はじめに
全力回避フラグちゃん! の動画のサムネイル画像を特徴量を平均色とし,k-menas + t-sne を用いてクラスタリングを可視化しました.
サムネイル画像のクラスタリングは今年の目標の一つであり,前回の記事ではPCA を用いた可視化を実施したので,今回はt-SNE を用いてみました.
注意事項
2021/9/25 18:30時点で取得した情報を利用しています.
サムネイル画像の中には,動画の一部に置き換えられた※ままのものがありますが,今回はフィルタリングせずに,実施しています.
※一時収益停止になった際にYouTube のポリシーに違反していると思われるものが置き換えられ,収益復活後もどうやら影響が続いている(というか,チャンネルの運営側が戻していない?)ように思えます.真相はどうかわかりません.
用いたデータセット/手法
YouTube Data API のVideos リソースを使用し,2021/9/25 18:30時点において,全力回避フラグちゃん! のチャンネルにアップロードされている全375 本の動画から取得できるサムネイル画像(high の解像度)に,前処理として画像の上下にある黒帯をカットした
幅 480 x 高さ 260 ピクセル のサムネイル画像を使用しています.
具体的なサンプルは,以下のリンクから確認できます.
https://i.ytimg.com/vi/XQ2IRAFLKLU/hqdefault.jpg
また,上記で述べたサムネイル画像が動画の一部に置き換わってしまっているサンプルは,以下のリンクから確認できます.
https://i.ytimg.com/vi/SG1FW5zVzko/hqdefault.jpg
プログラムの作成
あらかじめ不要な部分をカットし,サイズをそろえたサムネイル画像をカラーで読み込み,その画像の平均色を特徴量としてk-means を用いたクラスタリングを実施,その結果をt-SNE を用いて2次元に次元削減を実施して,クラスタリングの可視化を実施しました.(このような高次元の可視化を布置と呼んだりもする様です.)
なお,クラスターの数は別の記事で目視でクラスタリングした結果,大体6つに分類される形だったので,(あれからだいぶ時間がたってはいますが)6にしました.
import sklearn
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import glob
import cv2
import matplotlib
from matplotlib.font_manager import FontProperties
from matplotlib import rcParams
import re
# データセットの読み込み,特徴量の作成
image_datasets = []
for file in sorted(glob.glob(target), key=natural_keys):
file_name = file.split("/")[-1]
image_bgr = cv2.imread(file, cv2.IMREAD_COLOR)
channels = cv2.mean(image_bgr)
observation = np.array([[(channels[2], channels[1], channels[0])]])
image_rgb = cv2.cvtColor(image_bgr, cv2.COLOR_BGR2RGB)
image_data_vec = observation.flatten()
image_datasets.append(image_data_vec)
image_datasets_np = np.array(image_datasets)
# k-means によるクラスタリング
from sklearn.cluster import KMeans
k = 6
seed = 1
clusters_thumbnail = KMeans(n_clusters=k, random_state=seed).fit_predict(image_datasets_np)
# t-SNE を用いて2次元に変換
from sklearn.manifold import TSNE
tsne = TSNE(n_components=2, random_state = 0, perplexity = 30, n_iter = 1000)
X_embedded = tsne.fit_transform(image_datasets_np)
X_embedded_df = pd.DataFrame(X_embedded)
X_embedded_df['cluster'] = clusters_thumbnail
X_embedded_df = X_embedded_df.rename(columns={0: "tsne_x", 1: "tsne_y"})
# 上記の結果を結合
concat_df = pd.concat([src_datasets_df, X_embedded_df], axis=1)
concat_df.to_csv("flag_thumbnail_cluster_meancolor_20210925.csv")
可視化の結果
クラスタリングによる可視化の結果は下記です.
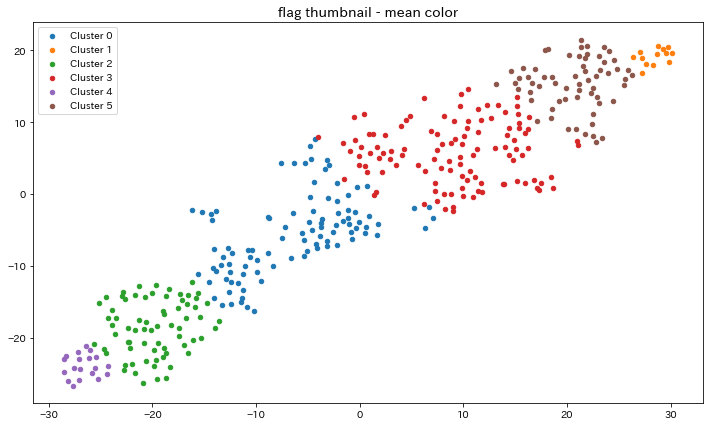
また,表にまとめると以下のようになります.
|cluster|動画数 |代表的な動画|
|:-:|:-:|:-:|:-:|---|
|0|98|クジラに飲み込まれるとどうなるのか?【アニメ】【漫画動画】 |
|1| 13 | 【アニメ】次世代通信システム5Gになるとどうなるのか【漫画動画】
|2|70|【漫画】リア充のための犯罪?若者が犯しがちな犯罪、礼拝所不敬罪とは?【アニメ】【漫画動画】 |
|3| 112 | 【漫画】戦いで食い止める役になったらどうすればいいのか【アニメ】【漫画動画】|
|4|19|【閲覧注意】恐怖の人喰いピエロに襲われるとどうなるのか…?【アニメ】【漫画動画】|
|5|63|【漫画】男女が砂漠で迷うとどうなるのか?…まさかの〇〇でピンチを切り抜ける?【アニメ】【漫画動画】|
詳細な結果は,データセット をご確認ください.
簡単なまとめ
- k-means + t-sne でクラスタリング結果を可視化した
- 結果を見てみると,あまり良い結果にならなかった
- 結果の考察や分析については,時間のある時に実施する.
今後の予定
他にも気になることがあったら,可視化していく予定です.
次は,タイトルや概要欄に使用されている単語の登場回数を調査したり,そこから動画のカテゴリ付けなどをしていく予定です.
おわりに
ここまで読んでいる人はいないと思いますが,もしいたらまずは,以下のリンクから全力回避フラグちゃん! チャンネルとフラグちゃんのTwitter をフォローしてください.この記事を読むより大切なことです.
大事なことなのでもう一度,チャンネル登録とTwitter のフォローをよろしくお願いいたします.
参考文献
機械学習の手法を実践する際に活用させていただきました.ありがとうございます.
- 仕事ではじめる機械学習 第2版.有賀 康顕,中山 心太,西林 孝 著.2021/04
- 機械学習のための特徴量エンジニアリング――その原理とPythonによる実践,Alice Zheng、Amanda Casari 著.2019/02
- Python機械学習クックブック,Chris Albon 著.2018/12
関連リンク
- YouTube Data API Channels リソース https://developers.google.com/youtube/v3/docs/channels?hl=ja
- 全力回避フラグちゃん! https://www.youtube.com/channel/UCo_nZN5yB0rmfoPBVjYRMmw/videos
- 株式会社Plott / Plott Inc. https://plott.tokyo/#top
- フラグちゃんのTwitter https://twitter.com/flag__chan
- Github https://github.com/uky007/flag_analysis