自分は自己研鑽で受けもしないのに資格の勉強をするのですが、QC検定という品質保証の資格試験で統計学や機械学習が出ているらしいです。
そこで数量化理論Ⅳ類というものがあって質的変数のクラスタリングとありました。
というわけで、プログラム作って理解しようと思います。
階層型クラスタリング
import pandas as pd
import matplotlib.pyplot as plt
from scipy.cluster.hierarchy import dendrogram, linkage
df = pd.read_csv("golf.csv", encoding="shift-jis")
df = df.drop(["気温", "湿度"], axis=1)
df
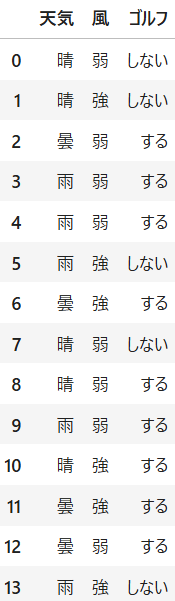
使用するのはゴルフデータです。少ないデータセットですがこれを使って理解しようと思います。
これから使用できるデータにしようと思います(駄洒落じゃないです)。
df = pd.get_dummies(df)
df = df.drop(["天気_雨", "風_弱", "ゴルフ_しない"], axis=1)
df = df.replace(True, 1)
df = df.replace(False, 0)
df
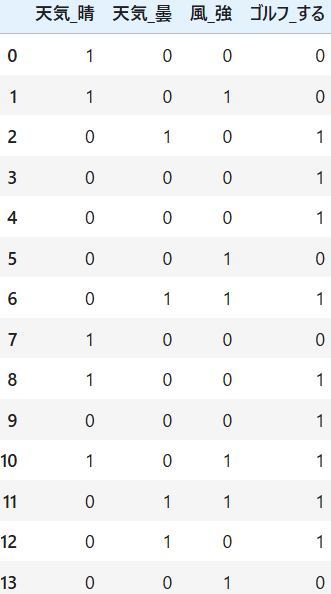
これで使用できるデータになりました。
ではここから予測してみようと思います。
Z = linkage(df, method="average", metric="euclidean")
dendrogram(Z)
plt.show()
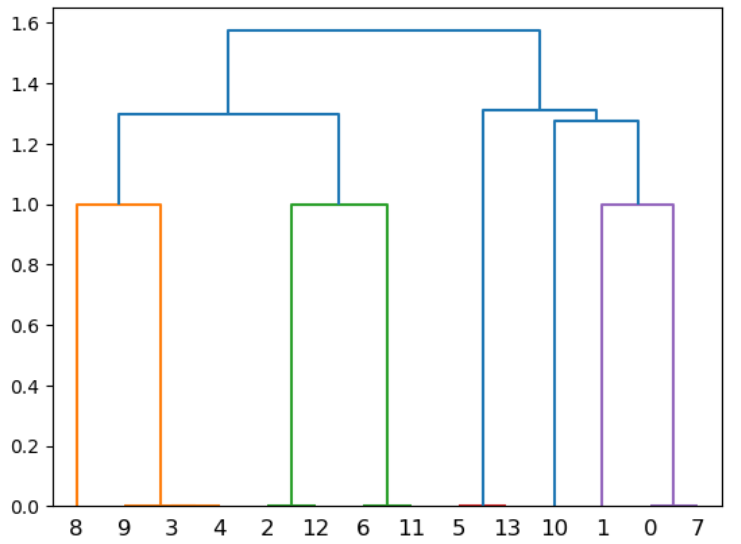
K-means法
だいたいクラスタは2つか3つであることが分かります。
では3つで考えてk-means法でクラスタリングをしてみましょう。
from sklearn.cluster import KMeans
model = KMeans(n_clusters=2)
model.fit(df)
y_pred = model.predict(df)
df_ctr2 = pd.DataFrame(model.cluster_centers_).T
df_ctr2.index = df.columns
df_ctr2
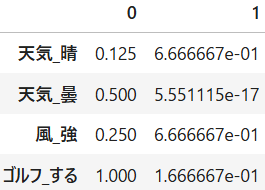
これがクラスタを2つにした時の重心になります。
from sklearn.cluster import KMeans
model = KMeans(n_clusters=3)
model.fit(df)
y_pred = model.predict(df)
df_ctr3 = pd.DataFrame(model.cluster_centers_).T
df_ctr3.index = df.columns
df_ctr3
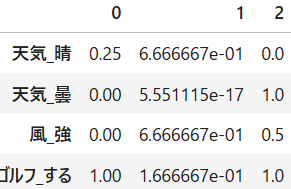
クラスタの0と2がきれいになったことが分かります。