はじめに
本記事では、SCDV(Sparse Composite Document Vectors)により、Qiita記事のベクトルを作成した。
以降、Qiita記事のベクトルをQiitaベクトルと呼ぶ。
本記事の概要
- [作成] Qiita記事を収集し、SCDVによるQiitaベクトルを作成
- [実験] Qiitaベクトルを用いて、Qiitaでのタグ、投稿者、組織間の類似度を観察
- [今後の課題] やってみると、微妙なところが気になったのでv0.1にした。試したいことが色々でてきた。
SCDVとは
SCDVは、EMNLP2017で発表された文書ベクトル作成手法[元論文]
文書ベクトルは、以下の特徴を持つ。
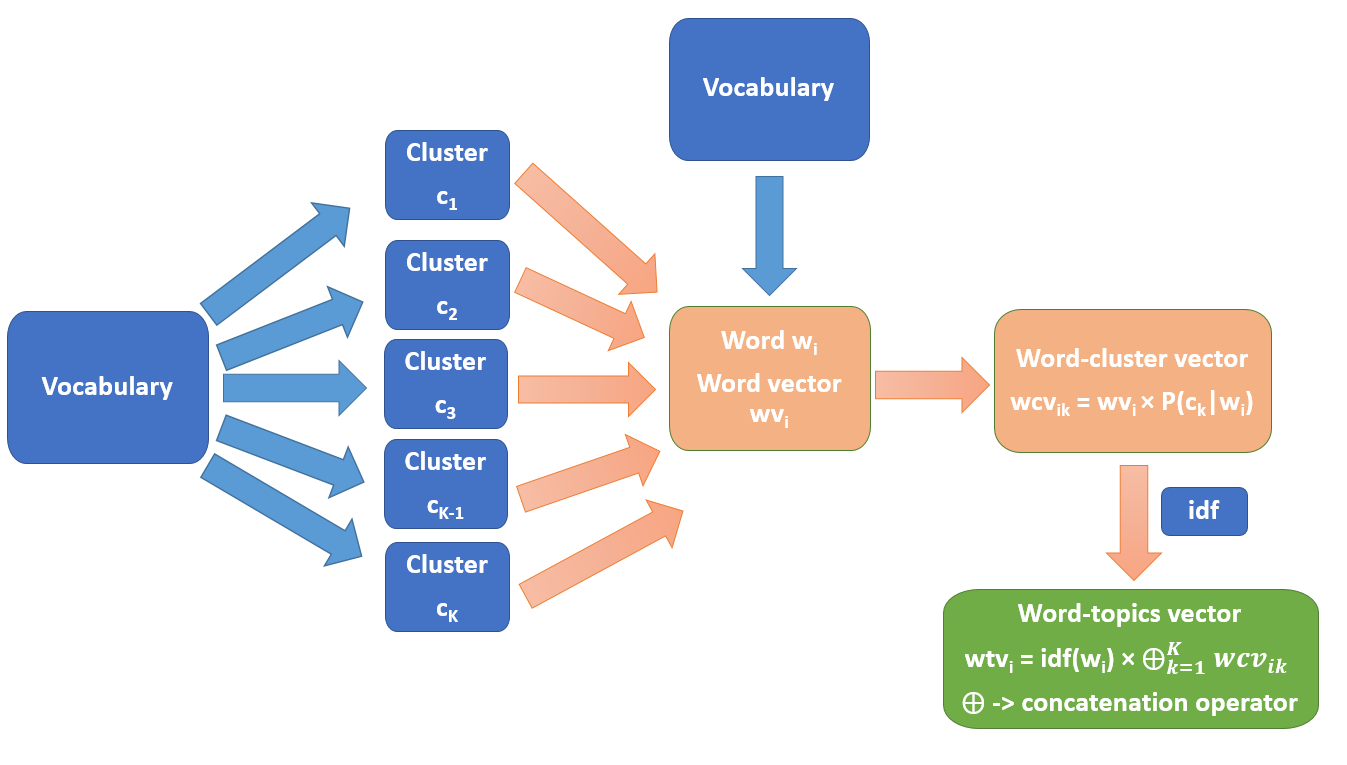
- Word-topics vectorにより高い表現力を実現
- Word-topics vectorは、単語の潜在的な複数のトピックを考慮する。具体的には、単語ベクトルへソフトクラスタリング(GMM)を適用し、各クラスタへの帰属度および文書のIDF値を考慮して、クラスタの数だけ単語ベクトルを連結する
- スパース化により計算効率の向上およびノイズ除去を実現(?)
元論文では英語文書の分類タスクで高い精度を確認している。
また、以下の記事では日本語文書において検証されている。
以下は手法の概要図である。こちらは著者ホームページより抜粋。
- Precomputation of word-topics vector
- Building sparse document vectors using word-topics vectors
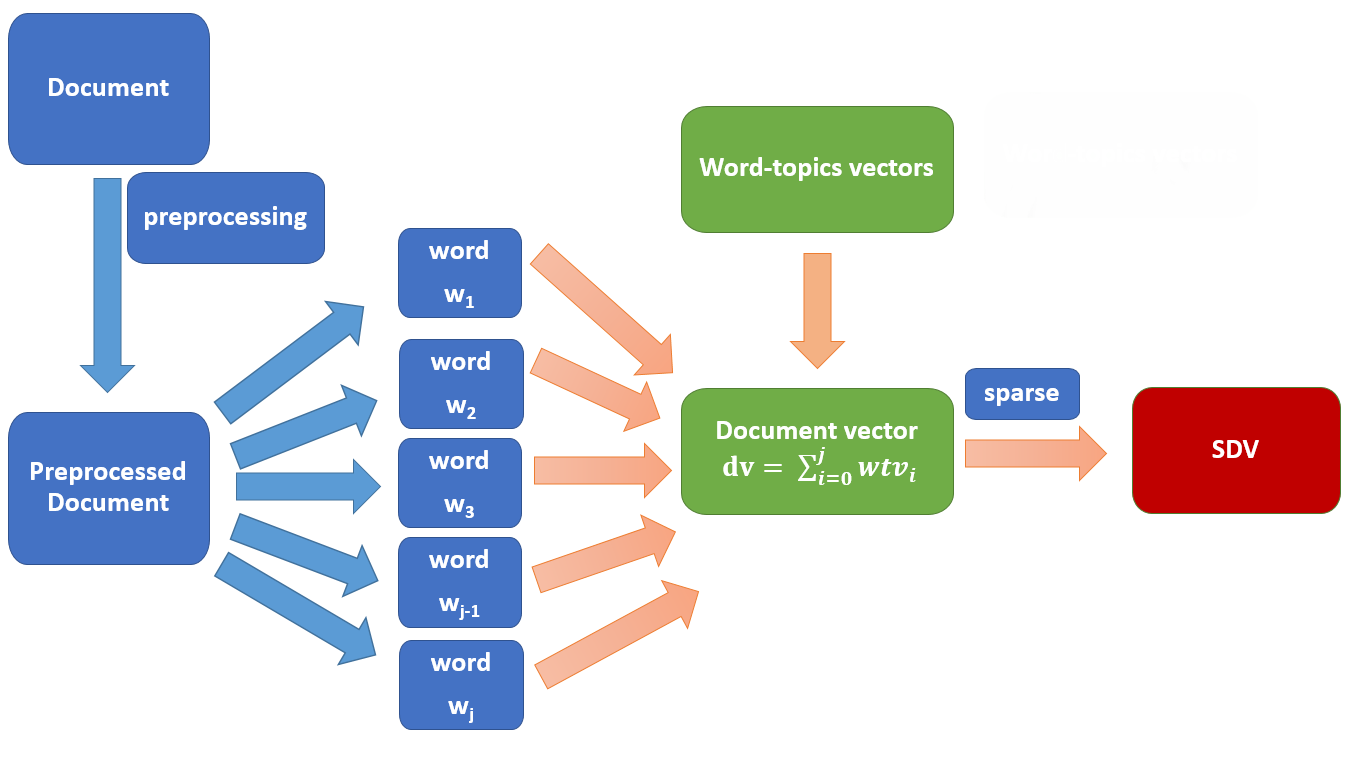
Qiitaベクトルの作成
参考にしたコード
Qiita記事取得
- 2011/9 - 2019/2の間の358574本の記事を取得した
- 本文はrendered_textからpタグ内のtextのみ取得。コード等は無視。
SCDVにより記事ベクトルを作成
今回は、Qiita記事のテキストをfastTextにより学習し、得られた単語ベクトルを用いてSCDVにより文書ベクトルを作成した。
テキスト前処理
- MeCabによる形態素解析
- 使用した品詞: 名詞、動詞、形容詞のみ
- 使用した辞書: IPA辞書+頻出Qiitaタグのユーザ辞書を作成。頻出Qiitaタグは、10以上の記事に付与されているものとした。今回の実験では、6049個。
fastTextの学習
fastTextの学習にはgensimを使用した。
from gensim.models import FastText
# hyper parameters
num_features = 300 # fastText embedding dim
min_word_count = 10 # Minimum word count
context = 10 # Context window size
# learn fastText
w2v_model = FastText(size=num_features, sg=1, workers=-1, window=context, min_count=min_word_count)
w2v_model.build_vocab( sentences )
w2v_model.train(sentences, total_examples=w2v_model.corpus_count, epochs=w2v_model.epochs)
SCDVによる文書ベクトル作成
from sklearn.mixture import GaussianMixture
# hyper parameters
num_clusters = 30 # cluster num of GMM clustering
sparse_percentage = 0.01
# train scdv
gmm = GaussianMixture(n_components=num_clusters, covariance_type="tied", init_params='kmeans', max_iter=50)
scdv_model = SCDV(w2v_model=w2v_model, sc_model=gmm, sparse_percentage = sparse_percentage )
scdv_model.precompute_word_topic_vector(sentences)
X = scdv_model.train(sentences)
class SCDV(object):
"""
w2v_model: gensim_w2v_model
softclustering_model: sklearn_gmm (gmm only?)
sparse_percentage: the threshold percentage for making it sparse
"""
def __init__(self, w2v_model, sc_model, sparse_percentage):
# values
self.w2v_model = w2v_model
self.num_clusters = sc_model.n_components
self.w2v_vector_size = w2v_model.vector_size
self.min_no = .0
self.max_no = .0
self.sparse_percentage = sparse_percentage
# apply soft clustering to embedding vectors
self.w2v_vectors = w2v_model.wv.vectors
idx, idx_proba = self._soft_clustering( sc_model, self.w2v_vectors)
self.word_centroid_map = dict( zip( w2v_model.wv.index2word, idx ) ) # Create a Word / Index dictionary, mapping each vocabulary word to a cluster number
self.word_centroid_prob_map = dict(zip( w2v_model.wv.index2word, idx_proba )) # Create a Word / Probability of cluster assignment dictionary, mapping each vocabulary word to list of probabilities of cluster assignments.
return
def precompute_word_topic_vector( self, sentences ):
# compute idf values
self.featurenames, self.word_idf_dict = self._compute_idf_values( sentences )
# compute word topic vectors
self.wv = self._get_probability_word_vectors()
return
def train( self, sentences ):
# values
doc_num = len(sentences)
# get document vector
X = np.zeros( (doc_num, self.num_clusters*self.w2v_vector_size), dtype="float32")
for idx, tokens in enumerate( sentences ):
X[idx] = self._create_cluster_vector_and_gwbowv( tokens, train=True)
# get the threshold value for making it sparse.
thres = (abs( self.max_no / float( doc_num ) ) + abs( self.min_no / float( doc_num ) )) / 2
self.sparse_thres = thres * self.sparse_percentage
# Make values of matrices which are less than threshold to zero.
temp = abs(X) < self.sparse_thres
X[temp] = 0
return X
def infer_vector( self, sentences ):
# values
doc_num = len(sentences)
# get document vector
X = np.zeros( (doc_num, self.num_clusters*self.w2v_vector_size), dtype="float32")
for idx, tokens in enumerate( sentences ):
X[idx] = self._create_cluster_vector_and_gwbowv( tokens, train=False)
# Make values of matrices which are less than threshold to zero.
temp = abs(X) < self.sparse_thres
X[temp] = 0
return X
def _create_cluster_vector_and_gwbowv( self, wordlist, train=False):
bag_of_centroids = np.zeros( self.num_clusters * self.w2v_vector_size, dtype="float32" )
for word in wordlist:
if not word in self.word_centroid_map: continue
bag_of_centroids += self.wv[word]
norm = np.sqrt(np.einsum('...i,...i', bag_of_centroids, bag_of_centroids))
if norm != 0: bag_of_centroids /= norm
# to make feature vector sparse, make note of minimum and maximum values.
if train:
self.min_no += min(bag_of_centroids)
self.max_no += max(bag_of_centroids)
return bag_of_centroids
def _get_probability_word_vectors( self ):
prob_wordvecs = {}
for word in self.word_centroid_map:
prob_wordvecs[word] = np.zeros( self.num_clusters * self.w2v_vector_size, dtype="float32" )
for c_idx in range(0, self.num_clusters):
if not word in self.word_idf_dict: continue
prob_wordvecs[word][c_idx*self.w2v_vector_size:(c_idx+1)*self.w2v_vector_size] = self.w2v_model.wv[word] * self.word_centroid_prob_map[word][c_idx] * self.word_idf_dict[word]
return prob_wordvecs
@staticmethod
def _soft_clustering( sc_model, word_vectors):
sc_model.fit(word_vectors)
idx = sc_model.predict(word_vectors)
idx_proba = sc_model.predict_proba(word_vectors)
return (idx, idx_proba)
@staticmethod
def _compute_idf_values( sentences ):
tfv = TfidfVectorizer(tokenizer=lambda x: x, preprocessor=lambda x: x, dtype=np.float32)
tfidfmatrix_traindata = tfv.fit_transform(sentences)
featurenames = tfv.get_feature_names()
idf = tfv._tfidf.idf_
idf_dict = { pair[0]:pair[1] for pair in zip(featurenames, idf) }
return featurenames, idf_dict
実験
以下では、ベクトルの近傍探索により類似記事、タグ、投稿者、企業の検索をしてみました。
記事は、SCDVにより得られたQiitaベクトルをそのまま使いますが、それ以外はそれぞれ以下のようにベクトルを作成しました。
-
タグタグが付与された記事のQiitaベクトルの平均ベクトル -
投稿者投稿者が投稿した記事のQiitaベクトルの平均ベクトル -
組織組織(Qiita Organization)が投稿した記事のQiitaベクトルの平均ベクトル- 投稿者が組織への所属を登録している場合、以下のようにQiita記事に登録されており、これを使いました。
-

なお、近傍探索はSpotifyの作ったライブラリAnnoyを使いました。
以下のコードのように9近傍のベクトルを探索しました。
target = id2idx['9f8fee924fdc3f7ef411'] # MeCabの辞書への語彙追加方法【Windows 10, Ubuntu 18.04】
print( 'Query - title: %s' % (titles[target]) )
k = 10
near_list, dists = t_scdv.get_nns_by_item(target, k, include_distances=True) #
for i in range( 1, k, 1 ):
doc_idx = near_list[i]
print( 'Rank:%d (dist:%.3f) - title: %s' % (i, dists[i], titles[doc_idx] ) )
記事
実験結果は以下の通りです。Queryが入力のベクトルです。
表示しているのがタイトルだけですが、上位部分はある程度類似していそうに見えます。
Query - title: MeCabの辞書への語彙追加方法【Windows 10, Ubuntu 18.04】
Rank:1 (dist:0.940) - title: MeCabで文字コードの違う辞書を使う
Rank:2 (dist:1.004) - title: mecabのユーザー辞書をphp-mecabから認識させる
Rank:3 (dist:1.047) - title: kagomeでの形態素解析にユーザ辞書を使う雑なサンプル
Rank:4 (dist:1.074) - title: Anacondaの仮想環境を切り替えるSimple is Best 方法
Rank:5 (dist:1.118) - title: Azure App Service へASP.NET Web アプリをコマンドプロンプトからデプロイする
Rank:6 (dist:1.122) - title: mecabと文字コード
Rank:7 (dist:1.123) - title: mecab-ipadic-neologd対応のRESTful MeCabサーバ用Dockerfile
Rank:8 (dist:1.124) - title: pipenv仮想環境内のJupyter Notebookを一瞬で起動する方法
Rank:9 (dist:1.124) - title: pythonでつくるTodoアプリ(CLI)
Query - title: 自然言語処理における前処理の種類とその威力
Rank:1 (dist:0.868) - title: 自然言語(前)処理
Rank:2 (dist:0.895) - title: なぜ自然言語処理にとって単語の分散表現は重要なのか?
Rank:3 (dist:1.029) - title: 汎用言語表現モデルBERTの内部動作を解明してみる
Rank:4 (dist:1.057) - title: Vimでキャメルケースのスペルチェックをするプラグインを作った 〜 CCSpellCheck.vim 〜
Rank:5 (dist:1.100) - title: word2vecで佐久間まゆの類似単語を調べる
Rank:6 (dist:1.103) - title: Atom や Sublime Text で日本語の単語移動を可能にする(Vim化プラグインでも有効)
Rank:7 (dist:1.106) - title: Gearpumpの最小アプリケーションの構成は?
Rank:8 (dist:1.118) - title: 大規模データ処理基盤に入門する
Rank:9 (dist:1.131) - title: ES2017 async/await で sleep 処理を書く
Query - title: AtCoder に登録したら次にやること ~ これだけ解けば十分闘える!過去問精選 10 問 ~
Rank:1 (dist:0.700) - title: AtCoder に登録したら解くべき精選過去問 10 問を Hexagony で解いてみた(問題解説編)
Rank:2 (dist:0.730) - title: AtCoder に登録したら解くべき精選過去問 10 問を別解で解いてみた
Rank:3 (dist:0.737) - title: 「期待値の線型性」についての解説と、それを用いる問題のまとめ
Rank:4 (dist:0.739) - title: しゃくとり法 (尺取り法) の解説と、それを用いる問題のまとめ
Rank:5 (dist:0.743) - title: Python3で競技プログラミングする時に知っておきたいtips(入力編)
Rank:6 (dist:0.747) - title: AtCoder に登録したら解くべき精選過去問 10 問を Whitespace で解いてみた
Rank:7 (dist:0.747) - title: ABC112 D問題
Rank:8 (dist:0.748) - title: Project Eulerをシェル芸で解いてみる(Problem 27) #シェル芸
Rank:9 (dist:0.758) - title: 動的計画法超入門! Educational DP Contest の A ~ E 問題の解説と類題集
タグ
良い感じに見えます。
ただ、タグに関しては記事の類似性というより、同じ記事に付与されたタグの共起っぽい類似性ですね。
Query - user: Python
Rank:1 (dist:0.121) - title: Python3
Rank:2 (dist:0.302) - title: python2.7
Rank:3 (dist:0.352) - title: 初心者
Rank:4 (dist:0.361) - title: #python
Rank:5 (dist:0.368) - title: 備忘録
Rank:6 (dist:0.373) - title: tips
Rank:7 (dist:0.389) - title: JavaScript
Rank:8 (dist:0.396) - title: TensorFlow
Rank:9 (dist:0.400) - title: Linux
Query - user: Ruby
Rank:1 (dist:0.256) - title: RubyOnRails
Rank:2 (dist:0.257) - title: Rails
Rank:3 (dist:0.315) - title: Rails4
Rank:4 (dist:0.343) - title: Rails5
Rank:5 (dist:0.390) - title: Gem
Rank:6 (dist:0.413) - title: 備忘録
Rank:7 (dist:0.421) - title: 初心者
Rank:8 (dist:0.425) - title: tips
Rank:9 (dist:0.433) - title: Python
Query - user: 機械学習
Rank:1 (dist:0.156) - title: MachineLearning
Rank:2 (dist:0.261) - title: DeepLearning
Rank:3 (dist:0.272) - title: 深層学習
Rank:4 (dist:0.320) - title: ディープラーニング
Rank:5 (dist:0.375) - title: scikit-learn
Rank:6 (dist:0.416) - title: 人工知能
Rank:7 (dist:0.422) - title: Keras
Rank:8 (dist:0.424) - title: Chainer
Rank:9 (dist:0.433) - title: TensorFlow
Query - user: 自然言語処理
Rank:1 (dist:0.285) - title: NLP
Rank:2 (dist:0.513) - title: Python
Rank:3 (dist:0.527) - title: word2vec
Rank:4 (dist:0.535) - title: 形態素解析
Rank:5 (dist:0.537) - title: DeepLearning
Rank:6 (dist:0.538) - title: 機械学習
Rank:7 (dist:0.538) - title: gensim
Rank:8 (dist:0.540) - title: Python3
Rank:9 (dist:0.562) - title: 初心者
投稿者
自分を入力にして、検索してみました。
Query - user: myaun
Rank:1 (dist:0.869) - name: methane
Rank:2 (dist:0.878) - name: FukuharaYohei
Rank:3 (dist:0.879) - name: daisukelab
Rank:4 (dist:0.881) - name: fantm21
Rank:5 (dist:0.884) - name: yukiB
Rank:6 (dist:0.892) - name: hiroyuki827
Rank:7 (dist:0.895) - name: wapa5pow
Rank:8 (dist:0.895) - name: gold-kou
Rank:9 (dist:0.895) - name: momotaro98
自分と類似する上位3名のプロフィールは、こんな感じです。
微妙ですが、主にPythonで、機械学習系が多めな感じなので割と納得感はあります。
| 投稿者 | プロフィール |
|---|---|
| Query(自分) |  |
| Rank 1 |  |
| Rank 2 | 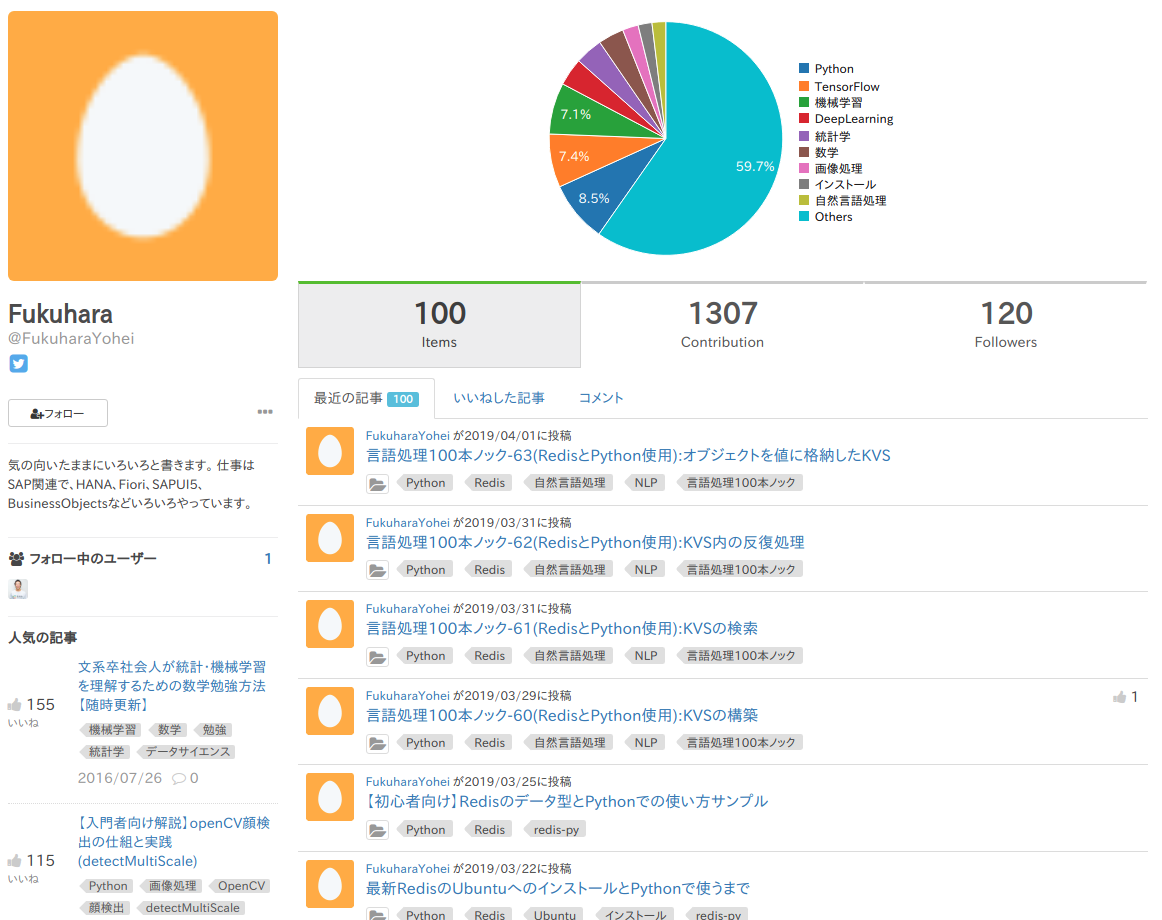 |
| Rank 3 | 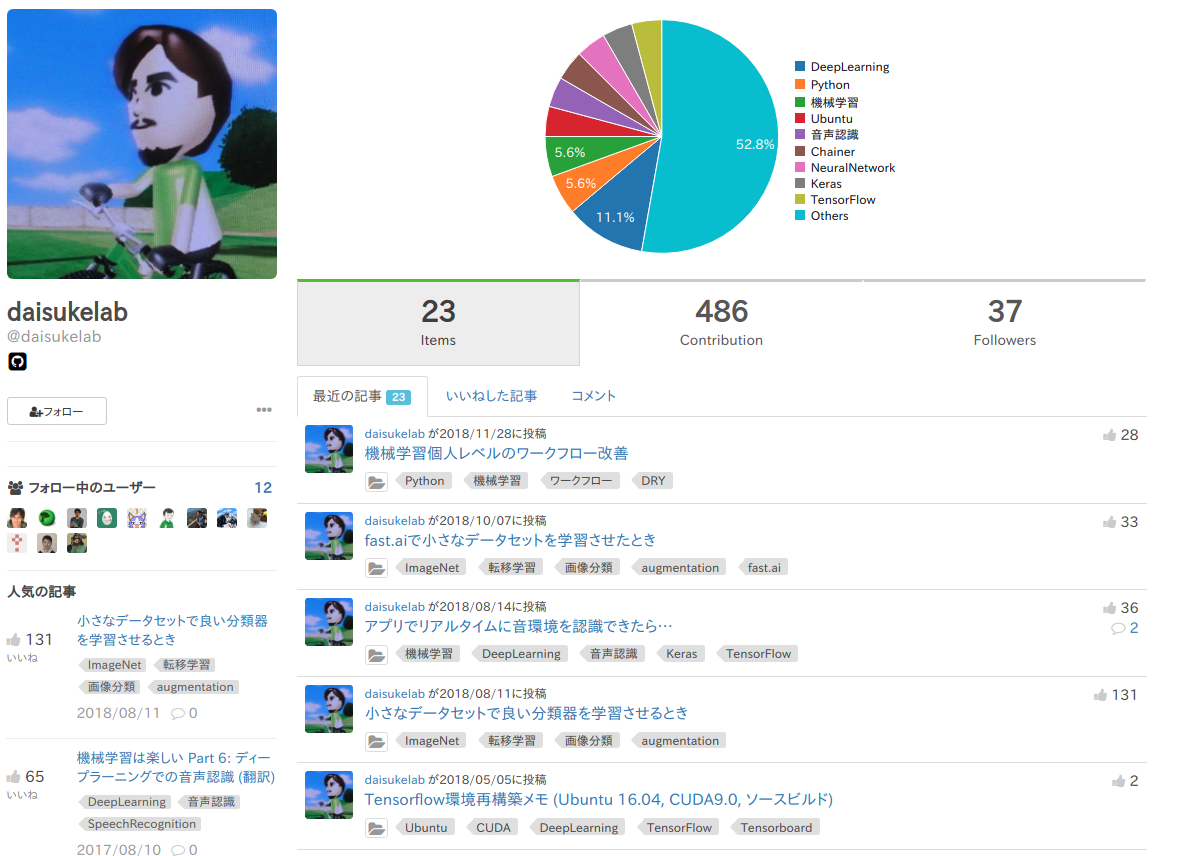 |
組織 (Qiita Organization)
あまりピンとこない感じでした。
この結果の理由としては、この辺かと思ってます。
- 所属ってそんなにちゃんと使われてない気がする (タグはちゃんとしてそう)
- 対象を絞り込んでないので、変なのがかなり混じっていた
-
組織の類似性を組織に所属している人が投稿した記事の類似性で測れる?
Query - name: 東京大学
Rank:1 (dist:0.827) - name: The University of Tokyo
Rank:2 (dist:0.830) - name: KLab Inc.
Rank:3 (dist:0.830) - name: Kyoto University
Rank:4 (dist:0.836) - name: Cookpad Inc.
Rank:5 (dist:0.838) - name: フリーランス
Rank:6 (dist:0.839) - name: 株式会社ニジボックス
Rank:7 (dist:0.839) - name: エムスリー株式会社
Rank:8 (dist:0.842) - name: 東京大学工学部
Rank:9 (dist:0.842) - name: なし
Query - name: IBM
Rank:1 (dist:0.625) - name: フリーランス
Rank:2 (dist:0.640) - name: DeNA Co., Ltd.
Rank:3 (dist:0.643) - name: Tech Fun株式会社
Rank:4 (dist:0.646) - name: 株式会社オープンストリーム
Rank:5 (dist:0.647) - name: 株式会社ISAO
Rank:6 (dist:0.651) - name: Freelance
Rank:7 (dist:0.659) - name: CyberAgent, Inc.
Rank:8 (dist:0.663) - name: SAKURA Internet Inc.
Rank:9 (dist:0.667) - name: Enechange
Query - name: Mercari
Rank:1 (dist:0.428) - name: フリーランス
Rank:2 (dist:0.455) - name: Cookpad Inc.
Rank:3 (dist:0.465) - name: AbemaTV, Inc.
Rank:4 (dist:0.469) - name: DeNA Co., Ltd.
Rank:5 (dist:0.480) - name: Freelance
Rank:6 (dist:0.482) - name: mixi
Rank:7 (dist:0.486) - name: 株式会社キュリオシティソフトウェア
Rank:8 (dist:0.490) - name: CyberAgent, Inc.
Rank:9 (dist:0.493) - name: freee K.K.
Query - name: DeNA Co., Ltd.
Rank:1 (dist:0.299) - name: フリーランス
Rank:2 (dist:0.364) - name: Freelance
Rank:3 (dist:0.391) - name: CyberAgent, Inc.
Rank:4 (dist:0.401) - name: Wantedly, Inc.
Rank:5 (dist:0.401) - name: freee K.K.
Rank:6 (dist:0.402) - name: 株式会社ISAO
Rank:7 (dist:0.406) - name: freelance
Rank:8 (dist:0.423) - name: 株式会社ゆめみ
Rank:9 (dist:0.440) - name: LIFULL Co., Ltd.
終わりに
なぜやったか
- ちょっと前、TwitterのTLや色んな技術記事で
SCDVを観測して、サブリミナル的に刷り込まれて試したくなった - 今春からQiitaが転職支援サービス
Qiita Jobsが始まったらしいので、投稿記事を用いて企業に合う求職中のQiitaユーザを予測するのかな(適当)と思ったので、その真似事をしてみたかった
今後やってみたいこと
- タグを考慮した学習: [5]のように記事のタグも一緒に学習したい。そのままテキストとして食べさせせずに、より高次な情報として良い感じに使いたい。
- コードを考慮した学習: 埋め込まれているコードの部分も使えたらQiitaっぽくて良い。せめて言語の種類ぐらいは埋め込みたい、技術記事の分析とかで先行事例あれば知りたい。
- メタデータを考慮した学習: 他の統計情報とかメタデータもモデルに組み込みたい(記事のいいね数、ストック数やユーザのいいね、フォロー関係など)。影響が強くなりすぎて文書の内容を汚染しないように注意。
- 定量評価: Qiitaベクトルを何らかの応用に適用して評価する。タグ予測をしようとたけどうまくいかなかった(良い感じに問題設定できなかった)そのうちやりたい。
参考
SCDV関連
[元論文] Dheeraj Mekala, Vivek Gupta, Bhargavi Paranjape, Harish Karnick, "SCDV : Sparse Composite Document Vectors using soft clustering over distributional representations", EMNLP2017, https://arxiv.org/abs/1612.06778
[1] 文書ベクトルをお手軽に高い精度で作れるSCDVって実際どうなのか日本語コーパスで実験した(EMNLP2017)
[2] 医療用語に注目した文書の類似度計算(SCDV+XGBoost)
[3] Anonymize Large-scale Sparse User Features at LINE Corp
Qiita記事スクレイピング関連
[4] Qiitaの記事データをQiita API, Scrapyで収集
その他
[5] サブカルのためのword2vec