はじめに
Sparkの学習をするにあたり、DatabricksでApache Spark Python (PySpark) DataFrame APIを使用して、基本的なDataFrameの操作をしてみました。
操作するにあたり、以下のDatabricksのチュートリアルを参考に実施しました。
https://docs.databricks.com/aws/ja/getting-started/dataframes
本記事では、試してみた操作を実際のコードとともに説明します。
DataFrameとは
Sparkにおいて、DataFrameは名前付きの列で構成された分散データの集合です。概念的には、リレーショナルデータベースのテーブルやR/Pythonのデータフレームに相当しますが、内部的にはより高度な最適化が施されています。
DataFrameは、以下のようなさまざまなデータソースから構築できます:
・構造化データファイル(CSV、JSONなど)
・Hiveのテーブル
・外部データベース
・既存のRDD(Resilient Distributed Dataset)
基本的なDataFrameの操作
ここからは、PySparkというSparkを実行するためのPython APIを使用した、DataFrameの操作をいくつか紹介します。
DataFrameの作成
手動で作成する方法
データとカラム名を定義し、createDataFrameで作成します。
data = [[2021, "test", "Albany", "M", 42]]
columns = ["Year", "First_Name", "County", "Sex", "Count"]
df1 = spark.createDataFrame(data, schema="Year int, First_Name STRING, County STRING, Sex STRING, Count int")
PySparkSQLを使用する方法
PySparkSQLは、膨大な量の構造化・半構造化データにSQLライクな分析を行うPySparkライブラリです。PySparkSQLのspark.sql()を使用してSQLクエリを実行することができます。
ここでは、事前にDatabricksのカタログに作成しておいたテーブルから全件を取得し、そのデータをDataFrameとして格納しています。
df2 = spark.sql("SELECT * FROM {workspace_name}.{schema_name}.{table_name}")
DataFrameの表示
showまたはdisplayでDataFrameを表示します。
displayの方が、よりグラフィカルに結果を表示することができます。
df1.show()
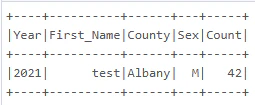
display(df1)

スキーマの表示
printSchemaでDataFrameのスキーマを表示します。
df2.printSchema()

カラム名の変更
withColumnRenamedでDataFrameのカラム名を変更します。
ここでは、カラム名を"First Name"から"First_Name"に変更しています。
df2 = df2.withColumnRenamed("First Name", "First_Name")
df2.printSchema()

DataFrameの結合
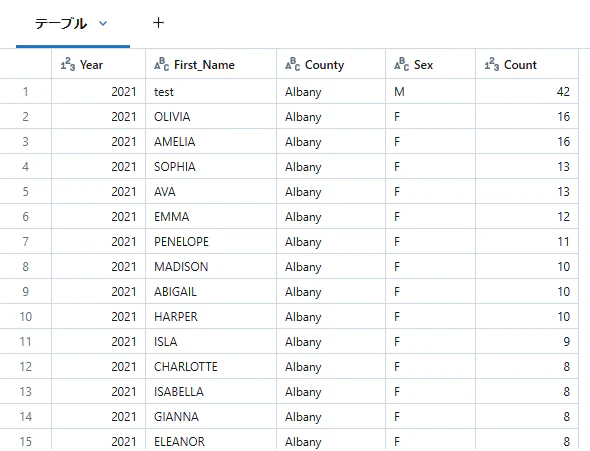
unionでDataFrameを結合します。
ここでは、「DataFrameの作成」で作成した2つのDataFrameを結合しています。
1行目にdf1のデータが追加されてることを確認できました。
df3 = df1.union(df2)
display(df3)
フィルタリング
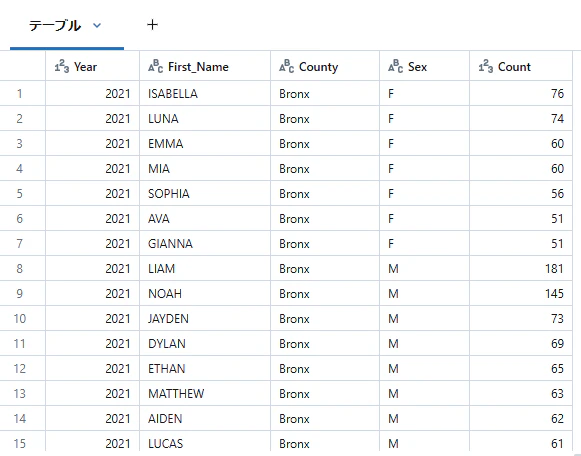
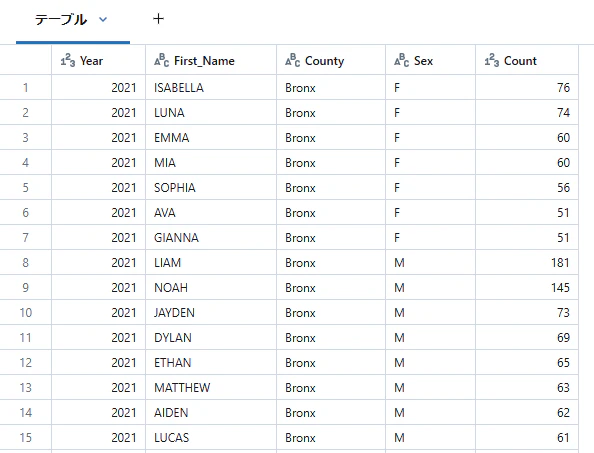
filterまたはwhereでDataFrameの行をフィルタリングします。
(filterとwhereでパフォーマンスや構文に違いはありません。)
ここでは、"Count"カラムが50より大きいレコードでフィルタリングしています。
display(df3.filter(df3["Count"] > 50))
display(df3.where(df3["Count"] > 50))
カラムの選択とソート
selectでDataFrameから取得するカラムを指定します。
また、orderbyおよびdescでソートします。
ここでは、DataFrameから"First_Name"と"Count"カラムを選択し、"Count"カラムの降順でソートしています。
display(df2.select("First_Name", "Count").orderBy(desc("Count")))
DataFrameのサブセットの作成
既存のDataFrameから新しいDataFrame(サブセット)を作成します。
ここでは、filterやselectを使用して既存のDataFrameからデータを取得し、新しいDataFrameとして格納しています。
subsetDF = df3.filter((df3["Year"] == 2009) & (df3["Count"] > 100) & (df3["Sex"] == "F")).select("First_Name", "County", "Count").orderBy(desc("Count"))
display(subsetDF)

DataFrameをテーブルとして保存
saveAsTableでDataFrameをテーブルとして保存します。
ここでは、「DataFrameのサブセットの作成」で作成したDataFrameを、保存するパスやテーブル名を指定して、保存しています。
subsetDF.write.saveAsTable("{workspace_name}.{schema_name}.{table_name}")
おわりに
シンプルな操作が多く、初心者でもDataFrameの操作の感触を掴むことができました。
今回試したのはほんの一部なので、今後はさらに実践を重ねることで、より複雑なデータ処理にも挑戦していきたいと思います。
関連記事