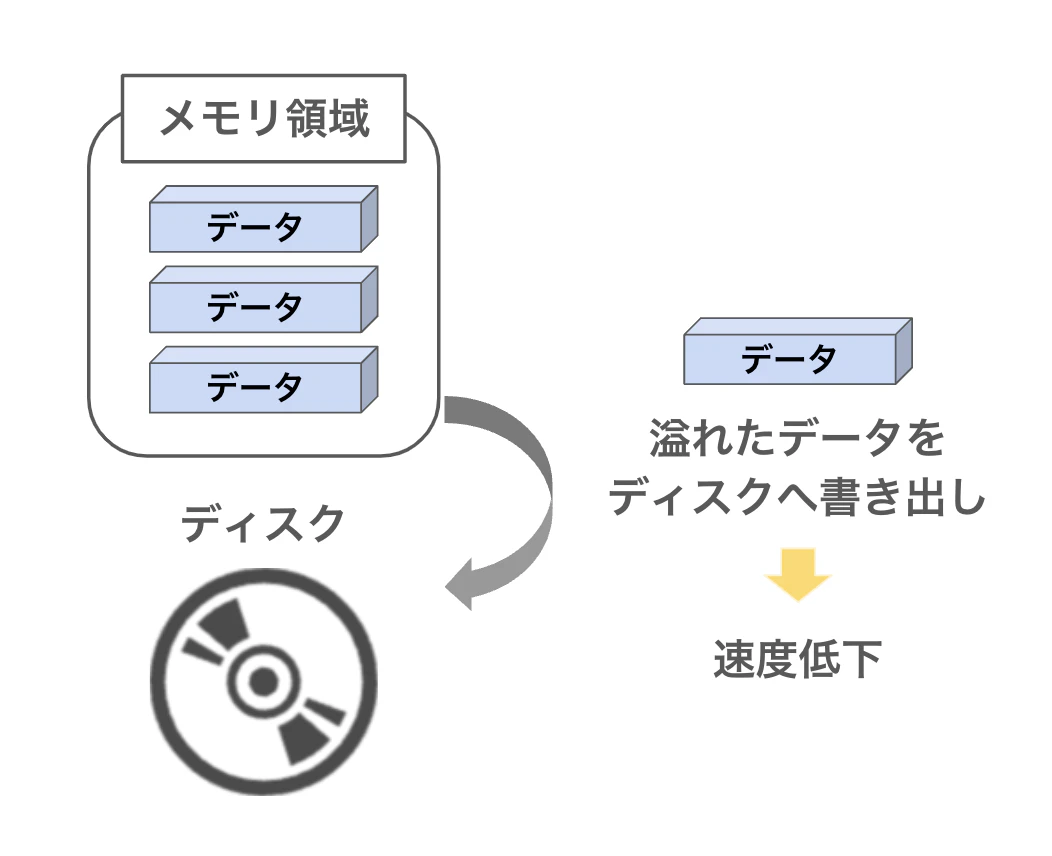
ソートはかなりコストの高い演算です。
データ量が膨大でメモリ上には収まりきらない場合、データベースは一時的に、ディスクへデータを書き出すディスクソートを行います。
ディスクソートが発生すると、I/O負荷(データの出し入れによる負荷)が発生し、ガクンとSQLのパフォーマンスが落ちます。
上記にもありますが、B-treeは、構築されるとき必ずキー値をソートします。
そのため、B-treeインデックスの存在する列をソートする際は、すでにソートし終えている状態のため、負荷を軽減することができます。
これは複合インデックスの場合にも当てはまります。
B-Treeインデックスはどのカラムに作るのがよいか?
B-Treeインデックスはやみくもに作ればいいわけではなく、適切な使い方があります。
代表的な使い方を以下に並べます。
- 大規模なテーブル
- カーディナリティが高いカラム
- WHERE句の選択条件、結合条件に使われるカラム
順に説明していきます。
大規模なテーブル
インデックスがない場合の検索はすべてのレコードを検索するフルスキャンです。
レコード数が少ない場合、インデックスをつけても、つけなくても、検索する量が少ないため速度はあまり変わりません。
その場合、わざわざB-Treeインデックスをつける必要もありません。
逆に、レコード数が多いテーブルはインデックスはつけるべきです。
どの程度がデータ量が多い、に該当するかはサーバーの性能によって変わりますが、大体1万レコード以上の場合はB-Treeインデックスありの方が早いとされています。
カーディナリティが高いカラム
カーディナリティは組になっている要素の数を表します。
「性別」の要素を考えた時「男性」「女性」「不明」の3つがあるとします。
この時、カーディナリティは3です。
これは非常に小さなカーディナリティになります。
カーディナリティが高い例として「商品の売上日」「ユーザーID」などが挙げられます。
売上日は毎日売れれば、1年で365カーディナリティが増えますし、ユーザーIDはユーザー数が増えるほど大きくなります。
WHERE句の選択条件、結合条件に使われるカラム
当たり前の話ですが、インデックスが効果を発揮するのは、検索・結合に使うカラムのみです。
ただしB-treeインデックスを使う際、いくつかNG例が存在するため、一部紹介します。
NG例1:インデックス列に演算を行っている
インデックスのあるカラムをSQLで問い合わせる時は、「裸」の状態で使用してください。
下の例だと、検索を行うカラムはあくまで、「index_col」であって、「index_col * 2」ではないためです。
-- NG例
SELECT * FROM table WHERE index_col * 2 > 100;
-- OK例
SELECT * FROM table WHERE index_col > 100 / 2;
NG例2:IS NULLを使う
B-treeインデックスではNULLはデータ値とみなされず、インデックスに保存されません。
そのため、IS NULL、IS NOT NULLはソートの対象となりません。
-- NG例
SELECT * FROM table WHERE index_col IS NULL
NG例3:前方一致以外のLIKE句
LIKE句を使う場合、基本的に前方一致の場合のみインデックスが適用されます。
-- NG例:中間一致を使用している
SELECT * FROM table WHERE index_col LIKE '%Patrick%';
-- NG例:後方一致を使用している
SELECT * FROM table WHERE index_col LIKE LIKE '%Patrick';
売上テーブルを例に検証
やってみる方が早い!ということで、インデックスをつけたバージョンと付けないバージョンでどれほど速度が変わるのか検証してみましょう。
次の売上テーブルを作成し、1万件のデータを入れてみます。
B-treeインデックスは売上日sales_dateにつけました。
-- CREATE文
CREATE TABLE sales_index (
sales_id INT AUTO_INCREMENT PRIMARY KEY,
product_name VARCHAR(255) NOT NULL,
category VARCHAR(100) NOT NULL,
price DECIMAL(10, 2) NOT NULL,
sales_date DATE NOT NULL,
);
-- INDEXの追加
create index sales_date_index on sales_index(sales_date);
使用したダミーデータ生成サイト
https://filldb.info/
測定に使うクエリ
B-treeインデックスは集合関数にも使えるということで、売上日ごとの売上個数を検索するクエリで測定してみました。
SELECT
sales_date,
COUNT(sales_date) as 日毎の売上個数
FROM
sales_index
GROUP BY
sales_date
ORDER BY
sales_date
;
結果
結果は、インデックスなしが「0.0244秒」、インデックスありが「0.0084秒」とインデックスありの方が格段に早いことが見て取れます。
1万件のレコードでこの速度の違いのため、レコード数が増えればさらにパフォーマンスに如実に現れそうですね!
| - | クエリにかかった時間 |
|---|---|
| インデックスなし | 0.0244秒 |
| インデックスあり | 0.0084秒 |
速度計測クエリのこちらのブログを参考にさせていただきました。
https://collapse-natsu.com/post/mysql_query_speed
-- 測定クエリ
SELECT
EVENT_ID,
TRUNCATE(TIMER_WAIT / 1000000000000, 6) AS Duration,
SQL_TEXT
FROM
performance_schema.events_statements_history_long
WHERE
SQL_TEXT LIKE "%SELECT sales_date ,COUNT(sales_date) as 日毎の売上個数 FROM sales_index GROUP BY sales_date ORDER BY sales_date%"
;
おまけ:インデックスの高さを確認する
検索で使用したクエリの頭にEXPLAINをつけると、クエリの実行状況を表示してくれます。
その中の「key_len」がインデックスの高さになります。
今回は高さが「3」となっていました。
EXPLAIN SELECT ,sales_date ,COUNT(sales_date) as 日毎の売上個数 FROM sales_index GROUP BY sales_date ORDER BY sales_date;
-- key_len: 3
まとめ
B-treeインデックスとはなにか?また、その使い方を解説しました。
新人研修などではさらっと流される部分ではありますが、SQLクエリチューニングにおいて重要な役割を持っているので、どんどん使いこなしていきたいですね。
参考
B ツリーインデックスの特性
https://dev.mysql.com/doc/refman/8.0/ja/index-btree-hash.html#btree-index-characteristics