はじめに
Blue Prism で PDF から文字データを抽出するのに、「PDFを開いて、Ctrl+A で全てを選択、メモ帳に Ctrl+V で貼り付け」よりもスマートな方法を採りたいですね。
blue prism DX から VBO を検索すると、テキスト抽出できるのは、「PDF Text Extraction Google Cloud」、「SRI - Utility - PDF」あたりが該当しそうです。
この記事では、敢えて Blue Prism から Apache Tika を使って文字データ抽出をやってみます。
Apache Tika とは
Apache Tika は、PPT、XLS、PDFなどの様々なファイルからテキストやメタデータを抽出するツールキットです。もともとオープンソースの全文検索エンジン Apache Lucene のサブプロジェクトだったそうです。検索エンジンのインデックス生成に使うデータ抽出に使われているのですかね。
Apache Tika を使えるようにする
まず Java をダウンロードします。Oracle Technology Network の Java SE Downloadsページから、最新ではなくても良い気がしますが、13.0.2 のダウンロードページを辿り、exe形式でない「jdk-13.0.2_windows-x64_bin.zip」ファイルをダウンロードします。
※ ダウンロードには Oracle アカウントが必要です。
ダウンロードできたら適当なフォルダに解凍し、jdk-13.0.2\bin\java.exe のフルパスを控えておきます。この記事では、C:\Users\m-nakamura\Documents\jdk-13.0.2\bin\java.exe になりました。
次に、Apache Tika ダウンロード から app jar ファイルをダウンロードします。
適当なフォルダに保存し、こちらもフルパスを控えておきます。この記事では、C:\Users\m-nakamura\Documents\tika\tika-app-1.23.jar になりました。
ダウンロードが終わったら、コマンドプロンプトを立ち上げ、下記のコマンドを実行します。画面のようなメッセージが表示されることを確認します。
(java.exe や tika-app-1.23.jar のパスは環境に合わせて適宜変更してください)
>C:\Users\m-nakamura\Documents\jdk-13.0.2\bin\java.exe -jar C:\Users\m-nakamura\Documents\tika\tika-app-1.23.jar --help
usage: java -jar tika-app.jar [option...] [file|port...]
Options:
-? or --help Print this usage message
-v or --verbose Print debug level messages
-V or --version Print the Apache Tika version number
-g or --gui Start the Apache Tika GUI
-s or --server Start the Apache Tika server
-f or --fork Use Fork Mode for out-of-process extraction
--config=<tika-config.xml>
TikaConfig file. Must be specified before -g, -s, -f or the dump-x-config !
--dump-minimal-config Print minimal TikaConfig
--dump-current-config Print current TikaConfig
--dump-static-config Print static config
--dump-static-full-config Print static explicit config
-x or --xml Output XHTML content (default)
-h or --html Output HTML content
-t or --text Output plain text content
-T or --text-main Output plain text content (main content only)
-m or --metadata Output only metadata
-j or --json Output metadata in JSON
-y or --xmp Output metadata in XMP
-J or --jsonRecursive Output metadata and content from all
embedded files (choose content type
with -x, -h, -t or -m; default is -x)
-l or --language Output only language
-d or --detect Detect document type
--digest=X Include digest X (md2, md5, sha1,
sha256, sha384, sha512
-eX or --encoding=X Use output encoding X
-pX or --password=X Use document password X
-z or --extract Extract all attachements into current directory
--extract-dir=<dir> Specify target directory for -z
-r or --pretty-print For JSON, XML and XHTML outputs, adds newlines and
whitespace, for better readability
--list-parsers
List the available document parsers
--list-parser-details
List the available document parsers and their supported mime types
--list-parser-details-apt
List the available document parsers and their supported mime types in apt format.
--list-detectors
List the available document detectors
--list-met-models
List the available metadata models, and their supported keys
--list-supported-types
List all known media types and related information
--compare-file-magic=<dir>
Compares Tika's known media types to the File(1) tool's magic directory
Description:
Apache Tika will parse the file(s) specified on the
command line and output the extracted text content
or metadata to standard output.
Instead of a file name you can also specify the URL
of a document to be parsed.
If no file name or URL is specified (or the special
name "-" is used), then the standard input stream
is parsed. If no arguments were given and no input
data is available, the GUI is started instead.
- GUI mode
Use the "--gui" (or "-g") option to start the
Apache Tika GUI. You can drag and drop files from
a normal file explorer to the GUI window to extract
text content and metadata from the files.
- Server mode
Use the "--server" (or "-s") option to start the
Apache Tika server. The server will listen to the
ports you specify as one or more arguments.
- Batch mode
Simplest method.
Specify two directories as args with no other args:
java -jar tika-app.jar <inputDirectory> <outputDirectory>
Batch Options:
-i or --inputDir Input directory
-o or --outputDir Output directory
-numConsumers Number of processing threads
-bc Batch config file
-maxRestarts Maximum number of times the
watchdog process will restart the child process.
-timeoutThresholdMillis Number of milliseconds allowed to a parse
before the process is killed and restarted
-fileList List of files to process, with
paths relative to the input directory
-includeFilePat Regular expression to determine which
files to process, e.g. "(?i)\.pdf"
-excludeFilePat Regular expression to determine which
files to avoid processing, e.g. "(?i)\.pdf"
-maxFileSizeBytes Skip files longer than this value
Control the type of output with -x, -h, -t and/or -J.
To modify child process jvm args, prepend "J" as in:
-JXmx4g or -JDlog4j.configuration=file:log4j.xml.
Apache Tika を使ってテキスト抽出をしてみる
テストとして、コマンドプロンプトから Apache Tika を使い、PDFファイルからデータ抽出ができるかどうか試してみます。
テスト用のファイルとして、なんでも良いのですが厚生労働省から「平成22年度診療報酬改定の基本方針(社会保障審議会医療保険部会・社会保障審議会医療部会) [266KB]」というファイルをダウンロードします(index-001.pdf)。
最初にワーニングが表示されます(これは StdErr に表示されているようです)。
-h オプションを指定して、html形式で抽出しています。
>C:\Users\m-nakamura\Documents\jdk-13.0.2\bin\java.exe -jar C:\Users\m-nakamura\Documents\tika\tika-app-1.23.jar -h index-001.pdf
1月 30, 2020 4:01:51 午後 org.apache.tika.config.InitializableProblemHandler$3 handleInitializableProblem
警告: J2KImageReader not loaded. JPEG2000 files will not be processed.
See https://pdfbox.apache.org/2.0/dependencies.html#jai-image-io
for optional dependencies.
1月 30, 2020 4:01:51 午後 org.apache.tika.config.InitializableProblemHandler$3 handleInitializableProblem
警告: org.xerial's sqlite-jdbc is not loaded.
Please provide the jar on your classpath to parse sqlite files.
See tika-parsers/pom.xml for the correct version.
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta name="date" content="2010-03-03T12:55:03Z"/>
<meta name="pdf:PDFVersion" content="1.5"/>
<meta name="xmp:CreatorTool" content="Word 逕ィ Acrobat PDFMaker 9.0"/>
<meta name="Company" content="蜴夂函蜉エ蜒咲怐"/>
<meta name="pdf:hasXFA" content="false"/>
<meta name="access_permission:modify_annotations" content="true"/>
<meta name="access_permission:can_print_degraded" content="true"/>
<meta name="dc:creator" content="蜴夂函蜉エ蜒咲怐繝阪ャ繝医Ρ繝シ繧ッ繧キ繧ケ繝・Β"/>
<meta name="dcterms:created" content="2010-03-03T12:55:01Z"/>
<meta name="dcterms:modified" content="2010-03-03T12:55:03Z"/>
<meta name="Last-Modified" content="2010-03-03T12:55:03Z"/>
<meta name="dc:format" content="application/pdf; version=1.5"/>
<meta name="xmpMM:DocumentID" content="uuid:c1b6afb2-ab40-4cfd-a667-506f7e4e3791"/>
<meta name="Last-Save-Date" content="2010-03-03T12:55:03Z"/>
<meta name="pdf:docinfo:creator_tool" content="Word 逕ィ Acrobat PDFMaker 9.0"/>
<meta name="access_permission:fill_in_form" content="true"/>
<meta name="pdf:docinfo:modified" content="2010-03-03T12:55:03Z"/>
<meta name="meta:save-date" content="2010-03-03T12:55:03Z"/>
<meta name="pdf:encrypted" content="false"/>
<meta name="modified" content="2010-03-03T12:55:03Z"/>
<meta name="pdf:docinfo:custom:SourceModified" content="D:20091207133553"/>
<meta name="Content-Length" content="271544"/>
<meta name="Content-Type" content="application/pdf"/>
<meta name="pdf:docinfo:creator" content="蜴夂函蜉エ蜒咲怐繝阪ャ繝医Ρ繝シ繧ッ繧キ繧ケ繝・Β"/>
<meta name="X-Parsed-By" content="org.apache.tika.parser.DefaultParser"/>
<meta name="X-Parsed-By" content="org.apache.tika.parser.pdf.PDFParser"/>
<meta name="creator" content="蜴夂函蜉エ蜒咲怐繝阪ャ繝医Ρ繝シ繧ッ繧キ繧ケ繝・Β"/>
<meta name="meta:author" content="蜴夂函蜉エ蜒咲怐繝阪ャ繝医Ρ繝シ繧ッ繧キ繧ケ繝・Β"/>
<meta name="meta:creation-date" content="2010-03-03T12:55:01Z"/>
<meta name="access_permission:extract_for_accessibility" content="true"/>
<meta name="access_permission:assemble_document" content="true"/>
<meta name="xmpTPg:NPages" content="6"/>
<meta name="Creation-Date" content="2010-03-03T12:55:01Z"/>
<meta name="resourceName" content="index-001.pdf"/>
<meta name="pdf:hasXMP" content="true"/>
<meta name="access_permission:extract_content" content="true"/>
<meta name="pdf:docinfo:custom:Company" content="蜴夂函蜉エ蜒咲怐"/>
<meta name="access_permission:can_print" content="true"/>
<meta name="SourceModified" content="D:20091207133553"/>
<meta name="Author" content="蜴夂函蜉エ蜒咲怐繝阪ャ繝医Ρ繝シ繧ッ繧キ繧ケ繝・Β"/>
<meta name="access_permission:can_modify" content="true"/>
<meta name="pdf:docinfo:producer" content="Adobe PDF Library 9.0"/>
<meta name="pdf:docinfo:created" content="2010-03-03T12:55:01Z"/>
<title></title>
</head>
<body><div class="page"><p/>
<p>1
</p>
<p>蟷ウ謌撰シ抵シ貞ケエ蠎ヲ險コ逋ょア驟ャ謾ケ螳壹・蝓コ譛ャ譁ケ驥・
....
豪快に文字化けしてますね。これは tika が「空気を読んで SJIS で標準出力に書き出す」ようには動作せず、UTF-8 で出力しているために起きているようです。
--encoding=SJIS オプションを付けると文字化けが防げます。
>C:\Users\m-nakamura\Documents\jdk-13.0.2\bin\java.exe -jar C:\Users\m-nakamura\Documents\tika\tika-app-1.23.jar -h --encoding=SJIS index-001.pdf 2> stderr.txt
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta name="date" content="2010-03-03T12:55:03Z"/>
<meta name="pdf:PDFVersion" content="1.5"/>
<meta name="xmp:CreatorTool" content="Word 用 Acrobat PDFMaker 9.0"/>
<meta name="Company" content="厚生労働省"/>
<meta name="pdf:hasXFA" content="false"/>
<meta name="access_permission:modify_annotations" content="true"/>
<meta name="access_permission:can_print_degraded" content="true"/>
<meta name="dc:creator" content="厚生労働省ネットワークシステム"/>
<meta name="dcterms:created" content="2010-03-03T12:55:01Z"/>
<meta name="dcterms:modified" content="2010-03-03T12:55:03Z"/>
<meta name="Last-Modified" content="2010-03-03T12:55:03Z"/>
<meta name="dc:format" content="application/pdf; version=1.5"/>
<meta name="xmpMM:DocumentID" content="uuid:c1b6afb2-ab40-4cfd-a667-506f7e4e3791"/>
<meta name="Last-Save-Date" content="2010-03-03T12:55:03Z"/>
<meta name="pdf:docinfo:creator_tool" content="Word 用 Acrobat PDFMaker 9.0"/>
<meta name="access_permission:fill_in_form" content="true"/>
<meta name="pdf:docinfo:modified" content="2010-03-03T12:55:03Z"/>
<meta name="meta:save-date" content="2010-03-03T12:55:03Z"/>
<meta name="pdf:encrypted" content="false"/>
<meta name="modified" content="2010-03-03T12:55:03Z"/>
<meta name="pdf:docinfo:custom:SourceModified" content="D:20091207133553"/>
<meta name="Content-Length" content="271544"/>
<meta name="Content-Type" content="application/pdf"/>
<meta name="pdf:docinfo:creator" content="厚生労働省ネットワークシステム"/>
<meta name="X-Parsed-By" content="org.apache.tika.parser.DefaultParser"/>
<meta name="X-Parsed-By" content="org.apache.tika.parser.pdf.PDFParser"/>
<meta name="creator" content="厚生労働省ネットワークシステム"/>
<meta name="meta:author" content="厚生労働省ネットワークシステム"/>
<meta name="meta:creation-date" content="2010-03-03T12:55:01Z"/>
<meta name="access_permission:extract_for_accessibility" content="true"/>
<meta name="access_permission:assemble_document" content="true"/>
<meta name="xmpTPg:NPages" content="6"/>
<meta name="Creation-Date" content="2010-03-03T12:55:01Z"/>
<meta name="resourceName" content="index-001.pdf"/>
<meta name="pdf:hasXMP" content="true"/>
<meta name="access_permission:extract_content" content="true"/>
<meta name="pdf:docinfo:custom:Company" content="厚生労働省"/>
<meta name="access_permission:can_print" content="true"/>
<meta name="SourceModified" content="D:20091207133553"/>
<meta name="Author" content="厚生労働省ネットワークシステム"/>
<meta name="access_permission:can_modify" content="true"/>
<meta name="pdf:docinfo:producer" content="Adobe PDF Library 9.0"/>
<meta name="pdf:docinfo:created" content="2010-03-03T12:55:01Z"/>
<title></title>
</head>
<body><div class="page"><p/>
<p>1
</p>
<p>平成22年度診療報酬改定の基本方針
</p>
<p>
平 成 2 1 年 1 2 月 8 日
社会保障審議会医療保険部会
社 会 保 障 審 議 会 医 療 部 会
</p>
<p>
</p>
<p> Ⅰ 平成22年度診療報酬改定に係る基本的考え方
</p>
<p>○ 医療は、国民の安心の基盤であり、国民一人一人が必要とする医療を適切
</p>
<p>に受けられる環境を整備するため、医療提供者や行政、保険者の努力はもち
</p>
<p>ろんのこと、患者や国民も適切な受診をはじめとする協力を行うなど、各人
</p>
<p>がそれぞれの立場で不断の取組を進めていくことが求められるところであ
</p>
<p>る。
</p>
...
</p>
<p>
</p>
<p> Ⅳ 終わりに
</p>
<p>○ 中央社会保険医療協議会におかれては、本基本方針の趣旨を十分に踏まえ
</p>
<p>た上で、国民、患者の医療ニーズに即した具体的な診療報酬の改定案の審議
</p>
<p>を進められることを希望する。 </p>
<p/>
</div>
</body></html>
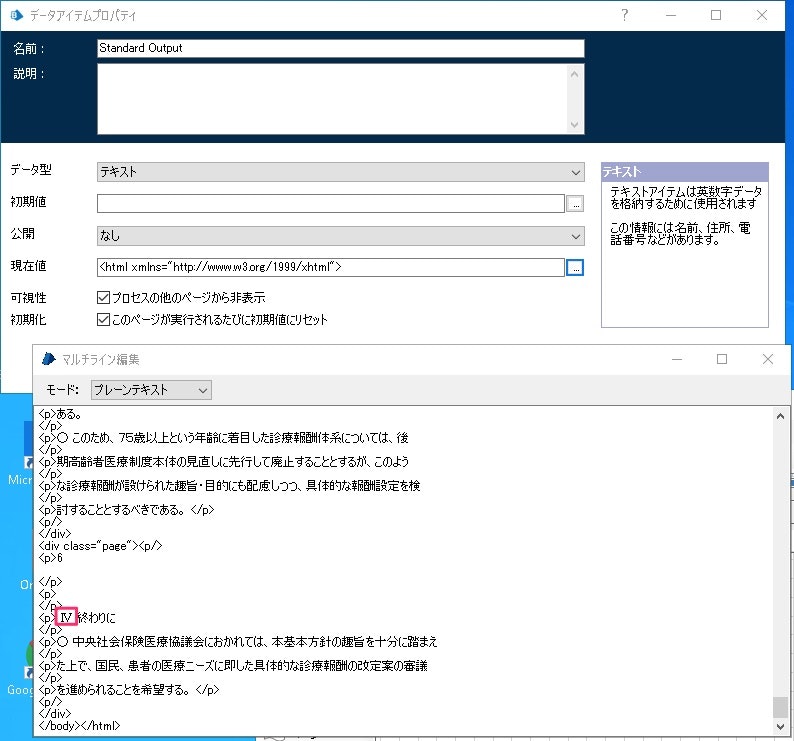
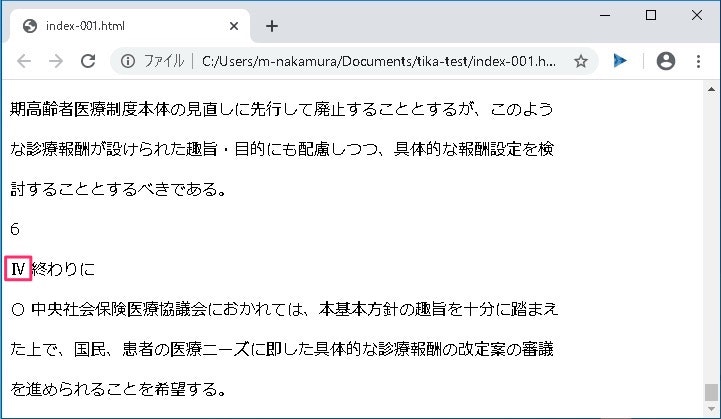
文字化けは防げましたが、ところどころ変換できていない文字がありますね。例えば、「終わりに」部分に変換できていない文字があります。元のPDFをみると、IV のようです。
UTF-8 のままで変換したファイルではきちんとIV と表示されているので、下手に SJIS 指定をしない方が良さそうです。
Blue Prism から Apache Tika を使う
Apache Tika の基本的な使い方がわかったところで、Blue Prism から呼び出す仕組みを作成していきます。
基本的には、 Utility - Environment::Start Process Read Stderr and Stdout を使い、コマンドの実行結果の Stdout を読み込めば良さそうですが、そのまま使うと文字化けしてしまいます。
オブジェクトの中をみてみると、ProcessStartInfo のところで文字コードが明示すれば良さそうです。
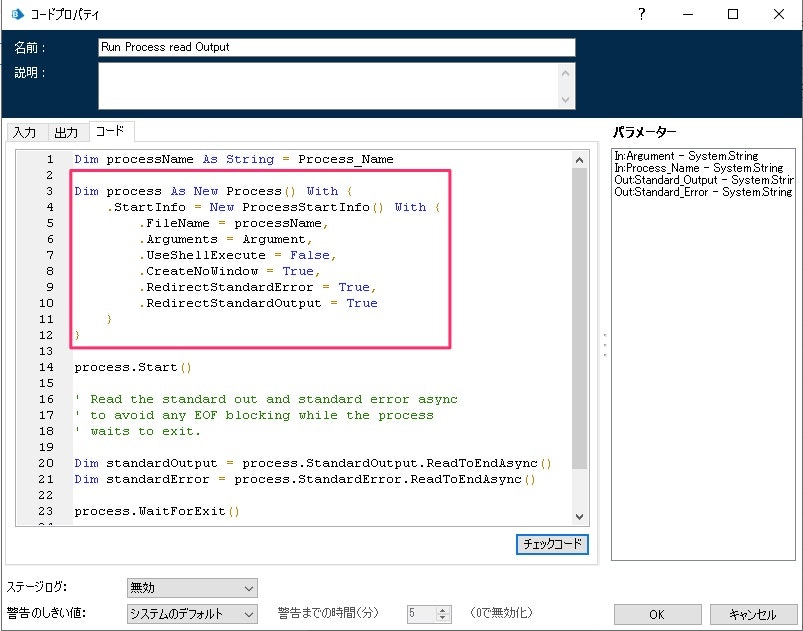
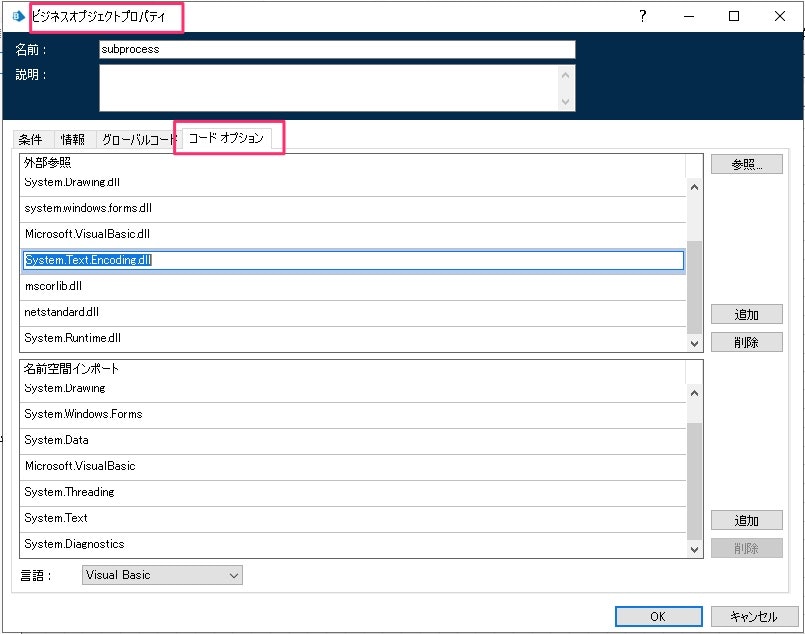
オブジェクトのアクションをコピーして、文字コードを UTF-8 に明示してみます。
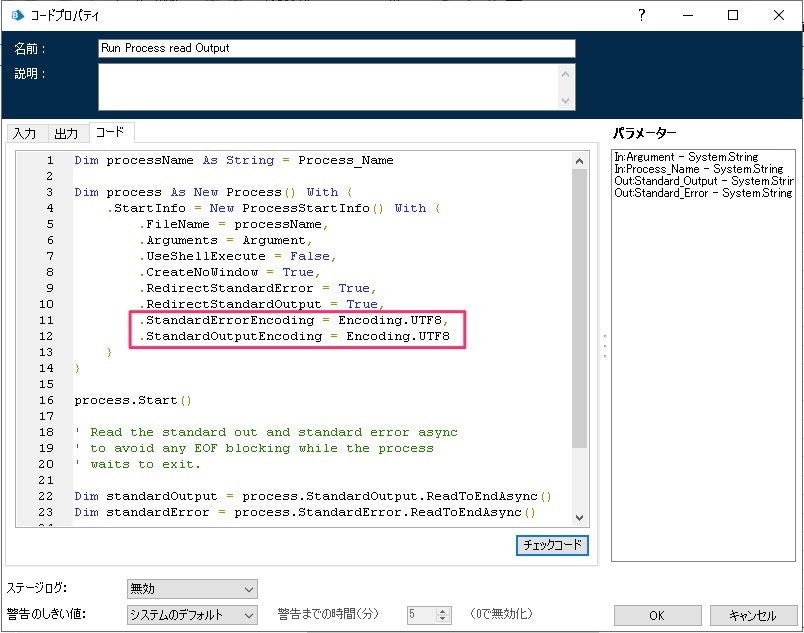
.NET Framework の Encoding クラス をみると、名前空間と必要なアセンブリが書かれているので、作成したオブジェクトの初期化アクションのビジネスオブジェクトプロパティ > コードオプション で必要なものを追加しておきます。
こうして作成したオブジェクトのアクションを、下記のような流れを組んで実際に実行してみます。
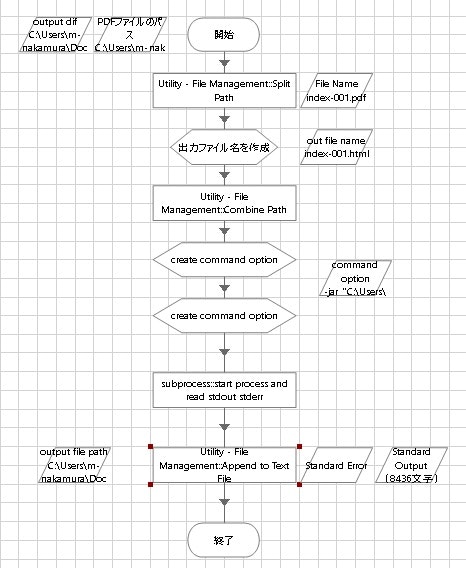
文字化けすることなく、Blue Prism 上のデータアイテムとして取得できました。(最後の IV も取れています!)