GBFSのアドベントカレンダー2022も半ばですね。
さて、今回は、GBFSを使ってステーション(自転車を借りる・返す拠点)の利用率…時間経過と利用数をヒートマップにして地図上に可視化したいと思います。
使う技術とその環境は以下の通りです。
- GoogleAppScript
- Python 3.9.13
- folium 0.12.1.post1
- Pythonで地図UIを扱うライブラリ。HeatMapWithTimeを使います
本記事では、OpenStreet株式会社(ハローサイクリング) / 公共交通オープンデータ協議会のバイクシェア関連情報(GBFS形式)をCC-BY4.0に従って利用しています。
https://ckan.odpt.org/dataset/c_bikeshare_gbfs-openstreet
はじめに
まず、GBFSとはなんぞやについては、@kumatira さんの記事に詳しいのでそちらを参照ください。
さて、GBFSのフォーマットの特徴として、リアルタイムな状況を示すものであるという点が挙げられます。
GBFSを取得すると、シェアサイクルのステーションの名前や住所、座標のほか、今このステーションに何台の借りられる車両があるか、何台駐輪スペースがあるかの情報が得られます。
しかし、これらの情報はリアルタイムなため、取得時点の情報しか分かりません。
1分後に情報を更新すれば、もう1分前の状態は分かりません。
そのため利用状況を追いかけるには、取得したGBFSを蓄積する必要があります。
前回の記事で紹介したbicidataというライブラリはそれをやろうとしたようなのですが、難ありだったので、今回は自分で蓄積します。
GBFSを蓄積する
Pythonでgbfs-clientを使って作るか、bicidataを改修するか考えたのですが、自宅マシンを立ち上げっぱなしにしておくのが嫌だったのでやめました。
なので今回は定期的に実行させることができて、取得したデータを蓄積するところまで、クラウドで完結するGoogleAppScriptを使いました。
取得スクリプトはこんな感じです。
//GBFSをJSONオブジェクトとして取得
function get_gbfs(type) {
//gbfsを取得
let url = "https://api-public.odpt.org/api/v4/gbfs/hellocycling/station_" + type + ".json";
//URLにリクエストしてレスポンスとしてjsonデータを読み込む
let response = UrlFetchApp.fetch(url).getContentText();
console.log("fetch " + type + ".json ok...");
//jsonにパース
let json = JSON.parse(response);
return json;
}
//SpreadSheetのシートオブジェクトを取得
function get_sheet_obj() {
sheet_id = 'spreadsheetのID';
sheet_name = 'シート1';
sheet = SpreadsheetApp.openById(sheet_id).getSheetByName(sheet_name);
return sheet;
}
//小平近辺のステーションに限定する
function filter_gbfs(address) {
target_cities = [
'小平市',
'東久留米市',
'西東京市',
'小金井市',
'国分寺市',
'東大和市',
'東村山市'];
for( city of target_cities ) {
if( address.includes(city) )return true;
}
return false;
}
function main() {
//スクリプト実行のタイミング制御用。実行タイミングのずれを考慮し前後10分までは許容
var date = new Date();
hhmm = Utilities.formatDate(date, "Asia/Tokyo", "HH:mm");
if( hhmm < "14:50" || hhmm > "18:10") {
return ;
}
console.log(date + " : gbfs saving start...");
//gbfsをjsonで取得
information_json = get_gbfs("information");
//gbfsから必要な項目を配列に保持
add_gbfs_rows = []
for( gbfs_row of information_json["data"]["stations"] ) {
//必要な都市だけに絞る。念の為、最大自転車数の取れないステーションは捨てる。本来はstation_statusのis_rantalを見るべき
if( filter_gbfs(gbfs_row["address"]) && gbfs_row['vehicle_type_capacity']['num_bikes_limit'] > 0 ) {
add_gbfs_rows.push([
information_json['last_updated'],
gbfs_row['station_id'],
gbfs_row['name'],
gbfs_row['lat'],
gbfs_row['lon'],
gbfs_row['address'],
gbfs_row['vehicle_type_capacity']['num_bikes_now'],//停車している自転車数(使用不可の自転車含む)
gbfs_row['vehicle_type_capacity']['num_bikes_limit'],//ステーションの最大自転車数
gbfs_row['vehicle_type_capacity']['num_bikes_parkable'],//駐輪可能台数
gbfs_row['vehicle_type_capacity']['num_bikes_rentalable']])//貸し出し可能台数
}
}
console.log("gbfs analyzing ok, filtered gbfs length is " + add_gbfs_rows.length);
//sheetオブジェクトを取得
sheet = get_sheet_obj();
last_row = sheet.getLastRow() + 1;
range = sheet.getRange(last_row, 1, add_gbfs_rows.length, 10);
range.setValues(add_gbfs_rows);
console.log("gbfs saved...");
}
スクリプトについていくつか補足です。
データは小さくしました
この記事で述べている通り、私は小平あたりでシビックテックというグループの一員なので、ステーションは小平近辺に絞ります。という言い訳で、単にログの数を絞りたかっただけです。
次に取得する時間帯を午後3時から6時まで、15分刻み、3日間に絞りました。
これを絞った理由に言い訳はありません。数を絞りたかっただけです。
機械処理において数は暴力です。やはり暴力、暴力は全てを解決する、なんてことはありません。むしろ崩壊します。振るわれる方です。
それに対抗するにはやはり暴力です。ストレージです。マシンパワーです。つまりお金です。 そんなものはない!
というわけで数が増えると処理をなるたけ高速化したりなどの工夫も必要になってきて面倒なので、数を絞りました。
蓄積先は、迷いましたがスプレッドシートで。
取得ごとにGoogleDriveにCSVファイルで出力するのも考えましたが、あとで結合するのが面倒なので、最初からスプレッドシートで書き足していけばいいやと。
これも数が小さいからできることです。全ステーションの情報をもっと頻繁にもっと長い期間取っていたら、スプレッドシートの限界を突破したでしょう。
GBFS外の項目
どうもHELLO CYCLINGのGBFS(station_information)には、GBFS仕様外の項目があります。
- vehicle_type_capacity.num_bikes_now //ステーションにある台数
- vehicle_type_capacity.num_bikes_limit //ステーションの最大台数
- vehicle_type_capacity.num_bikes_parkable //駐輪可能な台数
- vehicle_type_capacity.num_bikes_rentalable //貸し出し可能な台数
この4つですね。
HELLO CYCLINGの公式ステーションマップやstation_statusの類似項目と値が一致してました。
便利なのでこの値をこのまま使うことにしました。
分析仕様を定める
今回は利用率の可視化なので、1日の動きを追えれば良さそうです。
なので3日分取りましたが、使うのは1日分です。
まずステーションの「利用」を以下の通り、定義します。
- ステーションにある自転車が貸し出される
- ステーションに自転車が返される
貸し出された数+返された数を変化量とします。
以下、実際の台数をもとに変化量の計算式を説明していきます。
| 時間 | 自転車の台数 (最大16台) |
貸出可能台数 | 駐輪可能台数 |
|---|---|---|---|
| 3:00 | 4 | 4 | 11 |
| 3:15 | 5 | 5 | 10 |
| 3:30 | 6 | 5 | 10 |
| 3:45 | 7 | 6 | 7 |
さて、分析するにあたり、2つ考慮しないといけない点があります。
- 返却予約(30分前まで可能)
- 貸出予約(30分前まで可能)
3:00の例を見てみましょう。
最大16台に対し、自転車の台数4に駐輪可能台数11を足すと、15。1台分空いています。
この1台分の正体は次のどちらかです。
- 返却予約がされているため、駐輪可能台数の枠が1つ減っている
- つまり物理的には12台分のラックが空いているが、1台分は予約されているためシステム上は駐輪不可としている
- 故障などのため、貸出できない
- 本当は5台駐輪されているが、うち1台は充電切れなど回収が必要なため、自転車の台数としてカウントしていない
数値の仕様が明確でないため、後者も論理的には否定できませんが、ロジックとして不自然です。
回収が必要で貸し出せないなら、現地の自転車数とシステム上(つまりユーザーがアプリでみる)の自転車数を相違させる必要はありません。貸出台数を減らせばいい話です。
なので、今回の分析では、num_bikes_limit - num_bikes_now - num_bikes_parkableは、 返却予約数とします。
次に貸出予約です。
3:30を見ると自転車台数は6台なのに、貸出可能な台数は5台です。1台足りません。
この1台分の正体は次のどちらかです。
- 貸出予約がされているため、貸出可能台数の枠が1つ減っている
- つまり物理的には6台分の自転車があるが、1台分は予約されているためシステム上は貸出不可としている
- 故障などのため、貸出できない
- 本当は6台駐輪されているが、うち1台は充電切れなど回収が必要なため、貸出自転車の台数としてカウントしていない
これは本当にどちらか分かりません。
なので、 今回は故障自転車は考えず 、貸出予約されているものとします。
num_bikes_now - num_bikes_rentalableを貸出予約とします。
そうすると返却予約と貸出予約を足すと、先の表はこうなります。
| 時間 | 自転車の台数 (最大16台) |
貸出可能台数 | 駐輪可能台数 | 貸出予約数 | 返却予約数 |
|---|---|---|---|---|---|
| 3:00 | 4 | 4 | 11 | 0 | 1 |
| 3:15 | 5 | 5 | 10 | 0 | 1 |
| 3:30 | 6 | 5 | 10 | 1 | 0 |
| 3:45 | 7 | 6 | 7 | 1 | 2 |
そうすると、予約が履行された結果、本来あるべき台数と、実際の台数の差が出せます。
これは3:45の数字を見ると説明しやすいです。
3:30時点では6台あり、貸出予約が1、返却予約は0です。
つまりそれらが履行されると、3:45時点では本来6-1で5台しかないはずです。しかし、実際には7台と2台増えています。これはこの30分以内に予約の有無を問わず返された数と見做せます。
もし逆に4台に減っていた場合、これは30分以内に予約の有無を問わず1台貸し出されたと見做せます。
これらから変化量の計算は下記で導けます。
Rr = num_bikes_limit[n] - num_bikes_now[n] - num_bikes_parkable[n] //返却予約数
Sr = num_bikes_now[n] - num_bikes_rentalable[n] //貸出予約数
Ne = num_bikes_now[n] + Rr - Sr //30分後にあるべき台数
Nr = num_bikes_now[n+1] //30分後に実際あった台数
IF ( Nr - Ne ) < 0 : Sa = abs(Nr - Ne) //予約外で貸し出された数
ELSE : Ra = abs(Nr - Ne) //予約外で返された数
C = Rr + Sr + Sa + Ra //変化量
nは分析するタイミングとする
15分以内に行われた貸し返しは分析した時点の変化量とします。
つまり3:30時点の変化量を算出するのに、3:45時点の台数を参照してはいますが、3:30代にあった変化ということになります。
3つただし書です。今回は、取得頻度が15分と荒いので、その間に数字に現れない貸し借りが生じる可能性は十分にあります。
例えば3:00から3:15の間に2台返されて、2台貸し出されたとします。
その場合、変化量は+4されるべきですが、自転車の台数は±0のため、3:15時点の結果に反映されていません。
これは仕方ないので諦めます。1分単位で取ればそこも分かるでしょう。
あと30分以内に利用される返却、貸出の予約の集計がうまくないです。15分後だと履行されている可能性もあれば、されていない可能性もあるためです。
これが30分刻みなら、履行されたものとして考えてしまってもいいのですが、15分だと微妙です。
ですが、そこは実際どうだったかはわかりませんので、 予約された時点で利用したもの(変化した) とみなすことにします。
最後に自転車のローテーションです。
HELLO CYCLINGの運用はわかりませんが、シェアサイクルは、自転車の偏りを是正するのに自転車が余っているステーションから足りないステーションに自転車を移動させることがあります。
それにより利用ではない増減が生じる可能性がありますが、それは数値から推測できないため、ローテーションはしないものとします。
では、変化量を含めて表にしてみましょう。
| 時間 | 自転車の台数 (最大16台) |
貸出可能台数 | 駐輪可能台数 | 貸出予約数 | 返却予約数 | 変化量 |
|---|---|---|---|---|---|---|
| 3:00 | 4 | 4 | 11 | 0 | 1 | 1 |
| 3:30 | 5 | 5 | 10 | 0 | 1 | 1 |
| 4:00 | 6 | 5 | 10 | 1 | 0 | 3 |
| 4:30 | 7 | 6 | 7 | 1 | 2 | - |
これをすべてのステーションについて、1日分行います。
その分析はPythonでします。
分析スクリプト
蓄積したGBFSをgbfs_storage.csvとしてローカルにダウンロードします。
ここから分析スクリプトです。
import datetime
import pandas as pd
#CSV読み込み、初日に限る
df = pd.read_csv('gbfs_storage.csv')
df = df[df['last_updated'] <= 1669528351]
df['num_reserve_return'] = df['num_bikes_limit'] - df['num_bikes_now'] - df['num_bikes_parkable'] #返却予約を追加
df['num_reserve_rental'] = df['num_bikes_now'] - df['num_bikes_rentalable'] #貸出予約を追加
df['num_estimate_bikes'] = df['num_bikes_now'] + df['num_reserve_return'] - df['num_reserve_rental'] #30分後の推定台数を追加
#タイムスタンプを日時に変換
def to_datetime(t):
d = datetime.datetime.fromtimestamp(t, datetime.timezone(datetime.timedelta(hours=9)))
return d.strftime('%Y/%m/%d %H:%M:%S')
df['datetime'] = df['last_updated'].apply(to_datetime)
#時系列ごとの変化量を作成
def calc_change(df, i):
estimate = df[i:i+1]['num_estimate_bikes'].iat[0] #あるべき台数
real = df[i+1:i+2]['num_bikes_now'].iat[0] #実際あった台数
if (real - estimate) < 0:
rental_add = abs(real - estimate)
return_add = 0
else:
rental_add = 0
return_add = real - estimate
return df[i:i+1]['num_reserve_return'].iat[0] + df[i:i+1]['num_reserve_rental'].iat[0] + rental_add + return_add + 1#変化量
#ヒートマップ表示用のリスト(3次元配列)
'''
[
[#3:00時点
[lat, lon, 変化量],#ステーションの情報
...
],
...
]
'''
change_data = [[] for _ in range(len(df['last_updated'].drop_duplicates()))]
for _id in df['id'].drop_duplicates():
df_station = df[df['id'] == _id]
df_station.reset_index(inplace=True, drop=True)
changes = [calc_change(df_station, i) for i in range(len(df_station) -1)]
changes.append(1)
lat = df_station['lat'].iat[0]
lon = df_station['lon'].iat[0]
for i in range(len(change_data)):
change_data[i].append([lat, lon, changes[i] / 13])
変化量に+1しているのは、foliumのHeatmapWithTimeは、0の値があるとよくないらしいので。
また実際やってみましたが、どうも0.0 - 1.0あたりのレンジを表示するようなので、最大の変化量を探して12(補正して13)だったので、それで割り算して、レンジを1.0以下になるよう調整しています。
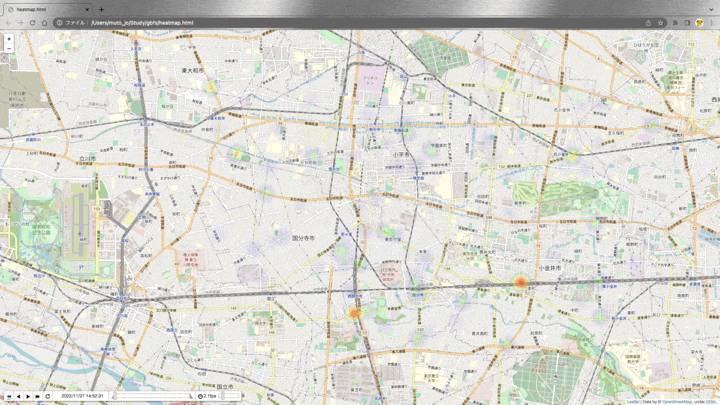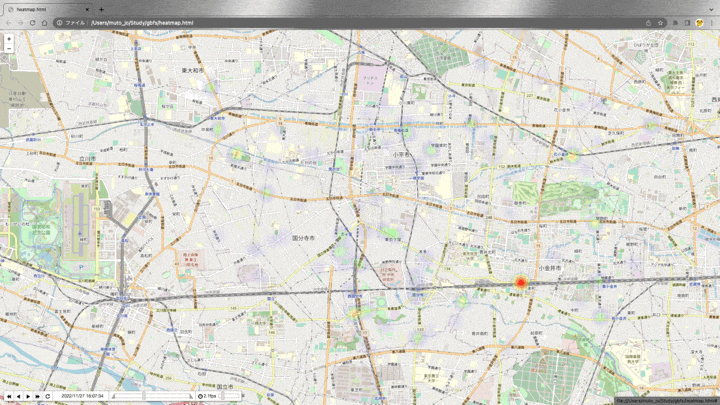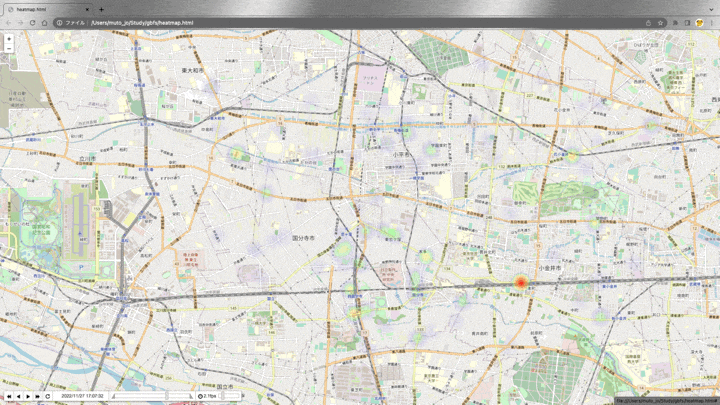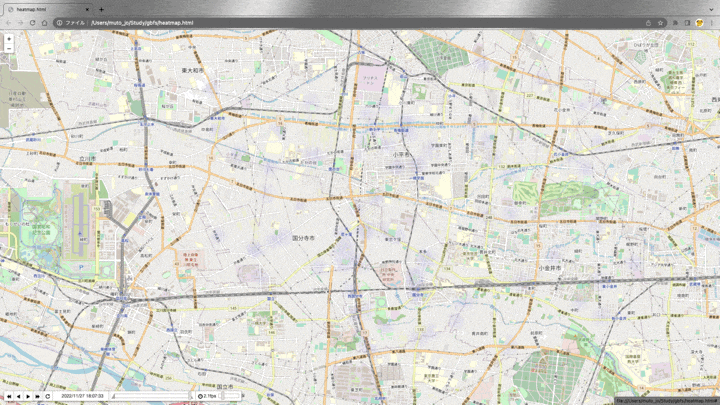
ヒートマップで表示
import folium
from folium import plugins
time_index = [datetime for datetime in df['datetime'].drop_duplicates()]
base_map = folium.Map(location = [35.7257966,139.4788924], zoom_start=13) #小平市役所の座標
hm = plugins.HeatMapWithTime(
change_data, index=time_index,
auto_play=True, radius=30, max_opacity=1,
gradient = {0.1: 'blue', 0.2: 'lime', 0.3:'yellow', 0.5: 'orange', 1.0:'red'})
hm.add_to(base_map)
base_map
デフォルトのgradientだと、変化量が少ない(0.1-0.3ほど)のステーションが多いため、色味を調整しています。
表示した結果がこちらです。