この記事は、Numerai Advent Calendar 2021 の16日目の記事です。
はじめに
このツイート内容と一部、重複します。
ツイート内容に加えてTB200の結果、新旧neutralize関数による結果も記載します。
変更履歴
- 2022-01-23
- モデルのURLを追加
- 2022-05-10
- 画像サイズを変更
- 2022-04-03にアナウンスのあった新Diagnosticsの結果を追加
- その他、文言や画像表示を微調整
- 2022-09-04
- R332以降は、これらのモデルの予測提出は停止するので、最終提出のR331を追記
データセットの20分割
のフォーラム記事でmdoさんが言及されている分割方法です。
ターゲットのオーバラップを避けるために、Eraを以下のようにパージングして全体を4つグループの分けます。
Eraグループ1: 0001, 0005, 0009, ...
Eraグループ2: 0002, 0006, 0010, ...
Eraグループ3: 0003, 0007, 0011, ...
Eraグループ4: 0004, 0008, 0012, ...
さらに、特徴量1050個を210個の区切りで、全体を5つのグループに分けます。
特徴量グループ1: 1 ~ 210
特徴量グループ2: 211 ~ 420
特徴量グループ3: 421 ~ 630
特徴量グループ4: 631 ~ 840
特徴量グループ5: 841 ~ 1050
このようにして、4 * 5 = 20 で、データセットが20分割になります。
アンサンブル結果
- ターゲット: target_nomi_20
- 学習アルゴリズム: LGBMRegressor
- パラメータ (exampleと同じ)
- n_estimators: 2000
- learning_rate: 0.01
- max_depth: 5
- num_leaves: 2 ** 5
- colsample_bytree: 0.1
ノーマル
今回、20個の各データセットで学習して、予測値の平均を求めてアンサンブルしてみました。
- Diagnostics
| All | TB200 |
|---|---|
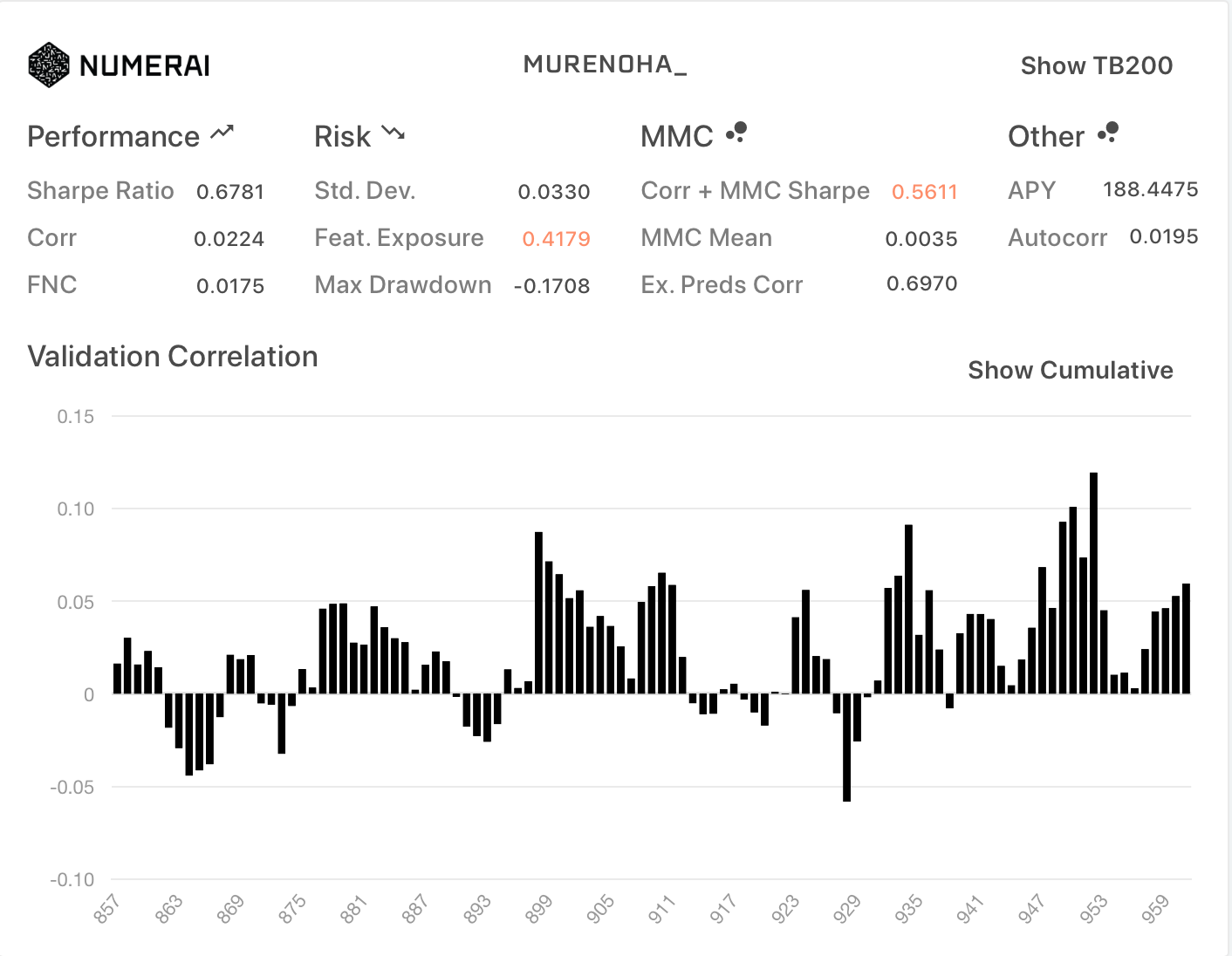 |
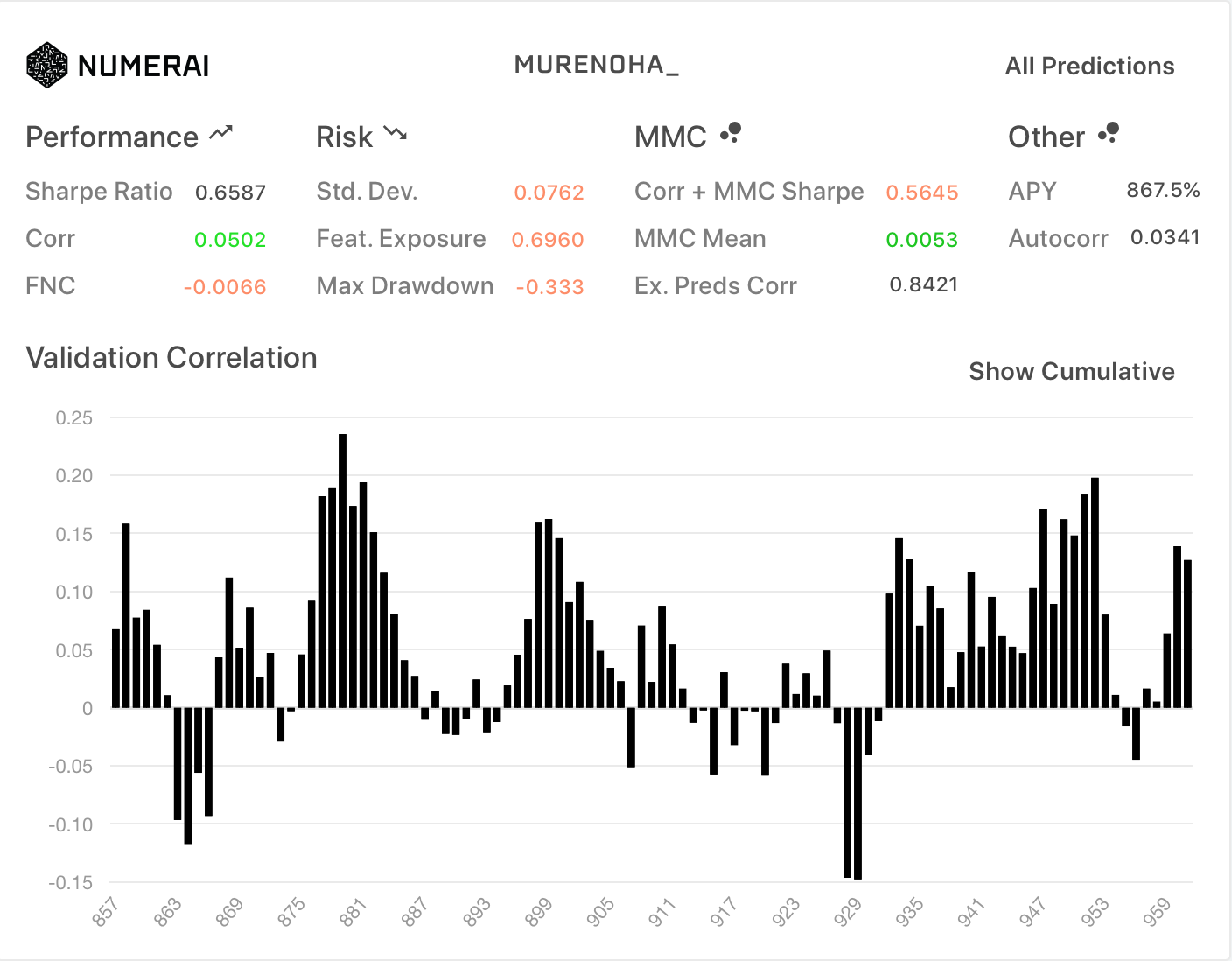 |
- 新Diagnostics
| All | TB200 |
|---|---|
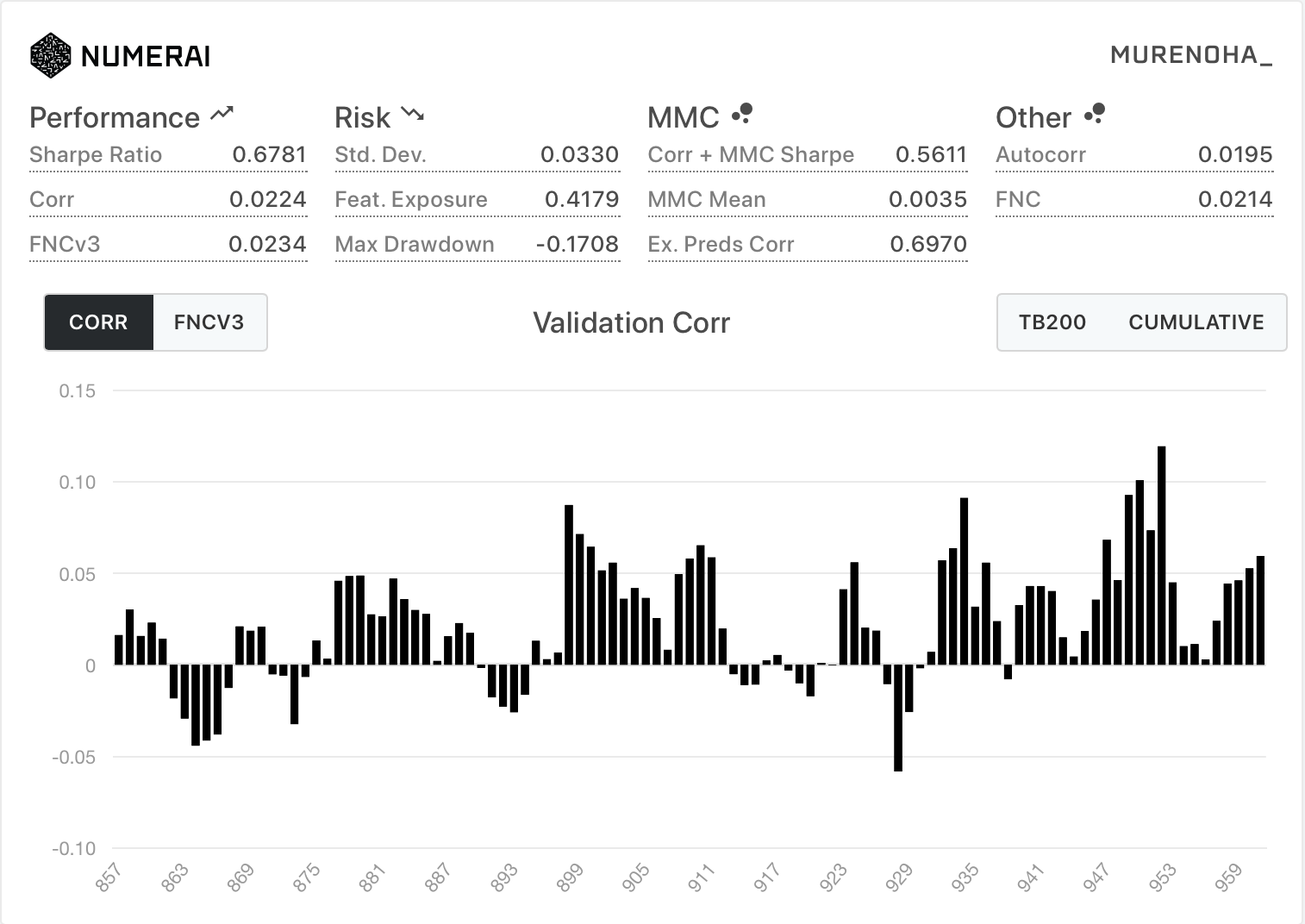 |
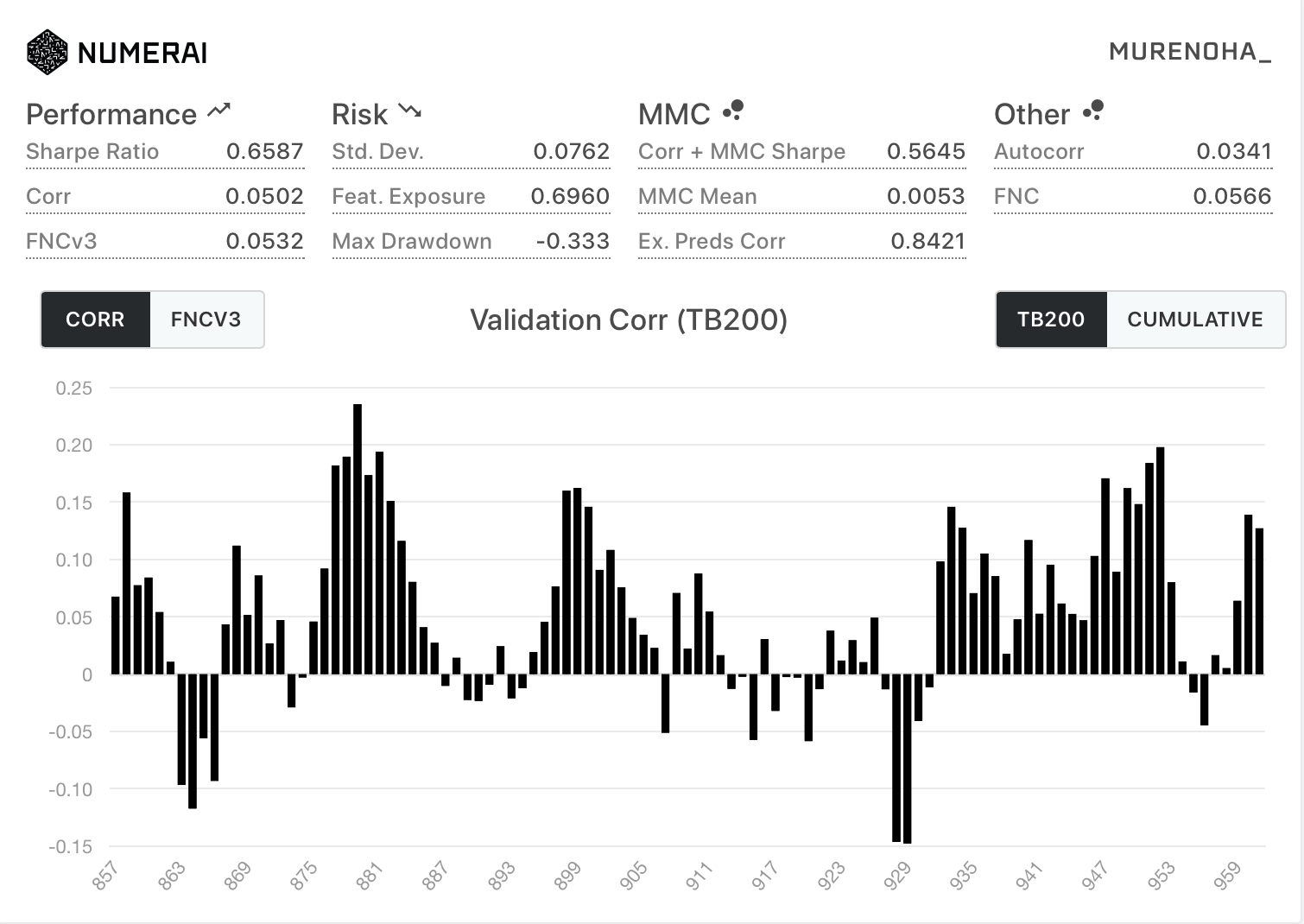 |
- モデル(R297からR331まで提出)
https://numer.ai/murenoha8
フルFN(新neutralize関数)
新データセットのutils.pyのneutralize関数を使用。proportion=1.0
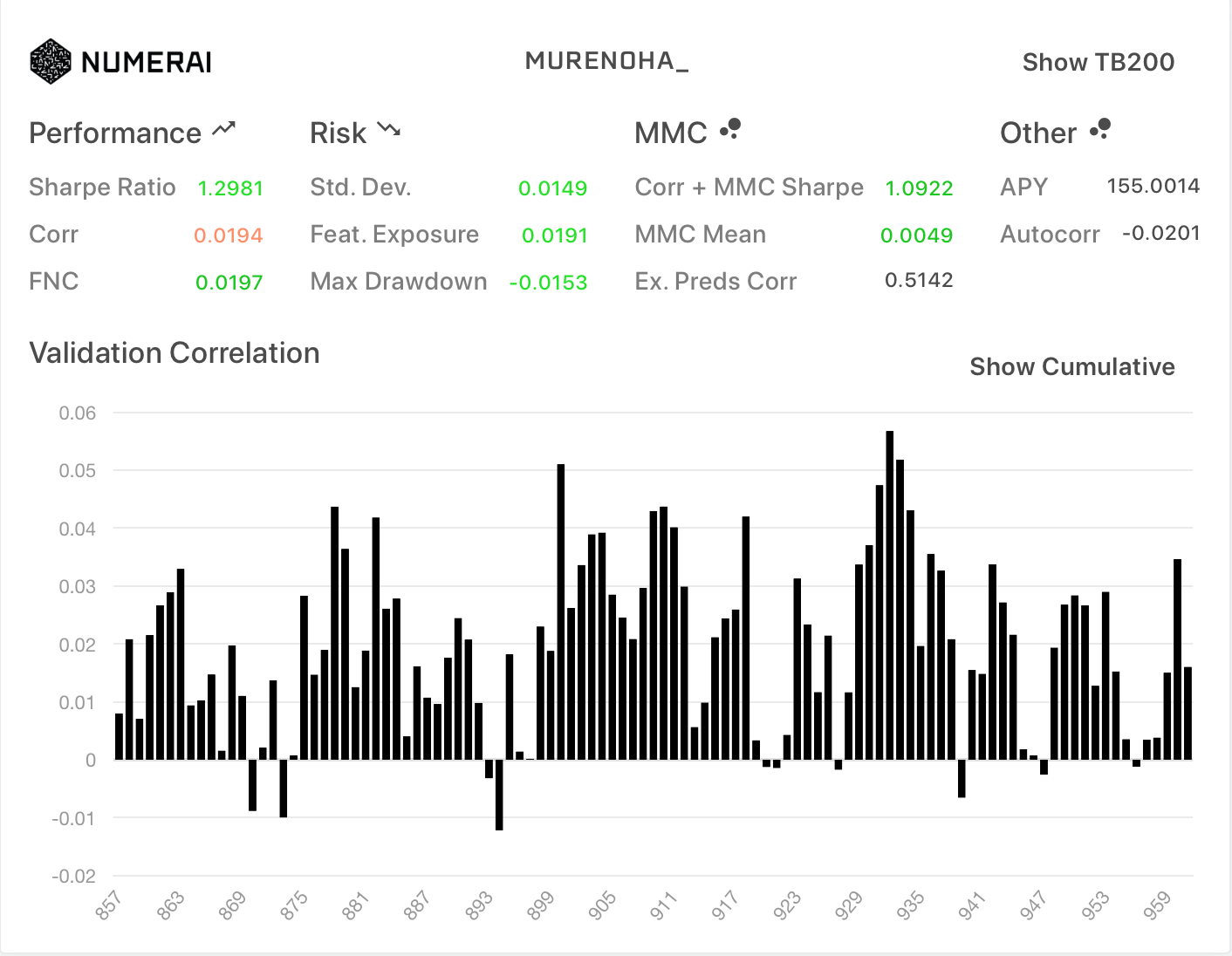
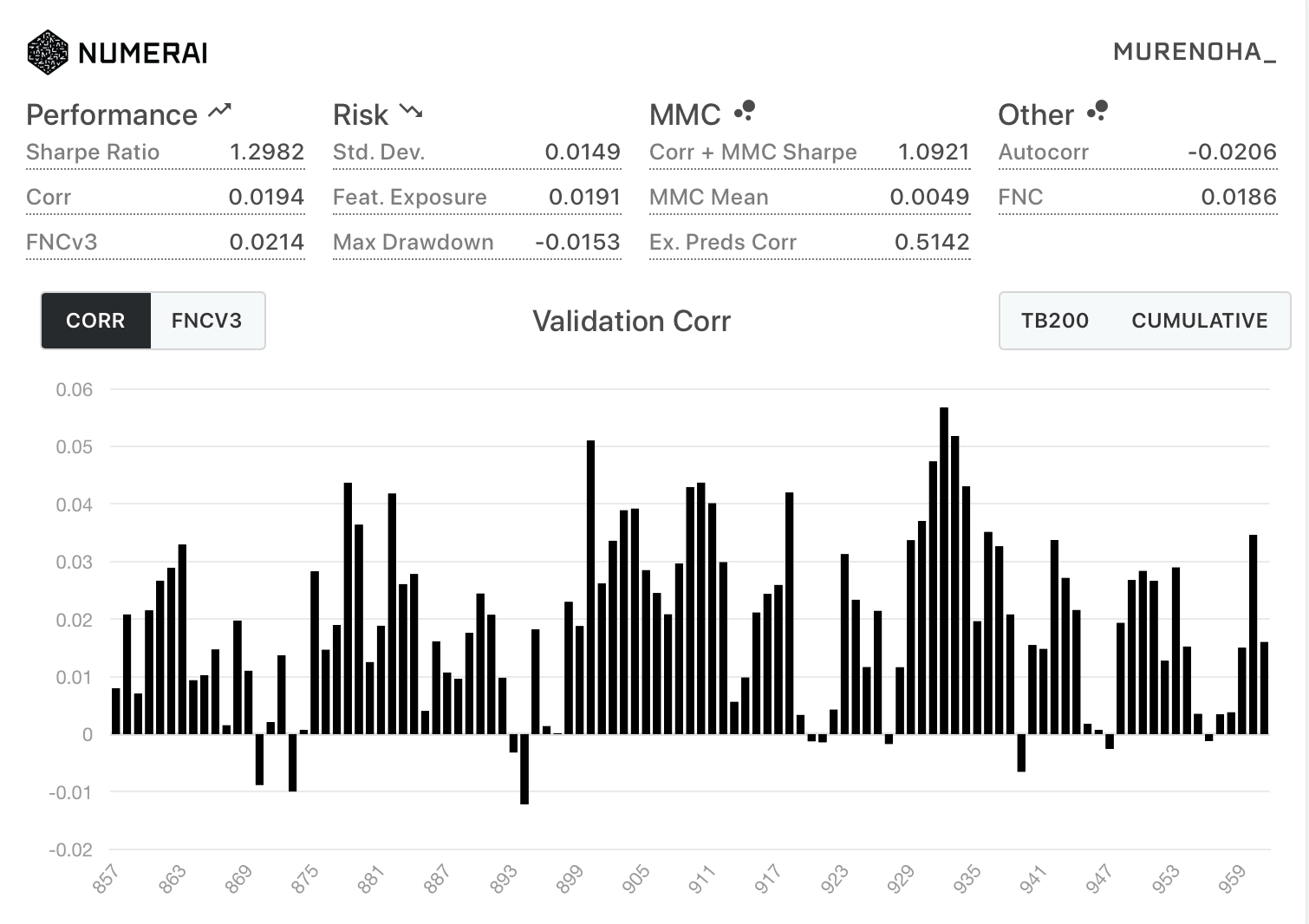
- Diagnostics
| All | TB200 |
|---|---|
 |
 |
この結果だけをみるとマイナスが少なくて安定してそうですが、最近のlive eraでどうだったのか気になります。
今後、提出して観察してみます。
フルFNのCorrは、ノーマルのFNCの0.0175になると思いましたが、 0.0194 で一致しませんでした。
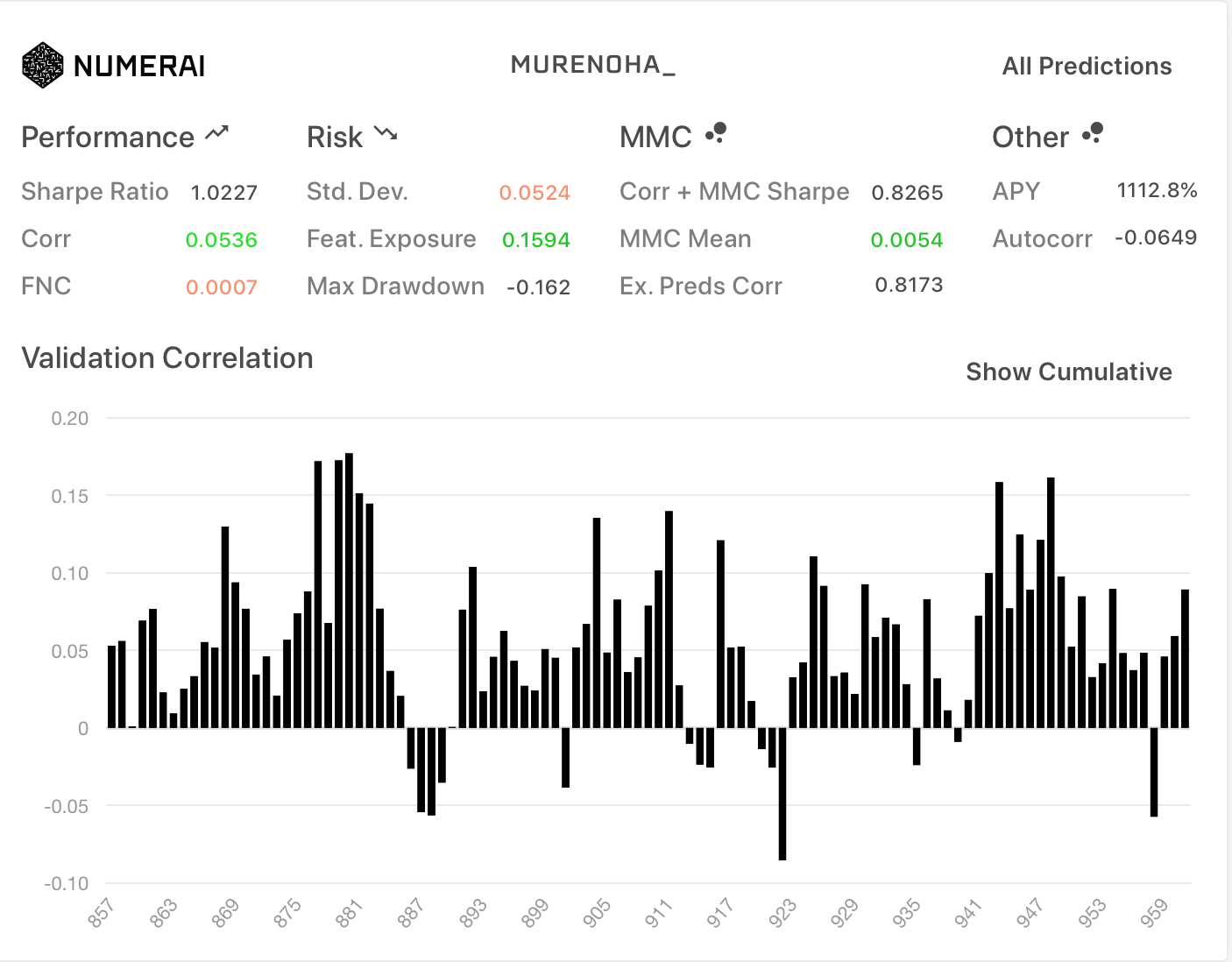
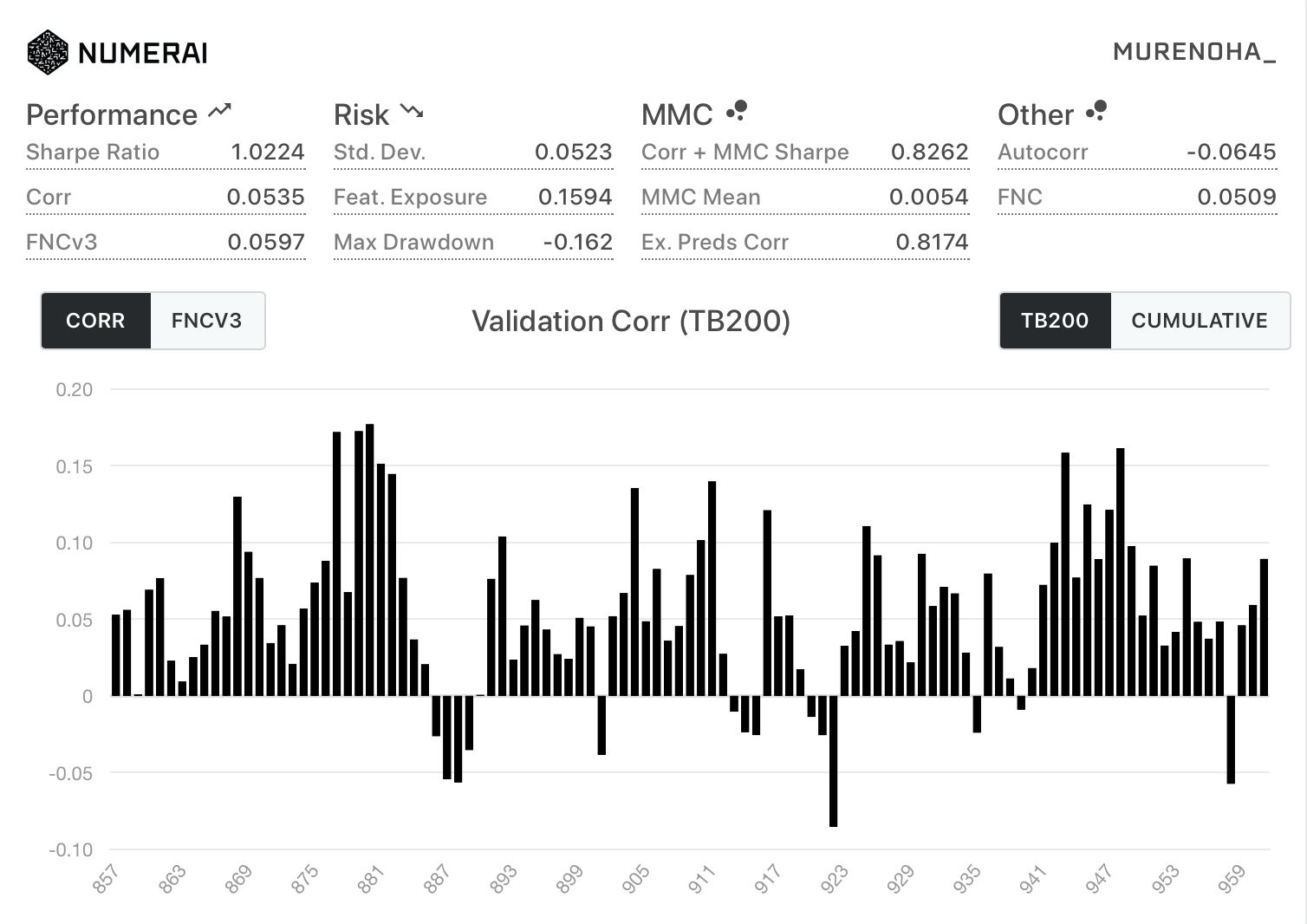
- 新Diagnostics
| All | TB200 |
|---|---|
 |
 |
- モデル(R298からR331まで提出)
https://numer.ai/murenoha9
フルFN(旧neutralize関数)
旧データセットのneutralize関数を使用。proportion=1.0
| All | TB200 |
|---|---|
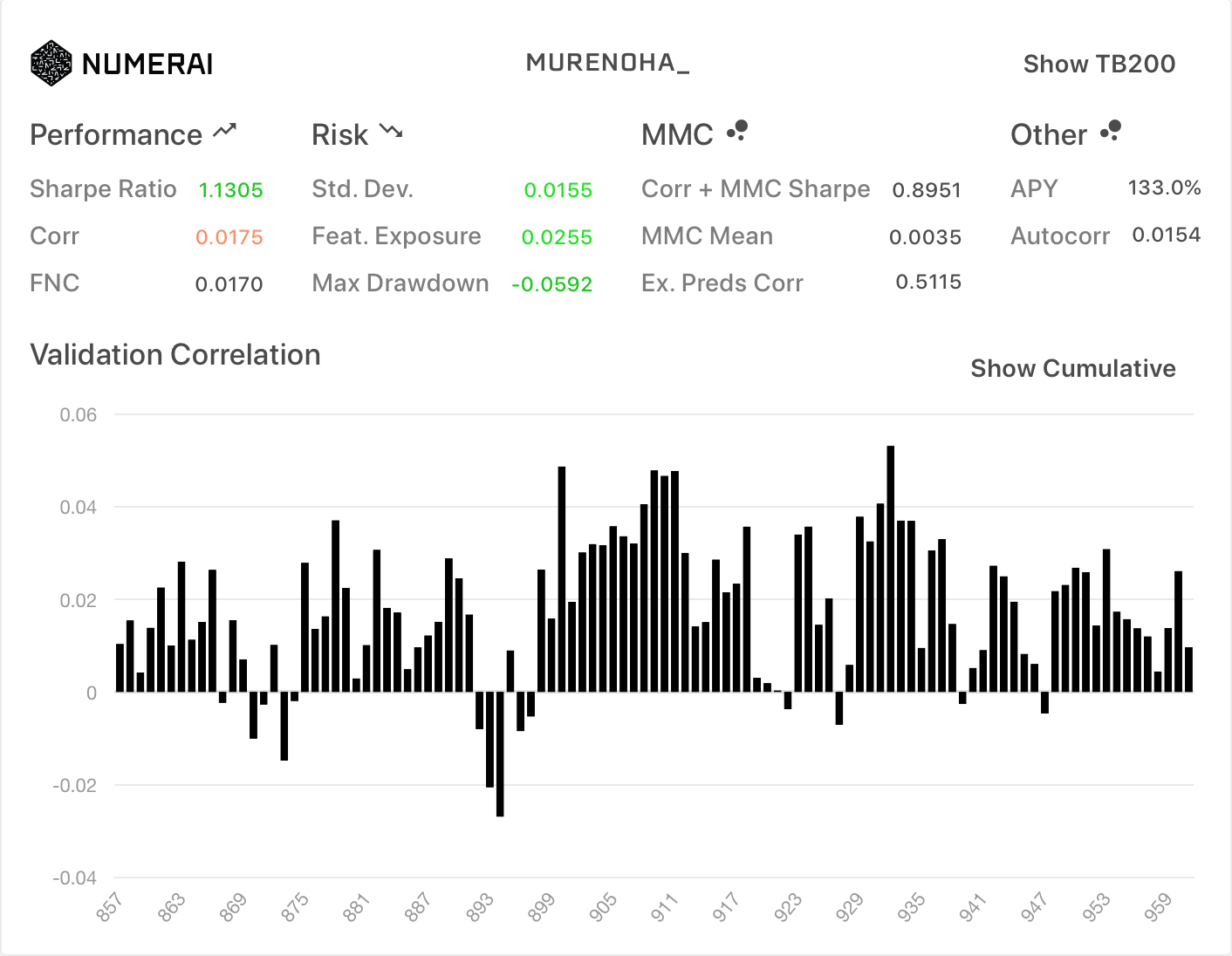 |
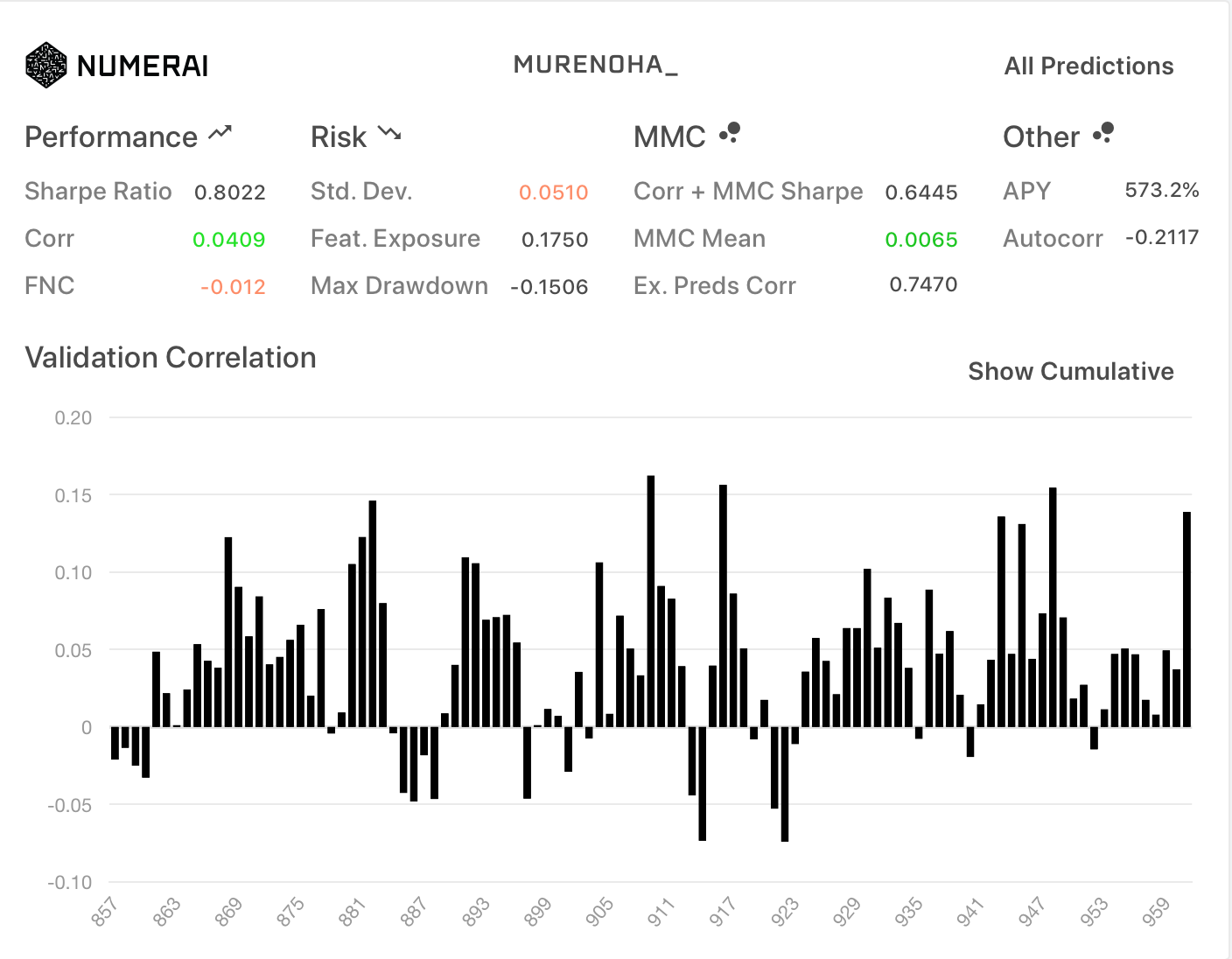 |
Corrが、ノーマルのFNCの0.0175と一致しました。
新診断は、旧データセットのneutralize関数が使用されているようです。
- モデル(R298から提出)
https://numer.ai/murenoha8
このモデルのFNCが該当
exampleモデルの結果
データセット分割との比較として、
新データセットに含まれている example_validation_predictions.csv です。
ノーマル
| All | TB200 |
|---|---|
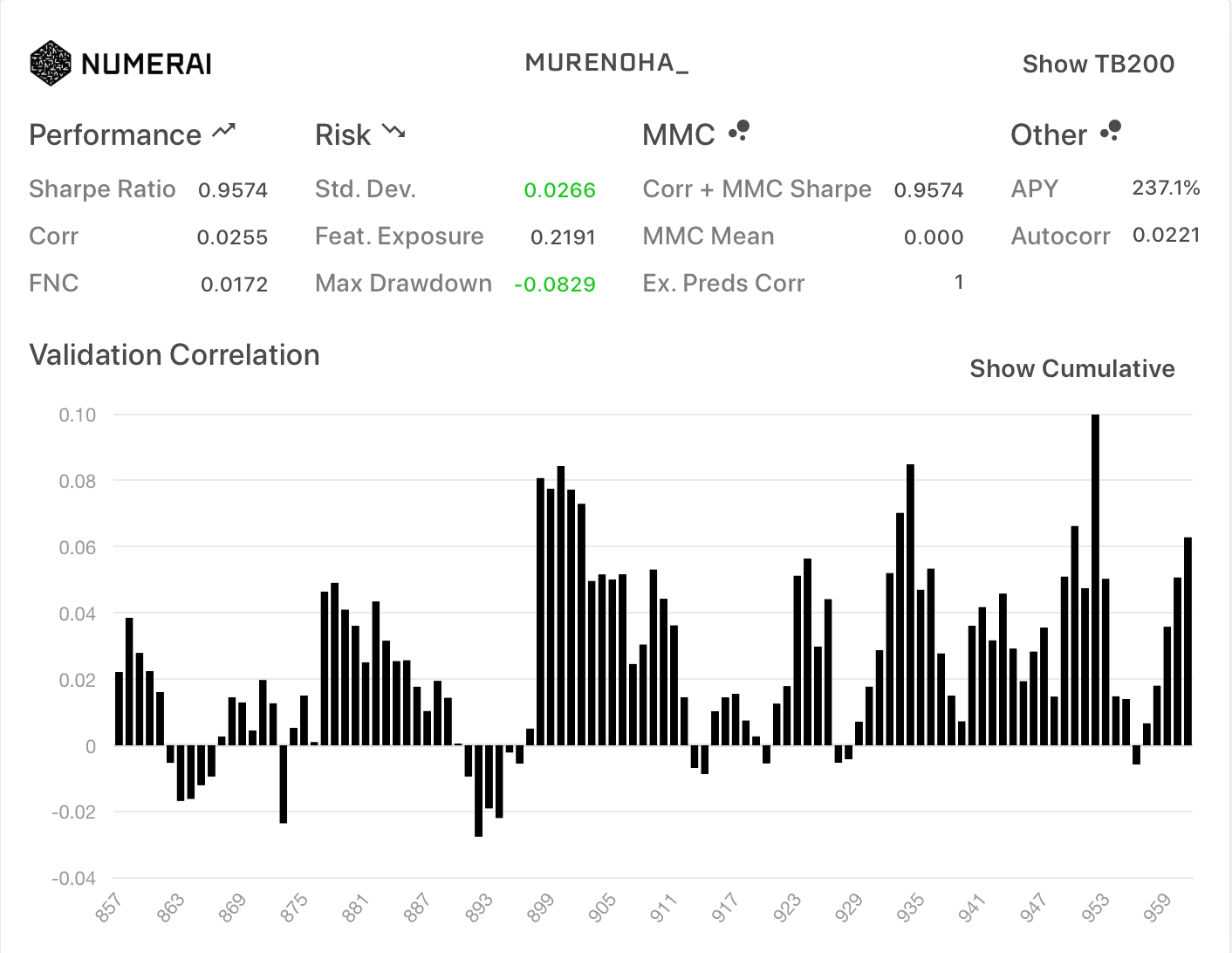 |
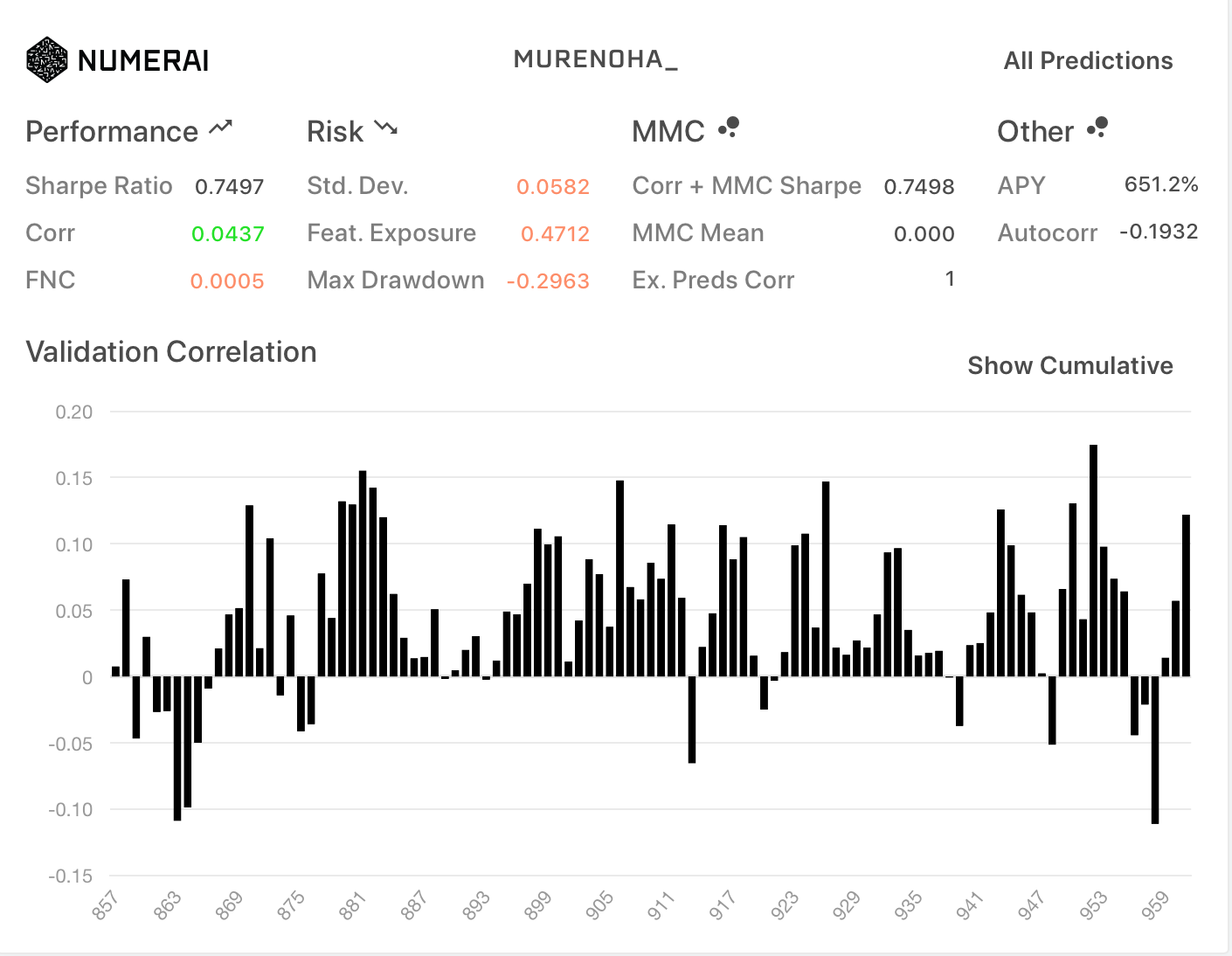 |
フルFN (新neutralize関数)
| All | TB200 |
|---|---|
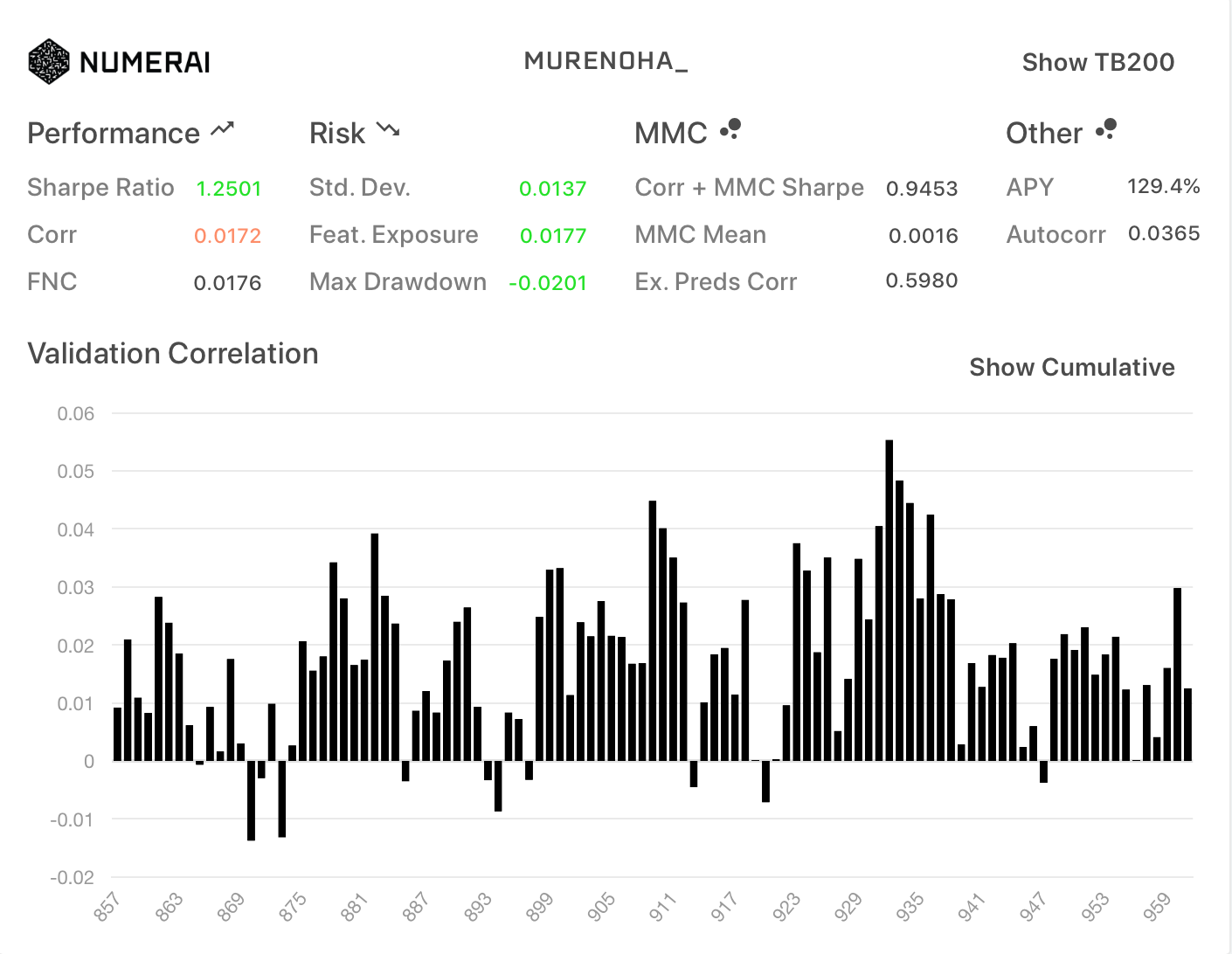 |
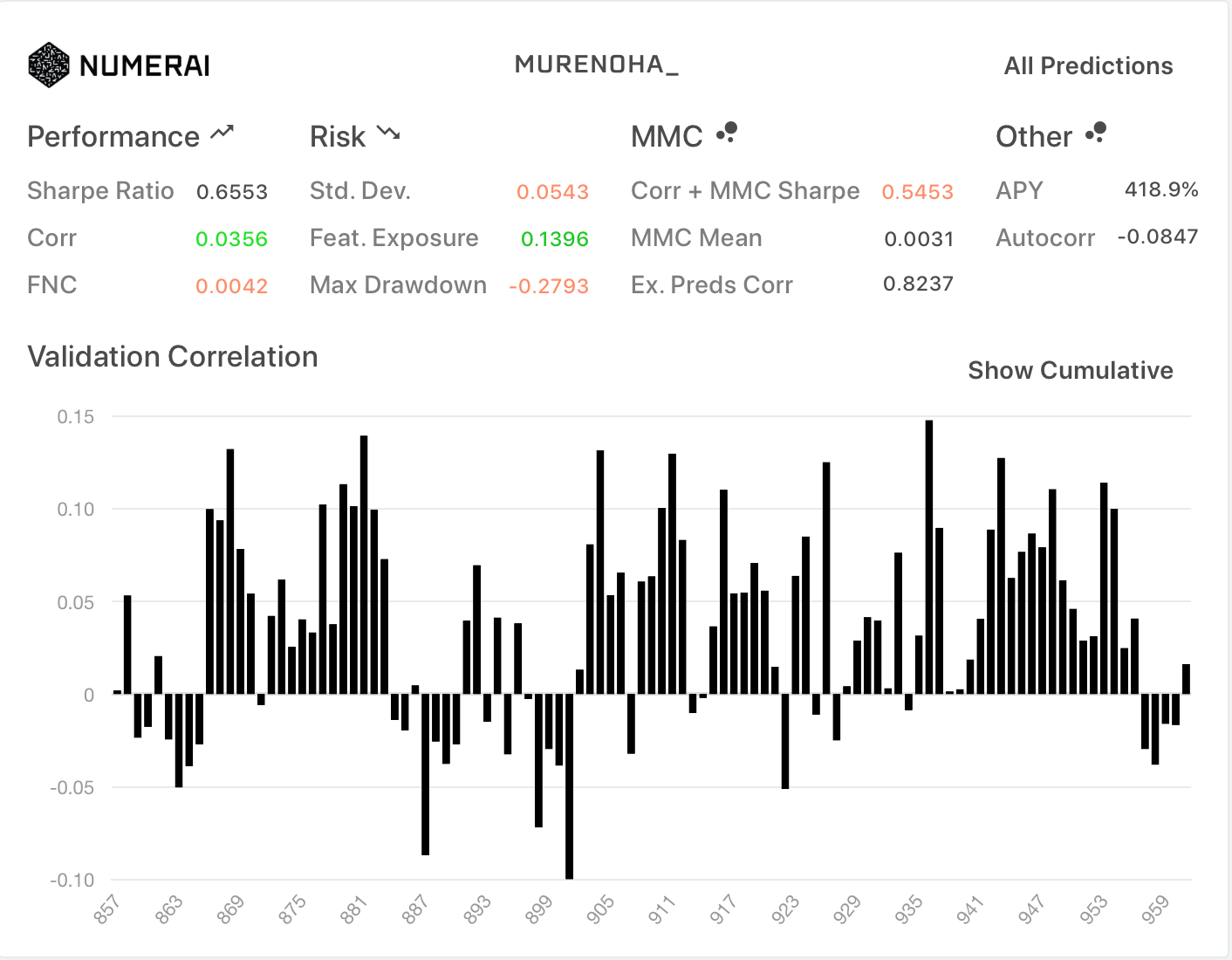 |
フルFN (旧neutralize関数)
| All | TB200 |
|---|---|
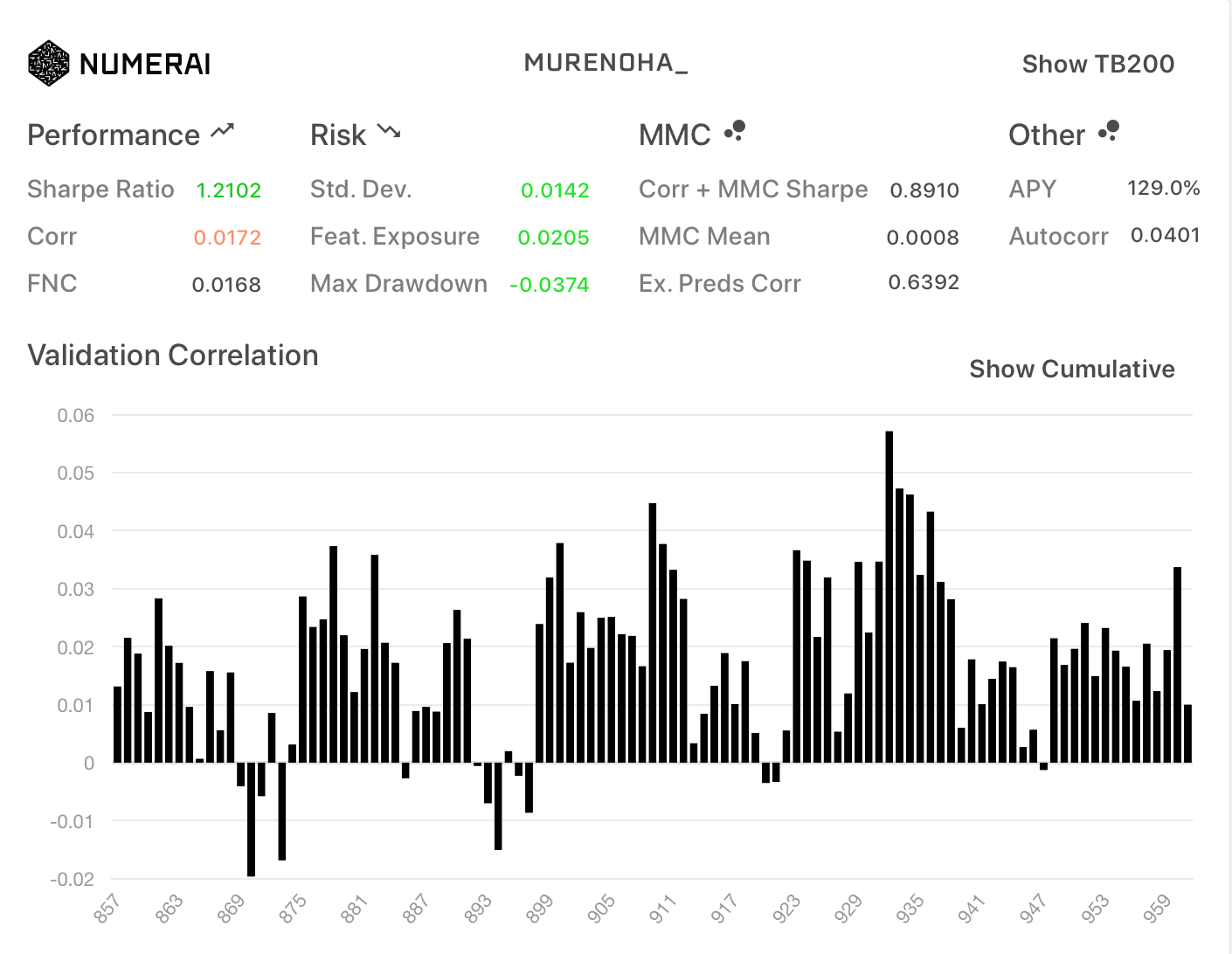 |
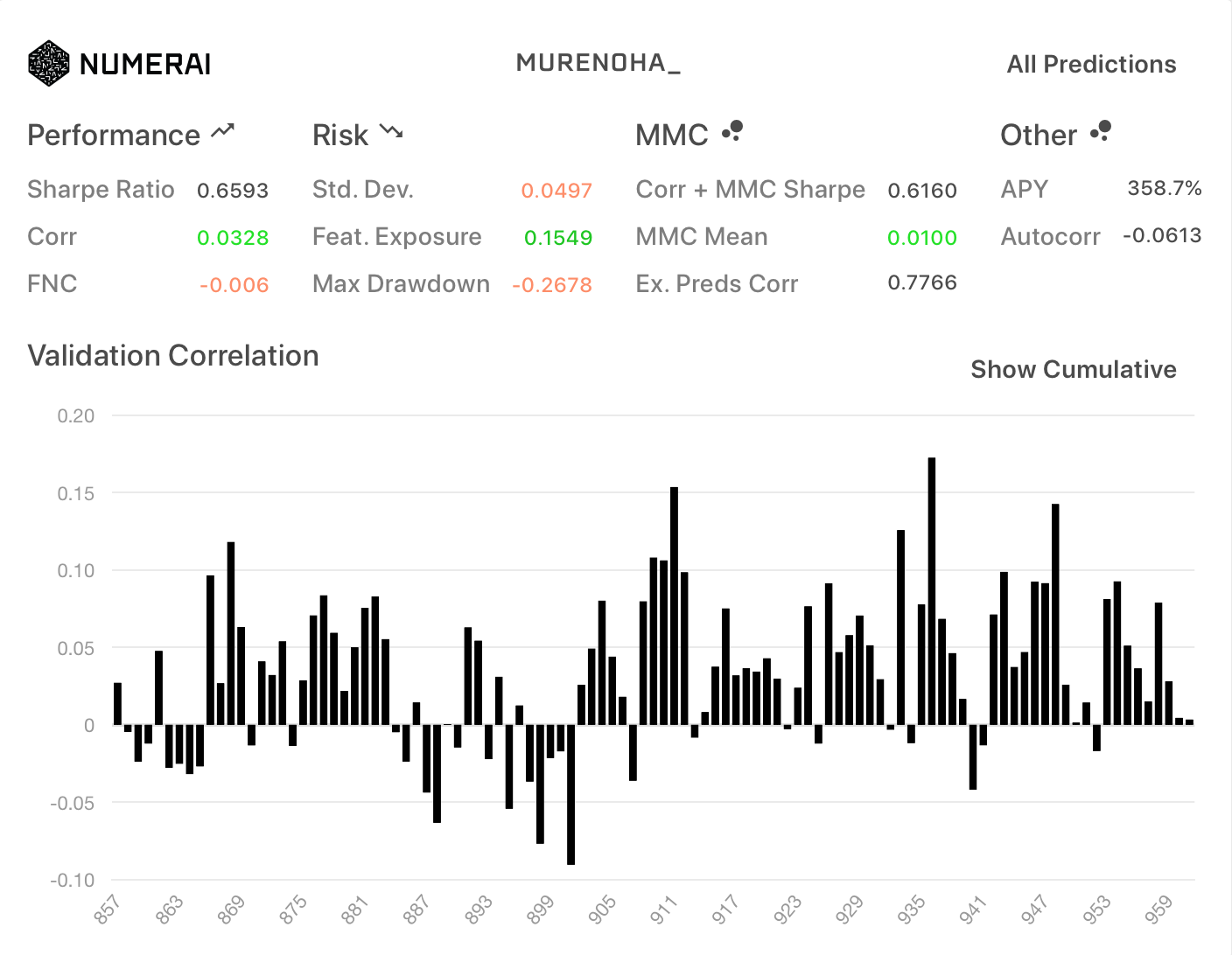 |
雑多なメモ
- 20個のモデルの最適な組み合わせを探す
- nomi以外の他の20dayターゲットで学習してアンサンブルする
- 60dayターゲットで学習してアンサンブルする
- riskiest featuresによる中和を導入する
- 新旧neutralize関数の違いを調査する
おわりに
ハイスペックマシンではなくても、データ分割してアンサンブルかつフルFNで高Sharpeを期待できそうです。
上記メモを試して進展ありましたら、共有したいと思います。
(特徴量が5つに分かれているのは、平日の5日間?)