はじめに
- 乃木坂46と欅坂46と日向坂46のブログをスクレイピングしました。
- スクレイピングした際のコードを公開してます。興味があれば使ってみて下さい。
- 使用言語はPythonでBeautiful Soup使ってます。
コード
- 言語: Python
- 使用ライブラリ: Beautiful Soupなど
- GitHubリポジトリ: https://github.com/haradai1262/keyakizaka46-mining
Pythonスクリプト
import pandas as pd
import re, requests
from bs4 import BeautifulSoup
import datetime
from dateutil.relativedelta import relativedelta
# nogizaka
def get_month_list( start, end ):
start_dt = datetime.datetime.strptime(start, "%Y%m")
end_dt = datetime.datetime.strptime(end, "%Y%m")
lst = []
t = start_dt
while t <= end_dt:
lst.append(t)
t += relativedelta(months=1)
return [x.strftime("%Y%m") for x in lst]
def get_nogi_articles_from_single_page( page_soup ):
titles = [ i.find('span', class_='entrytitle').text for i in page_soup.find_all('h1', class_='clearfix') ]
authors = [ i.text for i in page_soup.find_all('span', class_='author') ]
datetimes = [ i.text.split('|')[0].replace(' ','').replace('\n','') for i in page_soup.find_all('div', class_='entrybottom') ]
texts = []
images = []
for i, j in enumerate( page_soup.find_all('div', class_='entrybody') ): # 画像URL抽出 ... アドホックな処理多いので注意
image_urls = []
for img in j.find_all('img', src=re.compile("^http(s)?://img.nogizaka46.com/blog/")):
if img.get('src')[-4:] == '.gif':continue
if not img.get('class') == None:
if img.get('class')[0] == 'image-embed':
continue
image_urls.append( img.get('src') )
image_str = ''
for img in image_urls: image_str += '%s\t'% img
texts.append( j.text )
images.append( image_str )
articles = []
for i in range( len( titles ) ):
articles.append( [authors[i], datetimes[i], titles[i], texts[i], images[i]] )
return articles
headers = {'User-Agent':'Mozilla/5.0'}
start = '201111'
end = '201901'
month_list = get_month_list( start, end )
all_articles = []
for date in month_list:
print( date )
target_url = 'http://blog.nogizaka46.com/?p=%d&d=%s' % (page_idx, date)
r = requests.get(target_url, headers=headers)
soup = BeautifulSoup(r.text, 'lxml')
max_page_number = int( soup.find('div', class_='paginate').find_all('a')[-2].text.replace(u"\xa0",u"") ) # これでいいのか?
for page_idx in range( 1, max_page_number+1, 1 ):
target_url = 'http://blog.nogizaka46.com/?p=%d&d=%s' % (page_idx, date)
r = requests.get(target_url, headers=headers)
soup = BeautifulSoup(r.text, 'lxml')
page_articles = get_nogi_articles_from_single_page( soup )
all_articles.extend( page_articles )
df = pd.DataFrame( all_articles, columns=['author', 'datetime', 'title', 'text', 'images'] )
df.to_csv( '../data/nogizaka46_blog.csv', index=0 )
# keyakizaka
def get_keyaki_articles_from_single_page( page_soup ):
articles = []
for i, j in enumerate( page_soup.select('article') ):
author = j.p.text.replace(' ','').replace('\n','')
datetime = j.find('div', class_="box-bottom").li.text.replace(' ','').replace('\n','')
title = j.find('div', class_="box-ttl").a.text
body = j.find('div', class_="box-article")
text = body.text
images = ''
for img in body.find_all('img'): images += '%s\t'% img.get('src')
articles.append( [author, datetime, title, text, images] )
return articles
max_page_number = 814
all_articles = []
for page_idx in range( max_page_number, -1, -1 ):
if page_idx % 100 == 0: print(page_idx)
target_url = 'http://www.keyakizaka46.com/s/k46o/diary/member/list?ima=0000&page=%d&cd=member' % page_idx
r = requests.get(target_url)
soup = BeautifulSoup(r.text, 'lxml')
page_articles = get_keyaki_articles_from_single_page( soup )
all_articles.extend( page_articles )
df = pd.DataFrame( all_articles, columns=['author', 'datetime', 'title', 'text', 'images'] )
df.to_csv( '../data/keyakizaka46_blog.csv', index=0 )
ちょっとだけ中身確認
pandasで中身確認

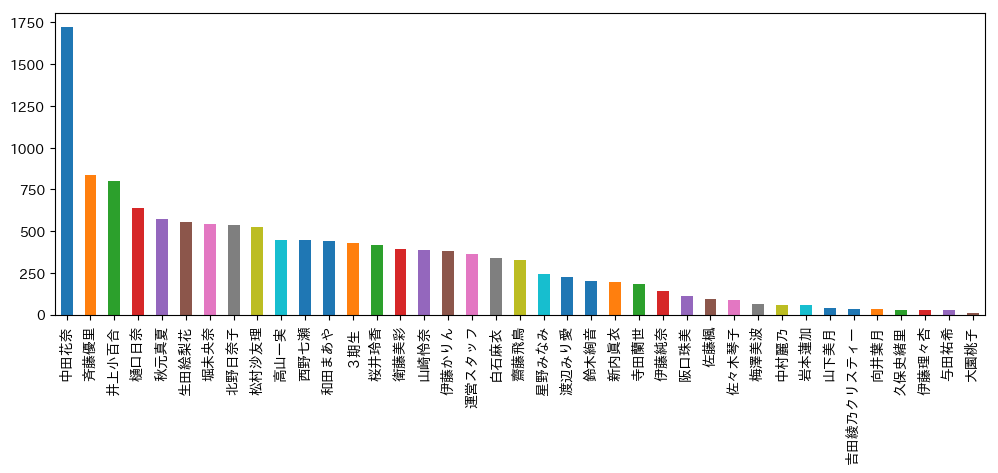
各メンバの投稿記事数をプロット
乃木坂46
欅坂46&けやき坂46
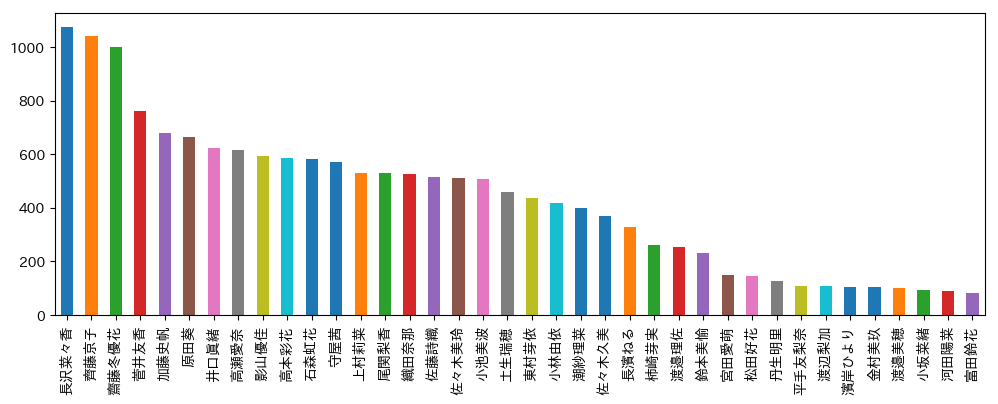
収集したブログを使った解析
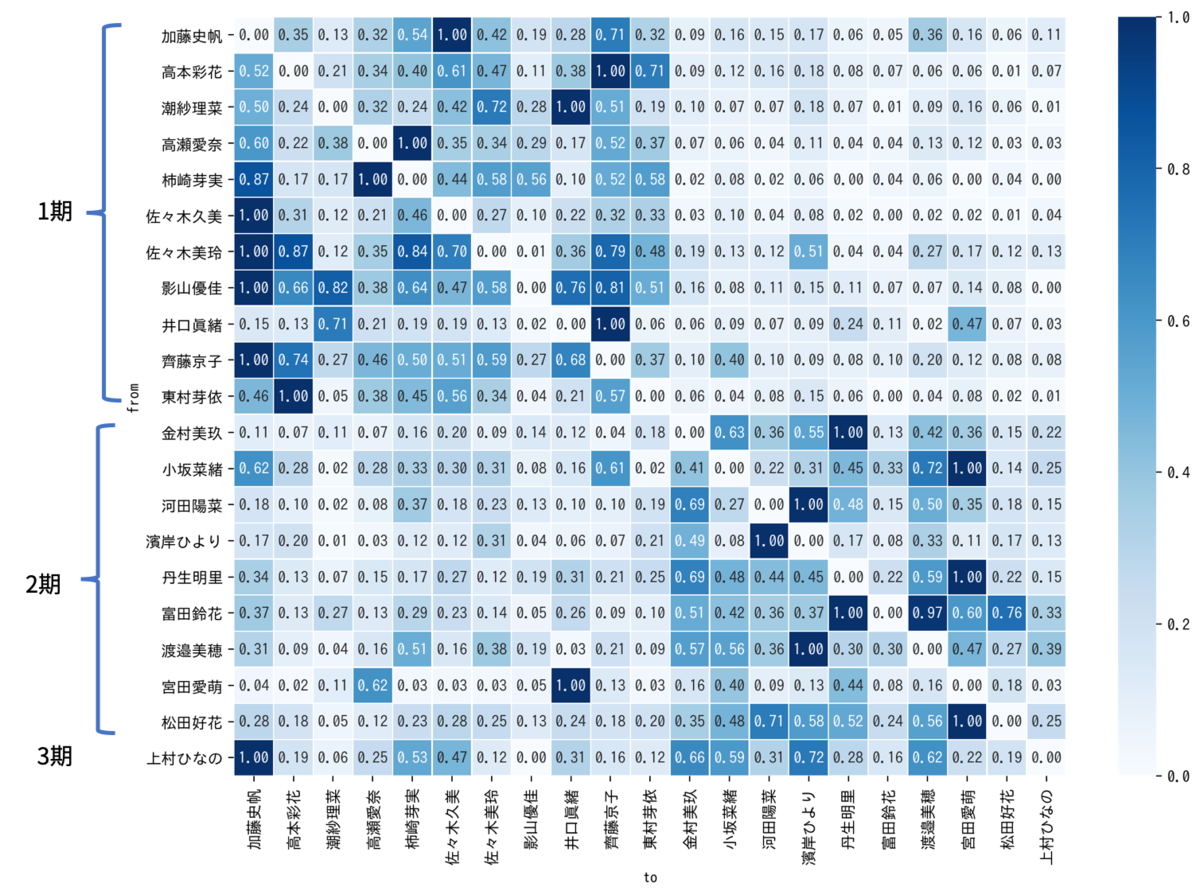
ブログ解析による欅坂46メンバの相関図作成
- 欅坂46メンバの公式ブログを解析し、メンバ間の関係を抽出して相関図を作成した。

ブログ解析による日向坂46メンバの相関図作成
乃木坂46・欅坂46・けやき坂46のブログから単語分散表現を学習
- 乃木坂46・欅坂46・けやき坂46のブログから単語分散表現を学習した。

修正
- 2019/01/14 GitHubレポジトリからcsvファイル削除、ダウンロードリンクを削除