私が書く、GBFSアドベントカレンダーの記事もこれで3つ目です。
今回は、GBFSを解析して、自転車がどの程度の確率で借りられるかを算出してみます。
使う技術とその環境は以下の通りです。
- GoogleAppScript
- Python 3.9.13
- folium 0.12.1.post1
- Pythonで地図UIを扱うライブラリ。HeatMapWithTimeを使います
本記事では、OpenStreet株式会社(ハローサイクリング) / 公共交通オープンデータ協議会のバイクシェア関連情報(GBFS形式)をCC-BY4.0に従って利用しています。
https://ckan.odpt.org/dataset/c_bikeshare_gbfs-openstreet
はじめに
まず、GBFSとはなんぞやについては、@kumatira さんの記事に詳しいのでそちらを参照ください。
今回の記事は、前回の記事で蓄積したGBFSを使っています。
蓄積については、下記の記事を参照してください。
確率の算出モデルを策定する
今回は蓄積したデータが1日3時間(15分刻み)、3日間のみと小さいです。
データ数が少ないので、シンプルに その時間帯において貸出可能な自転車が1台以上ある確率 にしたいと思います。
数式にすると、 自転車が1台以上貸し出しできる日数 / 集計日数 です。
シンプルですね。
1台以上ある日が3日中、3日なら100%、2日なら66.6%、1日なら33.3%、1日もなければ0%です。
もう少し真面目に算出モデルを考察する
それだけだとつまらないので、もう少し確率の算出モデルを考えてみます。
もし、もっときちんとデータを取ったら。
例えば、1日3時間15分刻みは同じでも、半年ほど取ったとします。
そうすると、曜日という軸で確率を考えることができます。
月曜日15時というタイミングのデータが半年分=180日分あります。180日だと、自転車が何台あるかは、ある程度分散してきます。貸出可能な自転車が豊富な日もあれば、1台もない日もあるでしょう。
1台もない確率、1台ある確率…MAX台ある確率と、台数ごとの確率も算出できます(その合計は1になります)。
とはいえステーションごとの利用率は、曜日・時間帯である程度決まるでしょうから、正規分布するのでないでしょうか。最頻値の台数の±数台の範囲で90%近くになるかと思います。
最大自転車数が4台のステーションで、ある曜日のある時間帯に貸し出せる自転車の数の確率分布は、以下のように表現できるかと思います。
| 貸出可能台数 | 利用確率(%) |
|---|---|
| 0 | 10 |
| 1 | 25 |
| 2 | 35 |
| 3 | 22 |
| 4 | 8 |
分析スクリプト
さて、まあ単純に1台以上ある日が何日あるかだけなので、スクリプトもそう難しくありません。
import pandas as pd
import datetime
import itertools
df = pd.read_csv('gbfs_storage.csv')
#今回は時間帯で分析するので、last_updatedは日付と時間に分ける
def to_date(t):
d = datetime.datetime.fromtimestamp(t, datetime.timezone(datetime.timedelta(hours=9)))
return d.strftime('%Y/%m/%d')
#時間は細かいズレを補正し15分刻みにする(15:02 -> 15:00)
def to_time(t):
d = datetime.datetime.fromtimestamp(t, datetime.timezone(datetime.timedelta(hours=9)))
h = int(d.strftime('%H'))
m = int(d.strftime('%M'))
m = m // 15 * 15
return '{:02}:{:02}'.format(h, m)
df['date'] = df['last_updated'].apply(to_date)
df['time'] = df['last_updated'].apply(to_time)
#IDと時間帯の一覧
id_list = df['id'].drop_duplicates().to_list()
time_list = df['time'].drop_duplicates().to_list()
rate_df = pd.DataFrame() #確率を保持
#ステーションを時間帯ごとに分析
for c in itertools.product(id_list, time_list):
d = df.query('id == {} and time=="{}"'.format(c[0], c[1])).reset_index()
s = d.loc[0:0, ['id', 'name', 'lat', 'lon', 'time']]
#ここが確率の算出モデル。貸出可能台数が1台以上ある日が何%か
s['rate'] = len(d[d['num_bikes_rentalable'] > 0]) / len(d)
rate_df = pd.concat([rate_df, s])
これで分析はOKです。
rate_dfには、ステーション、時間帯ごとの利用確率が入っています。
可視化してみよう
時間帯ごとのデータなので、利用確率の時間推移を可視化してみましょう。
time_index = [time for time in rate_df['time'].drop_duplicates()]
rate_data = [[] for _ in range(len(time_index))]
#ヒートマップ表示用に確率を補正する
def normalize_rate(rate):
if rate <= 0.0:
rate = 0.01
return rate
for _id in rate_df['id'].drop_duplicates():
df_station = rate_df[rate_df['id'] == _id]
df_station.reset_index(inplace=True, drop=True)
rates = [df_station[i:i+1]['rate'].iat[0] for i in range(len(df_station))]
for i in range(len(rate_data)):
rate_data[i].append([df_station['lat'].iat[0], df_station['lon'].iat[0], normalize_rate(rates[i])])
import folium
from folium import plugins
base_map = folium.Map(location = [35.7257966,139.4788924], zoom_start=13) #小平市役所の座標
hm = plugins.HeatMapWithTime(
rate_data, index=time_index,
auto_play=True, radius=30, max_opacity=1,
gradient = {0.1: 'blue', 0.4: 'green', 0.7:'yellow', 1.0:'red'})
hm.add_to(base_map)
base_map
今回はヒートマップのGIF化を割愛します(すみません、面倒でした…)。
こんな感じになりました。
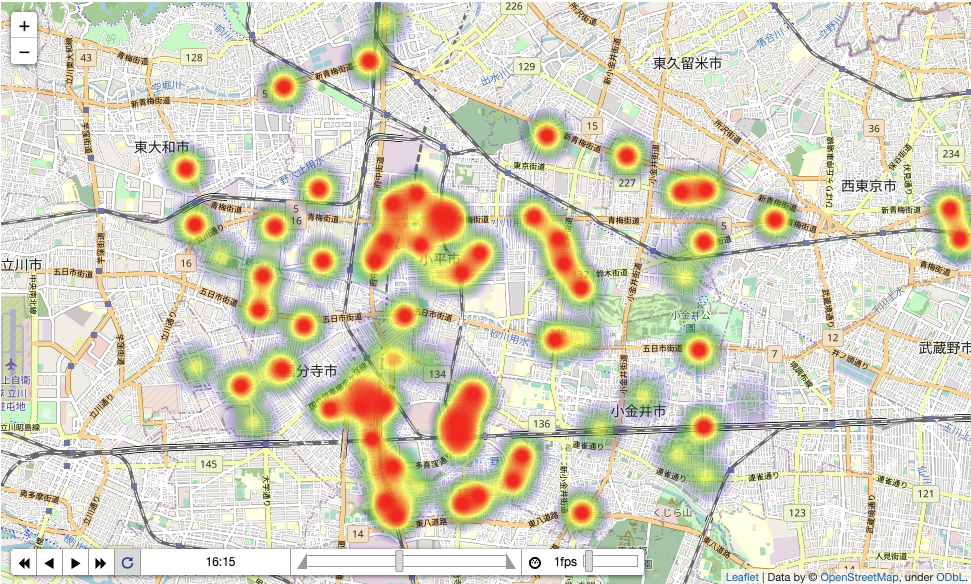
全般的に借りられないというい事態は少ないようですね。
API化する
さて、ID、時間帯ごとに利用確率を保持したDataFrameができたので、これをAPIにしてみましょう。
def get_estimate_rate(station_id, _time):
'''
ステーションの利用確率を取得する
Parameters
---------------
station_id : int
ステーションID
_time : str
時刻
Return
------
rate : float
利用確率
'''
tmp = rate_df.query('id == {} and time == "{}"'.format(station_id, _time))['rate']
return tmp.iat[0]
こんな感じで使います。
print(get_estimate_rate(1556, "14:45"))
0.6666666666666666
API化した理由
API化したのは、この利用確率が経路検索に使えるからです。
現在、国内の経路検索事業者では、シェアサイクルを取り込んだ結果を出すようになっています。
例えばこちらジョルダンが運営する乗換案内でのシェアサイクルの検索結果です。
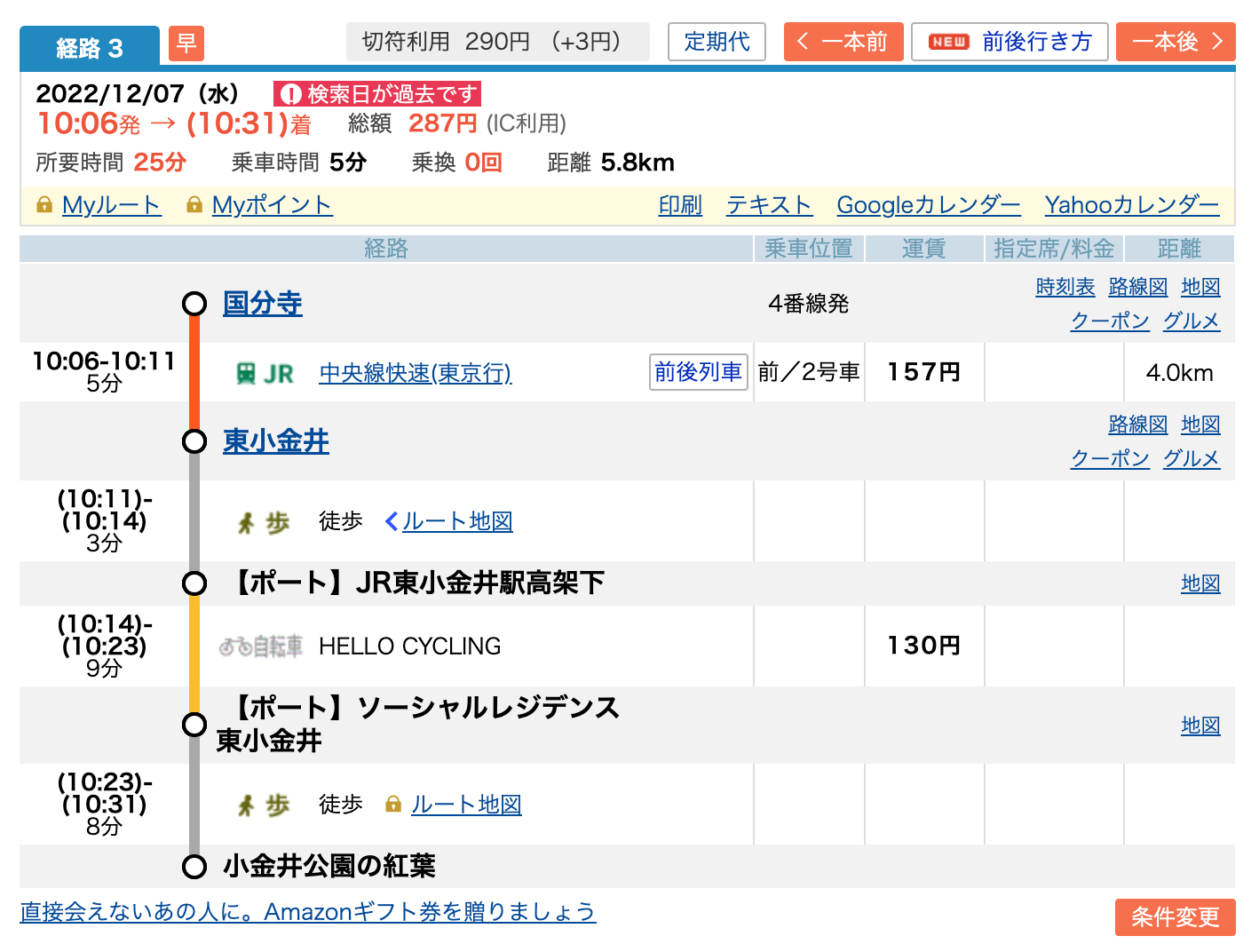
国分寺で電車に乗る前にこの経路を検索したとします。
検索時点で貸出が0台でも、実際に乗りに行くときには自転車がある可能性はありますし、逆に検索時点にあっても実際現地に行ったときには自転車がないということも考えられます。
まあ上の例は、検索時点でステーションまで8分なので、利用予約しますね。ないなら諦めるでしょう。
しかし、これがもう少し距離があるなら、電車で移動する間にステーションの状況は変わり得ます。
経路検索を案内する上で、 実際に現地に着いた時間に借りられるかどうか の予測を出せれば、ユーザーの経路選択の重要な指標になるはずです。
補足
検索した交通手段が使えるかどうかは、鉄道でもバスでも発生します。鉄道は一両編成でもそれなりの定員数があるため、平常時であれば実質問題にはならないのと、バスも通常、需要に合わせた車両を用いるため、これも平常時であれば、大きな問題は起きないでしょう。
コミュニティバスは数人乗りの小さな車両のことがあり、積み残しのリスクは上がります。
シェアサイクルは、鉄道・バスに比べれば使えない可能性は高いと思います。
反面、GBFSでデータが取れるので、データに乏しいバスに比べ、予測を立てやすいのは長所です。
借りられる見込みがないなら、シェアサイクルを利用する経路は諦めるか、今なくても借りられる見込みがあるかなどの判断がつくようになります。
API化の考えを示したのは、GBFSを蓄積、分析して曜日・時間帯ごとの利用確率を出しておくことで、経路検索した結果にシェアサイクルの利用可能性を表示できると思いついたためです。
個人的には面白いアイデアだと思ってますが、どうでしょうか?