目次
- 強化学習とは
- 環境
- 解決方法
- ハンズオン
強化学習とは
強化学習が扱う問題
変化する環境下で判断・行動し課題を解決する問題
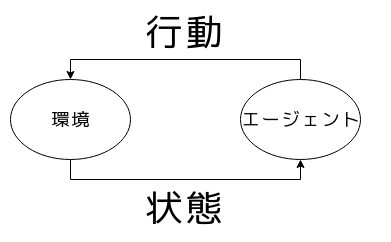
エージェントが環境の状態を見て行動をし、その行動により環境の状態が更新される。望む状態を目指す。
問題の例
- ゲーム
- 制御
- 広告
大抵の場合、リアルな環境かシミュレータで訓練をする。
強化学習の訓練方法
状態がどれくらい良いかを「報酬」として数値化して、より多くの報酬が得られるように訓練する。
例えば、
- 勝った → +1
- 負けた → -1
のように自分で決める。
環境
OpenAI gym
OpenAIのgymというライブラリが有名。
- いくつかの問題・ゲームのシミュレーション環境
- 統一されてたインターフェースを持つ
インターフェースが統一されていると、
- 自作の環境をgymの環境と同じように扱う拡張が可能
- 作ったモデルのコードが再利用できる(かも)
gymの環境の例
- 倒立振子
下の台を左右に動かして棒を倒れないようにする

gymの環境の例
- atari1(Space Invaders)
レトロなゲームもある。third party製のゲームもある。

gymでできること
- 環境のロード
- 環境から状態・報酬を取り出す
- 環境に行動を反映させる
解決方法
価値関数を用いて
強化学習のタスクでは、それぞれの状態に対して良い行動が導ければよい。
例えば、
状態$s$に対して行動$a$がどれだけ良いかを意味する価値関数$F(s, a)$を作る。それぞれの状態で$F$を最大にする行動を取る。
という方法が考えられる。
価値関数が上手く作れれば勝ち
Q学習
報酬がどれだけ貰えそうかを表す関数を使うと良さそう。
しかし、次もらえる報酬を予測するだけだと、次の次で失敗する可能性がある。
ある行動を取ったときに、その後最善を尽くしたとして、将来に渡って得られそうな最大の報酬を予想する。→ Q学習
累積報酬
将来得られそうなトータルの報酬を割引累積報酬で表現する。
なんらかの行動を行い続けたときに、順に$r_0,r_1,\dots$ という報酬が得られたとする。割引率$\gamma \in [0, 1)$に対して、
\begin{align}
R &= \sum_{t} \gamma^{t} r_{t} \\
&= r_0 + \gamma r_1 + \gamma^2 r_2 + \dots
\end{align}
を割引累積報酬という。
Q学習
状態$s$と行動$a$に対して、
Q^*(s, a) = \text{状態$s$で行動$a$をとったときの割引累積報酬の最大値}
を考え、それぞれの状態でこれが最大となる行動を選ぶ。
$Q$学習では、この関数$Q^*$を機械学習で作る。
*実際は確率が絡むから割引累積報酬の期待値の最大値とかに
Bellman equation
$Q^*$を前の式で計算するのは現実的ではない。$T$を大きくすると組合せが急激に増える。上手く言い換える必要がある。
Bellman equation
Q^*(s,a) = \mathbb{E}_{s'}\left[r+\gamma \max_{a'}Q^*(s', a') \right]
ただし、$s'$は状態$s$から行動$a$をとった次の状態で、確率が絡む場合を含めて考えている。
この等式を使って、右辺を予想するような訓練をする。これで訓練した$Q^*$を価値関数として使う。
ハンズオン
準備
ソースコード: https://github.com/n-kats/MLN_201804
今回のハンズオンは、gymのGUIを含むためdockerよりホストか仮想環境ですることをおすすめします。
依存ライブラリの詳細はconnpassを参照してください。
dockerを使う人は、sh launch.shのように起動スクリプトを実行して、dockerコンテナ内でpythonコマンドなど実行してください。
以下では、pythonコマンドがpython3.5以上を指すとします。
gymを動かす
とりあえず、gymを動かしてみましょう。
$ python sample_01_run_gym.py
をします。ちゃんとセットアップできていてば、ウィンドウが現れてなにか動くと思います。
dockerの場合は反応が無くて、しばらくして終了するかと思います。
gymの使い方(環境との通信)
env = gym.make(env_name) # 環境呼び出し
env.reset() # 初期化 状態を取得
env.render() # 可視化
env.step(action) # 行動を行う 状態・報酬などを取得
env.close() # 終了
動画として保存
そのままでは、dockerの場合が何も表示されない・・・
gymには最新のものを動画に残す機能がある。
$ python sample_02_write_movie.py
今度は_output/に動画が出力されます。dockerの外に出力されるので、ホスト側で動画を再生することができます。
(*すぐ倒れて動画が終わっちゃう)
gym.Monitor
gymの環境はgym.Envで定義されたインターフェースに従っている。
つまり、stepとかrender等を実装したもの。
逆に、こうれらがあればgymの環境のように使える。
その一例がgym.Monitorで、環境をラップした環境が作る。これを使うと動画として書き出せる。
gymのインターフェース(行動)
env.action_spaceにその環境で取れる行動の型が定義されている。
倒立振子(CartPole-V0)の場合Discrete(2)で、0か1の離散値で行動を表現するという意味になる。
- 0のとき、台を左へ移動
- 1のとき、台を右へ移動
という意味になる。
gymのwikiに他の環境についてもまとめてある。
action_spaceを見る用にsample_03_print_values.py
を用意したので、適当にいじってみてください。
gymのインターフェース(状態)
env.resetやenv.stepの返り値として状態が返ってくる。
gymではこれをobservationと呼んでいる。
倒立振子の場合、長さ4の配列で、
- 台の位置
- 台の速度
- ポールの角度
- ポールの速度
のような内容になっている。
env.resetではその返り値として、env.stepでは返り値がtupleでその一つとして返ってくる。
env.stepの返り値
env.stepは4つの要素からなるtupleを返す。
順に、
- 状態(observation)
- 報酬
- 終了したか(bool)
- メタ情報
を意味する。
ランダムに動かす
インターフェースが分かったので、とりあえず、ランダムに動かして見ましょう。
$ python sample_04_random_agent.py
をするとランダムに動きます。action_space.sample()でランダムな行動を取得することができます。
このスクリプトでは、Agent.actで状態に対して行動を返すということをしています。
エージェントを作る
ランダムだとつまらないので、適当に価値関数を作ってそれに従って行動するエージェントを作ってみましょう。
サンプルとして、台やポールの位置・速度に重さをつけて足しただけの価値関数を作ってみました。
$ python sample_05_handmade_agent.py
これを実行するとその価値関数で動作し、何ステップ続いたかが表示されます。
実は、思いの外上手く行って、強化学習の方が良くならなくて苦労した・・・
ChainerRLを使って強化学習
ChainerRLは、Chainer製の強化学習用のライブラリ
- gymのインターフェースに特化
- 最新のDQN系手法が実装されている
今回は、ChainerRLのサンプルをちょっといじったものを用意しました。
$ python sample_06_chainer_rl_agent.py
モデルの内容
- DQN
deep learningで$Q^*$を近似する - $\varepsilon$-greedy法
訓練用の事例をたまにランラム行動させて作る - experience replay
訓練用の事例を貯めて偏るのを避ける
といった手法を使っている。
ハンズオン
- gymがどういうインターフェースかを確認する
- 価値関数を自作する
- ChainerRLを使った訓練をしてみる
のようなことに取り組んでみてください