はじめに
MetapsAdventCalendar2023 14日目の記事です🏃♂️
文字コード初心者が文字コードについて調べた記事になります。
(※主にShift_JIS,Windows-31J,UTF-8を少々)
前半は、「文字コードとはなんぞや」から始まり、気になる用語を調べてまとめてみました。
後半は、Shift_JIS, Windows-31J, UTF-8の符号をPHPで出す方法と、
SJIS, Windows-31J, UTF-8の符号を出して、SJIS系なら2バイト文字をPHPで大雑把に分類してみるということをやってみました。本記事で利用したプログラムのGithubのリンクも記載しています。
環境
・PHP: 8.1.25
・macOS: Sonoma 14.1.1
・iTerm2: Build 3.4.22
文字コードを理解する上で役立った動画
下記動画は、なぜ「Unicodeが誕生したのか」及び、「Shift_JISでなぜ符号化する必要があったのか」をわかりやすく説明してくれています。この記事で紹介できていないASCII, JIS X 0201, JIS X 0208, Unicode, ISO-2022-JP(JISコード), EUC-JPの解説もされておりました。
文字コードとは
文字コードとは、符号化文字集合と文字符号化方式の両者を指し示しています。
その為、後述するJIS X 0208, Unicodeといった文字集合も文字コードと言えますし、Shift_JIS, Windows-31J, UTF-8といった文字符号化方式も文字コードと言えます。
符号化文字集合とは何かというと、特定の文字を、組み合わせの中で一意になる番号と1対1で対応づけた組み合わせの表になります。例えば、JIS X 0208という符号化文字集合では、「お」という文字は「4区10点」という一意になる番号(区点番号)をもっており、他の文字も一意となる番号を持っています。
一方で、文字符号化方式とは、特定の符号化文字集合に対して、特定のルールに基づいて計算や変形を行い、別の符号で文字を表現する方法のことを指します。例えば、JIS X 0208という符号化文字集合に対して、Shift_JISという文字符号化方式を利用した場合、「お」という文字は、JIS X 0208上で「4区10点」という区点番号を持ちますが、Shift_JISのルールに従い「0x82A8」という符号に変形されてコンピューターに利用されます。
また、文字符号化方式にはUTF-8というものも存在します。「UTF-8」という文字符号化方式は、世界中の文字を収録した「Unicode」という符号化文字集合を利用します。例えば、「お」という文字は、「Unicode」という符号化文字集合の中で「U+304A」という一意に特定できる符号位置(コードポイント)を持っています。「U+304A」は、「UTF-8」という文字符号化方式により、「0xe3818a」という符号に変形されてコンピューター(プログラム)から利用されます。
実際に区点番号やコードポイント、符号を確認してみましょう
・下記サービスで「お」という文字のUTF-8上の符号と、Unicode上の符号位置(コードポイント)を確認してみます。下記スクリーンショットのコード値の右側に出ている「e3 81 8a」がUTF-8上の符号で、Unicodeの右側に出ている「U+304A」がUnicode上の符号位置(コードポイント)です。
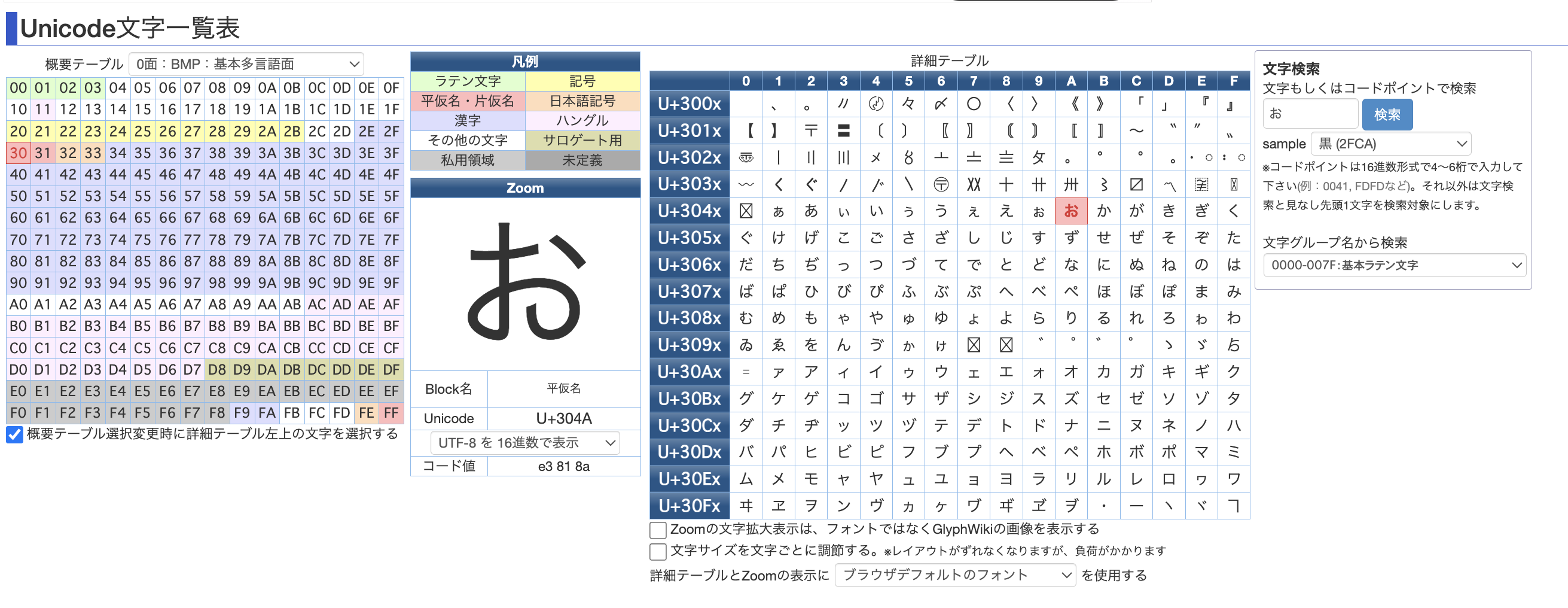
・下記サービスで「お」という文字のShift_JIS上の符号と、JIS X 0208上の区点番号を確認してみます。

同じくShift_JISの表があるみたいなので、そちらでも確認してみます。
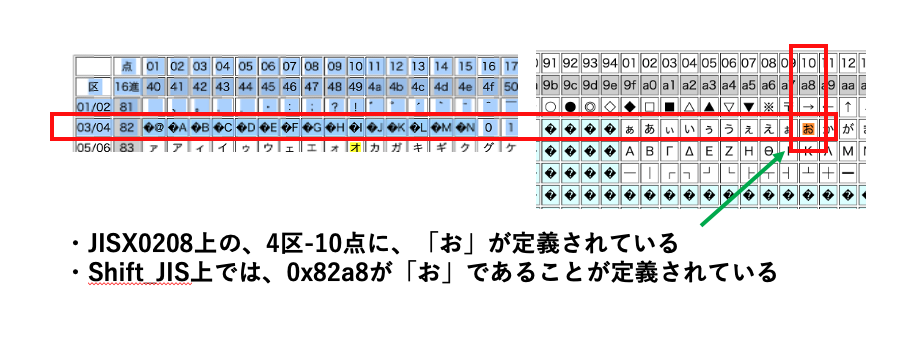
なんとなく、文字集合という表があって、ある特定のルール(文字符号化方式)で特定の値(符号)に変換されて文字を識別して扱ってるんだなーというのが掴めてきました。
※参考までに、以下の記事が、UnicodeとUTF-8の関係を掴む上でとてもわかりやすかったです。
「0x」について
0xをつけることで、のちに続く表現が16進数であることを示します。
「U+」について
U+をつけることで、のちに続く表現がUnicodeのコードポイントであることを示します。
U+以降は16進数で値を記載します。
Shift_JIS
文字符号化方式の1つ。SJISやシフトJISとも呼ばれています。
以下、非常にわかりやすかったのでShift_JISの説明を引用します:とほほの文字コード入門
半角文字(制御文字・英数記号・半角カナ)は JIS X 0201 の文字をそのまま使用し、全角文字は、1バイト目を JIS X 0201 で未使用の 0x81~0x9F、0xE0~0xEF、2バイト目を 0x40~0x7E、0x80~0xFC の領域に計算式でシフトして符号化します。
つまり、Shift_JISは半角文字を1バイト、全角文字を2バイトで表現します。
上記の引用文の通り、Shift_JISでは2つの符号化文字集合を利用します。
例えばですが、半角アルファベットの「A」は、JIS X 0201の方に定義がありますので、
JIS X 0208上の区点番号はありません。先述したサービスで確認してみても区点番号の項目が「-」となっていて区点番号がないことがわかります。

参考までに、以下はShift_JISで利用できる文字を一覧で整理してくれており、
区点番号とShift_JIS上の符号を確認できます。
Windows-31J(CP932・MS932)
Shift_JISと同じ方法で符号化を行いますが、扱う文字集合に
「NEC特殊文字」・「NEC選定IBM拡張文字」・「IBM拡張文字」を追加しています。
Windows-31JはIANAの登録名であり、最終的に統合されたCP932のことを指します。
また、MS932はWindows-31JのJava上の呼称のようなので、Windows-31JはMS932・CP932と同じものだと捉えて問題ないようです。
例えば、JIS X 0201とJIS X 0208の文字集合の中に「髙(はしごだか)」は定義されていません。その為Shift_JISでは符号も出せず取り扱いもできません。
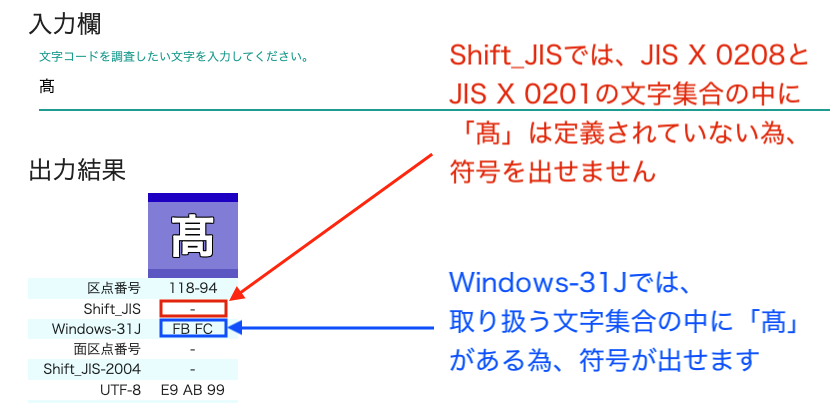
※面区点番号とは、符号化文字集合であるJIS X 0213の符号位置(コードポイント)です。上記画像では「-」となっていますので、「髙」の符号位置(コードポイント)が定義されていないことが分かります。
※Shift_JIS-2004とは、JIS X 0213の文字符号化方式の1つです。上記画像では「-」となっていますので、「髙」の符号を出すことができない符号化方式であることが分かります。
・Windows-31Jの歴史的な背景は以下が理解の助けになりました。
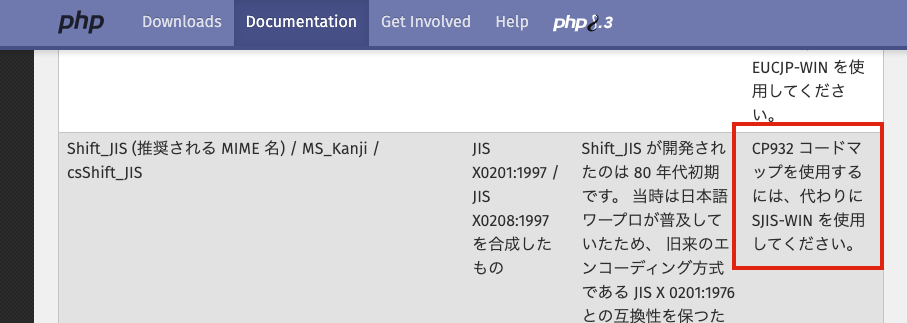
(余談)PHPのエンコードディング指定で「CP932」を使うべきなのか「SJIS-win」を使うべきなのか
には、
CP932
SJIS-win
があります、Windows-31Jを利用したい場合、どちらを利用すべきか
悩みました。現状の結論としては、SJIS-winでもCP932を指定しても取得できる符号に変化がないので、どちらを指定してもWindows-31Jで変換してくれるのではと想定してます。
試しに、paiza.ioというサービスを利用して
IBM拡張文字に定義されている「髙」の符号を出して確認してみました。
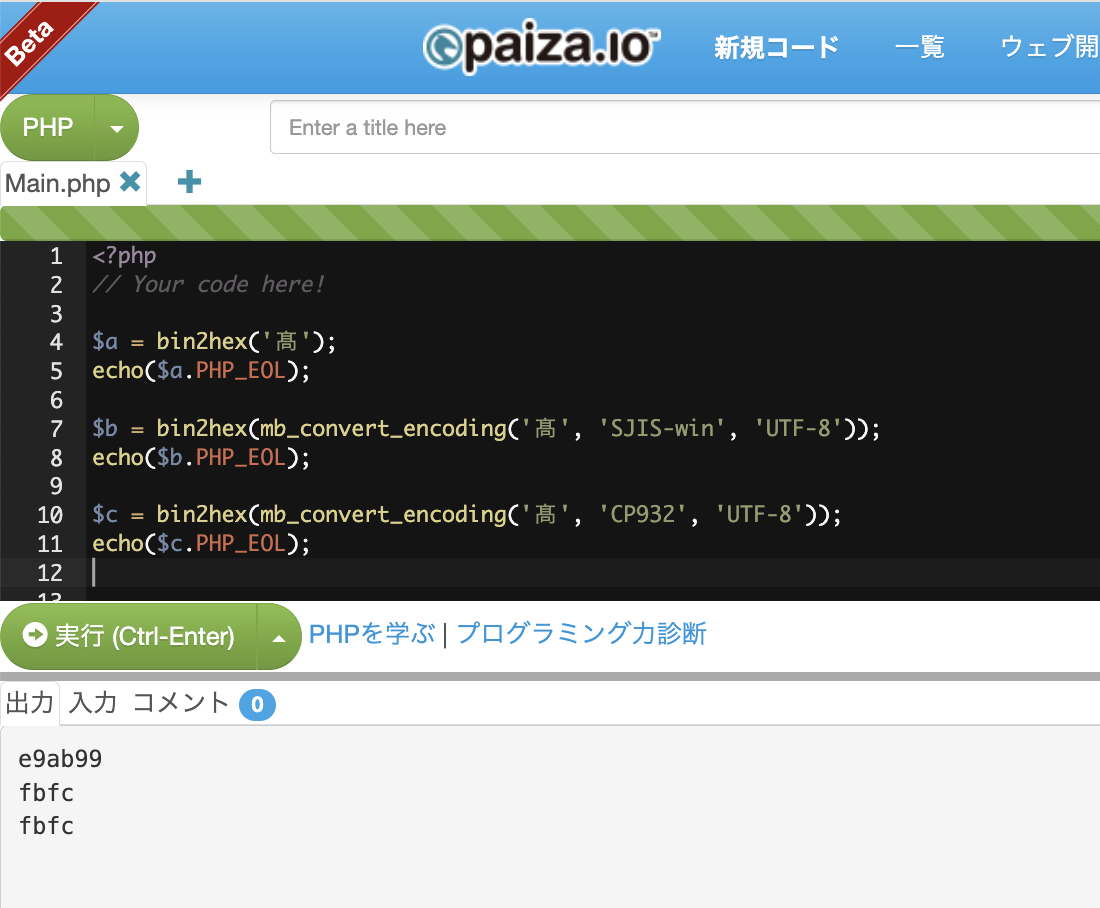
SJIS-winとCP932ともに、IBM拡張文字に定義されている「髙」の符号である「0xfbfc」となっていましたので、Windows-31Jで符号化されていると考えてよさそうです。
※e9ab99はUTF-8上の符号です。
こうなってくると、SJIS-winかCP932のどちらを使うべきかに対する答えをどう出すかは、好みになってくるような気がします。
個人的には下記PHPの公式に、「CP932のコードマップを使いたいならSJIS-winを使ってください」のような記載があるので、SJIS-winで指定しておこうかなくらいの気持ちです。
UTF-8
UTF-8は以下のpdfが分かりやすかったため、pdfから説明を引用します。
ASCIIと互換性がある8ビット単位のUnicodeの文字符号化方式。
・1つの符号位置の表現に1バイトから4バイトの可変長
・元々ASCIIで構成されていたデータフォーマットやプロトコルを拡張することに向いている
・漢字などは3バイト以上必要になるので従来のJIS系の文字符号化方式よりサイズが大きくなってしまう
ASCIIと同じバイト列を用いる
・複数のバイトで1文字を表す際も2バイト目以降に0x00〜0x7Fが出現することはない
外字(環境依存文字・機種依存文字)とは
以下は、「[改訂新版]プログラマのための文字コード技術入門 (WEB+DB PRESS plusシリーズ)」のP66からの引用になります。外字とはなんなのかや機種依存文字という言葉が生まれた背景を学ぶことができます。
※下記引用文内の「...」は省略を表現しています
JIS X 0208はかなりよく文字を収集していますが、実際に使われ始めると足りない文字があることが意識されるようになりました。一方、JIS X 0208の文字コード表には文字の割り当てのない区点位置、つまり空き領域が少なからず残されています。
そこで、足りない文字を文字コード表の空き領域に独自に割り当てた使用が行われるようになりました。これを外字と言います。外字には、利用者が自由に作字するユーザー定義外字もあれば、機器のベンダーが製品ごとに外字を定義しているベンダー定義外字もあります。
こうした外字は、プラットフォームをまたがる情報交換の少なかった時代にはそれなりの存在意義があったといえます。
しかし、ネットワークを通じた情報交換が盛んに行われるようになり、異種プラットフォーム間のデータ交換が増えると、外字は当然文字化けしますから、問題として認識されるようになりました。
...ベンダー定義外字はとくに機種依存文字という呼び名で知られるようになりました。
...今日では「機種」依存文字という用語は、実態を正確に反映しているとはいえません。
また、機種依存「文字」といいますが、問題なのは文字そのものではなく文字の符号であることから、この点でも不正確な用語です。(注16)
しかし、広く話題となり用いられてきた言葉であるため、本書では用いることにします。「環境依存文字」という呼称もあります。
機種依存文字の定義
1980年代
1980年代においては、以下の理由により、ベンダ定義文字(各コンピュータメーカーが、公的規格には無い文字を独自に拡張して搭載した文字)が、機種依存文字であるという定義が成り立っていた。
日本語文字コードの公的規格はJIS X 0201とJIS X 0208だけだった。
各メーカーのPCごとに搭載されているフォントセットの文字集合がまちまちだった。
ただし、公的規格であっても、以下のような文字は、規格が普及・定着するまでは機種依存文字とされることがあった。
JIS X 0208 第2水準
JIS X 0208 第2次規格 (JIS C 6226-1983。新JIS・83JISとも呼ばれる) で追加もしくは字形が変更された文字
2000年代以降
以下の理由により2000年代以降では、機種依存文字について、「どんな機種でも表示できるとは言えない文字」、もしくは「異機種間のデータ交換の際に文字化けする確率が高い文字」という程度の定義しか出来ない。
Wikipediaと書籍を踏まえて、現在では外字も機種依存文字も環境依存文字も、「異なる機種間でデータ交換する際に文字化けしてしまう可能性が高い文字」という認識で問題なさそうに思います。
PHPで文字コードを扱ってみる
PHPで文字列の符号(文字コード)を確認する
・UTF-8,SJIS,SJIS-win共通
bin2hexで符号を取得可能
$char = 'お';
$tmp_hex = bin2hex($char);
PHPでUnicodeの符号位置(コードポイント)を確認する
UTF-8からUCS-2にエンコードしてbin2hexで16進数の値(符号)の文字列を取得
$char = 'お';
$code_point = bin2hex(
// 基本多言語面(BMP)の範囲内で一旦十分なのでUCS-2を指定しています
mb_convert_encoding($char, 'UCS-2', 'UTF-8')
);
※↑「𩸽(ほっけ)」がUCS-2上になかった為、後述のGithub上のリソースはUCS-4を指定しています。
PHPで符号を出力するCLI処理
以下リポジトリで作成してみました。
特定ファイルに入力した文字の、SJIS-win,SJIS,UTF-8上の符号をターミナルに出力させることが可能です。
※MacとiTerm2で動作確認しております。
また、SJIS-win, SJISの場合、2バイト文字を大雑把に分類して出力することもできます。サンプルの文字も用意してみましたので、実際に各文字符号化方式でエンコードされた符号を確認してみましょう。
符号を出すサンプル文字を用意
このプログラムでは、以下の文字をサンプルとして用意しています。
※detect_targetsディレクトリ内の各txtファイルに書いてある文字です。
・半角数値, 半角アルファベット(大文字・小文字),半角記号
0123456789
ABCDEFG
abcdefg
xyz
@\,'
・半角カナ
アイウエオ
・全角ひらがな
あいうえお
・常用漢字,第1水準漢字
漢字
・第1水準漢字
※篭が常用漢字に入れなかったのは下記で解説がありました。
篭
・人名漢字,第2水準漢字
昴
・人名漢字,第3水準漢字
渚
・第4水準漢字
菥
・IBM拡張文字
※「髙」はWindows-31Jで独自にJIS X 0208の空いている領域に定義されており、JIS X 0208の第1,第2水準漢字に取り込まれていない漢字です、その後に規定されたJIS X 0213の第3,第4水準漢字にも取り込まれなかった漢字の為、第X水準漢字として分類することができない漢字になります。
※こちらでわかりやすく説明されています。
髙
・全角の句読点
、。
・NEC特殊文字
①⑩Ⅴ㌔㍗㎝〝㊧∟№㈱
・全角郵便記号, 全角数学記号(ニアリーイコール)
〒≒
・第3水準漢字,IBM拡張文字
※左から「さき」「わた」「なぎ」「えな」
﨑纊彅褜
・IBM拡張文字
※「かん・やかた」
館
・IBM拡張文字,第3水準漢字,人名漢字
※IBM拡張文字ですが、第3水準に入った漢字の例です
黑
・IBM拡張文字,第4水準漢字
※IBM拡張文字ですが、第4水準に入った漢字の例です
匤
・第4水準漢字,サロゲートペア
※サロゲートペアはUTF-8では存在しません。UTF-16のお話です。
※サロゲートペアに関してはこちらが分かりやすかったです。
𩸽
Shift_JISで符号を出してみる
第一水準及び、第二水準はJIS X 0208で定義されているので、Shift_JISでも正しく符号を出すことが出来ています。
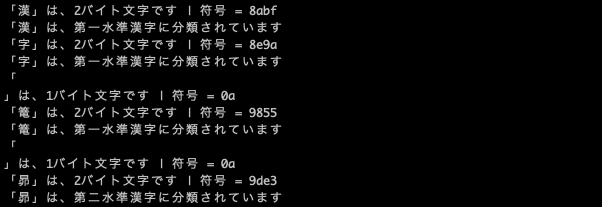
一方で、第3水準,第4水準漢字はJIS X 0208にて定義がないので出せていません。また、Windows-31JでJIS X 0208の未定義領域に拡張で定義された「NEC特殊文字」や「IBM特殊文字」もShift_JISはJIS X 0208をそのまま利用する関係上出せていないことがわかります。※内部ではmb_str_splitの時点で文字化けして「?」になっている為、?として扱われています。

Windows-31Jで符号を出してみる
第1,第2水準漢字はSJIS同様正しく判定できておりますが、第3,4水準漢字はWindows-31Jで拡張されたJIS X 0208には定義がない為、正しく取り扱えていないことがわかります。

また、SJISとは異なり、Windows-31Jにて、JIS X 0208に拡張定義された「NEC特殊文字」「IBM特殊文字」はWindows-31Jだと正常に取り扱えていることが確認できました。



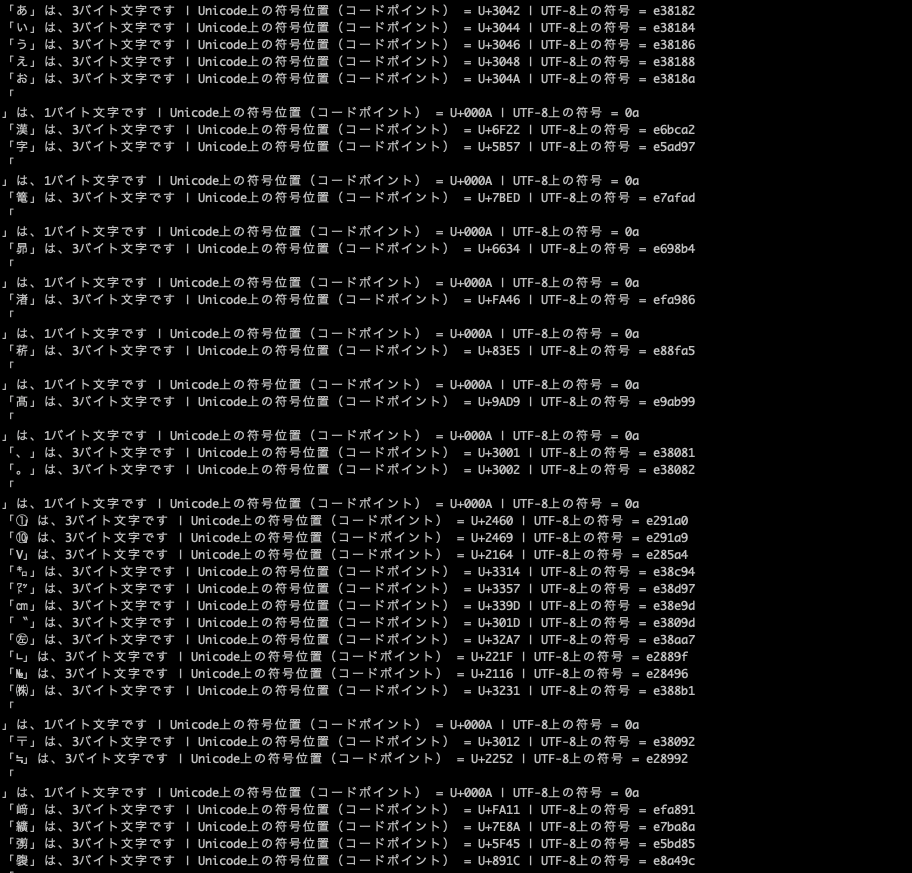
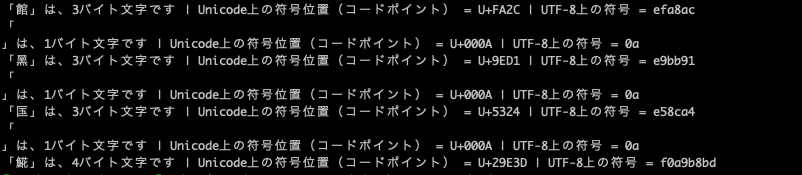
UTF-8でコードポイントと符号を出してみる
Unicode上では、今回用意した文字は全て定義されている為、全ての文字のコードポイントと符号を出すことができました。

おわりに
文字コードのもの字もわからぬ状態でしたが、なんとなく文字コードを理解できた気がします。調べているうちに気になるところが色々と出てきてしまったので、また続きをかければと思います。
本記事は以上です、この記事が文字コードの理解の一助になれば幸いです。