はじめに
今日 (2014/10/31) から政府の統計情報にアクセスできる
Web API が公開されたらしい。
http://www.e-stat.go.jp/api/
利用できるデータの一覧は下記 URL にある。
国勢調査から勤労統計からいっぱいある。
http://www.e-stat.go.jp/api/api-info/api-data/
なんか面白そう!
ということで使ってみた記録。
登録
-
まずは、このページにアクセスして、利用者登録を行う。
http://www.e-stat.go.jp/api/regist-login/
メールアドレスと名前なんかを入力。 -
メールアドレスにお知らせが届いているのでクリックしてアクティベート。
-
次に、ログイン。アプリケーション ID をゲット。一人 3 ID までらしい。これ以降、アプリケーション ID を xxx とする。
データ取得とプロット
手順は以下の通り。
- getStatsList にアクセスして適当な ID を取り出す。
- getStatsData にアクセスして、データを取り出す。
- カテゴリ名と VALUES のデータを取り出す。
- 最後に解析。今回は年齢ピラミッドをプロット。
# !/usr/bin/env python
# -*- coding: utf-8 -*-
import httplib2
import lxml.etree
import pylab
import matplotlib.font_manager as fm
# 初期設定
h = httplib2.Http('.cache')
key = "xxx"
baseUrl = "http://api.e-stat.go.jp/rest/1.0/app"
statsCode = "00200521"
# 政府統計コード 00200521 の最初のデータ
# (昭和 55 年の国勢調査) のデータ ID を取ってくる
print "getStatusList..."
cmd = "%s/getStatsList?appId=%s&statsCode=%s"
response, content = h.request(cmd % (baseUrl, key, statsCode))
xml = lxml.etree.fromstring(content)
dataid = xml.xpath('//LIST_INF')[0].attrib["id"]
# データ ID をキーに実際のデータを取り出す
print "getStatusData..."
cmd = "%s/getStatsData?appId=%s&statsDataId=%s"
response, content = h.request(cmd % (baseUrl, key, dataid))
xml = lxml.etree.fromstring(content)
# カテゴリ名の取り出し
categories = {}
for c in xml.xpath("//CLASS_OBJ"):
categories[c.attrib["id"]] = {"name": c.attrib["name"],
"labels": {}}
print c.attrib["id"]
for label in c.xpath("CLASS"):
print label.attrib["name"], label.attrib["code"]
categories[c.attrib["id"]]["labels"][label.attrib["code"]] = label.attrib["name"]
# 値の取り出し
values = [{"cat01": v.attrib["cat01"],
"cat02": v.attrib["cat02"],
"cat03": v.attrib["cat03"],
"area": v.attrib["area"],
"value": int(v.text)}
for v in xml.xpath('//VALUE')]
# 年齢層 (cat03) ごとの集計
c = categories["cat03"]
data = []
labels = []
for code in sorted(c["labels"].keys())[1:]:
labels.append(c["labels"][code])
data.append(sum([v["value"] for v in values if v["cat03"] == code]))
print data
# プロット
width = 0.5
x = pylab.arange(len(data))
prop = fm.FontProperties(fname='/Library/Fonts/Osaka.ttf') # for mac
pylab.barh(x, data, width)
pylab.yticks(x + width / 2, labels)
pylab.show()
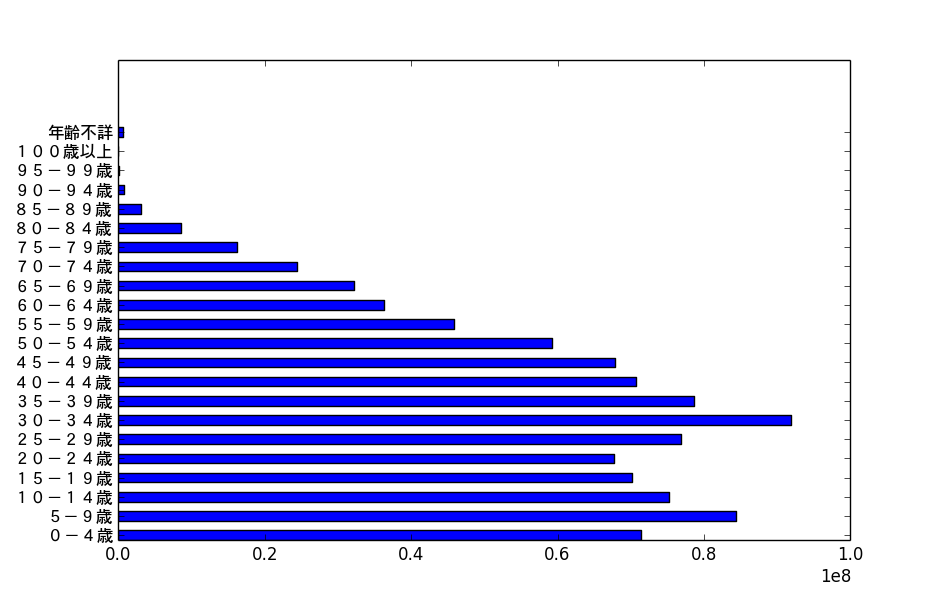
結果はこちら
参考情報
公式のマニュアル
http://www.e-stat.go.jp/api/wp/wp-content/uploads/2014/10/API-spec.pdf
ウェブのAPI を触るインターフェース
http://www.e-stat.go.jp/api/sample/testform/