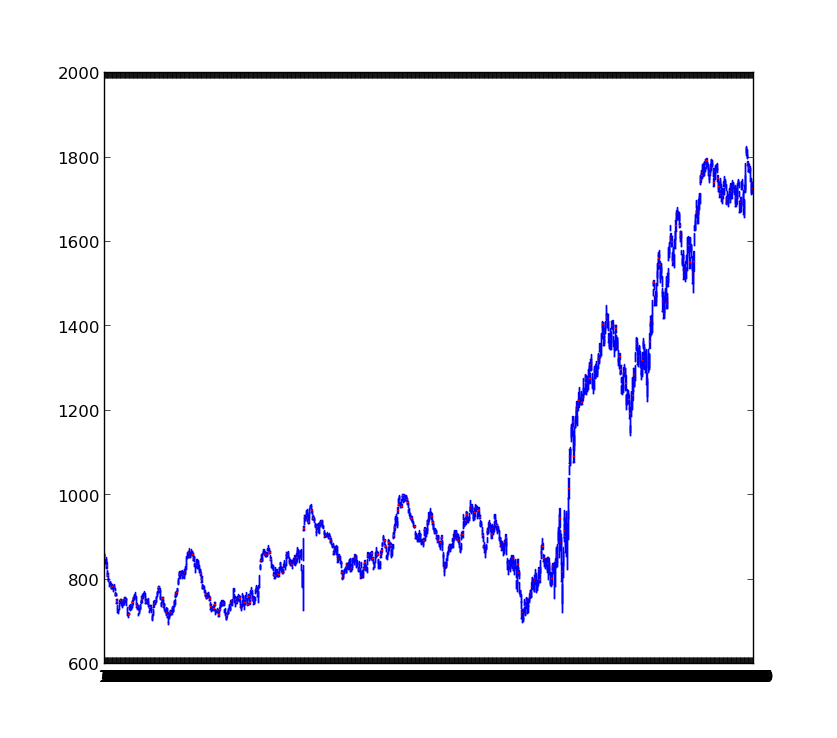
何をするのか
Yahoo ファイナンス の TOPIX の時系列をプロットして経済の変化を観察してみる
何のパッケージを使うのか
urllib2
http のリクエストを出して html を得る
urllib2.urlopen(url).read()
lxml
xml, html のパーサ
変数 html に 次のような html の文字列が入っているとすると
<table>
<tr><td>aa</td><td>bb</td></tr>
<tr><td>aa</td><td>bb</td></tr>
<tr><td>aa</td><td>bb</td></tr>
</tr>
次のようなコードで全部 td の中身を表示できる。
root = lxml.html.fromstring(html)
root.xpath("//table")
for tr in root.xpath("descendant::tr"):
for td in root.xpath("descendant::td"):
print td
コード
import pylab
import urllib2
import lxml
import lxml.html
import re
dateFr = {"year": 2000, "month":1, "day":1}
dateTo = {"year": 2013, "month":11, "day": 1}
data = []
for page in range(1, 30):
print page
url = "http://info.finance.yahoo.co.jp/history/?code=998405.T&sy=%d&sm=%d&sd=%d&ey=%d&em=%d&ed=%d&tm=d&p=%d"
url = url % (dateFr["year"], dateFr["month"], dateFr["day"], dateTo["year"], dateFr["month"], dateFr["day"], page)
html = urllib2.urlopen(url).read()
root = lxml.html.fromstring(html)
table = root.xpath('//*[contains(concat(" ",normalize-space(@class)," "), " boardFin ")]')[0]
for tr in table.xpath("descendant::tr"):
tmp = [td.text for td in tr.xpath("descendant::td")]
if len(tmp) != 5:
continue
begin = float(tmp[1].replace(",", ""))
high = float(tmp[2].replace(",", ""))
low = float(tmp[3].replace(",", ""))
end = float(tmp[4].replace(",", ""))
data.append([low, high, low, high])
pylab.boxplot(data)
pylab.show()
画像