※本内容はRPALT vol.12でお話した内容です。
今年の5月にAmazon TextractというAWSのOCRサービスが一般公開されました。
値段は安いし、精度もそれなりに良い!これは使わない手はないと思い、いろいろ実験しました。
あまりネット上に二次情報がなかったので、Amazon Textractに興味がある方の参考になれば幸いです。
Amazon Textractとは
Amazon Textractの概要については別の記事でお話しているので、そちらをご覧ください。
Amazon Textract(OCR)についてまとめてみた
Amazonが提供しているOCRサービスで、「クラウド上で動く」「APIも使える」「値段が安い」「フォームや表を読み取る」「信頼スコアが出てくる」「手書きは対応していない」「まだ日本語対応されていない」という特徴があります。

Amazon Textractの信頼スコアとは!?
そもそも「信頼スコアってなんだ!?」って疑問に思う方も多いと思います。
信頼スコアは「OCRで読み取ったテキストの正確性を表す0~100の数字です。
画像の中にある文字と、レスポンスで返したテキストがどれくらい一致するか(正確に読み取れるか)を表すものです。

信頼スコアがあると何が良いの?
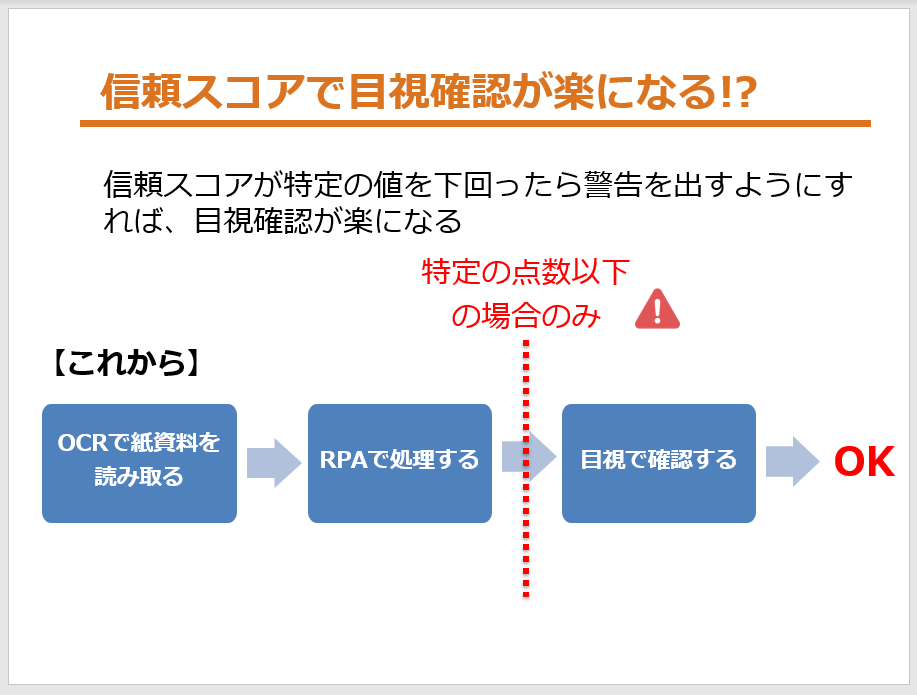
現在OCRは、紙の資料をPDFもしくは画像ファイルにして文字を読み取り、RPA
ツールで処理をするというのが多いですが、OCRの精度は100%ではないので必ず目視での確認が必須なのです。
しかし、信頼スコアを使用するとより劇的に人の作業が減ります。
RPAツールで処理した後に、信頼スコアがとある基準値以下になった場合に警告を出す、とある基準値を超えた場合はOKというルールにすれば、目視確認の負担がかなり減ります。
信頼スコアは本当に信頼できるのか!?
基準値を設定してそれを上回るか下回るか~という解決策はなかなか良いのではと思うのですが、何といっても僕はひねくれものなので、信頼スコアが全然あてにならないやつの可能性もあるじゃんwって思いました。
なので、信頼スコアはどれくらい信頼できるものなのかを検証してみました。
検証の方法
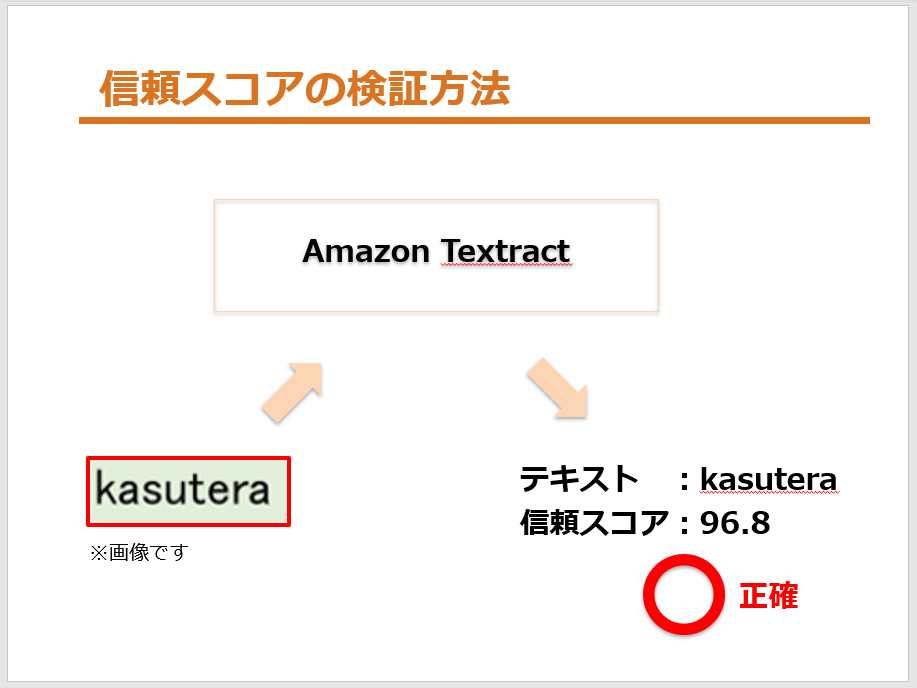
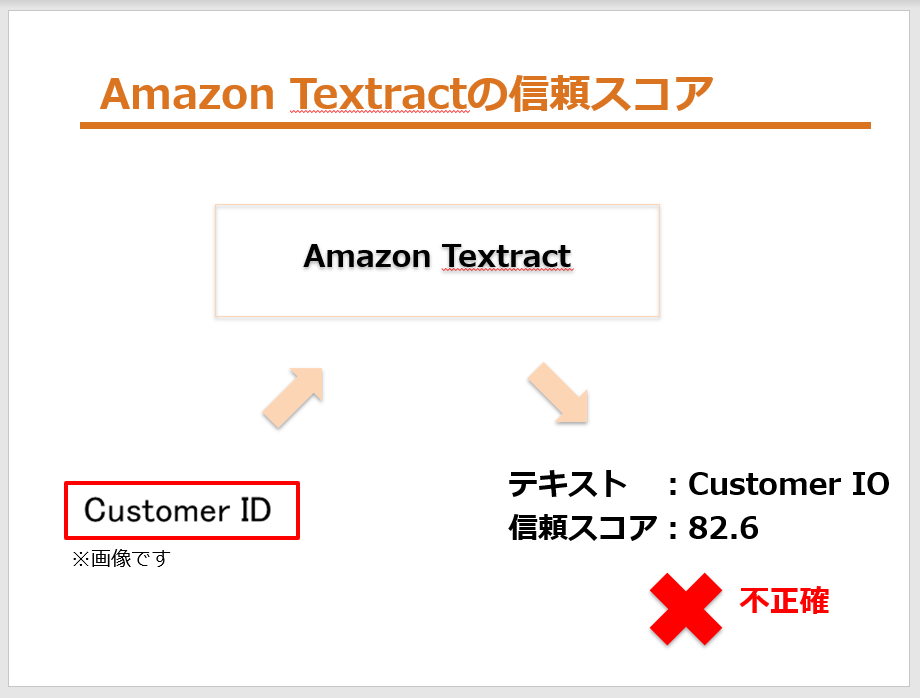
画像をAmazon Textractに送って、レスポンスでテキストと信頼スコアが返ってきます。
今回は「読み取った単語が正確な場合」と「読み取った単語が不正確な場合」の2つに分類して、信頼スコアを記録していきました。
「単語が正確な場合」の検証結果
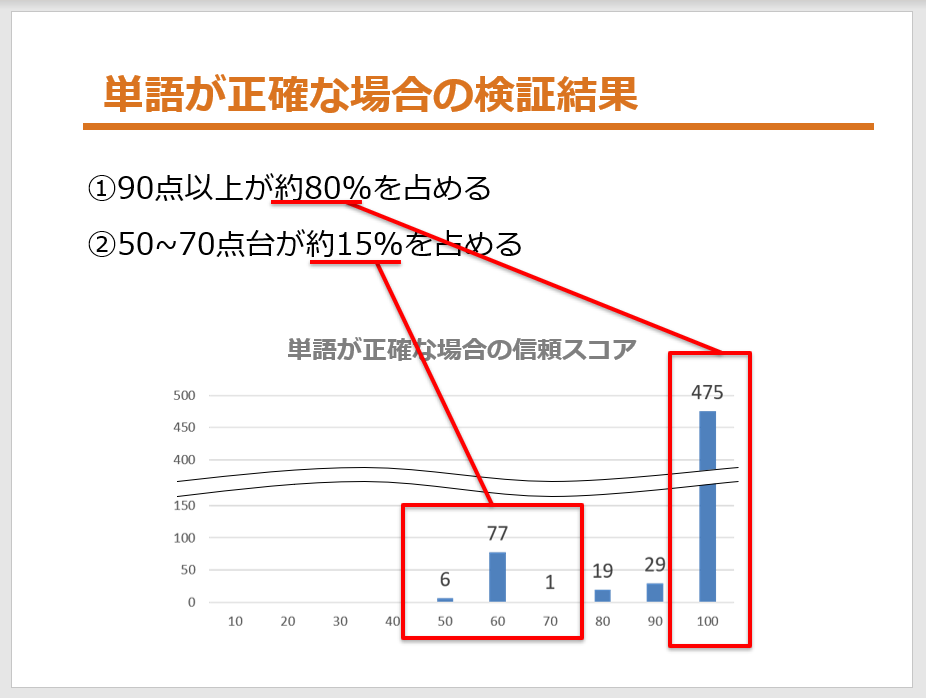
理想は信頼スコアが高い場合はテキストは正確で、信頼スコアが低い場合は単語が不正確であることなのですが、実際の検証結果は以下になりました。
- 90点以上が約80%を占める
- 50~70点台が約15%を占める
信頼スコアが高い場合はOCRの読み取りテキストは正確であってほしいので、1番に関してはOKですよね。
でも、2番にあるように、信頼スコアが低い場合でもレスポンスのテキストが正確である場合が約15%もありました。
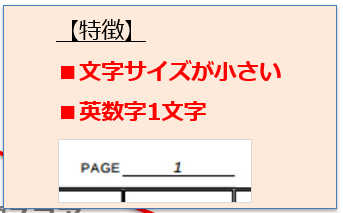
2番のような、信頼スコアが低いけれども単語が正確な場合の特徴を調べてみると、読み取り対象の「文字サイズが小さい」とか、読み取り対象が「英数字1文字」だけのときという特徴がみられました。
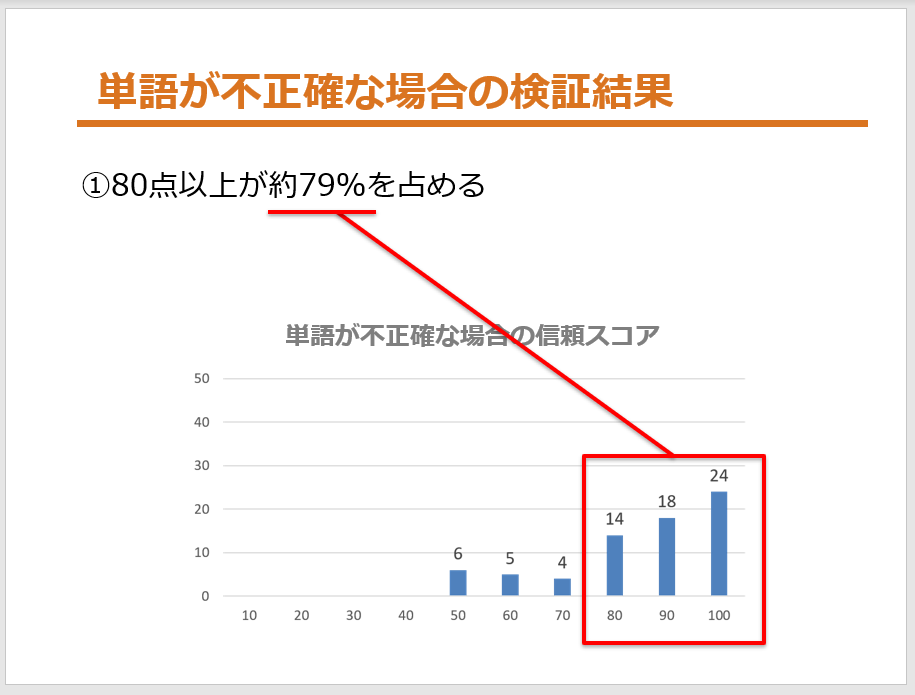
「単語が不正確な場合」の検証結果
レスポンスの単語が不正確な場合の結果は以下のようになりました。
(そもそも不正確の母数が少ないのは、OCRの精度が結構良いということで喜ばしいことなのですが、それは脇に置いておいて)
レスポンスの単語のテキストが不正確なのに、信頼スコアが80点以上のものが約8割ありました。自信満々に間違っているパターンですねw
このパターンが正直一番困ります。
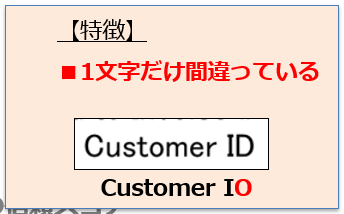
こちらも、特徴を調べてみたところ、「1文字だけ読み間違えている」ものが大半を占めていました。
工夫して信頼スコアを使用しよう!
これまでの検証により、以下の3点が分かりました。
- 単語が正確な場合、信頼スコア90点以上が約8割あった
- 単語が正確な場合、信頼スコアが50~70点台が約15%を占めた
- 単語が不正確な場合、信頼スコアが80点以上が約8割あった
また、2の特徴は「文字サイズが小さい」「英数字1文字だけ」だったり、3の特徴は「1文字だけ間違っている」というものでした。
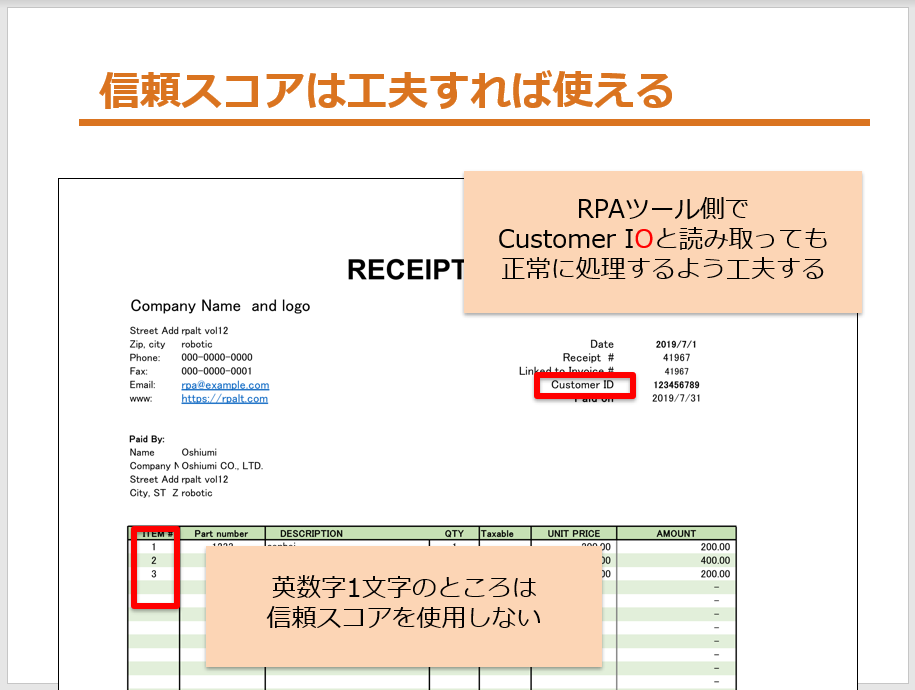
信頼スコアが低いのにレスポンスのテキストは正確だったり、信頼スコアが高いのにレスポンスが不正確だったりするのはとても困るので、一工夫いれてみましょう!
まあ、単純なのですが、英数字1文字だけのところは信頼スコアを活用しないとか、先に誤字をすると分かっているものに関しては、誤字をしてみ大丈夫なようにRPAツールを設計しましょう!(誤字に関しては、正規表現という技術が使えます!)
これだけはちゃんと聞いてほしい注意事項
この検証はあくまで私が何十枚もの帳票を読み取らせて検証した結果です。
別の帳票を読み取ると、僕の検証結果とは異なる結果になる可能性も大いにあります。今回の検証結果でこういう結果が出てきたからといってそれをあなたが手元に持っている帳票を読み取った場合に同じことがいえるかどうかは分かりません。
なので、今回の検証は「ふーん」くらいに思っておき、実際に業務などで使用するとなった場合に同じように検証して特徴をあぶりだして、不都合なデータは工夫して消していくという作業をやっていただけると良いかと思います。