はじめに
年末ちょっと時間ができた(?)ので,なでしこで簡単なニューラルネットワークを書いてみました.
自分はちゃんと読んでないのですが,ゼロから作る Deep Learning的な感じでライブラリ使わずに誤差逆伝播法による学習を再確認するような気持ちです.あと一年一本くらいはなでしこの記事を書いておきたかった
急いで雑に書いたので間違いなどあるかもしれません,なにかお気づきの際はご指摘いただければ.
前回のなでしこ記事: 「サイゼリヤで1000円あれば最大何kcal摂れるのか」をなでしこでDPで解いてみた。
なでしことは
日本語プログラミング言語.相変わらずv1の方を使います.
https://nadesi.com/top/
データセット
Iris flower (Fisher's Iris) データセットを使います.アヤメの種類を当てるデータセットで,scikit-learnなどで簡単に利用できるのでよく練習に使われています.が,今回はなでしこなので自分でダウンロードしてきます.
ダウンロード
ダウンロードデータセットパス=母艦パス&「iris_raw.csv」
保存データセットパス=母艦パス&「iris.csv」
「https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data」をダウンロードデータセットパスへHTTPダウンロード
データセット=ダウンロードデータセットパスを読んでCSV取得
データセット転置=データセットの表行列交換
ラベル一覧=データセット転置[4]の0を表重複削除
ラベルインデックスとはハッシュ
インデックス=0
ラベル一覧を反復
もし,それが空ならば,続ける
ラベルインデックス@それ=インデックス
インデックス=インデックス+1
保存データセットは空
データセットを反復
もし,それ[4]が空ならば,続ける
追加行=「{それ[0]},{それ[1]},{それ[2]},{それ[3]},{ラベルインデックス@(それ[4])}{~}」
保存データセット=保存データセット&追加行
保存データセットを保存データセットパスに保存
終わり
なぜかQiitaになでしこのシンタックスハイライトがないのでちょっと見づらいですが勘弁・・・.
HTTPダウンロード命令があるのでダウンロードは簡単です.CSV読むのも一瞬.
趣味ですが保存時点で花の種類を示すラベル(setosa, versicolor, versinica)を数値に変換しています.なでしこでは辞書型をハッシュと呼んでおり,「@」でアクセスできます.
訓練データとテストデータの分離
データセットパス=母艦パス&「iris.csv」
訓練データセットパス=母艦パス&「iris_train.csv」
テストデータセットパス=母艦パス&「iris_test.csv」
データセット=データセットパスを開く
データセットを配列シャッフル
テストデータ割合=0.1
テストデータ数=(データセットの要素数)*テストデータ割合を切り上げ
訓練データ数=データセットの要素数-テストデータ数
訓練データは空
データ番号で0から訓練データ数-1まで繰り返す
訓練データにデータセット[データ番号]を配列追加
訓練データを訓練データセットパスに保存
テストデータは空
データ番号で訓練データ数からデータセットの要素数-1まで繰り返す
テストデータにデータセット[データ番号]を配列追加
テストデータをテストデータセットパスに保存
終わり
上でダウンロードしたデータセットを訓練データセットとテストデータセットに分離します.
特筆するようなことはしていないですし,なにせ日本語なので何をやっているかは一目瞭然です.なでしこはいいぞ.
ニューラルネットワークの実装
三層のネットワークを実装します.入力は4次元,出力は3クラスのクラス確率とします.
ネットワーク構造は入力→アフィン変換→活性化関数(ハイパボリックタンジェント)→アフィン変換→ソフトマックス→出力として,交差エントロピーをロス関数としてクラス分類問題を学習します.
行列操作する関数の準備
もちろんなでしこに行列演算なんでありませんので,自前で実装していきます.二次元配列はあるので二次元配列を行列と思って操作します.表xxx命令は一次元は配列も列数が1の行列として解釈してくれるので,ベクトル用に関数を書き直す必要はありません.
まずは変数の初期化.
●ゼロ初期化(入力次元数,出力次元数で)
出力行列は空
着目行で0から(出力次元数-1)まで繰り返す
着目列で0から(入力次元数-1)まで繰り返す
出力行列[着目行,着目列]=0
出力行列で戻る
●Xavier初期化(入力次元数,出力次元数で)
乱数範囲=(6の平方根)/((入力次元数+出力次元数)の平方根)
出力行列は空
出力次元数回
現在行は空
入力次元数回
現在行に(((16384の乱数)/16383)-0.5)*乱数範囲*2を配列追加
出力行列に現在行を配列追加
出力行列で戻る
乱数で初期化したいのですが,たしかなでしこでは整数乱数しか生成出来ない(「Nの乱数」命令)のでごまかしています.
まさかなでしこもXavier初期化なんて命令を実装されるとは思っていなかったでしょうね.
次に行列同士・行列とスカラーの演算です.定義通り処理します.
●行列和(バイアス行列と入力行列の)
もし,(入力行列の表行数)=(バイアス行列の表行数)でなければ,「行列サイズ不一致.{入力行列の表行数}, {バイアス行列の表行数}」でエラー発生
もし,(入力行列の表列数)=(バイアス行列の表列数)でなければ,「行列サイズ不一致.{入力行列の表列数}, {バイアス行列の表列数}」でエラー発生
出力行列は空
着目行で0から(入力行列の表行数-1)まで繰り返す
着目列で0から(入力行列の表列数-1)まで繰り返す
出力行列[着目行,着目列]=入力行列[着目行,着目列]+バイアス行列[着目行,着目列]
出力行列で戻る
●行列積(重み行列と入力行列の)
もし,(入力行列の表行数)=(重み行列の表列数)でなければ,「行列サイズ不一致.{入力行列の表行数}, {重み行列の表列数}」でエラー発生
出力行列は空
着目行で0から(重み行列の表行数-1)まで繰り返す
着目列で0から(入力行列の表列数-1)まで繰り返す
出力行列[着目行,着目列]=0
(重み行列の表列数)回
出力行列[着目行,着目列]=出力行列[着目行,着目列]+重み行列[着目行,回数-1]*入力行列[回数-1,着目列]
出力行列で戻る
●行列定数倍(係数で入力行列を)
出力行列は空
着目行で0から(入力行列の表行数-1)まで繰り返す
着目列で0から(入力行列の表列数-1)まで繰り返す
出力行列[着目行,着目列]=係数*入力行列[着目行,着目列]
出力行列で戻る
一応簡単な行列サイズチェックはしています,漏れもあるかも.Pythonでのnumpy相当の部分まで自分で書くのでゼロから作っている気分です.
たとえば行列積は三重ループだなーみたいなことが実装しながらわかるので,ナイーブに実装すると計算量が $O(N^3)$ だなぁという実感がわきます.(Strassen algorithmなどいろいろ計算量を下げるアルゴリズムはあるらしいのですが,自分は全然詳しくないので略)
ニューラルネットワークっぽい話と関数の実装
ここからはニューラルネットワークっぽい&クラス分類っぽい関数です.誤差逆伝播法を利用する前提で,各関数の微分も実装していきます.以下ではちょっと数式を書きますが,全体にお気持ち数式なので察してください.
誤差逆伝播法では学習するパラメータについて最急降下法などの勾配を利用した手法で更新します.今回の記事では最もシンプルな手法である 確率的勾配降下法 (SGD) を利用します.実装が楽なので.(ちゃんとした深層学習ではAdamなどの,より学習が速かったり学習率にロバストだったりする手法が用いられる場合が多いです)
確率的勾配降下法についての詳細も省略しますが,一言で書くとランダムに選択したミニバッチによる最急降下法です.一応お気持ち数式を書いておくと学習するパラメータを$w$としたとき,
$$
w \leftarrow w - \alpha \frac{\partial y}{\partial w}
$$
で更新します.したがって出力での誤差に対応する各パラメータの微分値が必要です.(このとき各パラメータについて解析的に導関数を計算しておく必要があるわけではなく,微分値がわかっていればOKです)
この微分値を得るため,chain ruleによって出力からの誤差を各層に伝播させていきます.詳しい解説は教科書などを読んでください.これによって,各関数の微分を実装しておけば学習するパラメータを確率的勾配降下法で更新できるので学習することができるということになります.
ちょっと行儀はわるいのですが,今回はその部分の微分値を返すのではなく,下層の誤差と掛けた後の値(=出力に対する各層の微分値)を返すような関数として関数の微分を実装していきます.
ソフトマックス
$x_i$のような下付き文字をベクトル$x$の第$i$要素として,ソフトマックスとその微分は
y_i = \frac{\exp(x_i)}{\sum_k \exp(x_k)}
\frac{\partial y_j}{\partial x_i} =
\left\{
\begin{array}{ll}
(1-y_i) y_i & (i = j) \\
-y_i y_j & (i \neq j)
\end{array}
\right.
です.実装します.
●ソフトマックス(入力ベクトルの)
もし,入力ベクトルの表列数が1でなければ,「行列サイズエラー.」でエラー発生
正規化定数=0
入力ベクトルで反復
正規化定数=正規化定数+EXP(それ)
出力ベクトルは空
入力ベクトルで反復
EXP(それ)/正規化定数を出力ベクトルに配列追加
出力ベクトルで戻る
●ソフトマックス微分(出力ベクトルと誤差ベクトルの)
もし,出力ベクトルの表列数が1でなければ,「行列サイズエラー.」でエラー発生
もし,誤差ベクトルの表列数が1でなければ,「行列サイズエラー.」でエラー発生
微分ベクトルは空
着目行で0から(出力ベクトルの表行数-1)まで繰り返す
微分ベクトル[着目行]=0
着目列で0から(出力ベクトルの表行数-1)まで繰り返す
もし,着目行が着目列ならば
微分ベクトル[着目行]=微分ベクトル[着目行]+出力ベクトル[着目行]*(1-出力ベクトル[着目列])*誤差ベクトル[着目列]
違えば
微分ベクトル[着目行]=微分ベクトル[着目行]-出力ベクトル[着目行]*出力ベクトル[着目列]*誤差ベクトル[着目列]
微分ベクトルで戻る
交差エントロピー
前層までの出力がクラス確率であると考えて,交差エントロピーによって正解との比較をします.定義を考えると$x$が出力,$\hat{x}$が正解(one-hot vector)として
y = -\sum_i {\hat{x}_i \log(x_i)}
です.もちろん定義通り計算してもよいですが,今回は $\hat{x}$ がone-hotなので正解ラベル以外はゼロになるため,正解ラベルの要素だけを考えれば良いです.
y = -\log(x_k) (kは正解ラベル)
微分も同様に正解ラベルだけ考えればOKです.
\frac{\partial y}{\partial x_i} = -\frac{1}{x_k} (kは正解ラベル)
●交差エントロピー(入力ベクトルと正解ラベルの)
もし,入力ベクトルの表列数が1でなければ,「行列サイズエラー.」でエラー発生
出力値=-((入力ベクトル[正解ラベル]+0.000000001)の自然対数)
出力値で戻る
●交差エントロピー微分(入力ベクトルと正解ラベルの)
もし,入力ベクトルの表列数が1でなければ,「行列サイズエラー.」でエラー発生
微分ベクトルは空
(入力ベクトルの表行数)回
微分ベクトルに0を配列追加
微分ベクトル[正解ラベル]=-1/入力ベクトル[正解ラベル]
微分ベクトルで戻る
アフィン変換
y=Ax+b
ここで重み $A$ とバイアス $b$ を学習するため,入出力にくわえてこれらについての微分も考えます.
\frac{\partial y}{\partial x} = A^\top
\frac{\partial y}{\partial A} = x^\top
\frac{\partial y}{\partial b} = I
Iは単位行列です.実装するとこんな感じです.
●アフィン変換(重み行列,バイアスベクトルで入力ベクトルを)
もし,(入力ベクトルの表行数)=(重み行列の表列数)でなければ,「行列サイズ不一致.{入力ベクトルの表行数}, {重み行列の表列数}」でエラー発生
もし,(重み行列の表行数)=(バイアスベクトルの表行数)でなければ,「行列サイズ不一致.{重み行列の表行数}, {バイアスベクトルの表行数}」でエラー発生
もし,入力ベクトルの表列数が1でなければ,「行列サイズエラー.」でエラー発生
もし,バイアスベクトルの表列数が1でなければ,「行列サイズエラー.」でエラー発生
出力ベクトルは空
着目行で0から(重み行列の表行数-1)まで繰り返す
出力ベクトル[着目行]=バイアスベクトル[着目行]
着目列で0から(重み行列の表列数-1)まで繰り返す
出力ベクトル[着目行]=出力ベクトル[着目行]+重み行列[着目行,着目列]*入力ベクトル[着目列]
出力ベクトルで戻る
●アフィン変換バイアスベクトル微分(誤差ベクトルの)
もし,誤差ベクトルの表列数が1でなければ,「行列サイズエラー.」でエラー発生
誤差ベクトルで戻る
●アフィン変換重み行列微分(入力ベクトルと誤差ベクトルの)
もし,入力ベクトルの表列数が1でなければ,「行列サイズエラー.」でエラー発生
もし,誤差ベクトルの表列数が1でなければ,「行列サイズエラー.」でエラー発生
誤差ベクトルと(入力ベクトルの表行列交換)の行列積で戻る
●アフィン変換入力ベクトル微分(重み行列と誤差ベクトルの)
もし,(重み行列の表行数)=(誤差ベクトルの表行数)でなければ,「行列サイズ不一致.{重み行列の表行数}, {誤差ベクトルの表行数}」でエラー発生
もし,誤差ベクトルの表列数が1でなければ,「行列サイズエラー.」でエラー発生
(重み行列の表行列交換)と誤差ベクトルの行列積で戻る
なでしこではタプルを返せないので,それぞれの微分値を返す関数を分けています.
ハイパボリックタンジェント
中間層での活性化関数としてハイパボリックタンジェントを使います,これは要素ごとの演算なので実装も楽ですね.数式でも添字を省略します.
y = \frac{\exp(x) - \exp(-x)}{\exp(x) + \exp(-x)}
\frac{\partial y}{\partial x} = \frac{4}{(\exp(x) + \exp(-x))^2}
●ハイパボリックタンジェント(入力ベクトルの)
もし,入力ベクトルの表列数が1でなければ,「行列サイズエラー.」でエラー発生
出力ベクトルは空
着目行で0から(入力ベクトルの表行数-1)まで繰り返す
出力ベクトル[着目行]=(EXP(入力ベクトル[着目行])-EXP(-入力ベクトル[着目行]))/(EXP(入力ベクトル[着目行])+EXP(-入力ベクトル[着目行]))
出力ベクトルで戻る
●ハイパボリックタンジェント微分(入力ベクトルと誤差ベクトルの)
もし,(入力ベクトルの表行数)=(誤差ベクトルの表行数)でなければ,「行列サイズ不一致.{入力ベクトルの表行数}, {誤差ベクトルの表行数}」でエラー発生
もし,入力ベクトルの表列数が1でなければ,「行列サイズエラー.」でエラー発生
もし,誤差ベクトルの表列数が1でなければ,「行列サイズエラー.」でエラー発生
微分ベクトルは空
着目行で0から(誤差ベクトルの表行数-1)まで繰り返す
微分ベクトル[着目行]=4*誤差ベクトル[着目行]/((EXP(入力ベクトル[着目行])+EXP(-入力ベクトル[着目行]))の2乗)
微分ベクトルで戻る
GUI周り
この辺はなでしこだとほんと楽ですね.
!母艦設計=『母艦の可視はオフ。』
進行度バーとはプログレスバー
進行度バーについて
レイアウトは「上」
高さは32
ログメモとはメモ
ログメモについて
レイアウトは「全体」
母艦の可視はオン
データセットの読み込みと初期化
特筆することはないです,なでしこだとなにをやっているかは一目瞭然なので.
訓練データセットパス=母艦パス&「iris_train.csv」
訓練データセット=訓練データセットパスを開く
テストデータセットパス=母艦パス&「iris_test.csv」
テストデータセット=テストデータセットパスを開く
入力次元数=4
クラス数=3
中間層次元数=12
ミニバッチサイズ=32
訓練データセットサイズ=訓練データセットの要素数
テストデータセットサイズ=テストデータセットの要素数
学習率=0.01
エポック数=1000
進行度バーの最大値はエポック数-1
学習ループ
一層目重み行列=入力次元数,中間層次元数でXavier初期化
一層目バイアスベクトル=1,中間層次元数でXavier初期化
二層目重み行列=中間層次元数,クラス数でXavier初期化
二層目バイアスベクトル=1,クラス数でXavier初期化
エポックで0からエポック数-1まで繰り返す
進行度バーの値=エポック
今エポックデータセット=訓練データセット
今エポックデータセットを配列シャッフル
今エポック訓練ロス総和=0
今エポック訓練正解数=0
ミニバッチ番号で0から((訓練データセットサイズ/ミニバッチサイズ)を切り下げ)まで繰り返す
ミニバッチ開始エントリ番号=ミニバッチ番号*ミニバッチサイズ
ミニバッチ終了エントリ番号=ミニバッチ番号*ミニバッチサイズ+ミニバッチサイズ-1
もし,ミニバッチ終了エントリ番号が訓練データセットサイズ以上ならば,ミニバッチ終了エントリ番号=訓練データセットサイズ-1
今ミニバッチサイズ=ミニバッチ終了エントリ番号-ミニバッチ開始エントリ番号
一層目重み行列誤差総和=入力次元数,中間層次元数でゼロ初期化
一層目バイアスベクトル誤差総和=1,中間層次元数でゼロ初期化
二層目重み行列誤差総和=中間層次元数,クラス数でゼロ初期化
二層目バイアスベクトル誤差総和=1,クラス数でゼロ初期化
エントリ番号でミニバッチ開始エントリ番号からミニバッチ終了エントリ番号まで繰り返す
処理中データ=今エポックデータセット[エントリ番号]
入力ベクトルは空
入力次元数回
入力ベクトルに処理中データ[回数-1]を配列追加
正解ラベルは処理中データ[入力次元数]
中間層入力ベクトル=一層目重み行列,一層目バイアスベクトルで入力ベクトルをアフィン変換
中間層出力ベクトル=中間層入力ベクトルのハイパボリックタンジェント
推定ベクトル=二層目重み行列,二層目バイアスベクトルで中間層出力ベクトルをアフィン変換
推定確率分布=推定ベクトルのソフトマックス
ロス=推定確率分布と正解ラベルの交差エントロピー
今エポック訓練ロス総和=今エポック訓練ロス総和+ロス
推定確率最大値=推定確率分布[0]
推定ラベル=0
着目行で1から推定確率分布の要素数-1まで繰り返す
もし,推定確率分布[着目行]>推定確率最大値ならば
推定確率最大値=推定確率分布[着目行]
推定ラベル=着目行
もし,推定ラベルが正解ラベルならば
今エポック訓練正解数=今エポック訓練正解数+1
推定確率分布誤差=推定確率分布と正解ラベルの交差エントロピー微分
推定ベクトル誤差=推定確率分布と推定確率分布誤差のソフトマックス微分
二層目バイアスベクトル誤差=推定ベクトル誤差のアフィン変換バイアスベクトル微分
二層目重み行列誤差=中間層出力ベクトルと推定ベクトル誤差のアフィン変換重み行列微分
中間層出力ベクトル誤差=二層目重み行列と推定ベクトル誤差のアフィン変換入力ベクトル微分
中間層入力ベクトル誤差=中間層入力ベクトルと中間層出力ベクトル誤差のハイパボリックタンジェント微分
一層目バイアスベクトル誤差=中間層入力ベクトル誤差のアフィン変換バイアスベクトル微分
一層目重み行列誤差=入力ベクトルと中間層入力ベクトル誤差のアフィン変換重み行列微分
一層目重み行列誤差総和=一層目重み行列誤差総和と一層目重み行列誤差の行列和
一層目バイアスベクトル誤差総和=一層目バイアスベクトル誤差総和と一層目バイアスベクトル誤差の行列和
二層目重み行列誤差総和=二層目重み行列誤差総和と二層目重み行列誤差の行列和
二層目バイアスベクトル誤差総和=二層目バイアスベクトル誤差総和と二層目バイアスベクトル誤差の行列和
一層目重み行列更新量=-(学習率/今ミニバッチサイズ)で一層目重み行列誤差総和を行列定数倍
一層目バイアスベクトル更新量=-(学習率/今ミニバッチサイズ)で一層目バイアスベクトル誤差総和を行列定数倍
二層目重み行列更新量=-(学習率/今ミニバッチサイズ)で二層目重み行列誤差総和を行列定数倍
二層目バイアスベクトル更新量=-(学習率/今ミニバッチサイズ)で二層目バイアスベクトル誤差総和を行列定数倍
一層目重み行列=一層目重み行列と一層目重み行列更新量の行列和
一層目バイアスベクトル=一層目バイアスベクトルと一層目バイアスベクトル更新量の行列和
二層目重み行列=二層目重み行列と二層目重み行列更新量の行列和
二層目バイアスベクトル=二層目バイアスベクトルと二層目バイアスベクトル更新量の行列和
今エポックテストロス総和=0
今エポックテスト正解数=0
エントリ番号で0からテストデータセットサイズ-1まで繰り返す
処理中データ=テストデータセット[エントリ番号]
入力ベクトルは空
入力次元数回
入力ベクトルに処理中データ[回数-1]を配列追加
正解ラベルは処理中データ[入力次元数]
中間層入力ベクトル=一層目重み行列,一層目バイアスベクトルで入力ベクトルをアフィン変換
中間層出力ベクトル=中間層入力ベクトルのハイパボリックタンジェント
推定ベクトル=二層目重み行列,二層目バイアスベクトルで中間層出力ベクトルをアフィン変換
推定確率分布=推定ベクトルのソフトマックス
ロス=推定確率分布と正解ラベルの交差エントロピー
今エポックテストロス総和=今エポックロステスト総和+ロス
推定確率最大値=推定確率分布[0]
推定ラベル=0
着目行で1から推定確率分布の要素数-1まで繰り返す
もし,推定確率分布[着目行]>推定確率最大値ならば
推定確率最大値=推定確率分布[着目行]
推定ラベル=着目行
もし,推定ラベルが正解ラベルならば
今エポックテスト正解数=今エポックテスト正解数+1
ログメモ=「訓練ロス:{(今エポック訓練ロス総和/訓練データセットサイズ)を"%.7f"で形式指定}, 」&
「訓練正解率:{(今エポック訓練正解数/訓練データセットサイズ)を"%.4f"で形式指定}, 」&
「テストロス:{(今エポックテストロス総和/テストデータセットサイズ)を"%.7f"で形式指定}, 」&
「テスト正解率:{(今エポックテスト正解数/テストデータセットサイズ)を"%.4f"で形式指定}」&改行&ログメモ
母艦=「{エポック} / {エポック数}」
エポックごとに配列シャッフルして,ちゃんと確率的勾配降下法になるようにしています.学習データセットでロスを求めた後にネットワークを遡るように誤差を伝播させていき,各層での誤差を求めてパラメータを更新します.今回学習するパラメータは各層の重み行列とバイアスベクトスなので,これらについての誤差に学習率を掛けて更新しています.
テストデータについては逆伝播の計算はせず,ロスと正解率のみ求めています.
そういえば,なでしこには配列中の最大値を求める関数はあるのですが,そのインデックスを返す関数はなかったので自前で書きました.
結果
学習序盤はこんな感じ.
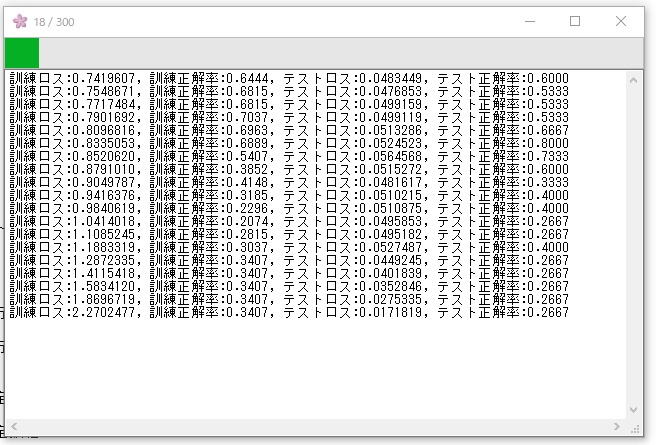
300エポック終了.

300エポック回して,訓練ロス:0.1902501, 訓練正解率:0.9778, テストロス:0.0138244, テスト正解率:1.0000でした.まぁ簡単な問題なのでこんな感じ.
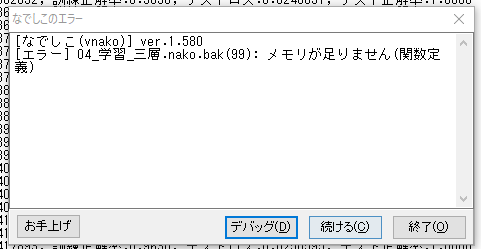
次はMNISTでもやろうかと思ったのですが,どっかでメモリリークしているっぽく(&32bitアプリケーションのためメモリをフルで使えさなそう),メモリ不足が起きてしまうので断念しました.
結論
ニューラルネットワークをなでしこで書くのはしんどい.便利なライブラリ使いましょう.
こんなん日本語でも何やってるか分からん!的なことを期待してたのですが,なでしこDPに比べると思ったより読みやすい気がします.