ヒストグラム以外で分かりやすく特徴量の分布を表してくれるものとしてカーネル密度関数というものがあるのですが、これを今回使って有効的な特徴量を探してみようと思います。
カーネル密度関数
for col in df_train.columns:
try:
sns.kdeplot(df_train[df_train["Survived"]==0][col], label="Survived = 0")
sns.kdeplot(df_train[df_train["Survived"]==1][col], label="Survived = 1")
plt.legend()
plt.show()
except:
_ = 0
ここで見つけた分布が異なる特徴量がこれでした。

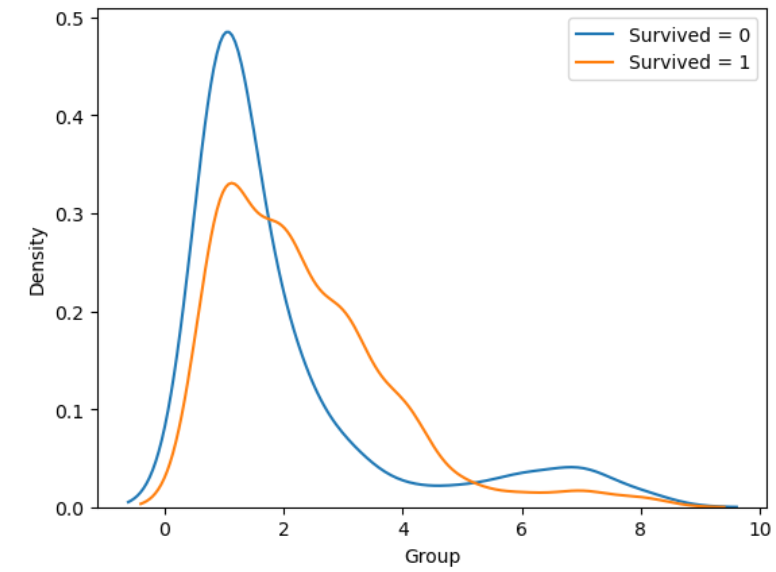


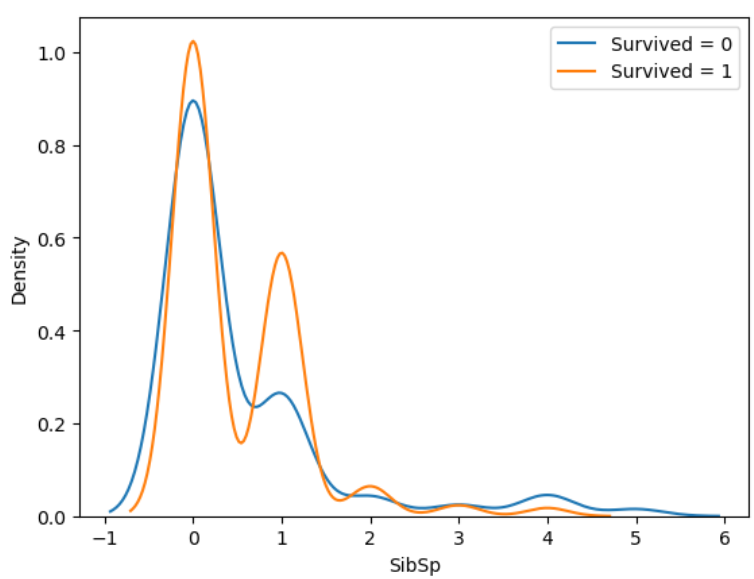

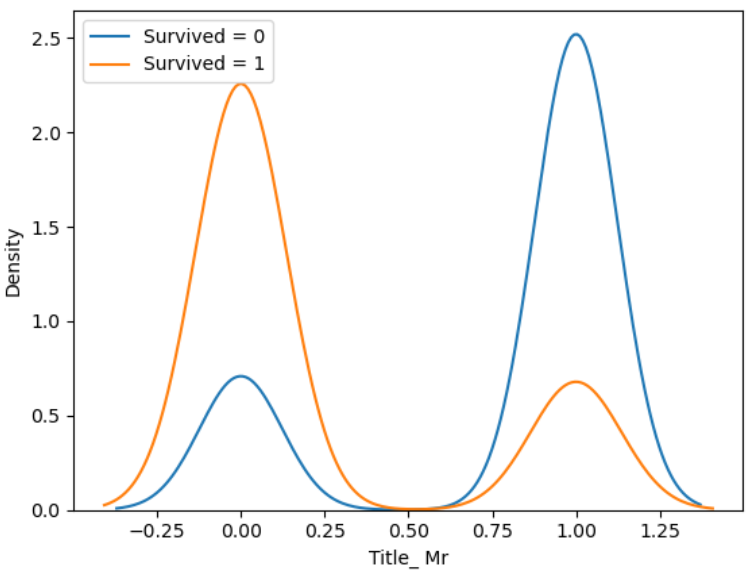

と、ここから変数選択してなんやかんや77.272%となりました。
予測手法はhold-outを200回訓練データと検証用データを変えて学習させ上位3位のモデルを使って多数決で予測するという手法です。