機械学習というと「教師あり学習」「教師なし学習」(と「強化学習」)がフィーチャーされますが、その中でやり方が「教師なし学習」と似ている「異常検知」があります。
異常検知では正常値が1となり、異常値が-1という風にクラスタリングと似たようになります。
ではその中でIsolationForestという異常検知アルゴリズムを使って見ましょう。
分かりやすく賃金指数で
昔のデータで今は違う値になっていますが、分かりやすいデータとして賃金データを使います。
なぜ分かりやすいかというと、賃金データにはボーナス月は異常に高くなるという性質があります。それを考慮して見てみましょう。
from sklearn.ensemble import IsolationForest
from sklearn.decomposition import PCA
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv("sarrary.csv", encoding="shift-jis")
df.head()
x = df["賃金指数"]
model = IsolationForest()
model.fit(x.values.reshape(-1, 1))
y_pred = model.predict(x.values.reshape(-1, 1))
plt.scatter(df["年月"], df["賃金指数"], c=y_pred, cmap="brg")
plt.colorbar()
plt.show()
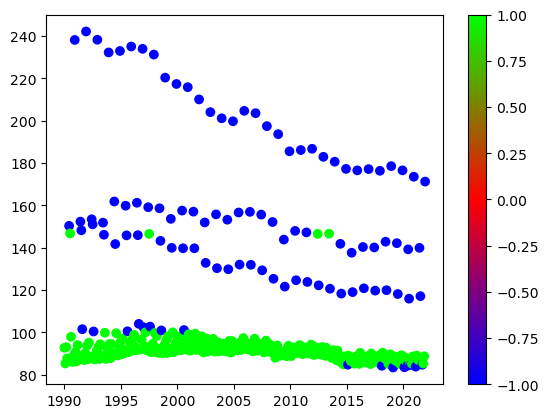
ボーナス月に一部正常データがありますが、おおむね異常値は当たっています。ただそれでも一部正常値にも異常値が混じっています。
アヤメデータでやってみる
さっきのプログラムの続きです。
df = pd.read_csv("iris.csv")
x = df.drop("category", axis=1)
model = IsolationForest()
model.fit(x)
y_pred = model.predict(x)
print(y_pred)
pca = PCA()
for col in x.columns:
x[col] = (x[col] - x[col].mean()) / x[col].std()
pca.fit(x)
tx = pca.transform(x)
plt.scatter(tx[:, 0], tx[:, 1], c=y_pred, cmap="brg")
plt.colorbar()
plt.show()
[ 1 1 1 1 1 1 1 1 -1 1 1 1 -1 -1 -1 -1 -1 1 -1 1 1 1 -1 -1
-1 1 1 1 1 1 1 1 -1 -1 1 1 1 1 1 1 1 -1 -1 -1 -1 1 1 1
1 1 1 1 1 1 1 1 1 -1 1 1 -1 1 -1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 -1 1 1
1 1 -1 1 -1 1 1 1 1 -1 -1 -1 -1 -1 1 1 1 1 -1 1 1 -1 -1 -1
1 1 -1 1 1 -1 1 1 1 -1 -1 -1 1 1 1 -1 -1 1 1 1 1 1 1 1
-1 1 1 1 1 1]
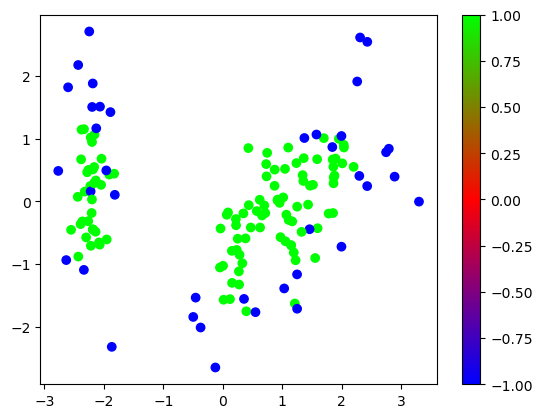
plt.scatter(tx[:, 0], tx[:, 1], c=df["category"], cmap="brg")
plt.colorbar()
plt.show()
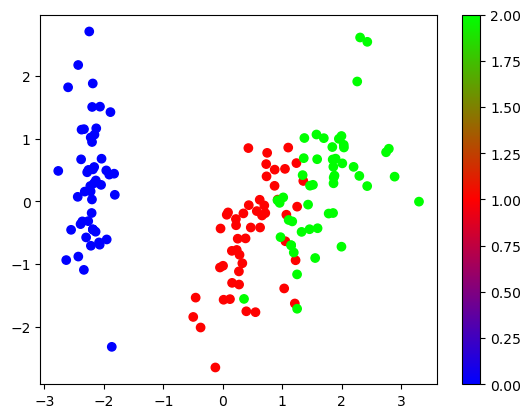
こうやってみると各クラスまたはクラスタの外れ値が異常値になっているような感じに見えますね。
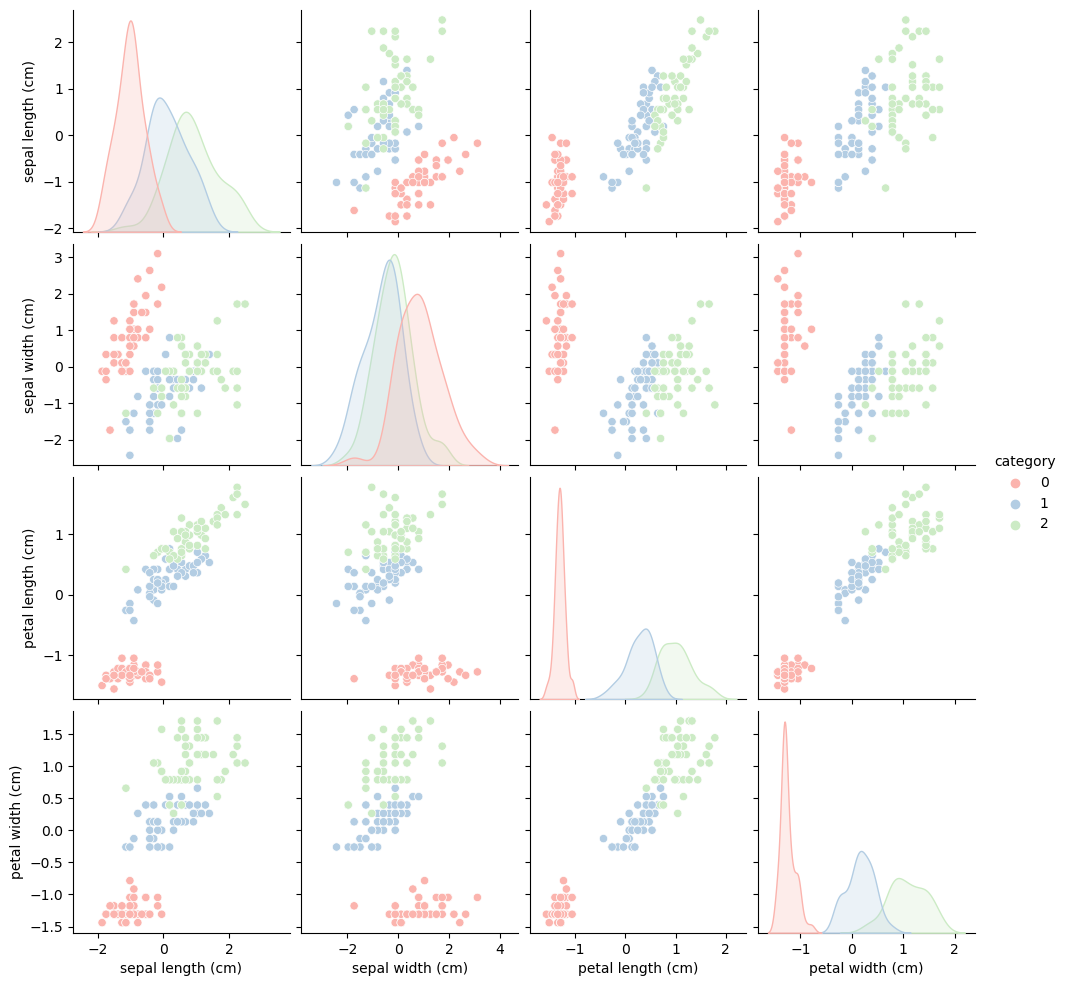
ちなみに各変数ごとにプロットするとこんな感じらしいです。
for col in x.columns:
df[col] = (df[col] - df[col].mean()) / df[col].std()
sns.pairplot(df, hue="category", palette="Pastel1")
plt.show()
これを異常検知の予測結果で散布図を見てみると
df_if = pd.DataFrame(y_pred)
df_if.columns = ["pred"]
df = pd.concat([df, df_if], axis=1)
sns.pairplot(df.drop("category", axis=1), hue="pred", palette="Pastel1")
plt.show()
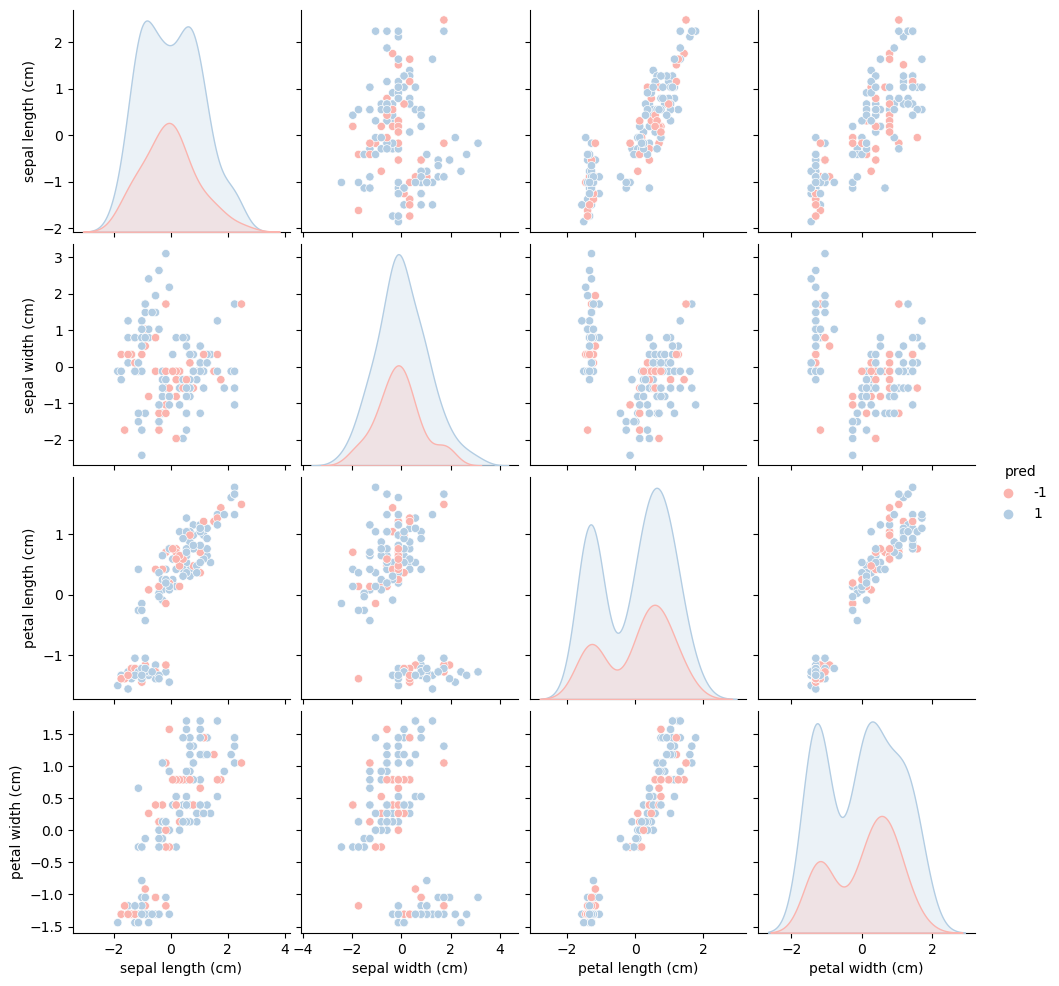
こんな形で異常検知をしているみたいです。
まとめ
色々使えそうです。