目次
1.はじめに
2.実行環境
3.データ収集
4.画像の選別
5.学習データの水増し
6.学習
7.学習に使用したパラメータと精度評価結果を保存
8.モデルを使って新たなデータを判定してみる
9.flaskとHerokuを使ってアプリ制作
10.考察
11.おわりに
1. はじめに
こんにちは。Aidemyさんで機械学習を勉強中でpython初心者の機械設計エンジニアです。
以前ナスを育ててた時に実りが悪く、害虫や病気にやられていたことが後から分かりました。
そこで、ナスの葉の画像から病気かどうか判別してくれる簡易アプリを作ってみました。
夢はスマート家庭菜園を自作することです。
2. 実行環境
- Visual Studio Code
画像データの手作業選別はローカルで作業する方が楽なため画像収集で使用しました。 - Google Colaboratory
モデルの学習にはGPUが使用できるGoogle Colaboratoryを使用しました。
3. データ収集
icrawlerというパッケージを使用して、webからナスの画像を収集します。
こちらはVisual Studio Codeを使用しました。
3-1コード
データ収集コードの全体像はこちら。
#Bingで「ナス 葉 健康」と「ナス 病気」で検索をかけた画像それぞれ100枚を指定のフォルダへ保存するプログラム。
from icrawler.builtin import BingImageCrawler #bing用のクローラーのモジュールをインポート
words = ["ナス 葉 健康" , "ナス 病気"]
for word in words:
crawler = BingImageCrawler(storage={"root_dir":"./gazo/"+word}) #保存先を指定。
crawler.crawl(keyword= word, max_num=100)
①ライブラリをインポート。
from icrawler.builtin import BingImageCrawler
BingImageCrawlerはBingで検索するモジュールです。
googleで検索するモジュールもあるようですが最近はgoogle側のシステム変更により使用できないようです。
②検索するキーワードを設定、画像を取得
wordsに検索したいキーワードをならべ、for文でまとめて画像を取得します。
words = ["ナス 葉 健康" , "ナス 病気"]
for word in words:
crawler = BingImageCrawler(storage={"root_dir":"./gazo/"+word}) #保存先を指定。
crawler.crawl(keyword= word, max_num=100)
BingImageCrawler :Bingを用いて画像取得するクローラー。
storage={"root_dir":" "} :画像を保存するフォルダーを指定。フォルダーがなければ作成されます。
crawler.crawl(keyword= , max_num= ) :keyword検索し、max_numの数だけ画像を取得します。
3-2結果
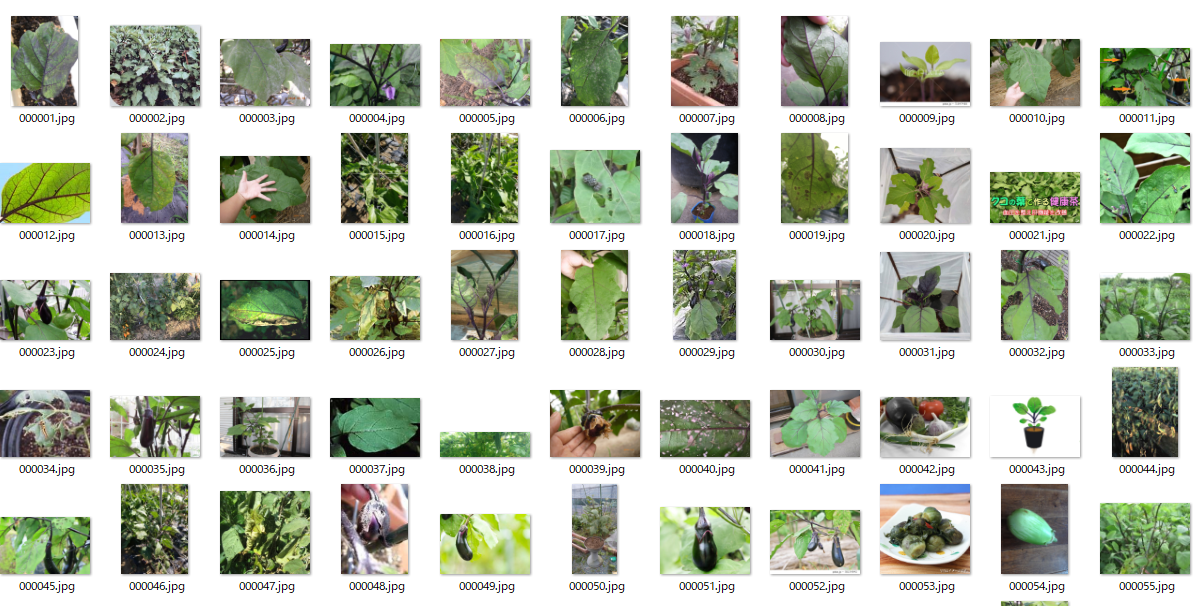
こんな感じで画像を取得できます。
ナスの果実の、病気状態、絵なども含まれており、目的である健康状態の葉の画像は比較的少ないです。
参考
4. 画像の選別
取得した画像のナスの葉が健康or病気かを目視で確認し、選別を行います。
選別後は健康画像が19枚、病気画像が80枚で偏りが出ました。
検索キーワードを工夫すれば結果は変わるかもしれませんが、そもそも健康な葉の写真をwebに上げる人が少ないのと、病気にも種類があるためだと思われます。
何かあった時のために元データはすべて残しておき、選別した画像はnasu_helthとnasu_sickという新しいフォルダーを作成して保存します。
5. 学習データの水増し
収集できたデータが少ないので水増しします。
データ数の偏りが大きすぎると精度に悪影響があるようなので、ある程度数を揃えるために健康画像は下記5つの手法、病気画像は上3つの手法で水増しを行いました。カッコ内は条件を記載。
- flip:画像の反転(左右)
- thr :閾値処理 (閾値100, しきい値より大きい値はそのまま、小さい値は0)
- filt :ぼかし (5×5個のピクセルを用いる)
- resize:モザイク(解像度は1/5にする)
- erode :収縮(自身を囲む8ピクセルを用いる)
5-1コード
健康画像水増しコードの全体像
#画像の水増しを行うプログラム。
import os
import cv2
import numpy as np
#水増し手法の関数
def scratch_image(img, flip=True, thr=True, filt=True, resize=True, erode=True ):
# 水増しの手法を配列にまとめる
methods = [flip, thr, filt, resize, erode]
# flip:画像の反転
# thr :閾値処理
# filt :ぼかし
# resize:モザイク
# erode :収縮
# 画像のサイズを習得、収縮処理に使うフィルターの作成
img_size = img.shape
filter1 = np.ones((3, 3))
# オリジナルの画像データをリスト型に入れる。numpy配列のままだと異なる画像データが同列で追加されてしまう。
images = [img]
scratch = np.array([
#画像の左右反転
lambda x: cv2.flip(x, 1),
#閾値処理
lambda x: cv2.threshold(x, 100, 255, cv2.THRESH_TOZERO)[1],
#ぼかし
lambda x: cv2.GaussianBlur(x, (5,5), 0),
#モザイク処理
lambda x: cv2.resize(cv2.resize(x, (img_size[1]//5, img_size[0]//5)), (img_size[1],img_size[0])),
#収縮する
lambda x: cv2.erode(x, filter1)
])
# 関数と画像を引数に、加工した画像を元と合わせて水増しする関数
doubling_images = lambda f, imag: (imag + [f(i) for i in imag])
# doubling_imagesを用いてmethodsがTrueの関数で水増し
for func in scratch[methods]:
images = doubling_images(func,images)
return images
# 画像を保存するフォルダーを作成
fn = "scratch_helth_img" #保存するフォルダー名
if not os.path.exists(fn):
os.mkdir(fn)
# 画像をリスト化。windowsはパスの先頭にrをつける
path_nasu = os.listdir(r"gazo\nasu_health")
#画像を読み込み、サイズ統一し、水増しを行う。× 画像枚数分
for i in range(len(path_nasu)):
img = cv2.imread(r"gazo\nasu_health/" + path_nasu[i]) #フォルダー名+名称で指定して順番に画像読み込み。
img = cv2.resize(img, (100,100)) #取得した画像はサイズが不均一なので統一する
scratch_nasu_img = scratch_image(img) # 画像の水増し
#データが[100,100,3]×枚数分のリストのため、enumerateを用いてインデックスを付与して画像番号をつける。numに画像蛮行、imには画像データを入れる。
for num, im in enumerate(scratch_nasu_img):
# 保存先のフォルダ"scratch_images/"を指定、番号を付けて保存
cv2.imwrite(fn +"/" + str((len(scratch_nasu_img)*(i)) + (num+1)) + ".jpg" ,im)
①ライブラリをインポート
import os
import cv2
import numpy as np
②水増し関数を定義
def scratch_image(img, flip=True, thr=True, filt=True, resize=True, erode=True ): #実行する手法をTrueにする。
# 水増しの手法を配列にまとめる
methods = [flip, thr, filt, resize, erode]
# flip:画像の反転
# thr :閾値処理
# filt :ぼかし
# resize:モザイク
# erode :収縮
# 画像のサイズを習得、収縮処理に使うフィルターの作成
img_size = img.shape
filter1 = np.ones((3, 3))
# オリジナルの画像データをリスト型に入れる。numpy配列のままだと異なる画像データが同列で追加されてしまう。
images = [img]
scratch = np.array([
#画像の左右反転
lambda x: cv2.flip(x, 1),
#閾値処理
lambda x: cv2.threshold(x, 100, 255, cv2.THRESH_TOZERO)[1],
#ぼかし
lambda x: cv2.GaussianBlur(x, (5,5), 0),
#モザイク処理
lambda x: cv2.resize(cv2.resize(x, (img_size[1]//5, img_size[0]//5)), (img_size[1],img_size[0])),
#収縮する
lambda x: cv2.erode(x, filter1)
])
# 関数と画像を引数に、加工した画像を元と合わせて水増しする関数
doubling_images = lambda f, imag: (imag + [f(i) for i in imag])
# doubling_imagesを用いてmethodsがTrueの関数で水増し
for func in scratch[methods]:
images = doubling_images(func,images)
return images
③画像を保存するフォルダーを作成
scratch_helth_imgフォルダがなければフォルダを自動作成します。あれば無視します。
fn = "scratch_helth_img" #保存するフォルダー名
if not os.path.exists(fn):
os.mkdir(fn)
os.path.exists() :ファイルやフォルダが存在していればTrue、存在していなければFalseを返す。
os.mkdir() :フォルダを作成
④画像の水増し
画像を読み込み、②の関数を使用して画像の水増しを行います。
# 画像をリスト化。windowsはパスの先頭にrをつける
path_nasu = os.listdir(r"gazo\nasu_health")
#画像を読み込み、サイズ統一し、水増しを行う。× 画像枚数分
for i in range(len(path_nasu)):
img = cv2.imread(r"gazo\nasu_health/" + path_nasu[i]) #フォルダ名+名称で指定して順番に画像読み込み。
img = cv2.resize(img, (100,100)) #取得した画像はサイズが不均一なので統一する
scratch_nasu_img = scratch_image(img) # 画像の水増し
#データが[100,100,3]×枚数分のリストのため、enumerateを用いてインデックスを付与して画像番号をつける。numに画像蛮行、imには画像データを入れる。
for num, im in enumerate(scratch_nasu_img):
# 保存先のフォルダ"scratch_images/"を指定、番号を付けて保存
cv2.imwrite(fn +"/" + str((len(scratch_nasu_img)*(i)) + (num+1)) + ".jpg" ,im)
os.listdir():指定したパスのファイル、フォルダ名をリスト化
cv2.imread():指定したパスの画像を読み込む
cv2.resize(画像データ, (縦サイズ, 横サイズ)):指定した画像のサイズに変換する
enumerate():リストやタプル、文字列や辞書などの各要素にインデックスを付与して、イテラブル(for文で繰り返し処理が可能なオブジェクト)を出力する。
cv2.imwrite():指定したパスに画像を出力する。
5-2結果
下図が健康画像の水増し後の例です。水増し手法が5つのため、1枚の画像が2^5の32枚に水増し出来ました。
病気画像も上記コードのパスを変更して水増しを行います。

参考
6. 学習
ローカルで学習させると時間がかかるためここからGoogle Colaboratoryを使用します。
6-1前準備
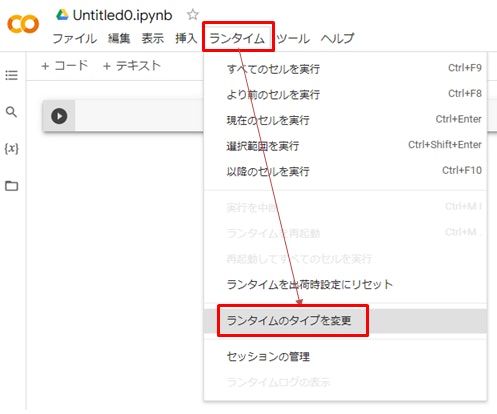
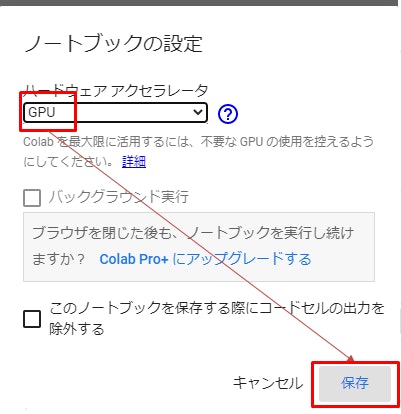
①GPUを使えるよう設定を変える
Google colaboratoryはCPUがデフォルト設定になっているためGPUを使えるようにします。
②Google Colaboratoryからデータにアクセスできるようにする
Google Colaboratoryはローカルデータにアクセスできないので、データをGoogleドライブのマイドライブに入れて、さらにGoogle Colaboratoryからマイドライブにマウント(操作・利用可能にすること)する必要があります。
以下手順
- データをファイルごと、マイドライブにドラッグ&ドロップでアップロードする
- Google Colaboratoryで下記コードを実行してマウントする。
#Googleドライブに接続
from google.colab import drive
drive.mount('/content/drive')
マイドライブのマウントはGoogle Colaboratoryの画面上のボタンとポチっと押してもいけます。
プログラム上でマウントする際に上記コードを使えばOKです。
参考:https://qiita.com/kado_u/items/45b76f9a6f920bf0f786
6-2コード
学習コードの全体像
#vgg16を用いた転移学習
#vgg16
img_size=100 #画像のサイズ
include_top = False #vgg16の下段の全結合層は使わないのでinclude_top = Fales
weights = "imagenet" #学習の重みもそのまま使うのでweights=imagentet
input_tensor = Input(shape = (img_size,img_size,3)) #100×100×3の空っぽテンソルを定義
vgg16 = VGG16(include_top = include_top, weights = weights, input_tensor = input_tensor)
#全結合層部作成
dunits1=256
drop1=0.5
dunits2=2
activation = "sigmoid"
top_model =Sequential() #モデルの箱を作るイメージ。
#全結合層を箱に追加
top_model.add(Flatten(input_shape=vgg16.output_shape[1:])) #多次元データの平滑化(ピクセルとフィルターを1次元表記)
top_model.add(Dense(dunits1, activation= activation ))
top_model.add(Dropout(drop1))
top_model.add(Dense(dunits2, activation= activation))
#vggとtop_modelを結合
model = Model(inputs = vgg16.input, outputs = top_model(vgg16.output))
#vggの層の重み変更について
L = 19
for layer in model.layers[:L]:#vgg16の19番目の層まで学習させない。
layer.trainable = False
#コンパイル
c_loss = "binary_crossentropy"
learning_rate =1e-4
momentum = 0.9
model.compile(loss=c_loss,
optimizer = optimizers.SGD(learning_rate=learning_rate, momentum=momentum),
metrics=["accuracy"])
#学習
batch_size=64
epochs=20
history = model.fit(X_train, y_train, batch_size=batch_size, epochs=epochs, validation_data=(X_test, y_test))
history_df=pd.DataFrame(history.history) #history(学習させたモデル)のhistoryオブジェクトをデータフレーム化。
print(history_df) #学習後の評価値を表示
#モデルを保存。このモデルを使ってアプリ作成を行います。
model.save('/content/drive/MyDrive/Colab Notebooks/model.hdf5')
①ライブラリをインポート
ライブラリは下記を使用しました。
import os
import cv2
import numpy as np
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras.layers import Input, Dense, Dropout, Flatten
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras import optimizers
import matplotlib.pyplot as plt
import pandas as pd
②データの読み込み
マイドライブにあるデータを読み込みます。流れは5-2-④画像の水増しの時と同じですが、画像サイズは水増し時にそろえているのでここでは省いています。
path_nasu_helth = os.listdir("/content/drive/MyDrive/Colab Notebooks/scratch_helth_img") #helthフォルダーの中のデータをリスト化
path_nasu_sick = os.listdir("/content/drive/MyDrive/Colab Notebooks/scratch_sick_img") #sickフォルダーの中のデータをリスト化
img_helth = []
img_sick = []
for i in range(len(path_nasu_helth)):
img = cv2.imread("/content/drive/MyDrive/Colab Notebooks/scratch_helth_img/" + path_nasu_helth[i])
img_helth.append(img)
for i in range(len(path_nasu_sick)):
img = cv2.imread("/content/drive/MyDrive/Colab Notebooks/scratch_sick_img/" + path_nasu_sick[i])
img_sick.append(img)
③学習用データセットと検証用データセットを作成
元のデータの順番ではデータに偏りがある可能性もありますので、順番をシャッフルしてデータセットを作成します。
X = np.array(img_helth + img_sick) #健康データと病気データを配列でまとめる。
y = np.array([0]*len(img_helth) + [1]*len(img_sick)) #正解ラベルは0は健康, 1は病気と割り当てる
#ランダムに並べ替え
rand_index = np.random.permutation(np.arange(len(X)))
X = X[rand_index]
y = y[rand_index]
#データの分割
data_f=0.8 #データの分割割合。8割が学習用データ、2割が検証用データ
X_train = X[:int(len(X)*data_f)]
y_train = y[:int(len(y)*data_f)]
X_test = X[int(len(X)*data_f):]
y_test = y[int(len(y)*data_f):]
#正解ラベルをone-hotの形にする。0(健康)→[1,0] 1(病気)→[0,1]
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
np.random.permutation():配列をランダムに並べ替える。
to_categorical():one-hotベクトルに変換。例[0, 1, 2, 3]→[[1,0,0,0] [0,1,0,0] [0,0,1,0] [0,0,0,1]]
④モデルの構築と学習
今回はvgg16モデルを用いた転移学習を行いますのを全結合層は追記します。
#vgg16
include_top = False #vgg16の下段の全結合層は使わないのでinclude_top = Fales
weights = "imagenet" #学習の重みもそのまま使うのでweights=imagentet
img_size=100 #画像のサイズ
input_tensor = Input(shape = (img_size,img_size,3)) #100×100×3の空っぽテンソルを定義
#vgg16の下段の全結合層は使わないのでinclude_top = Fales。学習の重みもそのまま使うのでweights=imagentet。
vgg16 = VGG16(include_top = include_top, weights = weights, input_tensor = input_tensor)
#全結合層部作成
u1=256
drop1=0.5
u2=2
activation = "sigmoid"
top_model =Sequential() #モデルの箱を作るイメージ。
#全結合層を箱に追加
top_model.add(Flatten(input_shape=vgg16.output_shape[1:])) #多次元データの平滑化(ピクセルとフィルターを1次元表記)
top_model.add(Dense(dunits1, activation= activation)
top_model.add(Dropout(drop1))
top_model.add(Dense(dunits2, activation= activation))
#vggとtop_modelを結合
model = Model(inputs = vgg16.input, outputs = top_model(vgg16.output))
#vggの層の重み変更について
L = 19
for layer in model.layers[:L]: #vgg16の19番目の層まで学習させない。
layer.trainable = False
#コンパイル
c_loss = "binary_crossentropy"
learning_rate =1e-4
momentum = 0.9
model.compile(loss=c_loss,
optimizer = optimizers.SGD(learning_rate=learning_rate, momentum=momentum),
metrics=["accuracy"])
#学習
batch_size=64
epochs=20
history = model.fit(X_train, y_train, batch_size=batch_size, epochs=epochs, validation_data=(X_test, y_test))
history_df=pd.DataFrame(history.history) #history(学習させたモデル)のhistoryオブジェクトをデータフレーム化。
print(history_df) #学習後の評価値を表示
#モデルを保存。colaboratoly上に置くと時間がたつと消えるのでマイドライブに保存する。
model.save('/content/drive/MyDrive/Colab Notebooks/model.hdf5')
VGG16(include_top= ,weights= , input_tensor= ):
include_topは使用したいvgg16に全結合層は含むかどうか。weightsは重みの種類で学習済みの重みを使用する場合はimagenet、そうでない場合はNone。input_tensorはインプットする画像のサイズを指定。Input(shape=(32,32,3))といった形で指定する。
Sequential():層を積み重ねたもの。.add() メソッドでレイヤーを追加できる。
Flatten():入力を平滑化する.
Dense(units, activation=):通常の全結合ニューラルネットワークレイヤー。unitsにユニット数、activationに活性化関数名を指定する。
sigmoid:分類問題(二値)によく使われる活性化関数。
Dropout:ランダムに入力ユニットを0とする割合。過学習の軽減の役割をする。
Model(inputs=, outputs=):inputsを入力、outputsを出力としてレイヤーをグループ化できる。
layer.trainable:レイヤーを訓練しないようにする。
model.compile(optimizer, loss=, metrics=):学習のためのモデルを設定する。
optimizer:最適化関数。Kerasモデルのコンパイルに必要な引数。関数はCGD、RMSpropなどいくつかある。
optimizers.SGD(learning_rate=, momentum=,):Stochastic Gradient Descent(確率的勾配降下法)。オプティマイザーの1種。learning_rate(学習率)は0~1の値(デフォルトは0.01)。momentumを設定すると最急降下の振動を緩和させて解を出す時間を短縮させることができる。デフォルトは0。
loss: 損失関数。一つひとつの出力データと教師データの差をみる。binary_crossentropyは2値分類に使用される。
metrics: 訓練時とテスト時にモデルにより評価される評価関数のリスト.一般的にはmetrics=['accuracy']を使う。
model.fit(x, y, batch_size=, epochs=, validation_data=(x',y')):xは訓練データ、yは訓練データのラベル、batch_sizeは一度に学習するサンプル数の数(デフォルトは32)、epochsは反復学習をする回数、validation_dataには各試行の最後に損失とモデル評価関数を評価する検証用データx'とその正解ラベルy'を指示。historyオブジェクトを戻り値としている。
history:学習実行に成功したエポックにおける訓練の損失値と評価関数値の記録と,検証における損失値と評価関数値を記録している。
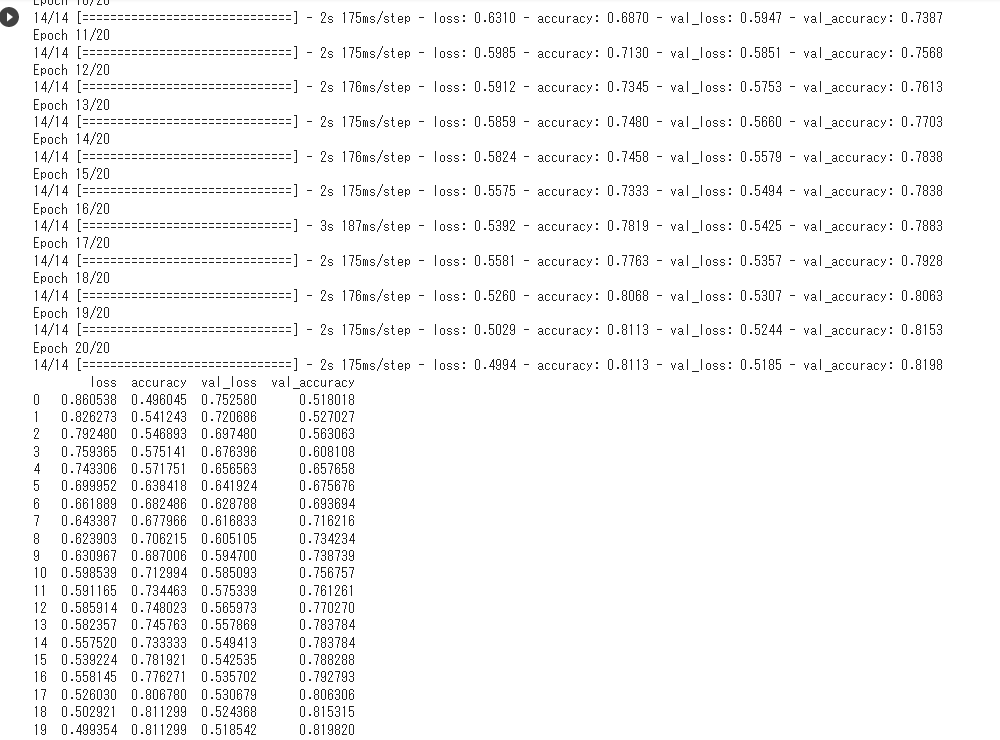
6-3結果
指示したepock数まで学習が完了し、評価関数値のエポック履歴が確認できました。これでモデルの完成です!
マイドライブ上でhdf5ファイルのモデルが保存されていることも確認できるかと思いますが、このモデルを使用してアプリを作成することができます。
参考
7. 学習に使用したパラメータと精度評価結果を保存
上記まででモデルは一通り完成です。番外編として、精度向上のためのキャリブレ時に役立つパラメータと精度評価結果を保存するプログラムも作成します。
7-1コード
パラメータと精度評価結果を保存するコードの全体像
#学習に使用したパラメータと精度評価結果を保存
#historyから最終的な評価値を読み込む
acc = history_df.iloc[-1]["accuracy"]
test_acc = history_df.iloc[-1]["val_accuracy"]
loss = history_df.iloc[-1]["loss"]
test_loss = history_df.iloc[-1]["val_loss"]
#学習に使用したパラメータと精度評価結果をシリーズ化
para_name=["include_top","weights","data_f", "img_size", "dunits1", "drop1", "dunits2","L",
"C_loss","learning_rate","momentum", "batch_size", "epochs","loss", "accuracy","test_loss", "test_accuracy"]
para=[include_top, weights, data_f, img_size, dunits1, drop1, dunits2, L,
c_loss, learning_rate, momentum, batch_size, epochs,loss, acc, test_loss, test_acc]
para_s = pd.Series(para, index=para_name) #直接データフレームで作ると整理しにくいので一度Seriesのindexで項目名を固定
para_df = pd.DataFrame(para_s)#データフレーム化
#csvファイルに保存
#ファイルがなければ新規作成
if not os.path.isfile("/content/drive/MyDrive/Colab Notebooks/para.csv"):
df = para_df.T #seriesとdataframeは行列が逆なので転置しておく。
df.to_csv("/content/drive/MyDrive/Colab Notebooks/para.csv") #csv保存
#既存ファイルがあれば今回取得した値を追記
else:
df=pd.read_csv("/content/drive/MyDrive/Colab Notebooks/para.csv", header = 0, index_col = 0).T #データを読み込み、追記しやすいように転置する。
df=pd.concat([df, para_df],axis=1).T #今回データを既存データに追加し、見やすくするように転置する。
df.index=range(1,len(df)+1) #通し番号でナンバリングするためindexを指示。
df.to_csv("/content/drive/MyDrive/Colab Notebooks/para.csv") #csv保存
#既存値含めてモデルのパラメータと評価関数値を出力
print(df)
#epoch履歴のプロットと画像として保存
#保存フォルダ作成
if not os.path.exists("/content/drive/MyDrive/Colab Notebooks/graph"):
os.mkdir("/content/drive/MyDrive/Colab Notebooks/graph")
#accグラフ作成&保存
graph = history_df[["accuracy","val_accuracy"]].plot()
plt.ylabel("accuracy")
plt.xlabel("epoch")
plt.legend(loc="best")
plt.savefig("/content/drive/MyDrive/Colab Notebooks/graph/No{}_acc.jpg".format(len(df))) #画像保存。plt.showの前に実行しないと白紙がデータ保存される。
plt.show()
#lossグラフ作成&保存
history_df[["loss","val_loss"]].plot()
plt.ylabel("loss")
plt.xlabel("epoch")
plt.legend(loc="best")
plt.savefig("/content/drive/MyDrive/Colab Notebooks/graph/No{}_loss.jpg".format(len(df)))
plt.show()
①必要なパラメータと精度評価結果をまとめる
今回取得した値をまとめます。
#historyから最終的な評価値を読み込む
acc = history_df.iloc[-1]["accuracy"]
test_acc = history_df.iloc[-1]["val_accuracy"]
loss = history_df.iloc[-1]["loss"]
test_loss = history_df.iloc[-1]["val_loss"]
#学習に使用したパラメータと精度評価結果をシリーズ化
para_name=["include_top","weights","data_f", "img_size", "dunits1", "drop1", "dunits2","L",
"C_loss","learning_rate","momentum", "batch_size", "epochs","loss", "accuracy",
"test_loss", "test_accuracy"]
para=[include_top, weights, data_f, img_size, dunits1, drop1, dunits2, L,
c_loss, learning_rate, momentum, batch_size, epochs,loss, acc,
test_loss, test_acc]
para_series = pd.Series(para, index=para_name) #直接データフレームで作ると整理しにくいので一度Seriesのindexで項目名を固定
para_df = pd.DataFrame(para_s)#データフレーム化
②csvファイルに保存
まとめた項目と値をcsvファイルに保存します。初回とそれ以降でcsvファイルの作成有無が変わってくるためif文で条件付けします。
#ファイルがなければ新規作成
if not os.path.isfile("/content/drive/MyDrive/Colab Notebooks/para.csv"):
df = para_df.T #seriesとdataframeは行列が逆なので転置しておく。
df.to_csv("/content/drive/MyDrive/Colab Notebooks/para.csv") #csv保存
#既存ファイルがあれば今回取得した値を追記
else:
df=pd.read_csv("/content/drive/MyDrive/Colab Notebooks/para.csv", header = 0, index_col = 0).T #データを読み込み、追記しやすいように転置する。
df=pd.concat([df, para_df],axis=1).T #今回データを既存データに追加し、見やすくするように転置する。
df.index=range(1,len(df)+1) #通し番号でナンバリングするためindexを指示。
df.to_csv("/content/drive/MyDrive/Colab Notebooks/para.csv") #csv保存
#既存値含めてモデルのパラメータと評価関数値を出力
print(df)
③epock履歴のプロット表示と画像として保存
epock数の最適化検討時のためにepock履歴をグラフで表示し、画像保存も行います。
#保存フォルダ作成
if not os.path.exists("/content/drive/MyDrive/Colab Notebooks/graph"):
os.mkdir("/content/drive/MyDrive/Colab Notebooks/graph")
#accグラフ作成&保存
graph = history_df[["accuracy","val_accuracy"]].plot()
plt.ylabel("accuracy")
plt.xlabel("epoch")
plt.legend(loc="best")
plt.savefig("/content/drive/MyDrive/Colab Notebooks/graph/No{}_acc.jpg".format(len(df))) #画像保存。plt.showの前に実行しないと白紙がデータ保存される。
plt.show()
#lossグラフ作成&保存
history_df[["loss","val_loss"]].plot()
plt.ylabel("loss")
plt.xlabel("epoch")
plt.legend(loc="best")
plt.savefig("/content/drive/MyDrive/Colab Notebooks/graph/No{}_loss.jpg".format(len(df)))
plt.show()
7-2結果
ターミナルにはパラメータ&評価関数値の表と、epoch履歴の評価関数値グラフが出力され、それぞれがcsvファイルと画像ファイルで出力されます。
最終的に正解率は約80%以上の値を示しました。
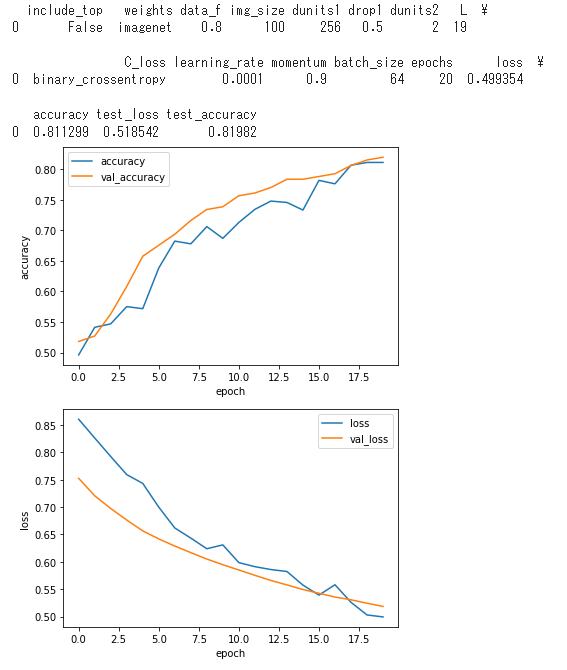
初回のcsvファイルは下記のように1行で作成されます。

2回目以降は前回記録に追記されていきます。パラメータ変更による傾向分析に用いたり、うっかり最適パラメータを忘れてしまった場合も心配いりません。

8. モデルを使って新たなデータを判定してみる
モデルの動作確認を含め、学習にも検証にも使用されていないナスの葉っぱの画像で健康状態を判定してみます。
アプリ作成時に確認してもよいですが、複数枚の画像を判別させるのはプログラムでやる方が楽なのでやっちゃいます。
8-1前準備
健康なナスの葉と病気のナスの葉の画像を新たにwebで探して数枚ずつマイドライブの任意のフォルダに保存します。
モデル作成時に検証用データでも判定は行っていますがベースデータが少なかったことが不安要素のため、全く異なる画像でも判定できるかの検証の意を込めて新しい画像を使います。
データ収集ではbingを使ったので、googleやyahooなど別の検索エンジンを使えば割と違う画像が出てきやすいです。
8-2 コード
import random
def pred_helth(img):
x = np.argmax(model.predict(img.reshape(1,img_size,img_size,3)))
if x==0:
return "helth"
else:
return "sick"
#フォルダーにある画像からn枚ランダムに判定する。
path_nasu_test = os.listdir("/content/drive/MyDrive/Colab Notebooks/nasu_img") #画像をリスト化
random.shuffle(path_nasu_test) #リスト化された画像の順番をシャッフル
n = 10 #判定を行う画像の枚数
for i in range(n):
img = cv2.imread("/content/drive/MyDrive/Colab Notebooks/nasu_img/" + path_nasu_test[i])
img = cv2.resize(img,(img_size,img_size))
b,g,r = cv2.split(img) #画像の色素情報を取り出す
img = cv2.merge([r,g,b]) #OpenCVは色素の並びがBGRのため、RGBへ並び替え
plt.imshow(img) #imgは配列のままなので画像に変換
plt.show() #画像を表示
print(pred_helth(img)) #判定結果を表示
8-3結果
10枚(健康:病気=6:4)中、7枚正解(健康:病気=4:3)と正解率7割でした。モデル精度80%に近い正解率です。
下記画像は評価結果を一部抜粋しています。(左から1,2枚目は健康、3枚目は病気なので、1枚目は正解、2,3枚目は不正解)

9. FlaskとHerokuを使ってアプリ制作
hdf5ファイルのモデルをFlask形式に変換し、Herokuでデプロイしてwebアプリを作成します。Google Colaboratoryでのやり方はよくわからなかったのでVisual Studio Codeを使用しました。
9-1前準備
①アプリに必要な下記を準備します
main.py
メインコードを記載したpythonファイル。 今回は下記のように作成しました。import os
from flask import Flask, request, redirect, render_template, flash
from werkzeug.utils import secure_filename
from tensorflow.keras.models import load_model
import numpy as np
import cv2
classes = ["健康","病気"]
message = ["この調子で育てていきましょう!","すぐに除去しましょう!"]
image_size = 100
UPLOAD_FOLDER = "uploads" #アップロードする画像を保存するフォルダ
ALLOWED_EXTENSIONS = set(['png', 'jpg', 'jpeg', 'gif']) #アップロードを許可する画像の拡張子を指定
#Flaskクラスのインスタンスを作成。
app = Flask(__name__)
app.secret_key = "hogehoge"
#アップロードされたファイルの拡張子チェックの関数
def allowed_file(filename):
#filenameに"."が含まれている&ALLOWED_EXTENSIONSのどれかにfilenameの拡張子が含まれているときにTrueを返す。
return '.' in filename and filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS
#学習済みモデルをロード
model = load_model('./model.hdf5')
@app.route('/', methods=['GET', 'POST']) #指定されたurlにアクセスすると次の行の関数を呼び出す。GET or POSTはhtmlファイルで指定される
def upload_file():
if request.method == 'POST': #index.htmlが読み込まれ、submitボタンが押されるとmethodにPOSTが入るのでif分に入る
#ファイル名がない=ファイルがアップロードされていないとき
if file.filename == '':
flash('ファイルを選択してください',"No_file")
print("ファイルを選択してください")
print(request.files)
return redirect(request.url)
#許可した拡張子でないとき
if not allowed_file(file.filename):
flash('ファイルの名前を確認してください',"check_name")
print(request.files)
return redirect(request.url)
#ファイルがある&拡張子チェックOKのとき
if file and allowed_file(file.filename):
filename = secure_filename(file.filename)
file.save(os.path.join(UPLOAD_FOLDER, filename)) #UPLOAD_FOLDERフォルダに画像を保存
filepath = os.path.join(UPLOAD_FOLDER, filename) #画像のパスを読み込む
#受け取った画像を読み込み、モデルで予測
img = cv2.imread(filepath)
img = cv2.resize(img, (image_size, image_size))
predicted = np.argmax(model.predict(img.reshape(1, image_size, image_size, 3)))
#予測した結果の回答テンプレート
pred_answer = "このナスは " + classes[predicted] + " です"
pred_massage = message[predicted]
return render_template("index.html",answer=pred_answer, answer2=pred_massage)
return render_template("index.html",answer="") #初回はmethodが不明なので上記if分には入らず、index.htmlが表示される。
if __name__ == "__main__":
port = int(os.environ.get('PORT', 8080))
app.run(host ='0.0.0.0',port = port)
作成したモデル
hdf5ファイルなどProcfile
拡張子無しファイル。Herokuのプラットフォール上にあるwebアプリがどのようなコマンドで実行されるのかを記述するファイルです。mayn.pyを実行させたいので下記を記述します。メモ帳などで作成できます。web: python main.py
requirments.txt
テキストファイル。必要なライブラリを記述することでHerokuの自分のアプリにインストールできます。 今回使っていないものも多いですが下記が参考です。absl-py==0.9.0
astor==0.8.1
bleach==3.1.5
bottle==0.12.18
click==7.1.2
certifi==2020.6.20
chardet==3.0.4
flask==2.0.1
future==0.18.2
gast==0.3.3
grpcio==1.31.0
gunicorn==20.0.4
h5py==2.10.0
html5lib==1.1
itsdangerous==2.0
idna==2.10
Jinja2==3.0.1
line-bot-sdk==1.16.0
Markdown==3.2.2
MarkupSafe==2.0
numpy==1.18.0
oauthlib==3.1.0
opencv-python-headless==4.5.5.64
pillow==7.2.0
protobuf==3.12.4
PyYAML==5.4.1
python-dotenv==0.14.0
requests==2.25.1
scipy==1.4.1
six==1.15.0
tensorboard==2.3.0
tensorflow-cpu==2.3.0
termcolor==1.1.0
urllib3==1.26.5
Werkzeug==2.0.0
runtime.txt
試用するpythonのバージョン情報を記述します。python-3.8.10
index.html
アプリのHTMLファイル<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>ナスの葉の健康診断</title> <!--タブに現れる文字-->
<link rel="stylesheet" href="./static/stylesheet.css">
</head>
<body>
<header>
<a class="header-logo" href="#">ナスの葉健康診断</a>
</header>
<div class="main">
<h2>送信されたナスの葉画像から病気の有無を診断します</h2>
<p>画像を送信してください(拡張子:png, jpg, jpeg, gif)</p>
<form method="POST" enctype="multipart/form-data">
<input class="file_choose" type="file" name="file">
<input class="btn" value="submit!" type="submit">
</form>
<div class="answer">{{answer}}</div>
<div class="answer2">{{answer2}}</div>
</div>
{% with messages = get_flashed_messages(with_categories=true) %} <!--引数にwith_categories=trueを入れることで2つ目の文字列を紐づけられる-->
{% if messages %}
{% for category, message in messages %}
<div class = flashes>{{ message }}</div> <!---->
{% endfor %}
{% endif %}
{% endwith %}
<footer>
<img class="footer_img" src="\static\なす.png" alt="">
<img class="footer_img" src="\static\なす.png" alt="">
<img class="footer_img" src="\static\なす.png" alt="">
<small> nasu 2022</small>
</footer>
</body>
</html>
stylesheet.css
アプリのCSSファイルheader {
background-color: #b605b0; /*背景色指定*/
height: 60px; /*高さ*/
margin: -8px; /*要素の全四辺のマージン領域。マイナスなので四方に8pxはみ出す方向*/
display: flex; /*レイアウトの種類:フレックスコンテナを指定。要素を横や縦に並べられる*/
flex-direction: row; /*フレックスアイテムの方向:row=左詰め*/
justify-content: start; /*フレックスコンテナの中身の配置間隔を配置する方法を定義。start:先頭に寄せる*/
}
.header-logo {
color: #fff;
font-size: 25px;
margin: 15px 25px; /*上下左右のマージン*/
}
h2 {
color: #444444;
margin: 90px 0px;
text-align: center; /*水平方向の配置を設定*/
}
p {
color: #444444;
margin: 70px 0px 30px 0px; /*上、右、下、左*/
text-align: center;
}
.answer {
color: #444444;
margin: 70px 0px 0px 0px;
text-align: center;
}
.answer2 {
color: #444444;
margin: 10px 0px 30px 0px;
text-align: center;
}
.flashes {
color: #f90c10;
margin: 0px 0px 30px 0px;
text-align: center;
}
form {
text-align: center;
}
footer {
background-color: #F7F7F7;
height: 80px;
margin: -8px;
position: relative; /* top, right, bottom, left の値に基づいて自分自身からの相対オフセットで配置*/
}
.footer_img {
height: 50px;
margin: 15px 0px 15px 30px;
position: relative;
}
small {
position: absolute; /*ページ全体or親に対して絶対座標。親要素にrelativeがついていれば子がabsoluteを使ってもはみ出ない。*/
left: 20px;
bottom: 0;
}
②上記ファイルを下記の構成で1つのフォルダにまとめます。
C:\APP #親フォルダ
│ main.py
│ model.hdf5
│ Procfile
│ requirements.txt
│ runtime.txt
│
├─static
│ stylesheet.css
│ なす.png #表示させたい画像があれば。無くてもよい。
│
├─templates
│ index.html
│
└─uploads
9-2デプロイ
下記手順でデプロイし、モデルの動作確認ができればOKです。
cd ファイルパス #アプリのあるディレクトリへ移動
heroku login #Herokuへログイン。(メールアドレスやパスワードの登録が必要)
#HerokuでCreate New Appボタンを押し、App nameを入力して新規アプリを作成。国はUnited Statesで登録する。
#アプリページsettingからAdd buildpackをクリックしてpythonを追加。
heroku create #アプリ名 --buildpack heroku/python
#下記コマンドを入力。
git init #(初回のみ)
heroku git:remote -a アプリ名
git add .
git commit -m 'コメントを記載' #履歴コメント
git push heroku master
heroku open #ブラウザでデプロイしたwebアプリが立ち上がる
https://nasu-app-2022.herokuapp.com/
参考
10. 考察
10-1 データ収集に関する考察
不要な画像が多く引っ掛かったのは、画像をアップロードする側がその画像をどういう説明に用いたかが影響してくるからだと考えられます。例えば健康状態を説明するサイトで代表的なナスの病気も紹介していれば、病気状態の画像も検索結果として出てしまいます。”キーワード”で画像検索する以上これは避けられないと考えられます。水増し以外の対策としてはキーワードを変えて地道にデータ数を増やすか、検索エンジンの画像検索機能(対象の画像と似ている画像を探す機能)を使うことが挙げられますが、後者はicrawlerでは活用できないので自動化するには別の手法を考える必要があります。
10-2 学習に対する考察
2値分類で精度が出やすかったためパラメータの最適化検証は行っていませんが、epoch履歴を見ても評価関数値は収束していないのでepoch数を増やせば精度向上が見込めることがわかります。ただepoch数足らずで再学習させるのは時間がもったいないので、EarlyStoppingというオブジェクトを利用してモデルの改善が止まるまで学習を続けることが有効的であることがわかりました。
10-3 モデルを使ったデータ判定について
8-3結果の3枚目の画像は黒っぽい斑点が黒枯病という病気の特徴ですが、2枚目の健康画像を見ても葉に黒っぽい斑点が見られます。おそらくこれは葉の葉脈で、画像リサイズ時に葉脈が途切れるもしくは周辺部に影響を及ぼしたものと考えられます。だとすれば水増し、リサイズなどをする際は、画像を加工することで好ましくない特徴が出ないか全てチェックを行う必要があると言えます。
11. おわりに
プログラミングは学生の時にC言語を授業で習った程度で、アプリを1から作るのは初めてでしたがとても楽しく学習することができました。
難しいと感じたのはデータの集め方です。
本アプリを実用化するには果実や茎に症状が出る病気や、ナス別、病気別の判定することが望ましいですが、それぞれの画像をweb上で集めるのは非常に困難です。
仮にナス農家でデータを自作するにしても、症状に対してアングル、画格、葉の表裏、実の断面など様々な状況を想定しなければいけません。
そもそも通常病気の個体は無いことが理想なので十分なデータが取れるかも不明です。
ディープラーニングは日々の積み重ねが大前提の技術であることを実感しました。
今後も独学で勉強は続けて本業や副業に繋げたいと思います。