はじめに
過去記事(YouTuberマイニング #1, YouTuberマイニング #2)でYouTuberのChannelから情報を取得する方法を紹介してきましたが、めでたくYouTuberデータセットを作成・公開することができました。 (Python1行で読み込むことができます)
本記事では、YouTuberデータセットについて、またこれを使った簡単なデモを紹介します。
YouTuberデータセット
データセットURL: YouTuber
概要
- データセットは以下の情報を含みます
- channels: YouTuberのチャンネルの情報 (YouTuber数 152名)
- channel_videos: 各YouTuberの投稿動画の情報 (投稿動画数 66289件, YouTuber数 152名)
- データ管理ツールQuiltにより管理されています(参考 ... Quilt紹介記事)
ソース
- 対象のYouTuberのリストはUUUM公式サイトより取得しました
- YouTubeチャンネルおよび動画の情報はYouTube Data API v3により取得しました
ダウンロード方法
まずは、QuiltからローカルPCにデータセットをダウンロードします。 (1行目はQuilt自体のインストールなので、既にインストール済みの方はSkip)
$ pip install quilt # Quiltのinstall
$ quilt install haradai1262/YouTuber
読み込み方法
ダウンロードが完了すれば、後は読み込みたいpythonスクリプト内で以下の1行を実行することにより読み込むことができます。
from quilt.data.haradai1262 import YouTuber
デモ
- データの確認
- YouTuberが投稿した映像をキーワードでクラスタリング
- 得られたクラスタの統計値を確認し、YouTuberの人気コンテンツを確認
データの確認
まずはデータセットの中身を確認してみます。
from quilt.data.haradai1262 import YouTuber
YouTuber.channels.UUUM().head()

こちらの"channels"には、各チャンネルに関する情報が格納されています。タイトルや説明文に加え、チャンネル登録者数や総再生数など含まれます。
YouTuber.channel_videos.UUUM_videos().head()
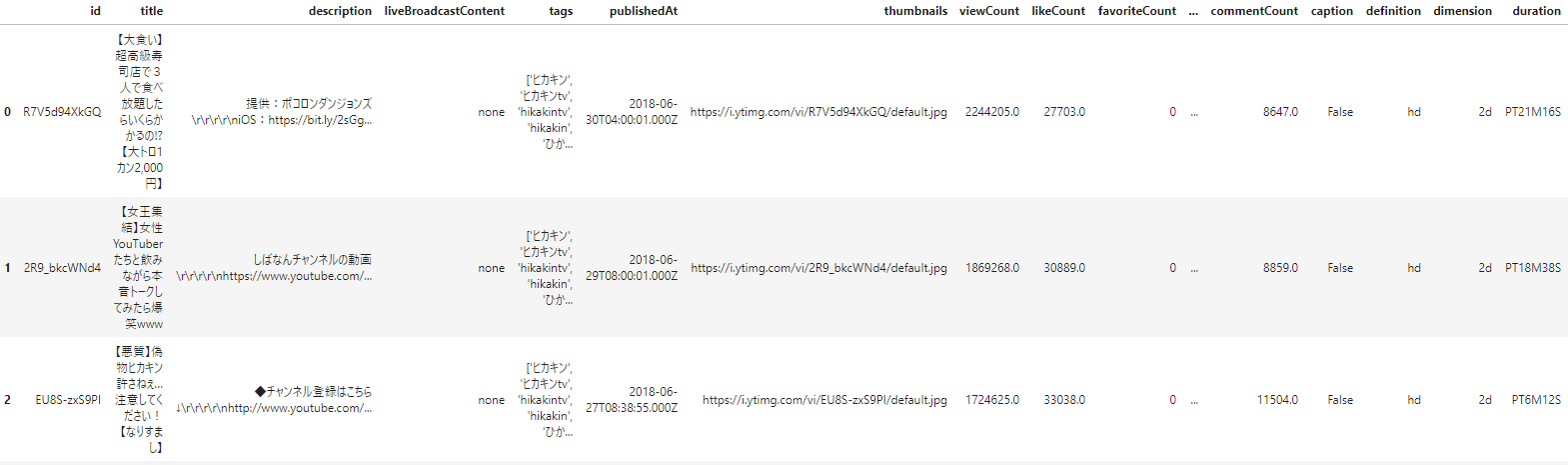
こちらの"channels_videos"には、各YouTuberの投稿動画に関する情報が格納されています。動画のタイトル、説明文などの基本情報、再生数、いいね数などの統計値が含まれています。
このように、それぞれpandasのDataframe形式で読み込むことができます。
以下のデモでは、channel_videosを使います。
YouTuberが投稿した映像をキーワードでクラスタリング
まずは、channel_videosの中からゆきりぬさん(channel id = 'UCMsuwHzQPFMDtHaoR7_HDxg')の動画のみ抽出し、タイトルとタグのみを使用します。
df_ori = YouTuber.channel_videos.UUUM_videos()
df_ori = df_ori[df_ori['cid'] == 'UCMsuwHzQPFMDtHaoR7_HDxg'].reset_index(drop=True)
df = df_ori.loc[:,['title','tags']]
映像に含まれるタイトルやタグを基にクラスタリングをします。
以下の処理では、タイトルから名詞を抽出し、タグと結合し、コーパスを作成します。
from janome.tokenizer import Tokenizer
tokenizer = Tokenizer()
def get_noun( str ):
nouns = []
for token in tokenizer.tokenize( str ):
pos = token.part_of_speech.split(',')[0]
if pos == '名詞': nouns.append( token.base_form )
return nouns
def tag2list( str ):
tags = []
for i in str[1:-1].split(','):
i = i.replace(' ','')
tags.append( i[1:-1] )
return tags
df['title_noun'] = df['title'].apply( get_noun )
df['tags_noun'] = df['tags'].apply( tag2list )
X_tmp = df.loc[:,['title_noun','tags_noun']].values
X = [ i[0] + i[1] for i in X_tmp ]
次に、作成したコーパスにLSIを適用し、各映像の特徴量を抽出します。(LSIには、gensimを使用しており、"dictionary.filter_extremes(no_below=2, no_above=0.5 )"で語彙を調整しています)
import gensim
from gensim import corpora, models, similarities
dictionary = corpora.Dictionary( X )
dictionary.filter_extremes(no_below=2, no_above=0.5 )
corpus = [dictionary.doc2bow(text) for text in X]
lsi = models.LsiModel(corpus, id2word=dictionary, num_topics=30)
lsi_feature = lsi[corpus]
X_lsi = np.ndarray(( len(corpus), 30 ))
for i in range( len( corpus ) ):
for j in lsi_feature[i]:
X_lsi[i, j[0]] = j[1]
そして、得られた特徴量を用いてクラスタリング(今回はK-means法、クラスタ数 20)を適用します。
def get_groups( t_cluster ):
groups_tmp = {}
for i, l in enumerate( t_cluster ):
if not l in groups_tmp: groups_tmp[l] = []
groups_tmp[l].append( i )
return groups_tmp
from sklearn.cluster import KMeans
cluster = KMeans(n_clusters=20, random_state=0).fit(X_lsi)
group = get_groups( cluster.labels_ )
得られたクラスタは以下のようになりました。ゲーム実況、旅行系動画や勉強系動画などに異なるジャンルに分割できていることが確認できます。
cluster: 0
211 20万人記念企画何がいいかなぁー?
381 【モンスト】ゆきりぬのBOXを紹介&フレンド募集♪【10万人突破記念】
395 【モンスト】4000万人記念ガチャ!最終日だしいいこと起こるはず【ゆきりぬ】
397 【モンスト】4000万人記念ガチャ!パンドラ来るか?-3日目【ゆきりぬ】
399 【モンスト】4000万人記念ガチャ!ストライクショットって言って!!-2日目【ゆきりぬ】
cluster: 1
25 たくさんの東大生が教える"一番オススメ"な参考書ランキング!【東大五月祭】
83 東大生が考える最強のメントスコーラがマジで最強だった!!!!
306 現役東大生と東大五月祭に行ったら視聴者さんに発見されたw【ゆきりぬ】
cluster: 2
222 【モンスト】超獣神祭☆ノストラダムスとパンドラ狙いで10連!【ゆきりぬ】
265 【モンスト】激獣神祭ワルプルギス狙いで久々に引いてみたら…
274 【モンスト】ノストラダムス求めて超獣神祭50連、ディズニーで引いてみた!【ゆきりぬ】
280 【モンスト】オールスター感謝ガチャ!パンドラ狙いで引いてみたら神引き!【もえりぬ】
297 【モンストlive】パンドラ狙い!UUUMで超獣神祭☆ガチャ回すぞー!!【ゆきりぬ】
cluster: 3
236 晩酌しながら雑談!【ゆきりぬ】
252 暑すぎて壊れました。夏休みの質問コーナー!【ゆきりぬ】
267 男装で愛してるゲームしたら最強なんじゃない?!【ゆきりぬ】
288 【逃げ恥】恋ダンス2017〜うろ覚えで踊ってみた。【ゆきりぬ】
293 文理選択で後悔しないために聞いて欲しい話。【ゆきりぬ】
cluster: 4
1 健康診断の結果を見てもらったらヤバいのがみつかりました。。。
2 キックボクシングはじめます。
3 ある日のカラオケでまさかの事件が起きました。
8 女友達に性格悪いってバラされました。
9 iPhoneの予測変換晒してみたら普段使ってる言葉がやばすぎた…
cluster: 5
241 【スプラトゥーン2】5キルしないと寝れません!女子がSラン目指して奮闘【Splatoon2】【ゆきりぬ】
251 【スプラトゥーン2】新武器スプラマニューバーがヤバイw空中に浮かぶSPが楽しすぎる【Splatoon2】【ゆきりぬ】
255 【スプラトゥーン2】女子だって上手くなりたい!まったり生放送【ゆきりぬ】
cluster: 6
340 【逆転オセロニア】神引き★ノクタニア狙いで超駒パレード55連であのキャラが…!【ちゅにりぬ】
398 【逆転オセロニア】超駒パレード55連で確定演出連発!!エクローシア狙い!【ゆきりぬ】
424 【逆転オセロニア】新春限定超駒パレード!55連引くつもりが神引きにより強制終了した件。【ゆきりぬ】
483 【逆転オセロニア】超駒パレード22+1連!レグス狙いのはずが、こんな結果見たことないww【ゆきりぬ】
cluster: 7
292 回っておいしい?食べられるハンドスピナーを作ってみた!
cluster: 8
250 【モンスト】モン玉ガチャ引いたらまさかの適正なアイツがきたー!【ゆきりぬ】
326 【モンスト】モン玉ガチャを中の人と引いてみた!最後にチラリとあの人も?【さなぱっちょ&ゆきりぬ】
409 【モンスト】モン玉をちゅうにーさんに引いてもらったら神引き?!【ゆきりぬ】
430 【モンスト】大晦日だよ!★6確定オールスター感謝ガチャ引いてみた♪【ゆきりぬ】
445 【モンスト】モン玉Lv3!!信長X狙いで星5確定モン玉ガチャ引いてみた【ゆきりぬ】
cluster: 9
266 怪しいオカマに誘われてついて行ったら大変なことに///【ゼルダの伝説-ブレス オブ ザ ワイルド実況プレイ!part11】
289 ゼルダの伝説-ブレス オブ ザ ワイルド実況プレイ!part10後編【ゆきりぬ】【任天堂スイッチ】
324 ゼルダの伝説-ブレス オブ ザ ワイルド実況プレイ!part10前編【ゆきりぬ】【任天堂スイッチ】
327 ゼルダの伝説-ブレス オブ ザ ワイルド実況プレイ!part9【ゆきりぬ】【任天堂スイッチ】
330 ゼルダの伝説-ブレス オブ ザ ワイルド実況プレイ!part8【ゆきりぬ】【任天堂スイッチ】
cluster: 10
5 ゆきりぬ毎日メイク〜芋すぎた理系女子がYouTube2年で辿り着いたメイク法〜 Everyday Makeup
39 もしも海外ブランドのモデルがゆきりぬだったらドッキリ!!!
40 【黒歴史】理系のイモ女が大変身した方法を全て話します。
122 私なら5分で寝起きすっぴんから出発できる!?
151 入手困難な福袋をゲットしたので開封するよ!【セザンヌ&レブロン】
cluster: 11
0 アメリカ旅行ではなおさんに仕返ししました。【vlog】
7 【ご報告】アメリカへ行くことになりました。
44 ひとりで台湾旅行したらYouTubeやめたくなりました
47 旅に出ます。
66 女子ふたりの温泉ぶらり旅。
cluster: 12
262 【モンストlive】キング・ブラッドレイ出た!ハガレンコラボ周回【ゆきりぬ】
268 【モンスト】M4とB4にBurning Night LIVEガチャを引いてもらったら色々奇跡【ゆきりぬ】
271 【モンストlive】寝る前に、少しアヴァロンとか!【ゆきりぬ】
281 【ファイトリーグ】確定演出がモンストと同じ?初見でいきなり出た!!【ゆきりぬ】
310 【モンスト】シャンバラソロ瀕死からの大逆転リベンジ【ゆきりぬ】
cluster: 13
6 コーラにお酒をこっそり盛られました。。。
48 泥酔した友達と斎藤さんやったら闇が深すぎたwwwwwww
70 【泥酔】コーラで割ればどんなお酒でも飲めちゃう説!!!
110 【泥酔】酒豪の女友達にお酒の飲み方を教えてもらった結果。。
145 【泥酔】年末なので過去最高にお酒飲んでみた結果。。。
cluster: 14
4 勉強の悩みに全て答えます!ゆきりぬ先生の質問相談コーナー!!
92 受験生必見!JK時代の秘蔵ノートを大公開!! ~英語の勉強法~
128 センター試験直前!今やるべき5つのこと。
157 年末年始はどうすべき?冬休みの勉強法!! 【センター対策】
176 成績が超アップ!!最強のノートの取り方。【完全版】
cluster: 15
55 【激安】GU2万円分を超大量購入して春コーデしてみた!
78 【破産】春服を10万円分大量購入して一気にコーデしてみた!!!
111 GU1万円で大人可愛い冬コーデ♡
114 ユニクロ1万円で冬コーデ!! 〜最近寒すぎるけど春先まで使いたい編〜
172 ズボラ女をたった1万円で大変身させてくれた。【GU全身コーデ】
cluster: 16
167 おっぱいの件について。
178 塗る塗る塗る塗る塗る塗る塗る塗る塗る塗る塗る塗る塗る塗る塗る
182 ビッグマックを早食いできるようになりたい
183 私が太らない理由。
186 ゆきりぬの自己紹介。
cluster: 17
10 天才的なお絵描きします。
36 皆さんに聞きたいことがあります。
57 最近の裏話をするよ。
71 大切なお知らせがあります。
74 謝ります。
cluster: 18
133 2018スタバ福袋を女子目線で開封レビューしてみた!
135 2018福袋を一気に開封レビューして全部着替える!【ジェラピケ、スナイデルetc】
cluster: 19
438 【モンストLIVE配信】闘神アカシャを皆で倒そう!!【ゆきりぬ】
454 【モンストLIVE配信】宮坊さんと!学びの実狙いで神殿周回マルチ【ゆきりぬwith宮坊】
481 【モンストLIVE配信】初見!パンプキーナちゃんに挑戦!【ゆきりぬ】
482 【モンストLIVE配信】ハロウィンコス!超絶阿修羅に初めて挑んでみる★【ゆきりぬ】
485 【モンストLIVE配信】学びの実欲しい!!神殿マルチやります!!【ゆきりぬ】
クラスタの統計値を確認し、YouTuberの人気コンテンツを確認
クラスタリングだけで終わってはつまらないので、各クラスタに含まれる映像の統計値(視聴数、いいね数など)を確認し、傾向を分析します。
また、分析のために"like_dislike"という統計値を追加しました。これは、likeとdislikeの比であり、この値が大きいほど、ファンの満足度が高いと考えます。
def get_cluster_means( x_tmp, group_tmp ):
mean_df_tmp= x_tmp.mean()
mean_df_tmp.name = -1
for i in range( len( group_tmp ) ):
c = pd.DataFrame(x_tmp,index=group_tmp[i])
c_mean = c.mean()
c_mean.name = i
mean_df_tmp = pd.concat([mean_df_tmp, c_mean], axis=1)
mean_df_tmp = mean_df_tmp.drop( columns=[-1] )
return mean_df_tmp
df_stat = df_ori.loc[:,['viewCount', 'likeCount', 'dislikeCount']]
mean_df = get_cluster_means( df_stat, group ).T
mean_df['like/dislike'] = mean_df['likeCount'] / mean_df['dislikeCount']
mean_df.style.background_gradient( cmap='Oranges' )

こちらは、各クラスタの統計値の平均値です。
色が濃くなっている箇所は相対的に大きな値であることを表しています。
この結果より、YouTuberゆきりぬさんは、cluster11の旅行系動画を投稿すると高い再生数が見込め、またcluster14の勉強系動画、cluster15のファッション系動画は"like_dislike"が高く、ファンからの人気が高いジャンルであることがわかりました。
一方で、cluster2, 6, 8, 12, 19のゲーム実況動画は再生数も"like_dislike"も低く、ファンには人気のないジャンルであることが確認できました。
終わりに
本記事では、公開したYouTuberデータセットについて説明し、また、これを使った簡単なデモを紹介しました。簡単な実験ではありましたが、YouTuberの投稿する動画の人気/不人気ジャンルを分析することができました。
今回のデモでは、クラスタリングを実施しましたが、他のタスクも試すことができると思うので、色々やっていければと思います。また、Quiltでは、データセットのバージョン管理ができるので、今後新たなデータの追加を行い、データセットの更新をしようと計画しています。