まずはこちらを
第一種の過誤が起きる確率は帰無仮説の棄却である有意水準であることは簡単に分かります。
そもそも過誤は
第一種の過誤→帰無仮説が正しいのに帰無仮説を棄却する
第二種の過誤→帰無仮説が正しくないのに帰無仮説を採択する
これについて表にすると
| 帰無仮説を採択 | 帰無仮説を棄却 | |
| 帰無仮説が正しい | 正しく検定できた | 第一種の過誤 |
| 対立仮説が正しい | 第二種の過誤 | 正しく検定できた |
という状況です。
では第二種の過誤はどう考えるかですが、まず帰無仮説を棄却出来ていない事が前提になります。
その帰無仮説の中での対立仮説の分布の面積を求めると第二種の過誤が分かります。
つまり帰無仮説の棄却域ではない帰無仮説の範囲内での対立仮説の分布です。
図にするとこうなります(ペイントで描いたので雑なのは許して)。
赤線は有意水準で青が対立仮説の分布の面積です。
両側検定
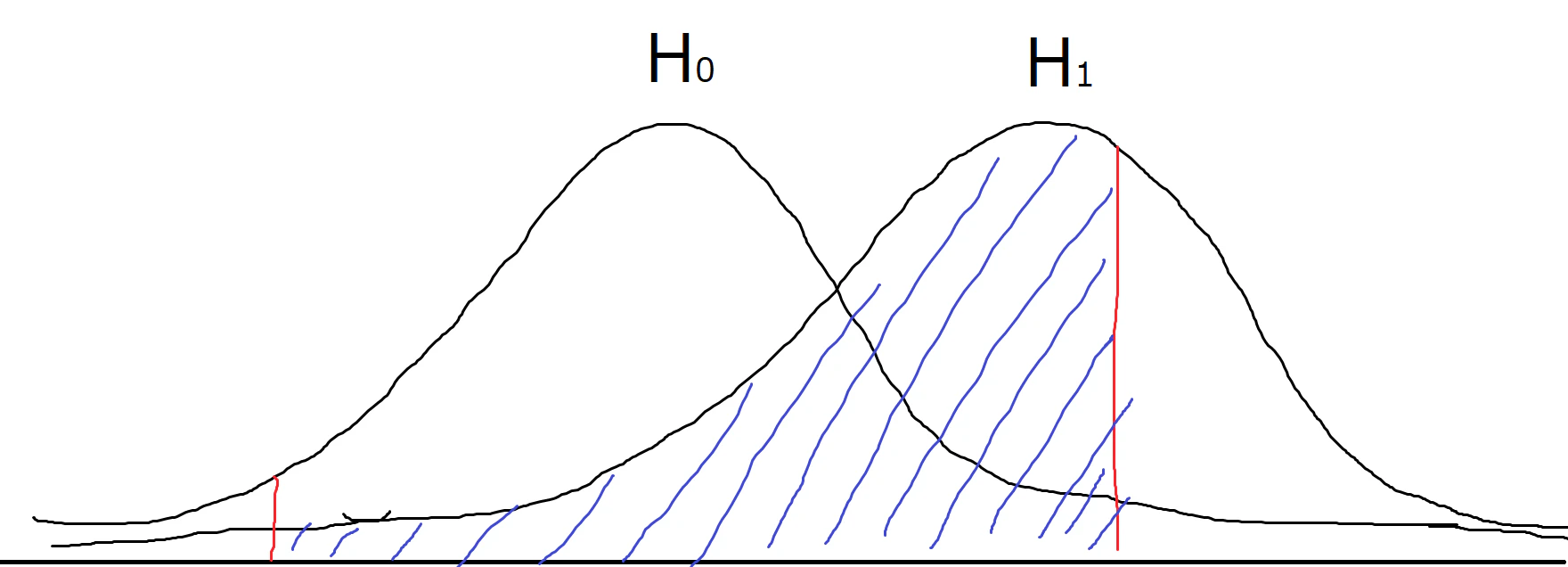
片側検定①

片側検定②
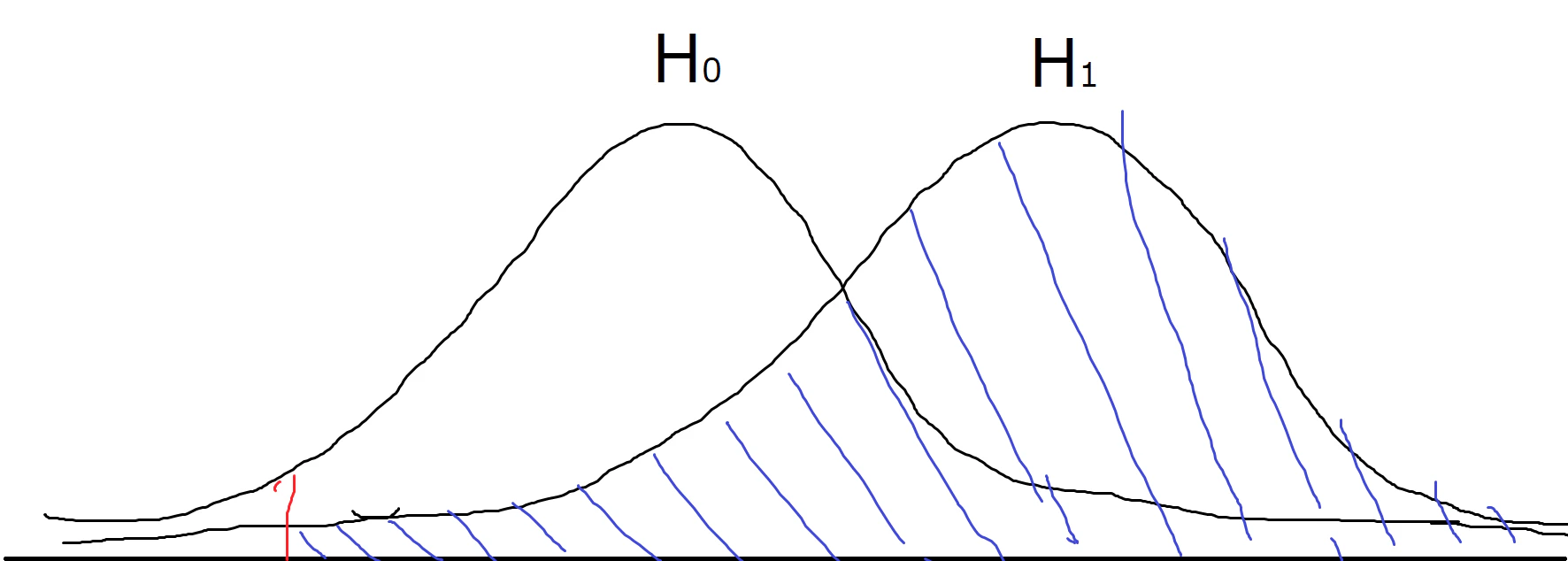
で面積を求めると第二種の過誤になります。
でこの第二種の過誤を1から引くと検出力になります。
よくある検査で罹患していない人を陽性と判断する時5%で、罹患している人を陰性と判断する確率がx%となることがありますが、この5%が第一種の過誤でx%が第二種の過誤になります。
なので帰無仮説をどうするかによって検出力が変わり罹患している人を正しく陽性と判断する確率が変動していて第一種の過誤と第二種の過誤はトレードオフであることが分かります。
図の場合はH1がH0より大きくなっていますが逆でも同じ考えで面積を求められます。
まとめ
第二種の過誤難しいよね計算。