※Qiita初心者でこれが初投稿なので温かく見守ってください
使用するのはJupyter Notebookです。
やる内容としては該当する質的変数が評価する項目にどのような影響を与えているかになります。
手順
ライブラリの読み込み
必要なのは「Pandas」と「matplotlib」になります。
import pandas as pd
import matplotlib.pyplot as plt
基本的にはExcelでデータは見れますが一応データの冒頭を出力します。
今回はCox比例ハザードモデルのライブラリであるlifelineというライブラリにある白血病のデータをCSVにしたものを読み込みます。
df = pd.read_csv("leukemia.csv")
df.head()
質的変数と評価する変数の名前を定義
次にどの変数を用いて評価・効果検証をするかを決めます。
columns = ["status", "sex", "Rx"]
y_name = "logWBC"
このとき。「columns」には質的変数を入れてください、また「y_name」には評価する変数の名前を入れてください。
補足ですが、
- Rx→投与(原因)
- status→効果(結果)
- sex→性別
- logWBC→白血球の数のlog
になります
効果検証のプログラム
ここからは効果検証を可視化する前準備を行います。
前項と前々項で使用するデータと変数を記載していますが、使用するデータセットと変数名を変えれば他のデータにも応用できます。
ave = []
pos = []
dtr = []
lab = []
x = 0
for col in columns:
values = list(set(df[col].values))
tmp_ave = []
tmp_pos = []
tmp_dtr = []
tmp_lab = []
for val in values:
tmp_df = df[df[col]==val]
tmp_ave.append(tmp_df[y_name].mean())
tmp_pos.append(x)
tmp_dtr.append(tmp_df[y_name])
tmp_lab.append(col+"_"+str(val))
x = x + 1
ave.append(tmp_ave)
pos.append(tmp_pos)
dtr.append(tmp_dtr)
lab.append(tmp_lab)
ここで「tmp_lab」の追加について、質的変数には文字列を使っている場合や名義尺度(数値そのものに意味が無いカテゴリとしての数値)を使う場合があるため汎用的にするために「tmp_lab.append(col+"_"+str(val))」としています。
効果検証を出力
では実際に検証結果を出力してみましょう。
やり方としては質的変数の項目ごとに各リストに値(とデータフレーム)が入っていますのでfor文で長さを指定する時にこのように指定します。
また、平均値が例えはT検定などで有意に差があるかを比較する際に使いますのでマーカーを付けて出力しましょう。
for i in range(len(ave)):
plt.boxplot(dtr[i], positions=pos[i], labels=lab[i])
plt.plot(pos[i], ave[i], marker="x")
plt.show()
この結果以下のようになります。
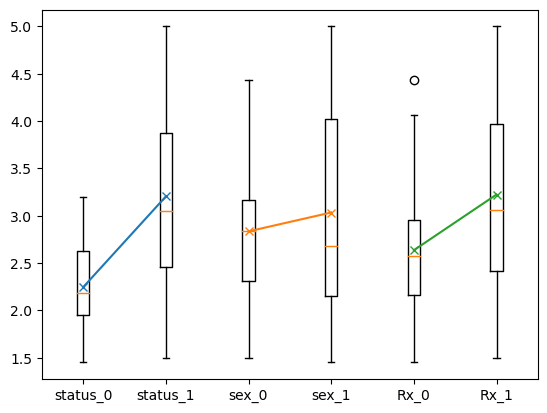
ここからあとは各種変数について時間的関係から原因なのか結果なのかを考察して原因なら「○○が原因として見たときこういう効果に違いがあるのか」「結果○○な場合こういう違いがあるのか」などが可視化でき考察の材料になります。
なのでこの場合投与すると白血球数が上がる、男女での差は少ないということが分かります。また、結果白血病の人は白血球数が多いということが分かります。
ただし気を付けてほしいのがこの場合は一つの因子に対して分析しているだけで、複数の変数についてはまた違った分析手法を使います。
それと報告書や論文でこういったものを書くときはグラフを使うのも大事ですが、平均値の差やp値とサンプル数(できれば標準偏差も)など記載した方がより丁寧になると思います。