動機
最近NVMeディスクをインストールしたのだけど、軽い気持ちで性能測定したら書き込みはカタログスペック通りなのに、読み出しが書き込みより遅かった。不思議。
暫定まとめ
今回つかったNVMeデバイスでは
- 使用済みセクタからの読み出しでは未使用セクタと比べて1割程度の性能劣化がある※
- とくにシングルスレッドでアクセスすると大幅に劣化する
- 書き込みでも若干劣化するが影響はそれほど大きくない
- 以上の組み合わせで書き込みより読み出しの方が遅くなる場合がある
- ブロックデバイス経由でのアクセスで影響が大きくファイルシステム経由ではあまり表面化しない
※(2018-05-19追記)未使用/使用済ではなく直前に書き込みがあったどうかによる。解決編参照。
わからないこと
- なんでこんなに読み出し性能が劣化するのか
- ブロックデバイスへの書き込みが予想より高速なのはなぜか
- ファイルシステム経由の読み出しが十分高速なのはなぜか
前提
HP Z440 Workstation
- CPU: Xeon E5-1620v3 (3.50GHz)
- MEM: 64GB DDR4 (2133MHz, ECC, Registered)
- NVMe: WD Black PCIe SSD 256GB (WDS256G1X0C)
OSはFreeBSD 11.1-RELEASE-p10で、NVMeの他にZFSでミラー構成になったHDDが付いている。デバイスの詳細は前回参照。
変更点
- NVMeディスク上にあったZFSのプールを退避して空きディスクにした
- 定常状態で64℃と高温だったのでヒートシンクを装着
# nvmecontrol logpage -p 2 nvme0 | grep ^Temp
Temperature: 314 K, 40.85 C, 105.53 F
詳細は省くけれど、高温だったことで測定結果に悪影響を与えていたのと、書き込みの性能測定を自由にできるようになったことで重要な手がかりが得られた。
デバイス特性の把握
nvme(4)にはデバイスドライバ内蔵の性能測定コードがあり、nvmecontrol perftestで実行できる。これはスレッド毎に特定のセクタをひたすら繰り返し読み書きするというもので、これを使って今回のNVMeデバイスの読み書き特性を把握する。
経緯は省略するけれど、未使用セクタと書き込み済みセクタとで、読み出し性能に大きな違いがあることがわかったので、測定間にnvmecontrol formatで未使用セクタに戻すステップを挟んでいる。つまり低レベルフォーマットで未使用セクタになった所をまず読み出し、そのあと書き込んで、使用済みセクタになった所を読み出し、また書き込むを1セットとして、IOサイズを増やしながら繰り返した。なおnvmecontrol formatについては「FreeBSDでNVMeディスクを低レベルフォーマットする」を参照。
# !/bin/sh
for size in 512 1024 2048 4096 8192 16384 32768 65536 131072
do
./nvmecontrol format nvme0ns1
sleep 10
nvmecontrol perftest -n $1 -i bio -o read -s $size -t 10 nvme0ns1
sleep 10
nvmecontrol perftest -n $1 -i bio -o write -s $size -t 10 nvme0ns1
sleep 10
nvmecontrol perftest -n $1 -i bio -o read -s $size -t 10 nvme0ns1
sleep 10
nvmecontrol perftest -n $1 -i bio -o write -s $size -t 10 nvme0ns1
done
結果を整理した表を末尾に示してある。まずカタログスペックを確認するために16スレッドを使った結果のグラフが以下。READ 0は未使用セクタの読み出し、READ 1は使用済みセクタの読み出しで、WRITE 0とWRITE 1も同様である。
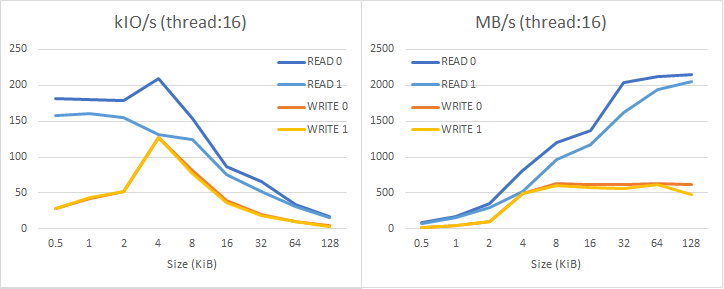
書き込みの方が単純で、IOサイズが4096バイトのときにIOPSがピーク(130kIO/s)になっている。デバイス内部では4kセクタとして処理されているものを、512バイトセクタとして見せている(いわゆる512eセクタ)ためである。最大スループットは620MB/s程度であり、カタログスペックには少し及ばないがまあそんなものだろう。これは未使用セクタへの書き込みでも、使用済みセクタへの書き込みでもほとんど変わらない。
読み込みも未使用セクタの場合は同様で、IOサイズ4096バイトでIOPSがピーク(210kIO/s)になり、それより小さいとわずかにペナルティがある。最大スループットは2100MB/s程度であり、カタログスペックどおりである。ところが使用済みセクタからの読み込みでは1割程度の性能劣化が認められる。特にIOサイズ4096バイトのピークがなくなっているのが面白い。
未使用セクタと使用済みセクタで性能が違うこと自体は、SSDの仕組みを考えればまあ自然な感じがする。しかし「未使用セクタからの読み込み」には現実的な意味がないので、カタログスペックが未使用セクタでしか得られないのは違和感のあるところだ。
※(2018-05-19追記)未使用/使用済ではなく直前に書き込みがあったどうかによる。解決編参照。
これがシングルスレッドになると非常に大きな差になる。以下がそのグラフ。
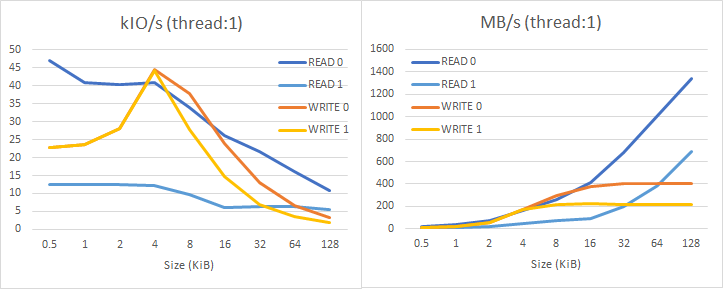
シングルスレッドでは性能が大幅に低下してしまう。これはホスト側のIO要求の処理コストが相対的に大きくなり、データ転送能力を埋め切れなくなると考えられる。それだけなら自然なことだけど、このデバイスの場合使用済みセクタからの読み込み性能が大幅に劣化している。読み込みのIOPSが12kIO/sというのは余りに酷いのではないか。なによりほとんどの条件で書き込みのIOPSの方が良好というのが不思議である。
ddによる性能測定
カーネルコードによる性能測定でデバイスの特性がわかったので、それを踏まえてユーザーランドからの性能を見てみる。前回同様、GNUスタイルのフラグを受け付けるddとしてsysutils/ddptを利用している。
ブロックデバイス経由
ddでブロックデバイスに対して読み書きする場合、シングルスレッドのシーケンシャルアクセスになっていると考えられる。これまでの検討を踏まえて、低レベルフォーマットの後、読み出し(未使用)→書き込み→読み出し(使用済)の順で測定した。
# ./nvmecontrol format nvme0ns1
# ddpt if=/dev/nvd0 of=/dev/null bs=1m count=1024 oflag=nowrite
# ddpt if=/tmp/testdata of=/dev/nvd0 bs=1m count=1024 oflag=nowrite
# ddpt if=/tmp/testdata of=/dev/nvd0 bs=1m count=1024
# ddpt if=/dev/nvd0 of=/dev/null bs=1m count=1024 oflag=nowrite
| 測定項目 | 速度(MB/s) |
|---|---|
| ブロックデバイスからの読み出し(未使用) | 1255.57 |
| ファイルシステムのキャッシュからの読み出し | 7331.85 |
| ブロックデバイスへの書き込み | 713.47 |
| ブロックデバイスから読み出し(使用済) | 525.67 |
これをnvmecontrol perftestのシングルスレッドでIOサイズ128KiB1の結果と照らし合わせると、未使用セクタからの読み出しはREAD 0が1341MB/s、使用済セクタからの読み出しはREAD 1が688MB/sであったことに対応していると思われる。一方、書き込み速度はWRITE 0が407MB/sなのに対して速過ぎるのし、マルチスレッドのWRITE 0も624MB/sでしかないので、なにか別の要素が関係していそうである。
ファイルシステム経由
現実的にはほとんどの場合に、ファイルシステムを経由してディスクへアクセスすることになる。そこでこのNVMeデバイス上にUFSのファイルシステムを作って、それに対する読み書き性能を測定してみた。まっさらなファイルシステムにtruncateでファイルを作成し、読み出し(未使用)→書き込みと測定した後、一旦再起動してキャッシュをクリアしてから読み出し(使用済)の測定を行った。
# ./nvmecontrol format nvme0ns1
# gpart create -s gpt nvd0
# gpart add -t freebsd-ufs -a 1m nvd0
# newfs -E -U -j -t nvd0p1
# mount /dev/nvd0p1 /mnt
# truncate -s 1G /mnt/testdata
# ddpt if=/mnt/testdata of=/dev/null bs=1m count=1024 oflag=nowrite
# ddpt if=/tmp/testdata of=/mnt/testdata bs=1m count=1024 oflag=nowrite
# ddpt if=/tmp/testdata of=/mnt/testdata bs=1m count=1024
# shutdown -r now
# mount /dev/nvd0p1 /mnt
# ddpt if=/mnt/testdata of=/dev/null bs=1m count=1024 oflag=nowrite
| 測定項目 | 速度(MB/s) |
|---|---|
| ファイルシステムからの読み出し(スパースファイル)2 | 2107.85 |
| ファイルシステムのキャッシュからの読み出し | 7782.49 |
| ファイルシステムへの書き込み | 728.96 |
| ファイルシステムから読み出し(使用済) | 1759.77 |
この結果を見ると、ブロックデバイス経由でのアクセスよりも使用済みセクタの読み出し性能が改善していることがわかる。16スレッドでIOサイズ128KiB1のREAD 1が2048MB/sであったことに対応しているようにも思われる。とするとマルチスレッドでアクセスするようになっているのか?一方書き込み速度はブロックデバイス経由のときと変わらない。
その他
このNVMeデバイスは512eセクタと4Kセクタを切り替えることができるが、nvmecontrol perftestの結果にはほとんど差がなかった。
nvmecontrol perftestの結果
| Threads | Size (KiB) | READ 0 IOPS | READ 0 MB/s | READ 1 IOPS | READ 1 MB/s | WRITE 0 IOPS | WRITE 0 MB/s | WRITE 1 IOPS | WRITE 1 MB/s |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.5 | 47099 | 22 | 12491 | 6 | 22840 | 11 | 22873 | 11 |
| 1 | 1 | 40829 | 39 | 12478 | 12 | 23778 | 23 | 23752 | 23 |
| 1 | 2 | 40432 | 78 | 12422 | 24 | 28159 | 54 | 28095 | 54 |
| 1 | 4 | 40811 | 159 | 12344 | 48 | 44563 | 174 | 44275 | 172 |
| 1 | 8 | 34021 | 265 | 9562 | 74 | 37734 | 294 | 27959 | 218 |
| 1 | 16 | 26210 | 409 | 6174 | 96 | 23970 | 374 | 14592 | 228 |
| 1 | 32 | 21693 | 677 | 6363 | 198 | 13058 | 408 | 7046 | 220 |
| 1 | 64 | 16200 | 1012 | 6247 | 390 | 6514 | 407 | 3537 | 221 |
| 1 | 128 | 10728 | 1341 | 5505 | 688 | 3256 | 407 | 1760 | 220 |
| 16 | 0.5 | 181562 | 88 | 158423 | 77 | 27736 | 13 | 28155 | 13 |
| 16 | 1 | 179925 | 175 | 160136 | 156 | 42795 | 41 | 43240 | 42 |
| 16 | 2 | 178459 | 348 | 155460 | 303 | 52183 | 101 | 51728 | 101 |
| 16 | 4 | 208957 | 816 | 131840 | 515 | 127103 | 496 | 126959 | 495 |
| 16 | 8 | 153109 | 1196 | 124004 | 968 | 80875 | 631 | 77355 | 604 |
| 16 | 16 | 87533 | 1367 | 75011 | 1172 | 39562 | 618 | 36759 | 574 |
| 16 | 32 | 65395 | 2043 | 52003 | 1625 | 19803 | 618 | 17950 | 560 |
| 16 | 64 | 34029 | 2126 | 31118 | 1944 | 10132 | 633 | 9826 | 614 |
| 16 | 128 | 17205 | 2150 | 16386 | 2048 | 4996 | 624 | 3847 | 480 |
-
カーネルのMAXPHYSが128KiBなので、ddで1MiBのバッファを用意してもデバイスに対するアクセスは128KiB単位に刻まれてしまう。それでもddに大きなバッファを用意することには意味があり、経験的には16MiBくらいまで性能が伸びる。おそらくシステムコールの回数が減り、コンテキストスイッチによるオーバーヘッドが少なくなるからではないか。今回バッファサイズを16MiBにしなかったのは、1MiBの方が指定しているデータ量が解りやすいから。 ↩ ↩2
-
truncate -s 1Gで作ったファイルを読み込んでもNVMeデバイスへアクセスしないため、これは「未使用セクタからの読み込み」とは関係が無い。なにかいい方法がないか考え中。 ↩