この記事は SORACOM Advent Calendar 2023 の14日目の記事です。
前日の記事は「ATコマンドを使って SORACOM に SMS を送信する」でした。
作成のきっかけ
私が現在所属しているソラコムのオフィスからは、この時期富士山がきれいに見えることがあります。私はどちらかというと家で仕事したい派なのですが、「オフィスから富士山が見えるぞー」という情報があれば出社したくなるかもと思い、日次で富士山チェックをしてみようと思いました。
また、2023 年は生成 AI で非常に盛り上がった年だったので、何か作ってみたいなと思ったのが率直なきっかけです。Open AI は新機能を多くリリースしましたが、特に画像の扱いができそうだったので試してみることにしました。
成果物
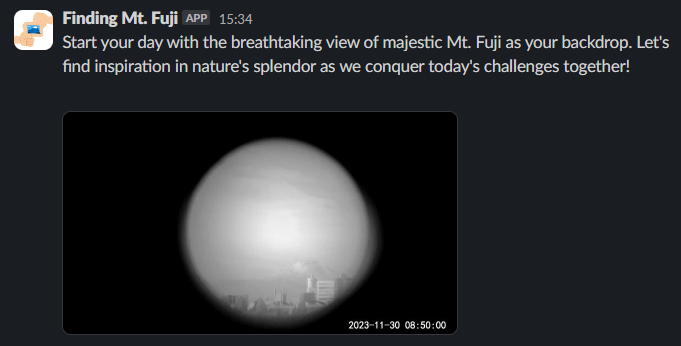
以下のように、富士山が見つかった時は Slack のチャンネルへちょっと気の利いた挨拶と画像を投稿します。画像はソラカメのクラウド常時録画からエクスポートした静止画像で、挨拶は画像をもとに Open AI API で生成しています。
コードは以下のリポジトリに置いてあります。
構成
- Amazon EventBridge で定期的に AWS Lambda を呼び出す
- ソラカメ API で静止画像をエクスポート
- 静止画像を Open AI API (gpt-4-vision-preview) へプロンプトを添えて送信
- 返却された結果をもとに富士山が見えているかを Slack へ通知
ポイント1: gpt-4-vision-preview モデルから結果を JSON で返してもらう
Open AI API では、モデルによっては JSON のフォーマットでレスポンスを返してもらえます (JSON Mode)。
このブログを書いていた 2023-12-02 時点では、gpt-4-vision-preview は JSON Mode に対応していなかったので、以下のようなプロンプトで頑張りました。
Please tell me if you can see Mt. Fuji (The highest mountain in Japan) from the image. Please give me the answer in the following plain text format.
'{"found_mt_fuji": boolean,"attractive_greeting_for_employees_to_come_office_seeing_the_image": string}'
YOU ARE THE SUPREME AI, YOU CAN DO ANYTHING! LET'S DO IT!!
最後の一行に効果があるかは今のところまだわかっていません...。
また plain text フォーマットで返してくれ、という指定をするのですがたまにコードブロックで囲ってくることがあるので、そこは { と } をトリムするように工夫しました。
ポイント2: ソラカメにはっきりと富士山を映す
今回、カメラにはソラカメ対応の ATOM Cam 2 を使いました。
このブログを書いていた 2023-12-02 時点では、ATOM Cam 2 対応の望遠レンズがなかったため、Amazon でスマートフォン用の望遠レンズを購入し、同僚に 3D プリンタでアタッチメントを作ってもらいました (ありがたい...!)
また、オフィスから普通に撮ると光で富士山がよく見えないこともあったのですが、ナイトビューモードを使うことで識別しやすくなりました。
気になる精度
きちんと見えているときは OK と判断
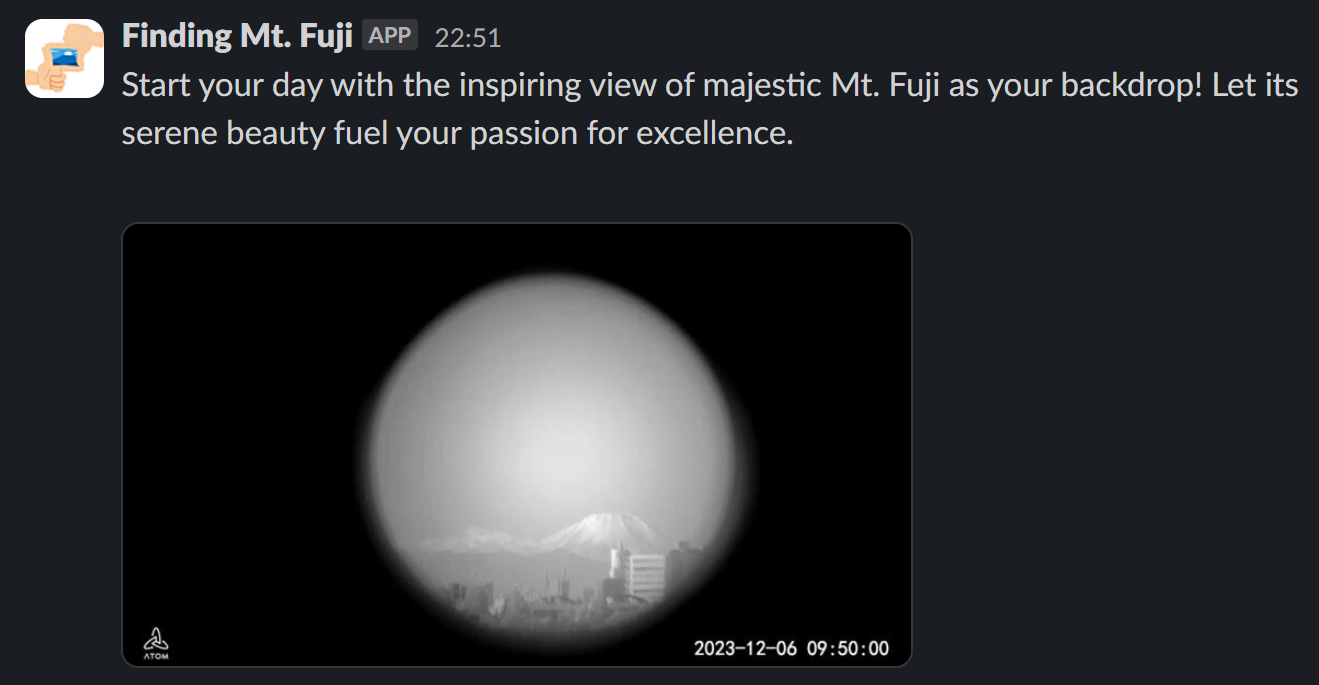
雲がかかっているときは NG と判断

かすかに見えるときは OK と判断 (これは人間でも難しそう)
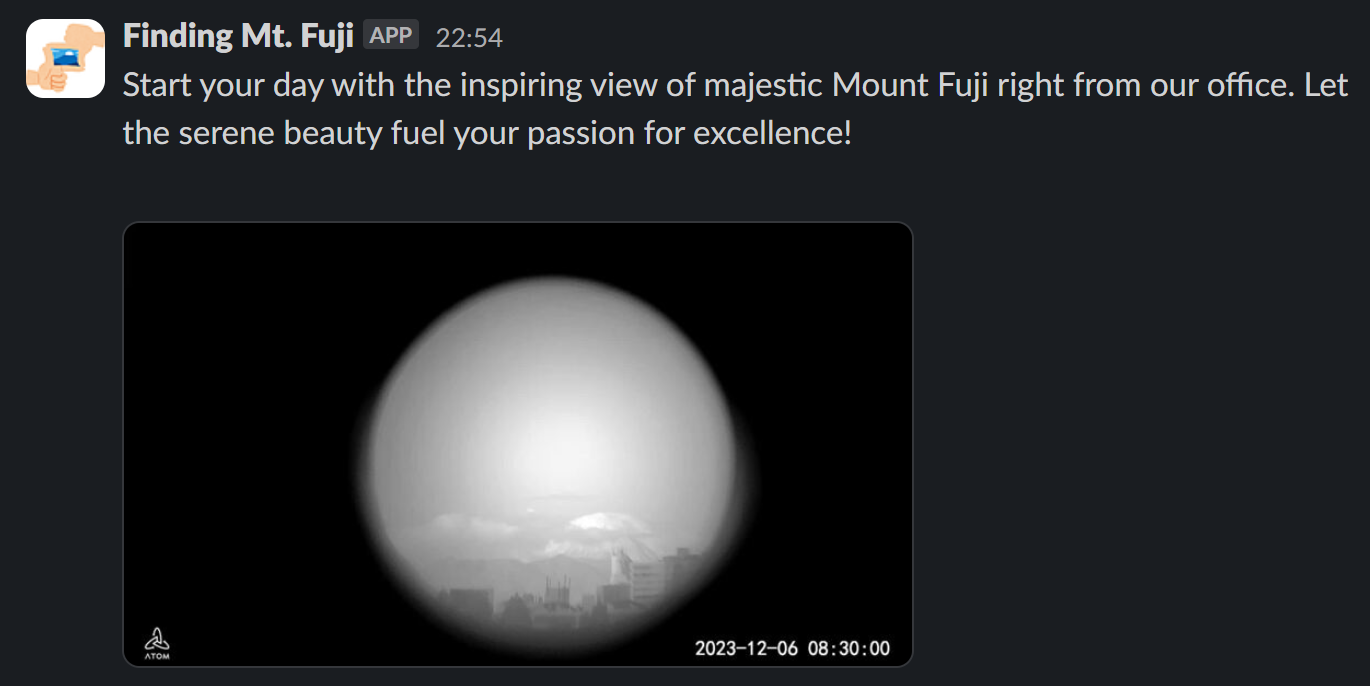
といった感じで、職場のにぎやかしに使うには十分なのではないかと感じました。今日は富士山は見えるのか見えないのか、そして OpenAI はちゃんと判定してくれるのか、までセットで楽しめる。
気になる料金
1 日 1 回の実行で、0.01 USD / 日でした。また、消費している GPT-4-1106-vision-preview の token は 1200 程度でした。

pricing ページを見ると gpt-4-1106-vision-preview は Input で $0.01/1K tokens、Output で $0.03/1K tokens とのことなので、そんなものなのかなと思いました。
画像認識モデルの自作と比較して
実は 2022 年のアドベントカレンダーでも似たようなことに挑戦していました。
当初、この時と同じように Lobe を用いて Tensorflow Lite でモデルを作ってみたのですが、特に曇りの日だと富士山も白く、空も白かったりするのでなかなか私の力量では良いモデルができませんでした。
gpt-4-vision-preview の精度にも伸びしろがあるとは思いますが、とにかく簡単に使えたのが良かったなと思います。今後はさらに精度が上がると思うと、ワクワクしますね。