週末、Twitterのランキングアルゴリズムが公開され話題となっています。既に色々な方が紹介・解説されているところですが、「最終的なタイムラインはどう作成されるのか」を中心に要点をまとめました。また、SNSで出回っている解説でいくつか正確でない記載が散見されたので、この投稿で(恐らく)正しいのではないかと思われるロジックを記しています。
「おすすめ」タブの並び順を決定するコアは"HEAVY RANKER"
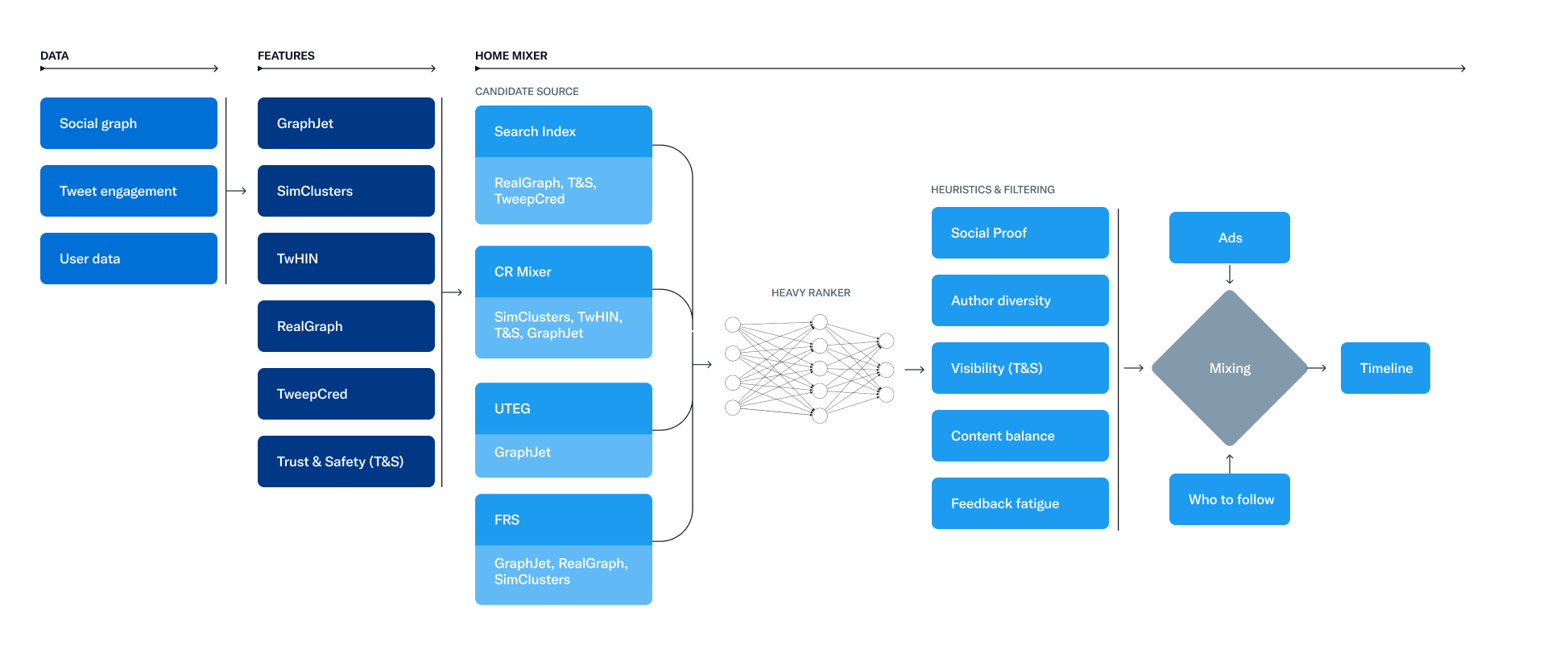
「おすすめ」タブは、Twitterユーザーのデフォルトタイムラインとなっており、ここで上位に掲載されることがインプレッションを獲得する重要な要素であるため、そのアルゴリズムが公開されたことで非常に注目を集めました。GitHubリポジトリのルートディレクトリにも掲載されている図を読むことで、このTwitterランキングアルゴリズムの概要を把握することができます。
https://github.com/twitter/the-algorithm
このダイアグラムの中心にあるのがHEAVY RANKERというシステムです。HEAVY RANKERはニューラルネットで構成されており、いわゆる深層学習・ディープラーニングの仕組みを使い、一人ひとりのユーザーの「おすすめ」タブに掲出すべきツイートを決定(スコアリング)します。
先に解説すると、HEAVY RANKERの右側にあるのがスコアリング後のフィルタリング・ヒューリスティックによる後処理です。具体的には次のような処理を行っているようです。
- 投稿者の偏り除去(Author Diversity)
- 知り合い/それ以外のバランス調整(Content Balance (In network vs Out of Network))
- ネガティブフィードバックの考慮(Feedback fatigue)
- 重複排除、既読投稿除去(Deduplication / previously seen Tweets removal)
- ブロック、ミュート投稿・ワードの排除(Visibility Filtering (blocked, muted authors/tweets, NSFW settings)
)
https://github.com/twitter/the-algorithm/blob/main/home-mixer/README.md
HEAVY RANKERのような単一のアルゴリズムによってスコアリングを行うと、例えば高スコアのついたユーザーによるツイートが上位投稿を独占したり、同じようなバズツイートが並んでしまうということが起こりがちです。レコメンドやキュレーションシステムにおいては、こうした後処理によってユーザー体験を良くする工夫が入れられていることが多くあります。最終的には、これらに広告やおすすめフォロワーが追加されてタイムラインが完成します。
ではこのシステムの中心にあるHEAVY RANKERとはどういったシステムなのでしょうか。一言でいうと、このシステムは例えば「あるユーザーがその投稿をいいねしそうかどうか」を、過去のビッグデータから作成された機械学習モデルを使って予測する仕組みです。このような予測モデルを使うことで、まだ「いいね」がついていないようなツイートに対してもスコアリングを行うことができます。これによって予測されるスコアは、
- recap.engagement.is_favorited
- The probability the user will favorite the Tweet.
- そのユーザーが「いいね」するかどうか
- recap.engagement.is_good_clicked_convo_desc_favorited_or_replied
- The probability the user will click - into the conversation of this Tweet and reply or Like a Tweet.
- そのユーザーがツイートをクリックするかどうか
- recap.engagement.is_good_clicked_convo_desc_v2
- The probability the user will click into the conversation of this Tweet and stay there for at least 2 minutes.
- そのユーザーがツイートをクリックした後、2分以上滞在するかどうか
- recap.engagement.is_negative_feedback_v2
- The probability the user will react negatively (requesting - "show less often" on the Tweet or author, block or mute the Tweet author)
- そのユーザーがそのツイートに対してネガティブなサインを送るかどうか(表示を少なくする、ブロックするなど)
- recap.engagement.is_profile_clicked_and_profile_engaged
- The probability the user opens the Tweet author profile and Likes or replies to a Tweet.
- そのユーザーがプロフィールをクリックしツイート投稿者にいいねやリプライを送るかどうか
- recap.engagement.is_replied
- The probability the user replies to the Tweet.
- そのユーザーがリプライするかどうか
- recap.engagement.is_replied_reply_engaged_by_author
- The probability the user replies to the Tweet and this reply is engaged by the Tweet author.
- そのユーザーがリプライし、さらにツイート投稿者がそのリプライにエンゲージするかどうか
- recap.engagement.is_report_tweet_clicked
- The probability the user will click Report Tweet.
- そのユーザーが違反報告を行うかどうか
- recap.engagement.is_retweeted
- The probability the user will ReTweet the Tweet.
- そのユーザーがリツイートするかどうか
- recap.engagement.is_video_playback_50
- The probability (for a video Tweet) that the user will watch at least half of the video
- そのユーザーが投稿された動画を半分以上視聴するかどうか
と10種類あるようです。これらの0〜1のスコアを予測した後、ルールベースで重み付け総和が計算され、そのツイートに関するスコアが決定されます。正直なところ、最終的なスコアがルールベースで算出されるというのは、Twitterほどのテクノロジーカンパニーの仕様としてはやや驚きです。例えばユーザーのTwitterに対するエンゲージメント(滞在時間や訪問頻度)を予測する上位レイヤーの機械学習モデルを導入することで、先ほどの重みを最適化する仕組みを入れることができるのではないかと考えられます。一応の予想としては、この重み付けをコントロールしたいというモチベーションがどこかに(誰かに)あったのかもしれません(ただし、やってみると分かりますが10種類のパラメータを人間が操作して適切な結果を導くのはかなり難易度が高いタスクです)
ここまで読むと分かりますが、現在出回っている解説で「いいねが多いと上位表示」のように言われているものは多分間違いです。正しくは「あなたがそのツイートをいいねしそうだと予測されるとそれに応じてスコアが加算される」となっています。つまり、まだまったくいいねが付いていなかったとしても、あるユーザーがその投稿をいいねしそうだと予測されれば、そのユーザーのおすすめタブで上位表示される要素として加味されます。もしかしたらこの違いは機械学習アルゴリズムに馴染みがない方には分かりにくいのかもしれません。
HEAVY RANKERの処理対象は様々なロジックで選出される
ニューラルネットで構成されたHEAVY RANKERは文字通り「重い」ので、処理対象のツイート候補を抽出する仕組みがあります(上のダイアグラムで書かれたCANDIDATE SOURCEの部分)。この投稿でここの詳細に立ち入ると長くなってしまうのでここでは控えますが、例えばソーシャルグラフに基づいて知り合いのツイートを候補に入れたり、知り合い外でもバズっているツイートを取ってきたりするような仕組みがあるようです。ただし、重いというのは「数億以上ある日々の全ツイートをスコアリング対象にできない」という意味においてです。数千〜数万くらいのツイートを処理することは十分可能なはずなので、恐らく自分のフォロワーのおすすめ候補には、よっぽどのことがなければ自分のツイートは含まれているはずです。
https://github.com/twitter/the-algorithm/blob/main/cr-mixer/README.md
先ほどと同様、話題の解説で、「いいねの影響度はリプライの30倍」、あるいは「フォローとフォロワーの比率が重要」と言われている処理は実はこの部分(の一部)です。なので、残念ながら仮にここを頑張ってハックすることはあまり本質的ではありません。繰り返しとなりますが、最終的なHEAVY RANKERで高スコアを得るツイートが多くインプレッションされます。
例外としてバズツイートを狙う場合、自分のフォロワー外の人のCANDIDATE SOURCEに入らなければいけないため、これらの要素を気にしたほうが良いかもしれません。しかし殆どのユーザーが気にする「自分のツイートが(フォロワーに)読まれるかどうか」について考えるとき、小手先の数字は重要ではなく、自分のフォロワーが読みたくなる・いいね/RTしたくなる・リプライしたくなるツイートを投稿すること、更に自分のフォロワーとの関係性を普段から高めておくことが重要であることが、今回のアルゴリズム公開によって明らかになったと言えます。
まとめ
日本人も多く使っているTwitterのアルゴリズムが公開されたということで興味を持った方も多いかと思います。この投稿では、コードの詳細部分にまで立ち入らずにその概要を把握できるような内容にすることを心掛けました。全体的な印象としては、サービスの立ち上げ時期から使ってきたと思われるヒューリスティック、人手パラメータを用いた仕組みと、ニューラルネットで作成された新しいアルゴリズムを結合させた工夫が感じられるようなアルゴリズム構成でした。本投稿が皆さまの理解の参考になればと思います。もし間違った記載がありましたらコメントで指摘をお願いします。