概要
ここ数日(記事初出時点)、MidJourney等の テキストから画像を生成するAI が話題になっています。
筆者もDALL-EとMidjourneyの2つを試してみたので、その比較をしてみました。
なおこの記事ではDALL-EやMidjourneyでのアカウントの作成の仕方、画像の生成の仕方等は解説しません。
注意事項
この記事で掲載している画像は、すべて筆者が指定したテキストに基づき、両サービスのAIが生成したものです。
画像生成は、2022/8/1から8/5にかけて行っており、その時点での両サービスによる生成結果です。
もし本画像により本記事の読者が何らかの被害(不快な思いなど)を被った場合、それは画像を記事に掲載した筆者にあり、両サービス及びAIには一切の責任はありません。
DALL-Eについて
OpenAIが開発。現在、一般公開された招待制。DALL-EのWebサイトに行って登録申請すれば、招待されます。
筆者申請時は数日で招待が来ましたが、もっとかかる場合もある模様。
登録すると初回は、50回分のクレジットが付与され、以降は毎月15回分のクレジットが付与されます。超える分は有料。
テキストから画像を生成するほか、画像をアップロードしてそれの続きを書かせるのもできる模様(そちらは試していない)。
Webサイト上で画像が生成される。英語のみ。
1つのテキストから4枚の画像が生成され、生成された画像のバリエーションをさらに作成することも可能。
Midjourneyについて
Midjourneyが開発。現在、一般公開されており、登録申請すればすぐ使えます。Discordアカウントが必要です。
初回は25回分のクレジットが付与されます。以降は月額の課金制で個人向けプランでは、月10.00ドル(200回分/月) or 30.00ドル(無制限)があります。有料会員だと生成した画像の商用利用が可能です。
同じく、1つのテキストから4枚の画像が生成され、生成された画像のバリエーションをさらに作成することも可能なほか、画像を高精細化することも可能。
比較
では両サービスの画像を比較します。
なお比較は基本的に、
- DALL-E 初回生成された4枚のうち筆者が気になった1枚
- Midjourney 初回生成された4枚の低精細画像、またはそのバリエーションを高精細化(Upscaling)したもの
で行います。
post-apocalypse submerged city like tokyo(東京っぽい水没した人類滅亡後の都市)
水惑星年代期みたいな水没した都市は好きなのです。
| DALL-E | Midjourney |
|---|---|
 |
 |
| 初回生成 | バリエーションの高精細 |
どちらも比較的イメージ通りになっていますが、DALL-Eが水上なのに対し、Midjourneyは水面下っぽいのが違いはあります。
どちらも東京らしさを近代的な高層ビル群と捉えている模様。
Japanese light novel illustration style silver-haired beautiful girl(日本のラノベ調の銀髪の美少女)
ど定番のキャラ造形
| DALL-E | Midjourney |
|---|---|
 |
 |
| 初回生成 | バリエーションの高精細 |
DALL-Eはちょっとラフ画っぽいが、ラノベっぽい感じはします。Midjourneyは顔各部のパーツはラノベっぽい気もしつつ、絵のタッチがあまりラノベじゃない。
Japanese light novel illustration style silver-haired beautiful girl with very big sword in ruined city(日本のラノベ調の荒廃した都市にいるバカでっかい剣を持った銀髪の美少女)
ど定番のキャラ造形に少しアクセントを加えてみたもの。
| DALL-E | Midjourney |
|---|---|
 |
 |
| 初回生成 | バリエーションの高精細 |
DALL-Eの方がラノベの表紙っぽく、Midjourneyは挿絵っぽいでしょうか。
同じラノベ調の銀髪の美少女なのに、DALL-Eは一気にラノベ感が増してます。剣、荒廃した都市のテキストに具体性が出てフィクションのイメージがマッチしやすくなった?
beautiful lady, ride on dragon, wearing leather armor and feather helmet, having lance/flying in the sky/auguste mestral(美しい淑女、竜に乗り、革鎧と羽付きの兜をまとい、槍を持っている。空を飛んでいる。オーギュスト・メストラル風)
タクティクスオウガのドラゴンテイマーとヴァルキリーを足したようなイメージ。
オーギュスト・メストラルは写真家。MidjourneyにStyleのサンプル例としてあったから指定してみました。
| DALL-E | Midjourney |
|---|---|
 |
 |
| 初回生成 | バリエーションの高精細 |
DALL-Eの方がイメージが正確だろうか。絵としてはMidjourneyの方が好き。ただ、どちらも槍は持ってない。
craft man of whiskey distillation with whiskey still pot.(ウィスキー蒸留の職人。ウィスキーのスティルポット(蒸留釜)も。)
ウィスキーのスティルポットを認識するかを確認してみたくて指定したテキスト。
本当はバルジ型まで指定したかったのですが、スペルが分からなかったため断念…
| DALL-E | Midjourney |
|---|---|
 |
 |
| 初回生成 | 初回生成 |
DALL-Eはいい。Midjourneyはなんでしょう、これ…、アルコールランプ…?
Midjoureyを先に試したのですが、最初自分の英文が悪いのかな?と思いましたが、DALL-Eはきちんと解釈できているので、おそらくMidjourneyのAIの知識不足。
little fairy girl in cyberpunk glass cylinder filled amber liquid(琥珀色の液体に満ちたガラス製のスチームパンクな円筒容器に閉じ込められた妖精の少女)
先のMidjourneyのウイスキー画像にインスパイアされて生成してみました。
ファンタジーやSFでありそうな、妖精の瓶詰めのイメージ。
| DALL-E | Midjourney |
|---|---|
 |
 |
| 初回生成 | 初回生成 |
DALL-Eは初回生成の4枚のうち一枚しか載せていませんが、これはMidjourneyの方がイメージを掴んだ画像を生成してくれました。
2 girls walking on railroad. The railroad runs straight from the front of the screen to the horizon. clear sky. both sides of railroad are blue and clear sea surface showing through the submerged city. A distant view of a building sticking out of the water. realistic(線路上を歩く2人の少女。線路は画面手前から水平線にまっすぐ伸びている。晴れた空。線路の両脇は、水没した都市が透ける青く透明な海。遠景には水上から突き出たビル。写実的)
水惑星年代期の表紙っぽさを出したみたかった。
| DALL-E | Midjourney |
|---|---|
 |
 |
| 初回生成 | バリエーションの高精細 |
これもMidjourneyの方がよりテキストの内容を表現できてます。
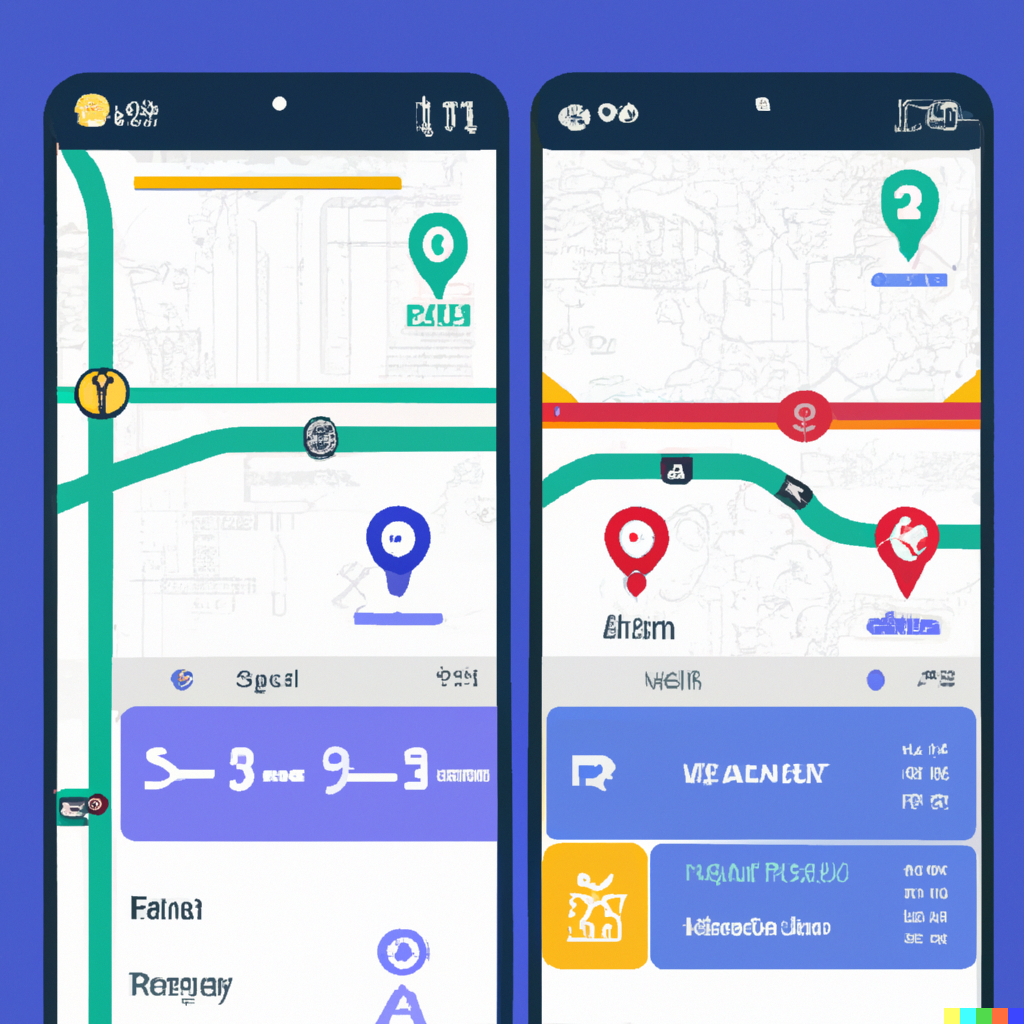
UI of public transportation route finding app like navitime, google map and so on.(ナビタイムやGoogleマップとかみたいな公共交通の経路検索アプリのUI)
UIのイメージを出力できるか確認したくて試したテキストです。
経路検索アプリなのは本業がらみ。
| DALL-E | Midjourney |
|---|---|
 |
 |
| 初回生成 | 初回生成 |
これはDALL-Eの方が遥かにそれっぽいイメージを生成してます。
Midjourneyは左上が地図っぽいくらい。
3 miniture cars lined up. police car, fire engine and ambulance./plastic toy(3台のミニカー。パトカーと消防車と救急車。プラスチックのおもちゃ)
| DALL-E | Midjourney |
|---|---|
 |
 |
| 初回生成 | 初回生成 |
どちらもそれらしい画像は生成できています。
これMidjourneyは、パトカー・消防車・救急車みたいに併記されると、それらを個別に並べるんじゃなくて、よっしゃ合体させよう!みたいになるらしく…。
画像のように車が並んだ画像を生成するテキストを作るのに苦労しました。それでも右下はパトカーと消防車が混じった奇怪な一台が…
karaage with lemon/osamu tedsuka(レモンを添えた唐揚げ。手塚治虫)
唐揚げをいろんなトーンでAIに生成させるのが流行ってると聞いて…
| DALL-E | Midjourney |
|---|---|
 |
 |
| 初回生成 | バリエーションの高精細 |
どちらも手塚治虫らしさは全くないですね…。
唐揚げはきちんと生成されていますが、Midjourneyのレモンの添え方がダイナミックすぎます。居酒屋で唐揚げ頼んでこれ出てきたらびっくりする。
その他
そのほかにもテキストの読解力や想像力を試したかったり、ただの性癖だったり、アーマードコアやブラッドボーンのイメージを再現させたい画像を生成しているのですが、割愛します。
なおどちらのサービスも性的な画像や暴力的な画像は生成されない(ワードが弾かれる)ようになっています。
Midjourneyでは「gun」は通りましたが、DALL-Eでは「gun」はポリシーに反すると生成されませんでした(クレジットは消費されず)。
画像生成系AIについての雑感
課題
- 文章の解釈がおかしい
- 自然言語処理の解釈も進展しているので、そのうち解決します
- あるいはテキストを指定する側の文章力の問題
- (2022/9/5追記)
- 文章力についてはAIの理解に人が寄せる方向に一気に進みましたね
- 文章が上手い人じゃなくて、AIに指示する文章の上手い人
- noteに多い。Qiitaには少ないですね。本質的に技術的じゃないからですが、AIのモデルからプロンプトの書き方を理解するみたいな記事ならQiita的だと思います(プロンプトガイドは書き方を指南してくれますが技術観点からなぜそう書くのかはあまり書かれてない印象)
- 生成される画像がおかしい
- 元画像の収集や学習によるもの。本質的な問題点ではないですね
- 意図がない
- 人が絵を描くときにこめる意図(デザインなら使い勝手を想像した意匠、イラストならオマージュで仕込んだ細部など)があるかという意味の課題
- AIは考えているのではなく、確率的にそれらしいものを作るだけなので、これはAIが意識を持たないとこの先もないと思う。これはコンピュータ式AIの情報工学的限界と思います
- 一貫性がない
- 例えばゲームのコンセプトアートだと、一定の調子で世界観を表すさまざまな場面を描く必要がありますが、DALL-EやMidjourneyのような汎用画像生成AIは苦手(テキストが少し変わるだけで調子が変わる。生成ごとに調子が変わる)な分野だと思います
- これは一定の調子でファインチューニングすれば解決する可能性がありますが、じゃあそのファインチューニングする元のイラストをどうしようとなると、人が描くしかないわけで。なら最初からそのイラストレーターに発注しますよね。
- 画像生成AIの開発コストが劇的に下がり、コンセプトアートをスタッフが自由に生成するニーズがあるなら、ファインチューニング用のイラスト作成のみをイラストレータに発注、AI開発後はAIに生成させるというのがサービスとして成り立ちます
- 私はゲーム開発には疎いのですが、コンセプトアートをスタッフが自由に生成するというニーズはあるのでしょうか
- (2022/9/5 追記)
- 1ヶ月もしないうちにStable Diffusionが出て画像生成AIの開発コストが劇的に下がった!(Google Colabなら無料枠で可能。実用するならGPU搭載の物理マシンか仮想マシンの費用はそこそこかかる)
- Stable Diffusionならファインチューニングできます
- そしてファインチューニングして絵柄を模倣するサービスを作ったのがmimicと…
- mimicが発表当時にStable Diffusionを使っていたと誤解を招きそうなので補足
雑感
非常に将来性は感じます。
上にあげた課題もいくつかは現在(あるいは数年後には)でも解決可能な問題でしかありません。
エロが描けないのはありますが、それらはニーズがあれば、そのうちつくられます。
本質的な課題もありますが、その解決が必ずしも必要かというとそうでもないです。
例えば、意図はありませんが、私が趣味で描かせたい絵なら別に意図はいらないですし、note書くときのヘッダやちょっとパワポにつけたい画像、部屋に貼りたいポスターくらいなら、今あるレベルのAIでも十分役目を果たす画像は生成されます。
意図がないと困るのは、「デザインなど人の使い勝手を想像する必要」だったり、それこそラノベイラストのように「元になるイメージがないところから文章だけで新規のキャラデザをする」みたいなところで、逆に言えばそうした領域は今後も人が残るかと思います。
(2022/9/5追記 と思ったんですが、これラノベ作家の榊一郎さんがTwitter(出典が見つからなかった…)で述べてましたが、最近はキャラデザの指定を著者がすることが増えたそうで…。
今後は原稿読んでキャラを起こせない絵師はAIに取って代わられるかもです。だって作者も編集者もいちいち人間とやりとりするのめんどくさいもん。
作者がいちいち指定するならAIに描かせて大体のキャラデザイン作るようになるかも。で、5枚くらい絵師に起こしてもらって、あとはmimicみたいなファインチューニングできるサービスで場面を指定してイラストを描くと。絵師より安い。起こすのすら発注しないかも?)
ビジネスの種として見ると、絵心が全くなくても、それらしい絵を1分で4枚のスピードで生成できるというのが非常に強力です。
自分では絵を描けないが、描きたいものをAIに描かせて、それを商売にするというのも将来的に成り立つ可能性はありそうです。
これまでも画家は自分の内面世界を絵にして売ってる側面があったわけですが、それに必要な絵画の技術がなくなり、画風は平凡だが持ってる想像を絵を描けなくても絵にできるようになります。そうした人の内面世界そのものがより手軽に売り物にできるようになる。
(ひょっとしたら今はテキスト入れてポンと、バリエーション出させるくらいですが、今後はより対話的になって「もうちょっとほっぺたをふっくら」みたいな細部の調整ができれば、言葉が筆になるかもしれない)
逆にいうとイラストレータなどでも凡庸な想像(凡庸なキャラデザイン、癖のない画風、平凡な構図)しかないのであれば、AIで良いになるかもしれません。
「絵を描く技術は身につけないが想像の出力としての絵を要する」というニーズ、「人手では追いつかない大量の画像生成を要する」というニーズが(現在顕在してなくても潜在的にも)どこまであるかが、市場性についてはカギかと思います。
(2022/9/5 この記事、私の本筋ではなく(文章生成AIの記事の方が現在は本筋)追記しないつもりでしたが、言及した方がいい動向が多かったので追記。市場ニーズについてですが、「(人が意図を込めて書いた美術性を高品質と定義して)低〜中品質の絵を安価に生成」するというニーズでも市場は成り立ちます)
日本初のAI画集についての指摘と将来AIの歴史を編纂する人へのメッセージ(2022/9/23)
社内のSlackでは8月下旬のこの記事を書いた頃に、「今後半年でAIで描いたイラストの画集を出す人が出る」と書いていましたが、先日、852話さんがインプレスR&DからAI画集を出されるというニュースがありました。
これ、インプレスR&Dは「本書は、現在大きく関心が高まっているイラスト画像生成AIを使って制作された、日本初の画集・画像集です。」と謳っていますが、私の観測する限りでは、 日本初ではないです 。
すでにAmazon Kindleで早いのは8月時点、9月上旬にはAI画集が出版されています(一例:9/7時点で私が見つけていたもの。AIイラスト集(魔法少女編))。
Amazon Kindleでの出版(個人出版かつ電子のみ、しかも本拠は日本ではない)を日本での出版としない=日本の出版社が出した紙も含めての商業出版なら、同書は私の知る限りでは日本初のAI画集です(同人誌では紙冊子でありそうですが、同人誌までは調べてません。なので真の日本初は不明です。日本はコミケ文化もあり、個人レベルの出版活動まで含めるとかなりの追跡調査を要します。少なくともここ10年内のコミケカタログは調査すべきです)。
ただ、同社は出版の定義にこだわらず、 日本初の画集・画像集 としていますので、それは違うよ、とは突っ込んでおきます。
旧来の自費出版、Kindleなどによる(特に電子の)個人出版、同人誌の出版まで範囲を広げると、商業出版の会社としては目が行き届かないのかと思います。
なお852話さんは、noteのアカウントも持たれていますが、そちらは有料なので読んでいません。ひょっとしてそちらに今回の件についての何かが書かれているかもしれませんが、私自身のこの指摘は、 あくまでインプレスR&Dのアピールの一言について日本初じゃないよというただの事実の指摘 です。
あとこの指摘、852話さんやインプレスR&Dなどに突っ込んだりしないでください。
この追記をした理由は、今後、日本におけるAIの歴史を編纂する人が、同書より前にAI画集が日本になかったと解釈しないように記載したものです。それ以前にもAI画集は非商業出版のレベルであったんだよというのを認識いただくためのものです。
多分この指摘の存在自体、気づいてほしい歴史の編纂をする人は、気づかないでしょうが、ひっそりと歴史とネットの片隅に記載しておきます。