Pythonの勉強を始めて半年、オリジナルのプログラムを組むことになったので、
投資に役に立つような分析プログラムに挑戦することにした。
Pythonの株価分析というと、日経平均株価などの時系列分析が多いけど、
今回は3000社以上の上場企業を対象にして、それらの企業の決算情報をもとに、
「投資対象として良好な銘柄」を探すプログラムを作ってみる。
ここでのよい銘柄とは、「1年後の株価の上昇率(下落率)が、日経平均のそれを上回っていること」。
株価分析のプログラムでよく見る「この後、上がるか下がるか予想」ではなく、1年後のパフォーマンスという、スパンが長く、相対的な指標をターゲットとした。
一般的に、ある企業の業績がよくても、株式市場全体から資金が引き上げられれば、
株価は下がるなど、単体企業の株価も市場全体の動向の影響は避けられないことと、
株価は財務情報の数値ではなく、投資家たちの思惑で動く部分が大半のため、
短期的には決算の数値的な変化とは無関係な動きとなる可能性が高いからだ。
上がるときは、日経平均より上がり、下がるときには、日経平均よりは下がらない、そんな銘柄を探す。
開発の環境はGoogleColaboratoryです。
※間違って、有料のproに申し込んでしまいましたが、proでなくとも動くと思います。
【分析フロー】
①財務情報の取得
②株価情報の取得
③財務データのクレンジング
④パラメーター情報の作成
⑤各企業の決算日の株価のみを抽出
⑥ターゲットの設定(対日経平均のパフォーマンスの計算)
⑦機械学習の準備
⑧機械学習で分析
⑨深層学習で分析
⑩考察
では、順番に説明していきます。
財務情報の取得
今回はIR BANKさんで公開されている、財務データ(.csv)を使用させていただきました。ありがとうございます。XBRLで収集されていると思いますが、早く私もそこまでできるようになりたいです。
! pip install pandas-datareader
import os
import datetime as dt
import time
import calendar
import pandas_datareader.data as web
import numpy as np
import tensorflow as tf
import pandas as pd
from pandas import read_csv
###############①IRデータの取得(3種の財務データCSVの14年~22年までのファイルを読み込み)####
##ir_dataはindexが銘柄コード、columnsは各年の売上高など財務データ
fys=["fy-profit-and-loss_","fy-balance-sheet_","fy-cash-flow-statement_"]
for fy in fys:
for i in range(14,23):
address = '/content/drive/MyDrive/IR/' + fy + str(i) + '.csv'
dataframe = read_csv(address, skiprows = 1, encoding = "utf-8")
#後のマージ処理のために各列名に年度を付加
dataframe = dataframe.add_suffix('_' + str(i))
#ただしmergeでkeyとなる列“コード”は年度を再度外す
dataframe = dataframe.rename(columns={'コード_' + str(i):'コード'})
#Loop処理の1回目は代入するのみ。
if(i==14 and fy=="fy-profit-and-loss_"):
ir_data = dataframe
else:
ir_data = pd.merge(ir_data,dataframe,on='コード')
#銘柄リスト(stock_list)の作成
#機械学習までの処理で増減があるため、都度都度更新をする。
stock_list = ir_data['コード']
3種類のCSVファイルを9年分のデータをpd.read_csvで順番に読み込んでいき、すべて一つのDataFrameにまとめておきます。このときmerge(on 銘柄コード)をしているので、9年分のデータがない企業はここで削除されることになります。
株価データの取得
##ライブラリDataReaderで、サイトstooqより、株価データを取得
##1日の取得数に制限があるため、何日かに分けてCSVで保存していく。
##銘柄コード0~999:0000、1000~1999:1000、2000~2999:2000、、、
#取得するコードの指定
list_num = '4000'
get_stock_list = [i for i in stock_list if (i>=int(list_num) and i<int(list_num)+1000 )]
###リスト内の証券コードに".JP"をつける。
#文字列に変換
ticker_symbols = [str(n)+".JP" for n in get_stock_list]
print(ticker_symbols)
#nikkeiのみを抽出する場合に使用
#stock_value = web.DataReader("^NKX", data_source='stooq', start='2014-01-01',end='2022-07-31')
##DataReaderでデータを取得
stock_value = web.DataReader(ticker_symbols, data_source='stooq', start='2014-01-01',end='2022-07-31')
#print('stock_vslue',stock_value)
##CSVで保存
stock_value.to_csv('/content/drive/MyDrive/scraping' + list_num + '.csv', index=True, encoding='utf_8_sig')
株価を取得する方法として、WEBで検索すると出てくるのが、DataReaderを使った取得方法。
DataReaderを使うとたったの2~3行で、10年以上過去のデータから取れてしまうので非常に便利なので今回使わせてもらった。
DataReaderでは2021年くらいまでは、Yahoo!ファイナンスの株価データも取得できたようだが、今はstooqくらいしかない。そういう意味では貴重なサイトです。
ただ案外ネックになったのが、1日の取得上限。
stock_value = web.DataReader(ticker_symbols, data_source='stooq', start='2014-01-01',end='2022-07-31')
この部分が実際に取得しているコード。ticker_symbolは、銘柄コードのリストで、リスト記載の銘柄の株価を一気に取得しています。ここを例えばトヨタ自動車なら'7203.JP'とすると個別銘柄の株価を取得できます。以下の部分は日経平均株価のみを取得しています(^NKX=日経平均のコード)
stock_value = web.DataReader("^NKX", data_source='stooq', start='2014-01-01',end='2022-07-31')
個別銘柄で取得しようとすると、1日250件程度が上限となり、リストで取得しても1日450件程度のようです。上限に達すると、空のdataFrameが返ってくるようになります。
上場企業は3000件超で推移しているので、7~8日程度をかけて、集めていきます。
ちなみに1日1回取得したあとは、DataReader部分を#コメントアウトしておかないと、時間がかかります。
財務データのクレンジング
#"-"が含まれる銘柄(行)を削除する
#ir_data = ir_data.query('●●●_△ !="-"')△年の●●●が"-"になっていないものを抽出
for column_name in ["売上高","EPS","BPS","自己資本比率","ROA","営業CF","投資CF"]:
for i in range(14,23):
ir_data = ir_data.query(str(column_name) +"_"+str(i) + '!="-"')
#'コード'列をindexに設定する
ir_data = ir_data.set_index('コード')
#stock_listの更新
#"-"のある銘柄を取り除いたため
stock_list = ir_data.index.values
最終利益がマイナスの場合、ROEやROAが'-'になっているようなので、これらの銘柄を削除します。
また銘柄コードをindexにしています。コードのデータ型はintです。
パラメーター(説明変数)情報の作成
取得した財務情報のうち、影響のありそうな指標を選びます。
今回は、よく企業の評価で使用される指標を選びました。
##売上5年成長率(sales_5) (売上高_n/売上高_n-5)~1/5
##売上3年成長率(sales_3) (売上高_n/売上高_n-3)~1/3
##売上1年成長率(sales_1) (売上高_n/売上高_n-1)
##EPS5(eps_5) n-5年のEPS ※マイナスになりうるので、成長率としない
##EPS3(eps_3) n-3年のEPS ※マイナスになりうるので、成長率としない
##EPS1(eps_1) n-1年のEPS ※マイナスになりうるので、成長率としない
##BPS5年成長率(bps_5) (BPS_n/BPS_n-5)~1/5
##BPS3年成長率(bps_3) (BPS_n/BPS_n-3)~1/3
##BPS1年成長率(bps_1) (BPS_n/BPS_n-1)
##ROA (roa) ROAのn年のデータ
##自己資本比率(car) 自己資本比率のn年のデータ ※Capital adequacy ratio
##フリーキャッシュフローn-4年(fcf_5) 営業CF-投資CF
##フリーキャッシュフローn-3年(fcf_4) 営業CF-投資CF
##フリーキャッシュフローn-2年(fcf_3) 営業CF-投資CF
##フリーキャッシュフローn-1年(fcf_2) 営業CF-投資CF
##フリーキャッシュフローn年(fcf_1) 営業CF-投資CF
##年度(ym5~0) 年度※株価取得のための決算月の情報
#DataFrameの用意
data19 = pd.DataFrame(columns=[],index=ir_data.index, dtype='float32')
data20 = pd.DataFrame(columns=[],index=ir_data.index, dtype='float32')
data21 = pd.DataFrame(columns=[],index=ir_data.index, dtype='float32')
##計算結果を格納
data19['sales_5'] = ir_data['売上高_19'].astype('float32')/ir_data['売上高_14'].astype('float32')
data19['sales_3'] = ir_data['売上高_19'].astype('float32')/ir_data['売上高_16'].astype('float32')
data19['sales_1'] = ir_data['売上高_19'].astype('float32')/ir_data['売上高_18'].astype('float32')
data19['eps_5'] = ir_data['EPS_15'].astype('float32')
data19['eps_3'] = ir_data['EPS_17'].astype('float32')
data19['eps_1'] = ir_data['EPS_19'].astype('float32')
data19['bps_5'] = ir_data['BPS_19'].astype('float32')/ir_data['BPS_14'].astype('float32')
data19['bps_3'] = ir_data['BPS_19'].astype('float32')/ir_data['BPS_16'].astype('float32')
data19['bps_1'] = ir_data['BPS_19'].astype('float32')/ir_data['BPS_18'].astype('float32')
data19['roa'] = ir_data['ROA_19'].astype('float32')
data19['car'] = ir_data['自己資本比率_19'].astype('float32')
data19['fcf_5'] = ir_data['営業CF_15'].astype('float32')-ir_data['投資CF_15'].astype('float32')
data19['fcf_4'] = ir_data['営業CF_16'].astype('float32')-ir_data['投資CF_16'].astype('float32')
data19['fcf_3'] = ir_data['営業CF_17'].astype('float32')-ir_data['投資CF_17'].astype('float32')
data19['fcf_2'] = ir_data['営業CF_18'].astype('float32')-ir_data['投資CF_18'].astype('float32')
data19['fcf_1'] = ir_data['営業CF_19'].astype('float32')-ir_data['投資CF_19'].astype('float32')
data19['ym_5'] = ir_data['年度_15']
data19['ym_4'] = ir_data['年度_16']
data19['ym_3'] = ir_data['年度_17']
data19['ym_2'] = ir_data['年度_18']
data19['ym_1'] = ir_data['年度_19']
data19['ym_0'] = ir_data['年度_20']
#print(data19)
data20['sales_5'] = ir_data['売上高_20'].astype('float32')/ir_data['売上高_15'].astype('float32')
data20['sales_3'] = ir_data['売上高_20'].astype('float32')/ir_data['売上高_17'].astype('float32')
data20['sales_1'] = ir_data['売上高_20'].astype('float32')/ir_data['売上高_19'].astype('float32')
data20['eps_5'] = ir_data['EPS_16'].astype('float32')
data20['eps_3'] = ir_data['EPS_18'].astype('float32')
data20['eps_1'] = ir_data['EPS_20'].astype('float32')
data20['bps_5'] = ir_data['BPS_20'].astype('float32')/ir_data['BPS_15'].astype('float32')
data20['bps_3'] = ir_data['BPS_20'].astype('float32')/ir_data['BPS_17'].astype('float32')
data20['bps_1'] = ir_data['BPS_20'].astype('float32')/ir_data['BPS_19'].astype('float32')
data20['roa'] = ir_data['ROA_20'].astype('float32')
data20['car'] = ir_data['自己資本比率_20'].astype('float32')
data20['fcf_5'] = ir_data['営業CF_16'].astype('float32')-ir_data['投資CF_16'].astype('float32')
data20['fcf_4'] = ir_data['営業CF_17'].astype('float32')-ir_data['投資CF_17'].astype('float32')
data20['fcf_3'] = ir_data['営業CF_18'].astype('float32')-ir_data['投資CF_18'].astype('float32')
data20['fcf_2'] = ir_data['営業CF_19'].astype('float32')-ir_data['投資CF_19'].astype('float32')
data20['fcf_1'] = ir_data['営業CF_20'].astype('float32')-ir_data['投資CF_20'].astype('float32')
data20['ym_5'] = ir_data['年度_16']
data20['ym_4'] = ir_data['年度_17']
data20['ym_3'] = ir_data['年度_18']
data20['ym_2'] = ir_data['年度_19']
data20['ym_1'] = ir_data['年度_20']
data20['ym_0'] = ir_data['年度_21']
#print(data20)
data21['sales_5'] = ir_data['売上高_21'].astype('float32')/ir_data['売上高_16'].astype('float32')
data21['sales_3'] = ir_data['売上高_21'].astype('float32')/ir_data['売上高_18'].astype('float32')
data21['sales_1'] = ir_data['売上高_21'].astype('float32')/ir_data['売上高_20'].astype('float32')
data21['eps_5'] = ir_data['EPS_17'].astype('float32')
data21['eps_3'] = ir_data['EPS_20'].astype('float32')
data21['eps_1'] = ir_data['EPS_21'].astype('float32')
data21['bps_5'] = ir_data['BPS_21'].astype('float32')/ir_data['BPS_16'].astype('float32')
data21['bps_3'] = ir_data['BPS_21'].astype('float32')/ir_data['BPS_18'].astype('float32')
data21['bps_1'] = ir_data['BPS_21'].astype('float32')/ir_data['BPS_20'].astype('float32')
data21['roa'] = ir_data['ROA_21'].astype('float32')
data21['car'] = ir_data['自己資本比率_21'].astype('float32')
data21['fcf_5'] = ir_data['営業CF_17'].astype('float32')-ir_data['投資CF_17'].astype('float32')
data21['fcf_4'] = ir_data['営業CF_18'].astype('float32')-ir_data['投資CF_18'].astype('float32')
data21['fcf_3'] = ir_data['営業CF_20'].astype('float32')-ir_data['投資CF_20'].astype('float32')
data21['fcf_2'] = ir_data['営業CF_20'].astype('float32')-ir_data['投資CF_20'].astype('float32')
data21['fcf_1'] = ir_data['営業CF_21'].astype('float32')-ir_data['投資CF_21'].astype('float32')
data21['ym_5'] = ir_data['年度_17']
data21['ym_4'] = ir_data['年度_18']
data21['ym_3'] = ir_data['年度_19']
data21['ym_2'] = ir_data['年度_20']
data21['ym_1'] = ir_data['年度_21']
data21['ym_0'] = ir_data['年度_22']
#print(data21)
〇売上高の成長率(5年前比、3年前比、前年前比)
〇EPS[^1](5年前のEPS、3年前のEPS、前年のEPS)
〇BPSの成長率(5年前比、3年前比、前年前比)
〇ROA(当年)
〇自己資本比率(当年)
〇FCF(5年前、4年前、3年前、2年前、1年前)
〇PBR[^2]
〇PER[^2]
19年~21年で、それぞれの年を基準としてデータを作っています。
つまり1企業につき3年分のデータセットになります。
株価の分析だと時系列のデータとして分析するケースが多く、その場合、仮に売上なら、
n年前の売上、n-1年前の売上、n-2年前の売上、、、
をまとめて、分析プログラムに渡すことになります。
ただ今回は決算が発表されたタイミングでの企業の状態(成長性、安全性など)を特徴量と
するため、時系列のデータは成長性という形としました。「5年前比、3年前比、1年前比でも売上が伸びているのであれば、今後も伸びていく」=成長性が高い、というような具合です。
[^1]・・・EPSはマイナスになりうるので、成長率にしない。
[^2]・・・この時点で株価がないので、あとから計算。
各企業の決算日の株価を取得
##決算日の株価を抽出するため、14~22年の各月の最終の平日の日付を格納した多重リスト(辞書型)を作成する。
#決算月の最終日(ymd)を調べる関数
def get_last_date(dt):
return dt.replace(day=calendar.monthrange(dt.year, dt.month)[1])
ymd= {}
for i in range(14,23):
for j in ['01','02','03','04','05','06','07','08','09','10','11','12']:
#dは各月の最初の日
d = dt.date(2000+i,int(j),1)
last_d = get_last_date(d)
#12/31は毎年取引のない休業日なので、12/30を最終日とする。
if j=='12':
last_d = last_d - dt.timedelta(days=1)
#2018.04.30は令和元年で休業日だったため4/26を最終日とする。
if last_d == dt.date(2018,4,30):
last_d = dt.date(2018,4,26)
#2019.04.30は令和元年で休業日だったため4/26を最終日とする。
if last_d == dt.date(2019,4,30):
last_d = dt.date(2019,4,26)
#最終日が土日のときは直前の金曜日を最終日にする。6:日曜日、5:土曜日
#4/30が土曜日のケースは、4/29が祝日なので、4/28を最終日とする。
if(last_d.weekday()==6):
last_d = last_d - dt.timedelta(days=2)
elif(last_d.weekday()==5):
last_d = last_d - dt.timedelta(days=1)
if(j=='04'):
last_d = last_d - dt.timedelta(days=1)
#print(last_d)
ymd[str(2000+i)+"/"+j]=str(last_d)
del ymd['2022/07'],ymd['2022/08'],ymd['2022/09'],ymd['2022/10'],ymd['2022/11'],ymd['2022/12']
##取得したデータ(csv)を読み込む(複数ファイルの終値"Close"のみ抽出し、1ファイル(stock_value.csv)にまとめている)
address = '/content/drive/MyDrive/IR/stock_value.csv'
dataframe = read_csv(address, skiprows = 1, encoding = "utf-8")
##日経平均のデータをCSVから読み込みマージ(merge)する。on 'date'
address = '/content/drive/MyDrive/IR/nk_value.csv'
nk_data = read_csv(address, skiprows = 0, encoding = "utf-8").reset_index()
dataframe = dataframe.rename(columns={'Symbols':'date'})
nk_data = nk_data.rename(columns={'Close':'nikkei','Date':'date'})
#日経データと個別銘柄のデータをマージする(取引日の違いで日数が2日だけ違うので、mergeを使う)
dataframe = pd.merge(nk_data[['nikkei','date']],dataframe,on='date')
sep = '/'
dataframe['date'] = [dt.date(int(s.split(sep)[0]),int(s.split(sep)[1]),int(s.split(sep)[2])).strftime('%Y-%m-%d') for s in dataframe['date']]
#dateをindexにする
dataframe.set_index('date',inplace=True)
#NaNのある列を削除
dataframe = dataframe.dropna(axis=1)
##決算日の株価のみ抜き出す
ymd_list = [s for s in ymd.values()]
dataframe = dataframe.loc[ymd_list,:]
##stock_listの更新(0:nikkeiなので。culumn名には".JP"がついているので[:4]でスライス)
for name in dataframe.columns[1:].values:
if (int(name[:4]) in stock_list) ==False:
dataframe = dataframe.drop(name,axis=1)
stock_list = []
stock_list_str =[]
for name in dataframe.columns[1:].values:
stock_list.append(int(name[:4]))
print(stock_list)
for name in stock_list:
stock_list_str.append(str(name)+"JP")
print(stock_list_str)
次は株価のデータです。stooqから取得した状態のままだと、数年分の毎営業日(1500件くらい)の株価があります。
今回必要なのは、決算日の株価と、その1年後の株価なので、これらだけ抽出します。また今回は"よい銘柄"を「日経平均よりパフォーマンスの高い銘柄」としているので、日経平均株価のデータもmergeして、ひとつのdataframeとします。
決算日は各企業でバラバラなので、各年の各月最終日のリストを作成し、その情報をもとに、対象銘柄の決算日の株価と1年後の株価、それに同じタイミングの日経平均株価も取得することで、比較します。
ターゲットの設定(対日経平均のパフォーマンスの計算)
##パフォーマンスは、各銘柄の20年株価の19年度比の数字が日経平均(nikkei)のそれを上回るかどうか(上回る:1、下回るor同じ:0)
##株価の取得は、各銘柄の決算年度情報(ym_0~ym_5)をもとにdataframeから抽出
##株価がない場合はデータから削除(福証から東証への市場替えなどにより、IRデータがあっても、株価データがない場合がある)
#日経の20年~22年の各月の1年前の株価との比較
nikkei_data = {}
for i in range(2019,2023):
for j in ['01','02','03','04','05','06','07','08','09','10','11','12']:
if i==2022 and j == '07':
break
if i !=2019:
nikkei_data[str(i) + '/' + j] = dataframe.at[ymd[str(i) + '/' + j] , 'nikkei']/ dataframe.at[ymd[str(i-1) + '/' + j] , 'nikkei']
y_data2019 = pd.DataFrame(index = stock_list,columns=['pf'],dtype=int)
y_data2020 = pd.DataFrame(index = stock_list,columns=['pf'],dtype=int)
y_data2021 = pd.DataFrame(index = stock_list,columns=['pf'],dtype=int)
y_data2019 = y_data2019.fillna(0)
y_data2020 = y_data2020.fillna(0)
y_data2021 = y_data2021.fillna(0)
#各銘柄ごとに処理
for name in stock_list:
#決算月の取得(data21には22年度から17年度までの決算月が入っている)
ym_list = data21.loc[name,['ym_5','ym_4','ym_3','ym_2','ym_1','ym_0']]
#各銘柄の決算月の株価を抽出し、1年後の株価と比較する(割り算)
stock_data_2019 = dataframe.at[ymd[ym_list[3]],str(name)+".JP"]/dataframe.at[ymd[ym_list[2]],str(name)+".JP"]
stock_data_2020 = dataframe.at[ymd[ym_list[4]],str(name)+".JP"]/dataframe.at[ymd[ym_list[3]],str(name)+".JP"]
stock_data_2021 = dataframe.at[ymd[ym_list[5]],str(name)+".JP"]/dataframe.at[ymd[ym_list[4]],str(name)+".JP"]
#各銘柄の対前年パフォーマンスが、日経の対前年パフォーマンスを上回っている場合はtargetを1とする
if stock_data_2019 > nikkei_data[ym_list[3]]:
y_data2019['pf'][name] = 1
if stock_data_2020 > nikkei_data[ym_list[4]]:
y_data2020['pf'][name] = 1
if stock_data_2021 > nikkei_data[ym_list[5]]:
y_data2021['pf'][name] = 1
#PBRとPERを追加する
data19.at[name,'per'] = dataframe.at[ymd[ym_list[2]],str(name)+".JP"]/data19.at[name,'eps_1']
data19.at[name,'pbr'] = dataframe.at[ymd[ym_list[2]],str(name)+".JP"]/(data19.at[name,'bps_1']*1000)
#data19.at[name,'stock'] = dataframe.at[ymd[ym_list[2]],str(name)+".JP"]
data20.at[name,'per'] = dataframe.at[ymd[ym_list[3]],str(name)+".JP"].astype(float)/data20.at[name,'eps_1'].astype(float)
data20.at[name,'pbr'] = dataframe.at[ymd[ym_list[3]],str(name)+".JP"]/(data20.at[name,'bps_1']*1000)
#data20.at[name,'stock'] = dataframe.at[ymd[ym_list[3]],str(name)+".JP"]
data21.at[name,'per'] = dataframe.at[ymd[ym_list[4]],str(name)+".JP"]/data21.at[name,'eps_1']
data21.at[name,'pbr'] = dataframe.at[ymd[ym_list[4]],str(name)+".JP"]/(data21.at[name,'bps_1']*1000)
#data21.at[name,'stock'] = dataframe.at[ymd[ym_list[4]],str(name)+".JP"]
パフォーマンス = 1年後の株価 / ある年の決算日の株価
日経平均よりパフォーマンスの高いものは1、低いものは0として、これらを目的変数(target)としました。
x_data = pd.DataFrame(dtype='float32')
y_data = pd.DataFrame(dtype=int)
##data19、data20、data21と株価を持たない銘柄が削除されていないので、stock_listでloc。
data19 = data19.loc[stock_list]
data20 = data19.loc[stock_list]
data21 = data19.loc[stock_list]
##19~21年のデータを連結
y_data = pd.concat([y_data2019,y_data2020])
y_data = pd.concat([y_data,y_data2021])
x_data = pd.concat([data19,data20])
x_data = pd.concat([x_data,data21])
####実際に分析するデータの数を制御(train + test)
count =1000
x_data = x_data.reset_index()
y_data = y_data.reset_index(drop=True)
data = pd.concat([x_data,y_data],axis=1)
data = data.sample(n=count)
x_data = data.drop('pf',axis=1)
y_data = data['pf']
x_data = x_data.drop(columns=['コード','ym_5','ym_4','ym_3','ym_2','ym_1','ym_0'])
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
from sklearn.metrics import mean_squared_error
# テストデータとトレーニングデータに分割
X_train, X_test, y_train, y_test = train_test_split(x_data, y_data, test_size=0.25, random_state=42)
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
y_train = y_train.astype(int)
y_test = y_test.astype(int)
19年~21年を基準にしたデータをひとつにまとめます。
そのうえで、分析対象とする銘柄数をpd.sampleで抽出し(1000件)、train_test_splitで訓練データと検証データに分割します。
データの標準化
from sklearn.preprocessing import StandardScaler
#インスタンス (平均=0, 標準偏差=1)
standard_sc = StandardScaler()
#すべての特徴量を標準化する。
X_train = standard_sc.fit_transform(X_train)
#testはtrainと同じスケーラーを使用するので、transform
X_test = standard_sc.transform(X_test)
億単位の売上データと、成長率などの比率の小さい数字が混在するため、標準化をして尺度を揃えます。
機械学習による分析
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.svm import LinearSVC
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import accuracy_score
from sklearn.metrics import precision_score
from sklearn.metrics import f1_score
import scipy.stats
from sklearn.model_selection import RandomizedSearchCV
model_param_set_random = {LogisticRegression():{"C": scipy.stats.uniform(0.00001, 1000),
"multi_class":["ovr","multinomial"],
"random_state":[42]},
LinearSVC(max_iter=100):{"C": scipy.stats.uniform(0.00001, 1000),
"multi_class":["ovr","crammer_singer"],
"random_state":[42]},
DecisionTreeClassifier(): {"max_depth":[i for i in range(1, 11)],
"random_state": [42] },
RandomForestClassifier(): {"n_estimators":[i for i in range(1, 21)],
"max_depth":[i for i in range(1, 11)],
"random_state": [42] },
KNeighborsClassifier(): {"n_neighbors": [i for i in range(1, 11)] }}
max_score = 0
best_param = None
# ランダムサーチでパラメーターを探索
for model, param in model_param_set_random.items():
clf = RandomizedSearchCV(model, param)
clf.fit(X_train, y_train)
pred_y = clf.predict(X_test)
# モデルのF値を計算する
score = f1_score(y_test, pred_y, average="micro")
print(y_test,pred_y)
score_acu = accuracy_score(y_test,pred_y)
score_pre = precision_score(y_test,pred_y)
print(model , ':accuracy_score:' , str(score_acu))
print(model , ':precision_score:' , str(score_pre))
if max_score < score:
max_score = score
best_param = clf.best_params_
best_model = model
# 最も成績のいいスコアを出力。
print("学習モデル:{},\nパラメーター:{}".format(best_model, best_param))
print(max_score)
結果
LogisticRegression() :accuracy_score: 0.615
LogisticRegression() :precision_score: 0.5
LinearSVC(max_iter=100) :accuracy_score: 0.55
LinearSVC(max_iter=100) :precision_score: 0.27586206896551724
DecisionTreeClassifier() :accuracy_score: 0.57
DecisionTreeClassifier() :precision_score: 0.2
RandomForestClassifier() :accuracy_score: 0.595
RandomForestClassifier() :precision_score: 0.16666666666666666
KNeighborsClassifier() :accuracy_score: 0.555
KNeighborsClassifier() :precision_score: 0.34210526315789475
学習モデル:LogisticRegression(),
パラメーター:{'C': 418.55090069098003, 'multi_class': 'multinomial', 'random_state': 42}
0.615
結果は、accuracy_scoreで0.5~0.6。
ただ、実際の投資を考えると、陽性(1)と予想したもののうち、いくつが正解だったかを表すprecision_scoreが高いことが重要となる。予想が外れることは、ほぼほぼ損をすることを意味するからだ。実際に陽性(1)だったもののうち、いくつを予想できていたか(recall)は投資の世界では、高いに越したことはないが、損にはつながらないので、それほど重要ではない。
だが、accuracy_scoreの結果は、一番高いLogisticRegressionでも0.5という結果に、、、
これなら、ヤマ勘で投資するのと変わらない。
検証
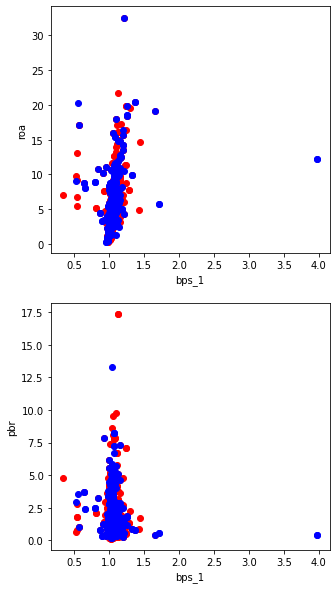
結果がイマイチなので、簡単な検証を行った。以下の散布図は赤がtarget:0、青がtarget:1。
変数が多いのでbps_1-roaと、pbr-bps_1の散布図だけ載せたが、どの変数でグラフ化しても、
結果は同じようなものだった。
よく企業の分析で使われるBPSやROAなどで分析したが、その数値だけではパフォーマンスは説明がつかないことがグラフを見るとよくわかる。これではいくらデータの数を増やしても、予想(分類)は難しいだろう。
今後の方針
〇今回配当のデータをまったく考慮に入れていないが、株価の動向には大きく影響する要素なので、変数に配当利回りなどを入れる。
〇時系列分析も行ってみる。
〇不動産の条件をもとに価格を予想するのは定番だが、同じ考え方で、財務情報をもとに株価を予想してみる。