イントロ
2023年5月12日、OpenAIからChatGPTのプラグインが試験リリースされました(リリースノート)。この新機能は、plusユーザーから順に利用できるようになっています。ブラウザ拡張ではなく、画像のように公式アプリ内の機能として提供されています。
以前から存在はしていましたが、waitlistに登録する必要がありました。今回の試験リリースでそれが不要になりました。
* この記事は2023年5月14日時点の情報に基づいており、その後のアップデートにより情報が変更される可能性があることをご了承ください。
ChatGPTプラグインとは
ChatGPTプラグインは、、ChatGPTの応答を特定の目的に合わせてカスタマイズするためのツールです。以下の画像のように既に多数のプラグインがあります。
利用するには
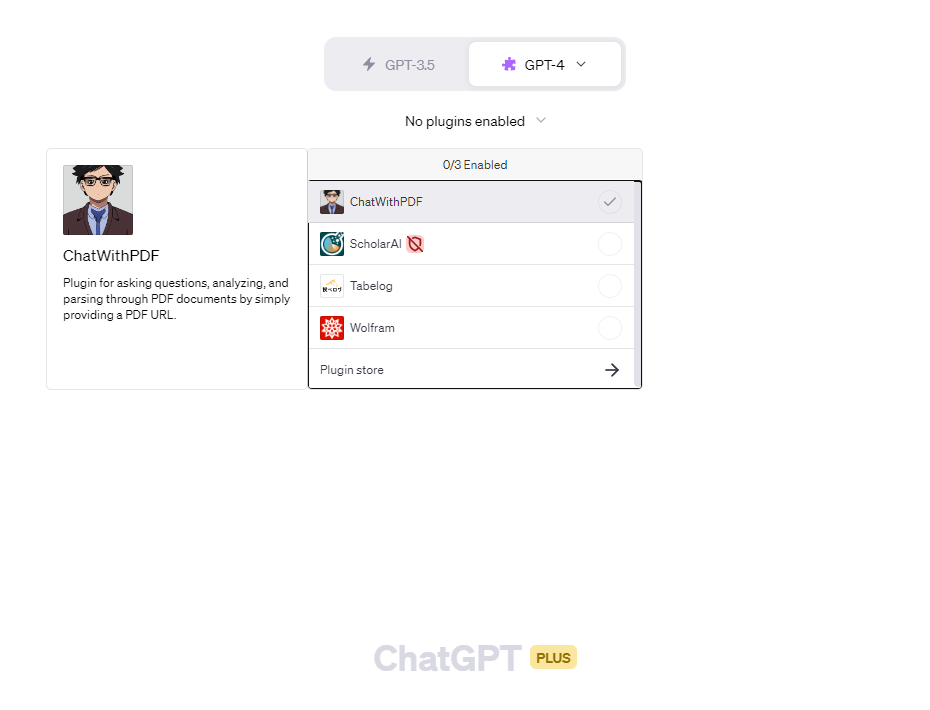
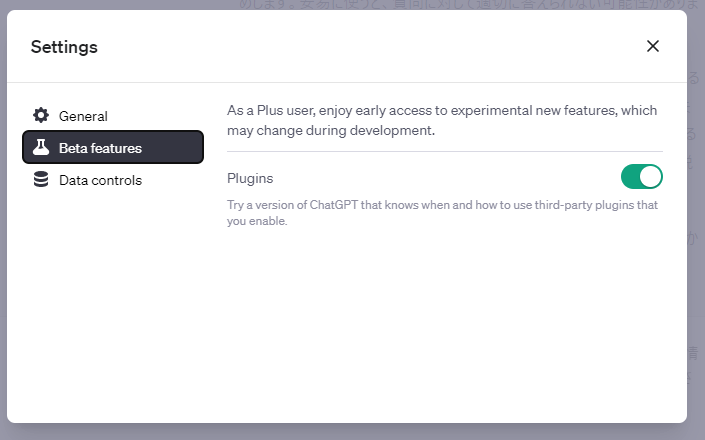
利用するには、まず、設定画面からBeta featuresのPluginsをオンにします。
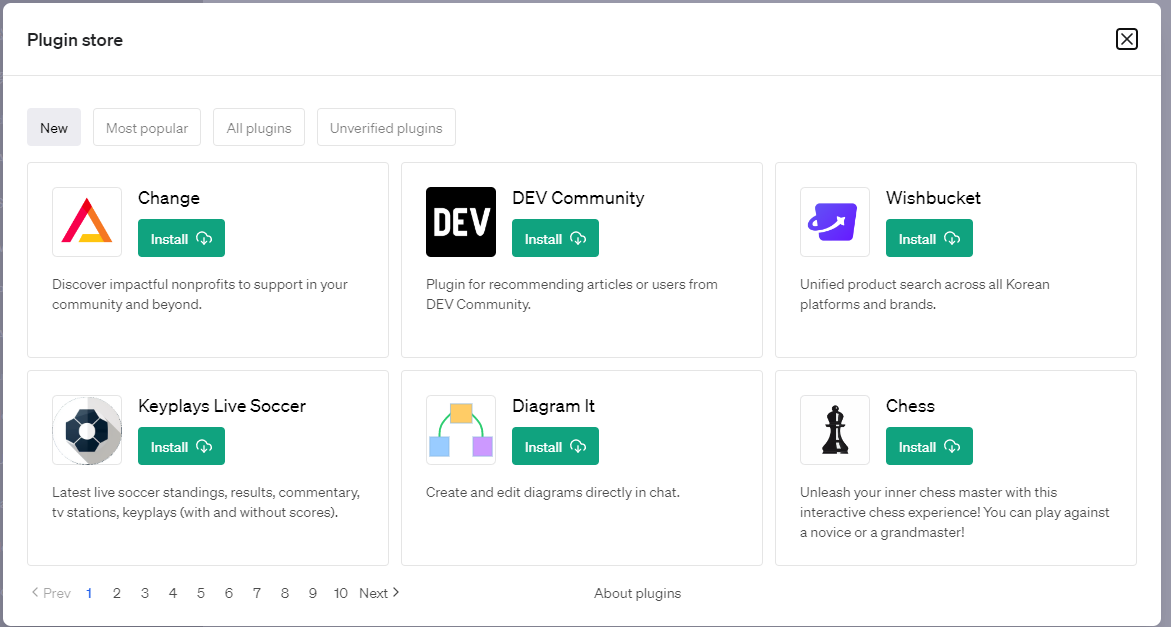
次に、「New Chat」のモデル選択の場所でプラグインをインストール・選択します(次の画像参照)。プラグインのインストールは「Plugin store」からできます。
例
例えば食べログのプラグインでは、このような実在するお店の情報を教えてくれます。「Used Tabelog」と利用しているプラグインが表示されているのも特徴でしょう。

これらのプラグインを活用することで、ChatGPTの可能性がさらに広がります。
論文を読ませよう
ChatGPTプラグインの中には、"ChatWithPDF"というものがあります。これを使えば、ChatGPTにPDF形式の論文を読ませることができます。
例えば、「{PDFのURL} の論文をまとめて」と尋ねると、以下のような返答が返ってきます。

ただし、まだ試験的な機能であったりするので、プラグインによっては動作が安定しないことがあるようです(たまに内部エラーが出ることがあります)。その場合は何度かリトライするか、プラグインを再インストールすると解消するかもしれません。ChatWithPDFで何度かエラーに遭遇しました。また、ChatWithPDF固有の問題としては、上手く論文が特定できない場合があることもあります(リトライで済む話ですが)。
勉強会の準備に使おう
私は機械学習名古屋研究会を主催しています。この研究会では、論文を概要・新規性・手法・検証・その他議論の観点でまとめて発表します。そこで、ChatWithPDFを使って研究会の準備をしてみました。
論文
今回、対象とする論文はhttps://arxiv.org/abs/1706.03741です。
この論文は、ChatGPTでも使われているRLHFの元ネタとなる論文です。
プロンプト
研究会のフォーマットにまとめてもらうために、以下のように注文をいれたプロンプトを作成しました。冒頭のURLだけ変更すれば他の論文でも使えます。
https://arxiv.org/pdf/1706.03741.pdf を日本語でまとめて欲しいです。
まとめ方は、最終的に、以下の項目に分けてそれぞれを説明するという方式をとってほしいです。
* どのような研究なのか(どういうジャンルか?)
* 先行研究と比べてどうか(どういう問題意識があって、対策をしたのか)
* 手法(それなりに詳しく教えてください。複数の手法を混ぜているなら、それぞれ説明してください。)
* 評価・検証(どういうデータを使って、どういう精度がでているなどの情報(主要なものだけでOK)も欲しい)
* その他議論(残課題など)
結果
結果は以下の通りです((UsedChatWithPDF)と表記した位置はプラグインの動作位置、(つづけて)(続けて)は回答が途切れたときに入力した内容です)。
結果(長い)
(UsedChatWithPDF)
(UsedChatWithPDF)
この研究は、人間のフィードバックを利用して深層強化学習を行う手法についてのものです。具体的には、人間が2つの行動のうちどちらを好むかを示すフィードバックを用いて、エージェントが目標を達成するための行動を学習します。この手法は、報酬関数が明示的に与えられない状況や、人間の好みを学習する状況に適用可能です。先行研究と比較して、この研究の主な貢献は、人間のフィードバックを用いた深層強化学習のスケーリングにあります。これにより、より複雑な行動を学習することが可能になりました。また、先行研究では全体の軌跡に対する比較を行っていましたが、本研究では短いクリップに対する比較を行い、人間の時間を大幅に節約しました。
手法について詳しく説明すると、まずエージェントは環境と相互作用し、その結果得られる行動のペアを人間に提示します。人間はこれらの行動のペアの中から好ましいものを選びます。このフィードバックを用いて、エージェントは報酬関数の推定値を更新します。そして、この報酬関数の推定値を用いて、エージェントは新たな行動を学習します。このプロセスを繰り返すことで、エージェントは人間の好みに従った行動を学習します。
評価・検証については、MuJoCoとAtariの2つの環境で行われました。MuJoCoは物理シミュレーションを行うソフトウェアで、ロボットの制御などのタスクを行います。一方、Atariはビデオゲームの環境で、エージェントはゲームをプレイすることで評価されます。これらの環境での実験結果は、人間のフィードバックを用いた学習が有効であることを示しています。
その他の議論としては、フィードバックの選択方法や、報酬関数の推定値の更新方法などが挙げられます。また、人間のフィードバックが一貫性を持つことの
(UsedChatWithPDF)
この研究の手法は、以下の3つのプロセスで構成されています。
ポリシーと報酬関数の推定値の維持: この研究では、時間ごとにポリシーと報酬関数の推定値を維持します。これらは深層ニューラルネットワークによってパラメータ化されています。
環境との相互作用: ポリシーは環境と相互作用し、一連の軌跡を生成します。ポリシーのパラメータは、伝統的な強化学習アルゴリズムによって更新され、予測される報酬の合計を最大化するように調整されます。
人間からのフィードバック: 軌跡からセグメントのペアを選択し、それらを人間に比較してもらいます。報酬関数の推定値のパラメータは、これまでに収集した人間からの比較にフィットするように、教師あり学習を通じて最適化されます。
これらのプロセスは非同期に実行され、軌跡はプロセス(1)からプロセス(2)へ、人間からの比較はプロセス(2)からプロセス(3)へ、そして報酬関数の推定値のパラメータはプロセス(3)からプロセス(1)へと流れます。
報酬を計算した後、伝統的な強化学習問題が残ります。この問題は、ドメインに適した任意のRLアルゴリズムを使用して解決することができます。報酬関数の推定値が非定常性を持つ可能性があるため、報酬関数の変化に対してロバストな方法を好む傾向があります。これは、ポリシーグラディエント法を選択する理由の一つであり、これらの方法はこのような問題に対して成功裏に適用されています。
具体的には、Atariゲームをプレイするためには、Advantage Actor-Critic (A2C)を使用し、シミュレートされたロボット工学のタスクを実行するためには、Trust Region Policy Optimization (TRPO)を使用します。
(つづけて)
(UsedChatWithPDF)
この研究の評価・検証は、MuJoCoとAtariの2つの環境で行われました。MuJoCoでは、人間のフィードバックを用いた方法(実際の人間のフィードバックと、報酬関数に基づく合成フィードバック)と、真の報酬関数を用いた強化学習とを比較しました。結果として、700のラベルを用いることで、ほぼすべてのタスクで強化学習と同等の結果を達成することができました。また、1400のラベルを用いると、真の報酬関数を用いた場合よりもわずかに良い結果を得ることができました。これは、学習された報酬関数がより良い形状を持つためと考えられます。
Atariでは、5500の人間の評価と、350、700、1400の合成評価、そして真の報酬関数を用いた強化学習とを比較しました。この環境では、強化学習と同等の結果を達成するのはより困難でしたが、それでもほとんどのゲームで学習が進んでいることが示されました。特に、BeamRiderとPongでは、3300の合成ラベルだけで強化学習と同等またはそれに近い結果を達成しました。
また、この研究では、人間のフィードバックが合成フィードバックと比較してどの程度効果的であるかも評価しました。結果として、人間のフィードバックは通常、合成フィードバックと同等またはそれよりわずかに劣る結果でした。しかし、一部のタスクでは、人間のフィードバックが合成フィードバックを大幅に上回る結果を示しました。これは、人間がロボットが「直立」する軌跡を好むように指示したためで、これは有用な報酬の形成となりました。
以上の結果から、人間のフィードバックを用いた学習は、真の報酬関数が利用できない状況でも有効であることが示されました。また、人間のフィードバックは、報酬関数の形状を改善する可能性があり、その結果、強化学習を上回る結果を達成する可能性があることも示されました。
(つづけて)
(UsedChatWithPDF)
この研究では、いくつかの課題や未来の研究方向が提起されています。
フィードバックの選択方法: 現在のフィードバックの選択方法は、報酬関数の不確実性の近似に基づいています。これは大まかな近似であり、一部のタスクでは実際にパフォーマンスを悪化させる可能性があります。理想的には、クエリの情報価値の期待値に基づいてクエリを選択することが望ましいですが、これは今後の研究でさらに探求する必要があります。
オフライン報酬予測器の訓練のパフォーマンス: オフライン報酬予測器の訓練では、占有分布の非定常性のために、予測器は真の報酬の一部しか捉えられず、この部分報酬を最大化することが、真の報酬によって測定される望ましくない奇妙な行動を引き起こす可能性があります。
フィードバックの収集: 現在のアプローチでは、フィードバックは訓練の初めにのみ収集されます。しかし、訓練を通じてフィードバックを継続的に収集することで、エージェントの学習が改善される可能性があります。
フィードバックの一貫性: 人間のフィードバックは一貫性が必要ですが、人間は一貫性を保つことが難しい場合があります。これは、エージェントの学習に影響を与える可能性があります。
複雑なタスクへの適用: この研究では、比較的単純なタスクに対して人間のフィードバックを用いた学習が行われました。しかし、より複雑なタスクに対してもこの手法を適用することが重要です。
これらの課題や未来の研究方向は、人間のフィードバックを用いた深層強化学習の研究を進める上で重要な指針となります。
まとめの内容については、まだ論文をちゃんと読んでいないですが、事前情報に近い結果が得られました。
注意
この記事を書くために何度かまとめを生成させましたが、そのたびに結果が大きく変わります。上記はその結果の一つです。
ChatGPT利用者には常識ですが、出力が長すぎると途中で途切れます。上記の場合でも2回「続けて」と継続回答してもらっています。また、結果をよく見ると、以下のように、途中で途切れる部分があります。プラグインが再活動し、別の話題に話題に移っています。これに関しては、そういうもんなんだなと思うしかないのでしょう。
その他の議論としては、フィードバックの選択方法や、報酬関数の推定値の更新方法などが挙げられます。また、人間のフィードバックが一貫性を持つことの
(UsedChatWithPDF)
この研究の手法は、以下の3つのプロセスで構成されています。
まとめ
ChatWithPDFを使うと、論文(PDF)の内容をChatGPTで扱えるようになります。研究会の準備のために使ってみましたが、発表できなかった人が発表できるようになる可能性があります。大筋はChatGPTで理解し、疑問点は人の目で確認するという使い方が有効かもしれません。
ただし、大学のゼミなどの発表で使用する際は、先生と相談することをお勧めします。安易に使うと、質問に対して適切に答えられない可能性があります。
今回、タイムリーな内に・・・と急いでこの記事を書いていて、あまり論文をちゃんと読んでいなかったりします。この論文をちゃんと読む以外にも 前情報のない論文・他ジャンルの論文・ページ数の多い論文で試したり、プロンプトを洗練するのもやりたいなと思います。
また、ChatGPTのAPI経由でも同様のことができると良いのですが、まだ調査していません。それぞれのプラグインの使い方を説明するページがあると、さらに便利になるでしょう。
以上、ChatGPTプラグインの一部を試してみた結果を報告しました。これからも新しい機能の発見や試用を続けていきますので、お楽しみに!
おまけ
この記事はchatGPTで下書きを作成しました(提案下書きにしたがうと、僕は最後の「これからも新しい機能の発見や試用を続けていきます」を実行しないといけないらしい)。
プロンプト
以下のような話の流れでQiitaに記事を投稿しようと思います。下書きを用意してください。
# イントロ
* 2023/5/12、ChatGPTのプラグインがお試しリリースされた(https://help.openai.com/en/articles/6825453-chatgpt-release-notes)
* plusユーザーから順に利用できるようになっているらしい
* ブラウザ拡張ではなくて、公式アプリの中の機能(画像を使って説明)
* 以前からもあったらしいが、waitlistに登録する必要があった。
* 2023/5/14時点の情報に基づく
# ChatGPTプラグインとは
* たくさんの候補の中から選べる(プラグイン選択画面で説明)
* どのように使うかを説明する(画像で説明)
* 食べログの例(画像)
# 論文を読ませよう
* ChatWithPDF
* 使い方の例(画像で説明)
* 注意点
* たまに内部エラーが出る
* なんどかリトライするといい?インストールしなおすといい?
# 勉強会の準備に使おう
* 機械学習名古屋研究会
* 論文を概要・新規性・手法・検証・その他議論の観点でまとめて発表
* 研究会の準備に使ってみよう
* 設定
* ○○の論文を読もうと思います。この論文は、RLHFの元ネタの論文らしい。
* 入力は「~」とした。
* 結果
* (画像)
* 課題
* 説明が途中で途切れる
# しめ
* ChatWithPDFを使うと論文(PDF)の内容をchatGPTで扱える
* 研究会の準備のために使ってみた。
* 準備時間が取れなくて、発表できなかった人が発表できるといいな(大筋はこれで理解して、あやしいところは人の目で見る)
* 大学のゼミとかの発表での使い方は先生と相談しましょう。安易に使うと、質問をされたときにちゃんと答えられないので注意
* まだやっていないこと・・・論文を読んでこのまとめの妥当性を検証するとか、まったく前情報のない論文や他ジャンルの論文で試すとか、プロンプトを工夫する
* chatGPTのAPI経由でもできるといいな(調べていない)
* それぞれのプラグインの使い方の説明ページができるといいな
それなりに修正したり、本編の「勉強会の準備に使おう」の部分は、後からほとんど自分で書いたりしましたが、2時間くらいでこの記事がかけました。何を書くかを整理→下書き生成→内容修正ってやり方で執筆も捗りそうですね。