概要
本記事では、Rustにおいてスレッド間で変数を共有し読み書きする方法を説明したうえで、それがコンパイラにより安全に行われ、データ競合(data race)が起こらないことが保証されていることを説明します。
また、その安全性の点で特にC++と比較して優れており、業務アプリケーションや個人開発においても安心してマルチスレッドプログラミングができるという個人的感想も共有します。
そして最後にスレッド間で変数を共有して読み書きを行うことを活用する実装例として、メモ化と並列処理を組み合わせて実行時パフォーマンスを大幅に改善するコードを示します。
※本記事のコード例ではエラーハンドリングの実装は省略してunwrapで済ませています。threadやMutexなどの適切なエラーハンドリングのやり方についてはいつか別記事で扱いたいと思います。
読み込み専用の変数をスレッド間で共有する
テーブル参照用の大きなデータなどスレッド間で共有して読み込みのみ行う場合、参照カウンタを持つスマートポインタの一種であるArcを使えば実現できます。
use std::sync::Arc;
const THREAD_NUM: usize = 3;
fn main() {
let mut handles = vec![];
// 実際は大きなデータを共有する想定だが簡単のため3要素だけ入れておく
let v = Arc::new(vec![1, 2, 3]);
for _ in 0..THREAD_NUM {
let v = Arc::clone(&v);
handles.push(thread::spawn(move || {
// 実際はテーブル参照で処理を行う想定だが簡単のため単にprint
println!("[{}, {}, {}]", v[0], v[1], v[2]);
}));
}
handles.into_iter().for_each(|h| h.join().unwrap());
}
Arcで包まないと1回目のmoveでVecが無効になってコンパイルエラーになります。
const THREAD_NUM: usize = 3;
// コンパイルエラー!!
fn main() {
let mut handles = vec![];
let v = vec![1, 2, 3];
for _ in 0..THREAD_NUM {
handles.push(thread::spawn(move || {
// error[E0382]: use of moved value: `v`
println!("[{}, {}, {}]", v[0], v[1], v[2]);
}));
}
handles.into_iter().for_each(|h| h.join().unwrap());
}
かといってmoveせずに参照で渡そうとするとコンパイルエラーになります。
コンパイラはスレッドがいつ終了するかが分からないため、'staticの寿命(プログラム実行時から終了時までという最も長い寿命)を持つ変数の参照以外はスレッドに参照を渡すことができません。
// コンパイルエラー!!
fn main() {
let v = vec![1, 2, 3];
// error[E0597]: `v` does not live long enough
let v_ref = &v;
let handle = thread::spawn(|| {
// スレッド内に'staticより短い寿命の参照を持ち込むことはできない
println!("[{}, {}, {}]", v[0], v[1], v[2]);
});
handle.join().unwrap();
} // `v` dropped here while still borrowed
// コンパイルエラー!!
fn main() {
let v = vec![1, 2, 3];
// error[E0373]: closure may outlive the current function,
// but it borrows `v`, which is owned by the current function
let handle = thread::spawn(|| {
println!("[{}, {}, {}]", v[0], v[1], v[2]); // `v` is borrowed here
});
handle.join().unwrap();
}
ちなみにArcと同様に参照カウンタを持つスマートポインタにRcがありますが、こちらもコンパイルエラーとなります。
Rcはスレッドセーフでないため、コンパイラが事前にエラーにしてくれるのです。
use std::rc::Rc;
const THREAD_NUM: usize = 3;
// コンパイルエラー!!
fn main() {
let mut handles = vec![];
let v = Rc::new(vec![1, 2, 3]);
for _ in 0..THREAD_NUM {
let v = Rc::clone(&v);
handles.push(thread::spawn(move || {
// error[E0277]: `Rc<Vec<i32>>` cannot be sent between threads safely
println!("{:?}", v);
}));
}
handles.into_iter().for_each(|h| h.join().unwrap());
}
以上、長々とコンパイルエラーになるパターンを列挙しましたが、Rustではスレッドセーフでない変数をスレッドに渡そうとしたり、寿命の尽きた変数にアクセスするリスクが生じる場合はコンパイラが事前に弾いてくれるわけで、ここだけでもRustがマルチスレッドプログラミング初心者に優しい仕様だとわかります。
書き込みする変数をスレッド間で共有する(プリミティブ型の場合)
書き込みをする変数がプリミティブ型の場合、std::sync::atomicモジュール内のアトミック型を使用することができます。
以下のコードでは複数のスレッドがcurrent_numというアトミック型整数値をインクリメントし、10以上になったらスレッドを終了するという処理をしています。
なお、アトミック型もスレッド内にmoveされるためArcで包んでやる必要があります。
use std::sync::Arc;
use std::sync::atomic;
const THREAD_NUM: usize = 3;
fn main() {
let mut handles = vec![];
let current_num = Arc::new(atomic::AtomicUsize::new(0));
for _ in 0..THREAD_NUM {
let current_num = Arc::clone(¤t_num);
handles.push(thread::spawn(move || {
loop {
let n = current_num.fetch_add(1, atomic::Ordering::Relaxed);
if n >= 10 {
break;
}
println!("got {}", n);
}
}));
}
handles.into_iter().for_each(|h| h.join().unwrap());
}
書き込みする変数をスレッド間で共有する(Vec内の要素の場合)
Vecをスレッド間で共有し、pushなどでVec自体をいじることなく(Vecの&mut selfを取るメソッドを呼び出さずに)Vecの要素を読み書きする場合は以下のコードで実現できます。
正確に言うとMutexはRefCellのように内部可変性を持っているため、Vecの添字アクセスで不変参照を取得し、それを可変化して値の書き込みをすることができます。
不変参照を可変化するなんて危険なのでは無いかと(初見では)思うかもしれませんが、Mutexで包んでいる変数は排他制御されるので、複数箇所から可変参照として読み書きしても安全なのです。
この仕組みによってVec自体をMutexで包む必要はなくなります。
use std::sync::{Arc, Mutex};
const THREAD_NUM: usize = 3;
fn main() {
let mut handles = vec![];
let v = Arc::new(vec![Mutex::new(1), Mutex::new(2), Mutex::new(3)]);
for _ in 0..THREAD_NUM {
let v = Arc::clone(&v);
handles.push(thread::spawn(move || {
{
let mut n = v[0].lock().unwrap();
*n = 10;
println!("v[0] = {}", *n);
} // ここでnが破棄され、取得したロックが解放される
// ここで何か別の処理が挟まれる想定
// ...
println!("{}", v[0].lock().unwrap()); // ここでロック取得 -> 値読み込み -> ロック解放
}));
}
handles.into_iter().for_each(|h| h.join().unwrap());
}
ちなみに、Vec内の要素の書き込みより読み込みの方が頻繁に走る場合はMutexの代わりにRwLockを使用すると実行時パフォーマンスの改善を期待できます。
Mutexは読み込み書き込みともに同一のロックをかけるのに対し、RwLockではreadとwriteの2種類のロックが用意されていて、readを呼び出した場合は書き込みスレッドだけブロックして読み込みスレッドはブロックしないため、特定の要素の読み込みが同時に走るような状況下ではその分だけMutexよりも高速化されるという理屈です。
use std::sync::{Arc, RwLock};
const THREAD_NUM: usize = 3;
fn main() {
let mut handles = vec![];
let v = Arc::new(vec![RwLock::new(1), RwLock::new(2), RwLock::new(3)]);
for _ in 0..THREAD_NUM {
let v = Arc::clone(&v);
handles.push(thread::spawn(move || {
{
let mut n = v[0].write().unwrap(); // 書き込みはwriteメソッド
*n = 10;
println!("v[0] = {}", *n);
} // ここでnが破棄され、取得したロックが解放される
// ここで何か別の処理が挟まれる想定
// ...
println!("{}", v[0].read().unwrap()); // 読み込みはreadメソッド
}));
}
handles.into_iter().for_each(|h| h.join().unwrap());
}
書き込みする変数をスレッド間で共有する(Vecそのものをいじる場合)
複数のスレッドでVecの構造自体をいじる(pushやpopなど&mut selfを取るメソッドを呼び出す)場合、Vec全体をMutexで包む必要があります。
use std::sync::{Arc, Mutex};
const THREAD_NUM: usize = 3;
fn main() {
let mut handles = vec![];
let v = Arc::new(Mutex::new(vec![1, 2, 3]));
for _ in 0..THREAD_NUM {
let v = Arc::clone(&v);
handles.push(thread::spawn(move || {
let mut v = v.lock().unwrap();
v[0] = 10; // 書き込み可能
v.push(4); // v自体の操作が可能
let elem = v.pop().unwrap();
println!("popped = {}", elem);
}));
}
handles.into_iter().for_each(|h| h.join().unwrap());
}
VecをMutexに包まず前項のように要素だけをMutexで包む書き方をしてVecのpushメソッドを呼び出すとコンパイルエラーになります。
use std::sync::{Arc, Mutex};
const THREAD_NUM: usize = 3;
fn main() {
let mut handles = vec![];
let v = Arc::new(vec![Mutex::new(1), Mutex::new(2), Mutex::new(3)]);
for _ in 0..THREAD_NUM {
let mut v = Arc::clone(&v);
handles.push(thread::spawn(move || {
// error[E0596]: cannot borrow data in an `Arc` as mutable
v.push(Mutex::new(4));
}));
}
handles.into_iter().for_each(|h| h.join().unwrap());
}
安全にスレッド間共有変数を使えるRustのありがたみ
以上のように、Rustにおいて複数スレッドに変数を共有するときは、読み込み専用の場合、プリミティブ型の読み書きの場合、Vecの要素の読み書きの場合、Vec自体の操作の場合とでそれぞれに適した型が宣言されていることがわかります。
そして適さない型で宣言された変数が渡されるとコンパイルエラーになります。
こうすることで、Rustは特定の変数に対して複数スレッドによるデータ競合(data race)が発生しないことをコンパイル時に保証しているわけです。
C++では複数スレッドで自由に生の変数を読み書きすることができ、各メソッド毎に自由な粒度でロックの取得や解放をすることができます。
しかしその引き換えとして常にデータ競合の可能性をはらみ、特にマルチスレッドで実装された巨大な業務ソフトウェアでは非常にデバッグが困難な不具合が発生する危険が常にありました。
というのもC++のデータ競合によるエラーは実際にエラーが起きた場所ではなく無関係な場所まで進んでからセグメンテーションフォルトで落ちることがあり、もはやその時には吐かれたコアダンプをgdbのback traceで見ても原因が分かりません。
プロダクション環境で突然このようなことが起き、対応にほとほと困るという経験をした人は業務C++プログラマーには多いと思います。
C++はそれだけでなく、あらゆるライブラリ関数の呼び出しがスレッドセーフなのか調べないと分からず、たとえばOpenSSLのライブラリなんかは事前にmutexを渡したり特定の関数を呼び出したりなどの準備をしないとデータ競合に陥る危険があります。
そのため他のライブラリも含め調べる余裕が無いときは怪しい関数呼び出し全てにとにかくロックをかけるというせっかくのマルチスレッドプログラミングが台無しになるような実装も目にしてきました。
このような悪夢をコンパイル時に防いでくれるというだけでもRustの型チェックは非常にありがたい存在だといえます。
最初はなんでわざわざArcとMutexで包んだりしないとコンパイルエラーになるのか、難しいな、と感じるかもしれませんが、これが本当に頼れるお守りになるのです。
(ただしデッドロックについては完全に防ぐことができないので、マルチスレッドプログラミングがシングルスレッド並みに簡単になったわけではありません。)
スレッドに処理をさせて結果を受け取る方法
次に、別のスレッドで特定の処理を実行し、結果を受け取る方法を2種類紹介します。
処理毎にスレッドを立ち上げる
最もシンプルな方法で、クロージャで処理内容を渡し、各スレッドのhandleを通して処理結果を受け取ります。
デメリットは処理数分だけスレッドが立ち上がってしまうことで、処理数が多いと重くなります。(スレッドの立ち上げそのものに実行コストがかかることと、スレッドの数が多すぎるとコンテキストスイッチのコストもかかってきます。)
以下では0, 1, 2にそれぞれ1を足してその合計値(6)を計算するコード例を示します。
pub struct Data { n: i32 }
impl Data {
fn incr(&mut self) { self.n += 1; }
}
fn main() {
let mut handles = vec![];
let v = vec![Data { n: 0 }, Data { n: 1 }, Data { n: 2 }];
for mut data in v {
handles.push(std::thread::spawn(move || {
data.incr();
data // dataを処理結果として返却
}));
}
let mut sum = 0;
for handle in handles {
let data = handle.join().unwrap(); // ここで処理結果を受け取る
sum += data.n;
}
println!("sum = {}", sum); // 6
}
スレッドプールを作ってジョブを渡す
あらかじめ一定数のスレッドを立ち上げてスレッドプールを生成しておき、そのスレッドプールに処理内容を渡してstd::sync::mpscのチャネルを利用して処理結果を受け取る方法です。
CPUのコア数に応じた最適な数のスレッドを立ち上げられる点がメリットですが、スレッドプール自体は標準ライブラリで提供されていないことがデメリットです。
スレッドプールはThe Rust Programming Languageを参考に自分で実装するか、threadpoolという外部クレートを利用できます。
ここでは外部クレートのthreadpoolを利用したコード例を示します。
use threadpool::ThreadPool;
use std::sync::mpsc;
pub struct Data { n: i32 }
impl Data {
fn incr(&mut self) { self.n += 1; }
}
fn main() {
let n_workers = 4;
let pool = ThreadPool::new(n_workers);
let (tx, rx) = mpsc::channel();
let v = vec![Data { n: 0 }, Data { n: 1 }, Data { n: 2 }];
let n_jobs = v.len();
for mut data in v {
let tx = tx.clone();
pool.execute(move || {
data.incr();
tx.send(data).expect("channel will be there waiting for the pool");
});
}
let sum: i32 = rx.iter().take(n_jobs).map(|data| data.n).sum();
println!("sum = {}", sum); // 6
}
実際にスレッド間共有変数を活用する例
メモ化用のキャッシュにスレッド間共有変数を利用する例として以下の問題を考えてみましょう。
問題
毎回ランダムに配られる3色のカラーボールを2つの筒に1個ずつ入れていきます。
1つの筒には最大6個のカラーボールを1列に積むことができます。
12個のカラーボールを2つの筒に入れ終わった時点で、いずれかまたは両方の筒において同色のカラーボールが4つ以上接しているようにカラーボールを積める確率を求めてください。
なお、手元のカラーボールを積むまで次にどの色が来るかは見ることができないものとし、カラーボールをどちらの筒に入れるかは求める確率が最大となるように選択する(その時点での最善手を選択する)ものとします。
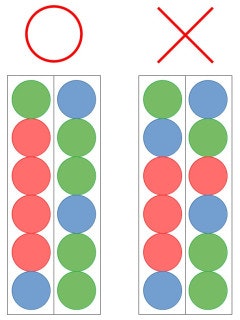
解法
大まかな戦略は、以下の擬似コードに示すような再帰関数で表現できます。
なお、Boardは実際にカラーボールが積まれている2つの筒を表現しているデータ構造だとします。
fn probability(n: usize, board: Board) -> f64 {
if n == 0 {
// 全てのカラーボールを積み終わった状態なので、確率は1.0か0.0のどちらか
// 2つの筒のいずれかに4つ以上の連結があれば1.0を返す
// そうでなければ0.0を返す
if board.is_connected() { 1.0 } else { 0.0 }
} else {
let mut sum = 0.0;
for color in ["赤", "緑", "青"] {
let mut max = 0.0;
// 最善手を取る想定なので、両方の筒に積んだ場合の確率を求め、最大値を採用する
for x in 0..2 {
let mut board = board.clone();
board.drop(x, color); // xの方の筒にボールを積む
let p = probability(n - 1, board); // 積んだ後の状態の確率を計算
if p > max {
max = p;
}
}
sum += max;
}
// 3色はランダムで来るのでそれぞれの場合の確率の平均値が求める確率となる
sum / 3.0
}
}
fn main() {
probability(12, Board::new());
}
ここで実行時の処理を高速化するため考えたいのが以下の2点です。
- マルチスレッドで並列に計算したい
- 計算途中で何度も同じBoardの状態が出現するはずなので、状態に対応する確率をキャッシュに保存したい
2について補足すると、たとえば左に赤、右に青、左に緑の順に置いた状態は、右に青、左に赤、左に緑の順に置いた状態と同じなので、この状態から4以上の連結が生じる確率は等しくなります。
また、問題の条件は2つの筒の並びを区別しないため、右に赤、左に青、右に緑と左右逆に置いた状態も等しくなります。
このように既に求めた値をキャッシュに保存して同じ計算を繰り返さないやり方をメモ化といいます。
そしてマルチスレッド環境においてこのメモ化を実現するためにはキャッシュ処理をスレッドセーフにしなければなりません。
そこで**「書き込みする変数をスレッド間で共有する(Vec内の要素の場合)」で説明したスレッド間共有変数を活用する**ことができます。
以下、実際に問題の確率を計算するコードを記載します。
問題では色数3、筒数2、筒の高さ6、カラーボール数12としましたが、コードではこれらの値が変化しても計算できるようにしました。(色数を増やす場合はenumの要素とallメソッドにYellowなど新しい色を追記する必要があります。)
ただ、計算量が指数オーダーとなってますので、色数を増やしたりカラーボール数を増やすと途端に処理に時間がかかったりキャッシュサイズが爆発したりするので注意してください。(自分の環境ではたとえば色数4、筒数3、高さ4、カラーボール数8は現実的に計算できました)
※本記事はあくまでスレッド間共有変数の活用をテーマにしているので深追いしませんが、これらの設定値が増えた時にキャッシュのメモリ使用量が爆発しないように制限したり、色についての対称性を利用してさらにキャッシュヒット率を高めたり、Boardのデータ構造自体をビット列にして処理を高速化したりなどの最適化の余地はたくさんあるかと思います。
マルチスレッドでスレッド間共有キャッシュを利用した解法の実装
use std::time::Instant;
use std::sync::{Mutex, Arc, RwLock};
use std::cell::RefCell;
use std::marker::{Sync, Send};
# [derive(Clone, Copy, PartialEq, Eq, PartialOrd, Ord, Debug)]
pub enum Color {
Red,
Green,
Blue,
}
impl Color {
fn all() -> Vec<Self> {
vec![Self::Red, Self::Green, Self::Blue]
}
fn len() -> usize {
Self::all().len()
}
// Color全種類とNoneを表現できるビット数(1色なら1ビット、2~3色なら2ビット、4~7色なら3ビット)
fn bits() -> usize {
let mut n = Self::len();
let mut count = 1;
while n > 1 {
count += 1;
n >>= 1;
}
count
}
// 色のビット表現(Noneを0としたいのでColor::Redを1とする)
fn to_bit(&self) -> usize {
*self as usize + 1
}
}
// width個の筒にカラーボールをheight個積むことができる筒のセットの状態を表現する構造体
# [derive(Clone, Debug)]
pub struct Board {
board: Vec<Vec<Option<Color>>>
}
impl Board {
pub fn with_size(width: usize, height: usize) -> Self {
let mut board = vec![];
for _ in 0..width {
let mut line = vec![];
for _ in 0..height {
line.push(None);
}
board.push(line);
}
Self { board }
}
pub fn width(&self) -> usize {
self.board.len()
}
pub fn height(&self) -> usize {
self.board[0].len()
}
// カラーボールを積める最も高い位置のインデックスを返す
pub fn top(&self, x: usize) -> usize {
let mut y = 0;
while y < self.height() && self.board[x][y] != None {
y += 1;
}
y
}
// カラーボールを落として設置する
pub fn drop(&mut self, x: usize, color: Color) {
let y = self.top(x);
debug_assert!(y >= self.height());
self.board[x][y] = Some(color);
}
// Boardの状態のビット表現。筒の並びは問わないため筒のビット表現の値順にソートして計算
pub fn serialize(&self) -> usize {
let mut v = vec![];
for line in &self.board {
let mut data = 0;
for color in line {
data <<= Color::bits();
if let Some(c) = color {
data += c.to_bit();
}
}
v.push(data);
}
v.sort();
let mut data = 0;
for line in v {
data <<= Color::bits() * self.height();
data += line;
}
data
}
// いずれかの筒において同色のカラーボールがconnection_size個以上連続して積まれていたらtrueを返す
pub fn is_connected(&self, connection_size: usize) -> bool {
for line in &self.board {
let mut count = 0;
let mut current_color = Color::Red;
for color in line {
if let Some(c) = color {
if *c == current_color {
count += 1;
if count >= connection_size {
return true;
}
} else {
current_color = *c;
count = 1;
}
} else {
break;
}
}
}
false
}
}
// 確率計算のメモ化に使用するキャッシュのインターフェース
pub trait Cache {
fn with_len(len: usize) -> Self;
fn len(&self) -> usize;
fn get(&self, board: &Board) -> Option<f64>;
fn set(&self, board: &Board, data: f64);
}
// シングルスレッド用のキャッシュ構造体
// MutexCache / RwLockCacheとインターフェースを共通化するためRefCellで包んでいる
pub struct RefCellCache {
cache: Vec<RefCell<Option<f64>>>,
}
// Mutexを使用したスレッドセーフなキャッシュ構造体
pub struct MutexCache {
cache: Vec<Mutex<Option<f64>>>,
}
// RwLockを使用したスレッドセーフなキャッシュ構造体
pub struct RwLockCache {
cache: Vec<RwLock<Option<f64>>>,
}
// キャッシュを使用しないことを示す空の構造体
pub struct NoCache { }
impl Cache for RefCellCache {
fn with_len(len: usize) -> Self {
let mut cache = Vec::<RefCell<Option<f64>>>::with_capacity(len);
for _ in 0..len {
cache.push(RefCell::new(None));
}
Self { cache }
}
fn len(&self) -> usize { self.cache.len() }
fn get(&self, board: &Board) -> Option<f64> {
let i = board.serialize();
if i < self.cache.len() {
*self.cache[i].borrow()
} else {
None
}
}
fn set(&self, board: &Board, data: f64) {
let i = board.serialize();
if i < self.cache.len() {
self.cache[i].replace(Some(data));
}
}
}
impl Cache for RwLockCache {
fn with_len(len: usize) -> Self {
let mut cache = Vec::<RwLock<Option<f64>>>::with_capacity(len);
for _ in 0..len {
cache.push(RwLock::new(None));
}
Self { cache }
}
fn len(&self) -> usize { self.cache.len() }
fn get(&self, board: &Board) -> Option<f64> {
let i = board.serialize();
if i < self.cache.len() {
*self.cache[i].read().unwrap()
} else {
None
}
}
fn set(&self, board: &Board, data: f64) {
let i = board.serialize();
if i < self.cache.len() {
*self.cache[i].write().unwrap() = Some(data);
}
}
}
impl Cache for MutexCache {
fn with_len(len: usize) -> Self {
let mut cache = Vec::<Mutex<Option<f64>>>::with_capacity(len);
for _ in 0..len {
cache.push(Mutex::new(None));
}
Self { cache }
}
fn len(&self) -> usize { self.cache.len() }
fn get(&self, board: &Board) -> Option<f64> {
let i = board.serialize();
if i < self.cache.len() {
*self.cache[i].lock().unwrap()
} else {
None
}
}
fn set(&self, board: &Board, data: f64) {
let i = board.serialize();
if i < self.cache.len() {
*self.cache[i].lock().unwrap() = Some(data);
}
}
}
impl Cache for NoCache {
fn with_len(_: usize) -> Self { Self { } }
fn len(&self) -> usize { 0 }
fn get(&self, _: &Board) -> Option<f64> { None }
fn set(&self, _: &Board, _: f64) { }
}
// 条件を満たす確率を求める関数
// Cacheを使用する場合と使用しない場合とで共通の実装になっているが
// Cacheトレイト実装型として引数に与えられる型は静的ディスパッチで決定されるため
// NoCacheを与えた場合はコンパイラの最適化によりキャッシュ処理のコードは削除される
pub fn probability(n: usize, board: Board, connection_size: usize, cache: &impl Cache) -> f64 {
// 最後まで積み終わった状態で、設定された連結数以上に連結があれば条件を満たす
// 条件を満たしている場合は確率1、満たしていない場合は確率0を返す
if n == 0 {
if board.is_connected(connection_size) {
1.0
} else {
0.0
}
} else {
// キャッシュがある場合はキャッシュの値を返す(NoCacheの場合は常に存在しない)
if let Some(c) = cache.get(&board) {
return c;
}
let mut sum = 0.0;
// ランダムに来るn色の場合の確率をそれぞれ計算してsumに足していく
for color in Color::all() {
let mut max = 0.0;
// どの筒に入れるかは、入れた場合にもっとも確率が高くなる方に入れるという判断をする
// もっとも確率が高くなる方に入れた場合の確率がmax変数に入る
for x in 0..board.width() {
if board.top(x) >= board.height() {
continue;
}
let mut board = board.clone();
board.drop(x, color);
let p = probability(n - 1, board, connection_size, cache);
if p > max {
max = p;
}
}
sum += max;
}
// sumを色数で割って得られる確率の平均値が求める確率
let p = sum / Color::len() as f64;
// 得られた確率はキャッシュにも格納しておく(NoCacheの場合は何もしない)
cache.set(&board, p);
p
}
}
// threaded_n回目の呼び出しまでスレッドを立ち上げて並列処理を行う
pub fn probability_parallel<T>(n: usize, threaded_n: usize, board: Board,
connection_size: usize, cache: &Arc<T>) -> f64
where T: Cache + Sync + Send + 'static
{
if n <= 1 || threaded_n == 0 {
// 以降の計算は各スレッドにおいて直列処理を呼び出して処理を続行
probability(n, board, connection_size, cache.as_ref())
} else {
let mut handles_map = vec![];
for color in Color::all() {
handles_map.push(vec![]);
for x in 0..board.width() {
if board.top(x) >= board.height() {
continue;
}
let mut board = board.clone();
let cache = Arc::clone(&cache);
let handle = std::thread::spawn(move || {
board.drop(x, color);
probability_parallel(n - 1, threaded_n - 1, board, connection_size, &cache)
});
handles_map[color as usize].push(handle);
}
}
let mut sum = 0.0;
for handles in handles_map {
let mut max = 0.0;
for handle in handles {
let p = handle.join().unwrap();
if p > max {
max = p;
}
}
sum += max;
}
sum / Color::len() as f64
}
}
pub fn print_elapsed_times(elapsed_nanos: &Vec<u128>, label: &str) {
let unit = 1_000_000_000.0;
println!("{} (min): {:.4} [s]", label, *elapsed_nanos.iter().min().unwrap() as f64 / unit);
println!("{} (max): {:.4} [s]", label, *elapsed_nanos.iter().max().unwrap() as f64 / unit);
println!("{} (mean): {:.4} [s]", label,
elapsed_nanos.iter().sum::<u128>() as f64 / (unit * elapsed_nanos.len() as f64));
}
fn main() {
let width = 2; // 筒の個数
let height = 6; // 1本の筒に積めるカラーボールの最大数
let n = 12; // カラーボールを積む総数
let connection_size = 4; // 条件を満たすのに必要な同色のカラーボールの連結数
let threaded_n = 2; // スレッドを立ち上げる再帰の深さ(2なら色数3・筒数2のとき6 + 6 * 6 = 42スレッド)
let cache_size = 2usize.pow((width * height * Color::bits()) as u32);
let board = Board::with_size(width, height);
println!("cache_size = {}", cache_size);
// 処理時間にばらつきが生じるためそれぞれ3回計測
let repeat_num = 3;
// 直列処理キャッシュ無し
let mut elapsed_nanos = vec![];
for _ in 0..repeat_num {
let start = Instant::now();
let p = probability(n, board.clone(), connection_size, &NoCache::with_len(0));
let end = start.elapsed();
elapsed_nanos.push(end.as_nanos());
println!("p = {} (elapsed: {:.4})", p, end.as_nanos() as f64 / 1_000_000_000.0);
}
print_elapsed_times(&elapsed_nanos, "Serial without cache");
// 並列処理キャッシュ無し
let mut elapsed_nanos = vec![];
for _ in 0..repeat_num {
let cache = Arc::new(NoCache::with_len(0));
let start = Instant::now();
let p = probability_parallel(n, threaded_n, board.clone(), connection_size, &cache);
let end = start.elapsed();
elapsed_nanos.push(end.as_nanos());
println!("p = {} (elapsed: {:.4})", p, end.as_nanos() as f64 / 1_000_000_000.0);
}
print_elapsed_times(&elapsed_nanos, "Parallel without cache");
// 直列処理RefCellキャッシュ使用
let mut elapsed_nanos = vec![];
for _ in 0..repeat_num {
let cache = RefCellCache::with_len(cache_size);
let start = Instant::now();
let p = probability(n, board.clone(), connection_size, &cache);
let end = start.elapsed();
elapsed_nanos.push(end.as_nanos());
println!("p = {} (elapsed: {:.4})", p, end.as_nanos() as f64 / 1_000_000_000.0);
}
print_elapsed_times(&elapsed_nanos, "Serial with RefCellCache");
// 並列処理Mutexキャッシュ使用
let mut elapsed_nanos = vec![];
for _ in 0..repeat_num {
let cache = Arc::new(MutexCache::with_len(cache_size));
let start = Instant::now();
let p = probability_parallel(n, threaded_n, board.clone(), connection_size, &cache);
let end = start.elapsed();
elapsed_nanos.push(end.as_nanos());
println!("p = {} (elapsed: {:.4})", p, end.as_nanos() as f64 / 1_000_000_000.0);
}
print_elapsed_times(&elapsed_nanos, "Parallel with MutexCache");
// 並列処理RwLockキャッシュ使用
let mut elapsed_nanos = vec![];
for _ in 0..repeat_num {
let cache = Arc::new(RwLockCache::with_len(cache_size));
let start = Instant::now();
let p = probability_parallel(n, threaded_n, board.clone(), connection_size, &cache);
let end = start.elapsed();
elapsed_nanos.push(end.as_nanos());
println!("p = {} (elapsed: {:.4})", p, end.as_nanos() as f64 / 1_000_000_000.0);
}
print_elapsed_times(&elapsed_nanos, "Parallel with RwLockCache");
}
実行環境
OS: Windows 10 (64 bit)
CPU: Intel Core i9-7980XE 2.60GHz (18コア36スレッド)
メモリ: DDR4-2666 32GB クアッドチャネル (ARD4-U32G48SB-26V-Q D4 2666 8GBx4)
実行コマンド: cargo run --release
※--releaseオプションをつけないと実行時の処理が非常に遅くなるため気をつけてください。
実行結果
main関数で実行した各処理方法の確率の値と、3回の実行の平均時間を掲載します。
確率の値: 0.8548550074232134
直列処理キャッシュ無し: 165.5067秒
並列処理キャッシュ無し: 23.3474秒
直列処理RefCellキャッシュ使用: 0.3293秒
並列処理Mutexキャッシュ使用: 0.1002秒
並列処理RwLockキャッシュ使用: 0.1044秒
キャッシュ(メモ化)を利用すると劇的に処理時間が短くなっていることが分かります。
並列処理をすることでさらに早くなっています。
ただしこの問題は直列処理の方がキャッシュヒット率が高いのか、コア数18のCPUの割には速度改善率が小さくなってます。
また、この問題では特定のキャッシュに同時に読み込みが走る頻度が少ないためかMutexを用いたキャッシュとRwLockを用いたキャッシュとで処理時間の差はほとんどありませんでした。(実行するたびに結果が逆転したりします)
結論として、スレッド間共有キャッシュを用いた並列処理によって、直列処理キャッシュ無しと比べて1500倍以上高速に問題を解くことができました。
おわりに
本記事ではRustで安全にスレッド間共有変数を利用できることと、そのありがたみについて実装例を交えて説明してきました。
私は以前にC++でゲーム木探索に分類されるようなコードを趣味で書いていたのですが、直列処理を前提に最適化しまくっていたそれを並列処理できるように改修を進めたところ、どこかで実装をミスったのかどうしても実行時のセグメンテーションフォルトを解消することができずに諦めたことがあります。
その後は再挑戦することなく年月が経っていったのですが、本記事で書いたようにRustでは同じようなセグメンテーションフォルトの悪夢に悩まされることが無いということで、10年ぶりにそのコードのRustへの移植と並列処理化に着手し始めました。
とても大きなコードなので時間がかかりそうですが、Rustの勉強を兼ねて久々に楽しくコードを書けています。
C++は特にtemplateの機能がRustのジェネリクスより圧倒的に表現力が高く大好きな言語なのですが、そのようなC++の表現力や自由度の代償としての数々の落とし穴のことを考えると今後はもうRustに完全移行しようと思っています。(もちろん前提としてC++に対して実行時パフォーマンスが低下しないことが必要ですが、今のところ大きな問題を感じません。)
その気持ちが特に強く高まったのがマルチスレッドプログラミングでしたので、本記事でRustの魅力が少しでも読者に伝われば幸いです。