はじめに
全力回避フラグちゃん! の動画の人気理由を決定木と呼ばれる手法で,可視化しました.
ここで人気理由とは,再生回数が100万回以上を超えている動画を指します.
手元にあるデータで,何かしら可視化できたら面白そうということでやってみることにしました.
注意事項
2021/5/8 18:30時点で取得した情報を利用しています.
出現のカウントは,目視でやっています.基準は上記過去記事の「全力回避フラグちゃん!」チャンネルの動画をグラフ化するとどうなるのか?【Python】【グラフ化】に書いています.
データを取得及び,データセットを自動作成するプログラムを使用しています.関連リンクのGithub に用意していますので,ご自由にご使用ください
用いたデータセット/手法
YouTube Data API のVideos リソースを使用し,2021/5/8 18:30時点において,全力回避フラグちゃん! のチャンネルにアップロードされている全293 本の動画から取得できる情報に加え,実際に動画を視聴して各3フラグの登場をカウント,さらにコラボやShouts,フラグラといった回の情報をラベル付けしています.
データセットの主なカラムは以下の通りです.
| No. | カラム名 | データ型 | 説明 |
|---|---|---|---|
| 1 | viewCount | int | 動画の再生回数 |
| 2 | likeCount | int | 動画の高評価数 |
| 3 | dislikeCount | int | 動画の低評価数 |
| 4 | commentCount | int | 動画のコメント数 |
| 5 | DeadEndCount | int | 動画がデッドエンドであれば1,そうでなければ0で表現 |
| 6 | shibouflagCount | int | 死亡フラグちゃんが登場していれば1,そうでなければ0で表現 |
| 7 | seizonflagCount | int | 生存フラグさんが登場していれば1,そうでなければ0で表現 |
| 8 | renaiflagCount | int | 恋愛フラグさんが登場していれば1,そうでなければ0で表現 |
| 9 | videoTime | int | 動画時間を秒で表現 |
| 10 | collabo | int | コラボ動画であれば1,そうでなければ0で表現 |
| 11 | story | int | 動画がストーリー編であれば1,そうでなければ0で表現 |
| 12 | sub-story | int | 動画がサブストーリー編であれば1,そうでなければ0で表現 |
| 13 | flagra | int | 動画にフラグラが含まれていれば1,そうでなければ0で表現 |
| 14 | shorts | int | 動画がshorts であれば1,そうでなければ0で表現 |
| 15 | viewCountLabel | object | 動画が100万再生を超えていれば"Yes",そうでなければ"No"で表現 |
| 16 | vid | object | YouTube が各動画に割り振っているid |
| 17 | title | object | 動画のタイトル |
| 18 | date | object | 動画の公開日 |
| 19 | description | object | 動画の概要 |
この中で,今回は各キャラクターの登場及びコラボやshourts,フラグラやストーリー編といった実際に動画を見たりしないことにはわからないメタファー的な情報がどういう形で動画の人気に影響があるか知りたいのがモチベーションだったので,以下の情報を用いて動画の人気理由(100万再生回数を超えているか)を探っていきます.
目的変数は,15番目のカラムviewCountLabel をOne-Hot Encoding した値(Yes なら1,No なら0)で,説明変数は4~8 および10~14 のカラムです.
プログラムの作成
上記の手法を用いて決定木で可視化するためのプログラムを作成します.
以下が,実際に使用したプログラムです.
mport sklearn
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
from matplotlib.font_manager import FontProperties
from matplotlib import rcParams
# font
font_path = '/usr/share/fonts/truetype/takao-gothic/TakaoPGothic.ttf'
font_prop = FontProperties(fname=font_path)
matplotlib.rcParams['font.family'] = font_prop.get_name()
# 対象のデータセット
source_df = pd.read_csv("flag_datasets_20210508.csv")
# 目的変数をint に変換
vc_label = (source_df.viewCountLabel == 'Yes').astype(np.int64)
single_value_column = source_df.nunique() == 1
source_df.drop(source_df.columns[single_value_column],
axis=1, inplace=True)
# 不要なカラムを削除
numerical_df = source_df.select_dtypes(include=['int64'])
numerical_df.drop(['No.'], axis=1, inplace=True)
numerical_df.drop(['viewCount'], axis=1, inplace=True)
numerical_df.drop(['likeCount'], axis=1, inplace=True) #
numerical_df.drop(['dislikeCount'], axis=1, inplace=True) #
numerical_df.drop(['commentCount'], axis=1, inplace=True) #
numerical_df.drop(['videoTime'], axis=1, inplace=True) #
# 決定木の作成
import sklearn.tree
dt_model = sklearn.tree.DecisionTreeClassifier(max_depth=4, random_state=42)
dt_model.fit(numerical_df, vc_label)
plt.figure(figsize=(50, 10))
sklearn.tree.plot_tree(dt_model, feature_names=numerical_df.columns, filled=True)
# 決定木の詳細を可視化
from dtreeviz.trees import dtreeviz
viz = dtreeviz(dt_model, numerical_df, vc_label, target_name="viewCount>million", feature_names=numerical_df.columns, class_names=["No", "Yes"])
viz.save("flag_viz.svg")
可視化の結果
決定木を可視化したものが以下の図です.

決定木を読み取っていくと,最上位のノードには,生存フラグさんが登場有無が来ました.このことから,生存フラグさんの登場は動画の100万再生越えに大きく影響していそうです.ここから,一番100万再生越えの数が多い左側のルートをみていくと,
「生存フラグさんが登場しない」→「デッドエンドでない」→「コラボでない」→「shorts でない」という動画が200動画存在し,そのうち57動画が100万再生を超えていることがわかります.2021/05/08 18:30 時点の293 動画のうち,100万再生を超えている動画は85 動画しかないので,全体の100万再生越えの動画のうち,およそ7割ほどを占める結果となります.
次に割合が一番多いルートを見ていくと,
「生存フラグさんが登場する」→「死亡フラグちゃんが登場しない」→「shorts でない」→「恋愛フラグさんが登場しない」という動画が5動画存在し,そのうち4つの動画が100万再生越えを達成しています.割合としては80 %です.つまり,生存フラグさん単独の動画は数こそ少ないが,100万再生を超える人気を誇る動画であるようです.
以下は,上記の決定木において,データの分布表示したものです.
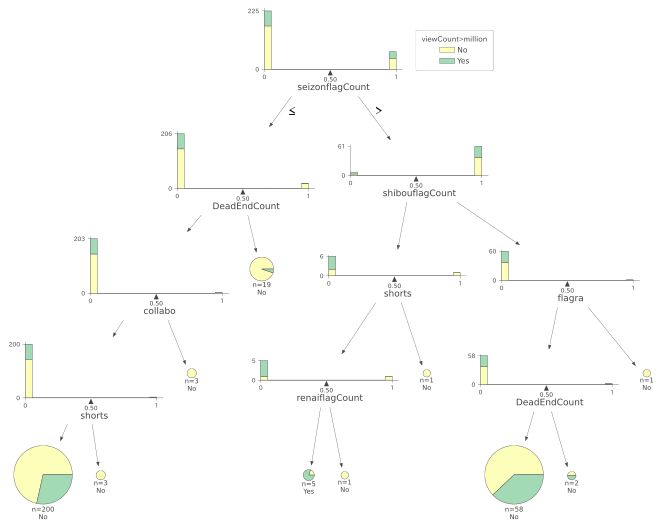
可視化の結果を受けると,生存フラグさんが出ないのであれば,コラボやshorts,デッドエンドのような特殊な回ではなく普通の回,出る場合であれば単独回もしくは,死亡フラグちゃんを登場させるといった動画が人気がありそうということになりました.
簡単なまとめ
- 決定木は簡単に使用できる
- 動画の人気に生存フラグさんの登場は大きく影響していそう
- 生存フラグさん単独登場回は人気がある
今後の予定
他にも気になることがあったら,可視化していく予定です.
次は,タイトルや概要欄に使用されている単語の登場回数を調査したり,そこから動画のカテゴリ付けなどをしていく予定です.
おわりに
ここまで読んでいる人はいないと思いますが,もしいたらまずは,以下のリンクから全力回避フラグちゃん! チャンネルとフラグちゃんのTwitter をフォローしてください.この記事を読むより大切なことです.
大事なことなのでもう一度,チャンネル登録とTwitter のフォローをよろしくお願いいたします.
参考文献
機械学習の手法を実践する際に活用させていただきました.ありがとうございます.
関連リンク
- YouTube Data API Channels リソース https://developers.google.com/youtube/v3/docs/channels?hl=ja
- 全力回避フラグちゃん! https://www.youtube.com/channel/UCo_nZN5yB0rmfoPBVjYRMmw/videos
- 株式会社Plott / Plott Inc. https://plott.tokyo/#top
- フラグちゃんのTwitter https://twitter.com/flag__chan
- Github https://github.com/uky007/flag_analysis