先日Kaggleでタイタニック以外にテーブルデータのコンペは無いものかと思って探してメダルを取りたいと思っていたのですが(のちにメダルの無いコンペと発覚)、面白いコンペがありました。

多分血糖値を予想するのかなと思ったんですが、このコンペ、癖が強い。
テーブル
訓練データ
まず訓練データとテストデータで変数が合っているのかわからない
import pandas as pd
train = pd.read_csv("train.csv")
train
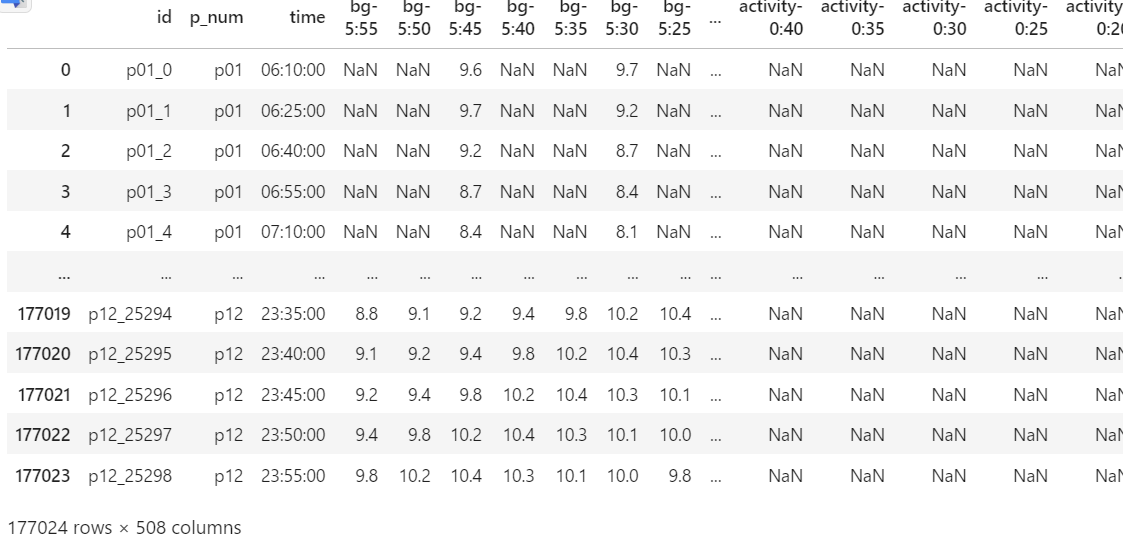
NaNが多すぎる。
テストデータ
test = pd.read_csv("test.csv")
test

変数を合わせる
念のため変数を合わせました。
columns = []
for col in train.columns:
if col in test.columns:
columns.append(col)
train = train[columns]
for col in x_test.columns:
if col not in x_train.columns:
x_test = x_test.drop(col, axis=1)
欠損値の補完
このデータはあまりにも欠損が多くしかも数値なので埋めようがありません。そのため欠損値を欠損値として使います。
LightGBMを使うことを前提にします。
train = train.fillna(-9999)
test = test.fillna(-9999)
基本的に各変数は0以上なのでこれで問題ないでしょう。
IDを作る
train.index = train["id"]
train = train.drop("id", axis=1)
train
ページを変数に
train["p_num"] = train["p_num"].map(lambda x:x.split("p")[1])
train["p_num"] = train["p_num"].astype("float")
train

ページがfloatになりました。同じことをテストデータでもやります。
時間を変数に
時間にも特徴量があると仮定して時間を特徴量化しました。
train["time"] = pd.to_datetime(train["time"])
train["H"] = train["time"].dt.hour
train["M"] = train["time"].dt.minute
train["S"] = train["time"].dt.second
train = train.drop("time", axis=1)
train
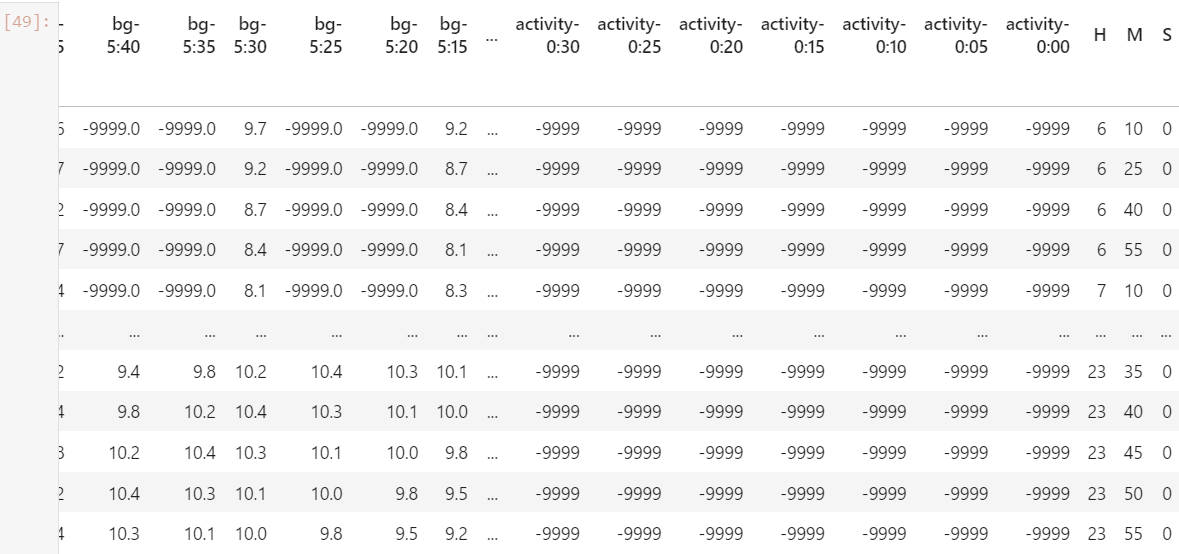
これで時間を特徴量にすることができました。テストデータにも同様の処理をしました。
目的変数(訓練データ)を結合
変数合わせで目的変数がなくなってしまったので結合します。
df_train = pd.read_csv("train.csv")
df_train.index = df_train["id"]
df_train = df_train.drop("id", axis=1)
train2 = pd.concat([df_train["bg+1:00"], train], axis=1)
これで結合ができました。
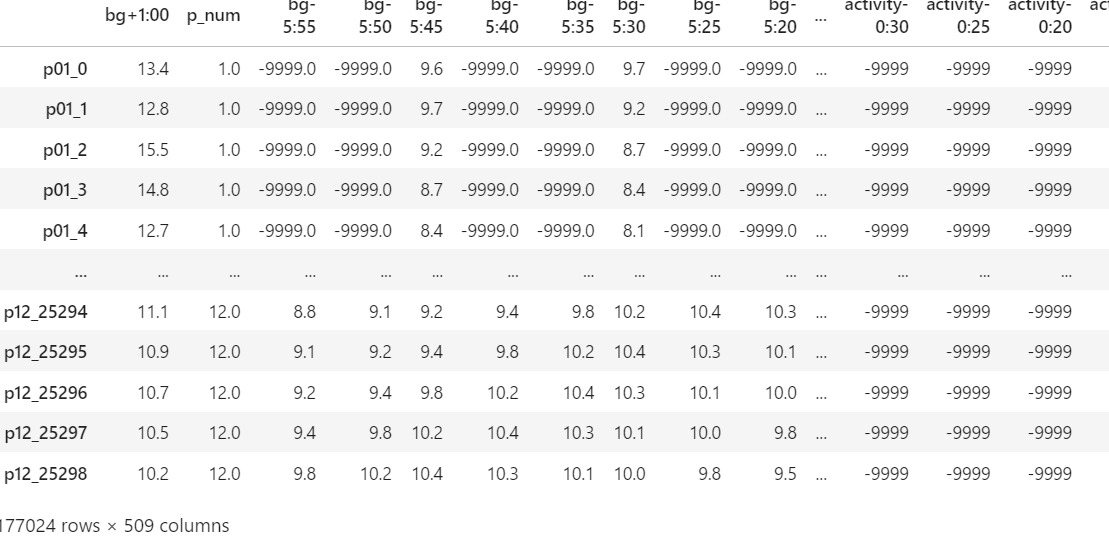
学習
ではここからようやくデータを学習させましょう。
from lightgbm import LGBMRegressor as LGBMR
x_train = train2.drop("bg+1:00", axis=1)
y_train = train2["bg+1:00"]
x_test = test
このデータ、よく見ると質的変数があるためダミー変数化します。
x_train = pd.get_dummies(x_train)
x_test = pd.get_dummies(x_test)
次に変数の順番を念のため合わせます。
x_train = x_train.sort_index(axis=1)
x_test = x_test.sort_index(axis=1)
そしてこのまま学習させるとエラーを起こしたので時間変数(だと思う)に変数をいじりました。
import re
x_train = x_train.rename(columns = lambda x:re.sub('[^A-Za-z0-9_]+', '', x))
x_test = x_test.rename(columns = lambda x:re.sub('[^A-Za-z0-9_]+', '', x))
いよいよようやく学習です
model = LGBMR()
model.fit(x_train, y_train)
y_pred = model.predict(x_test)
提出用データを作ります。
pred = pd.DataFrame(y_pred)
pred.index = x_test.index
pred.columns = ["bg+1:00"]
pred.sort_index().to_csv("submit_1.csv")
精度と順位
精度の測定はRMSEだそうてす。

ついで順位を確認します。
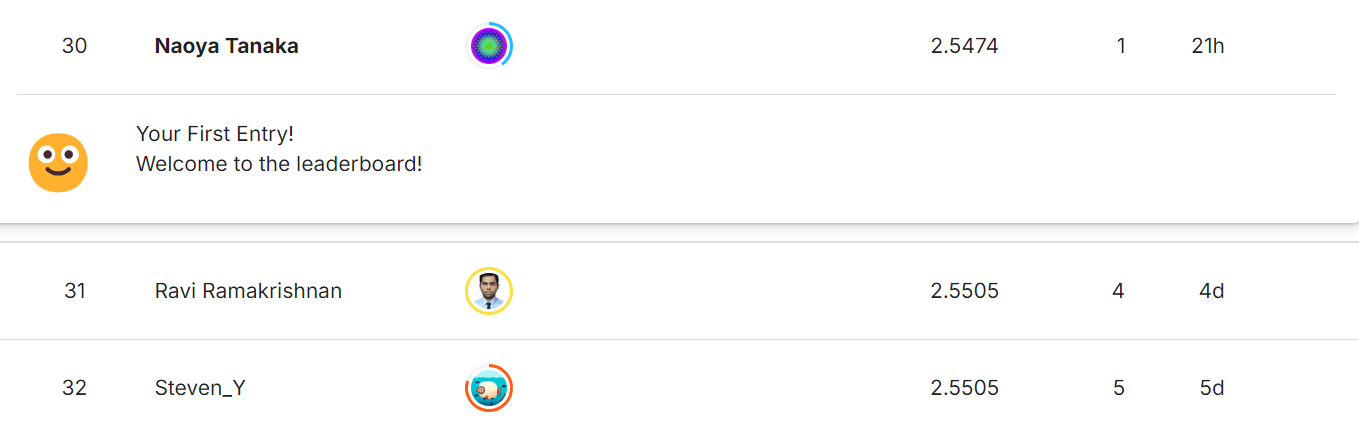
なんと自分の下にMasterとGrandMasterがいました。
10月2日時点では101人中30位とまずまずな結果になりました。データサイエンス初心者にしては中々いい結果なのではないでしょうか。