Webページからちょっとデータ抜き出したいときありますよね。
1回だけしか行わず、わざわざプログラム組むほどでもないならVimでやるのがおすすめです。
例:はてぶのページからリンクを取得する
vimを開いて4コマンドでリンクを抜き出します。
しかもエディタ上なのでその後の加工や連続スクレイピングなどもスムーズに行えます。
# 最初の行以外はどのサイトでも共通的に使えるはず
:e http://b.hatena.ne.jp/ctop/it
:%s/></>\r</g | filetype indent on | setf xml | normal gg=G
:%v/<a/d
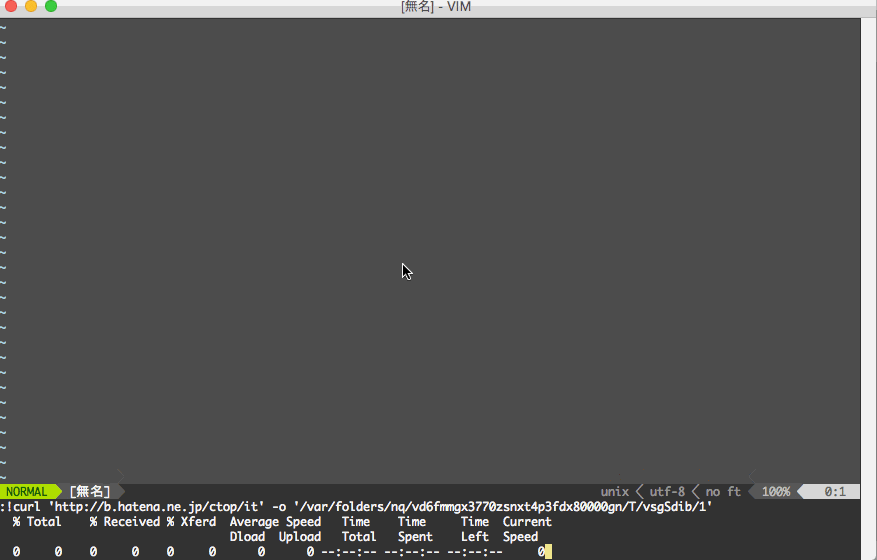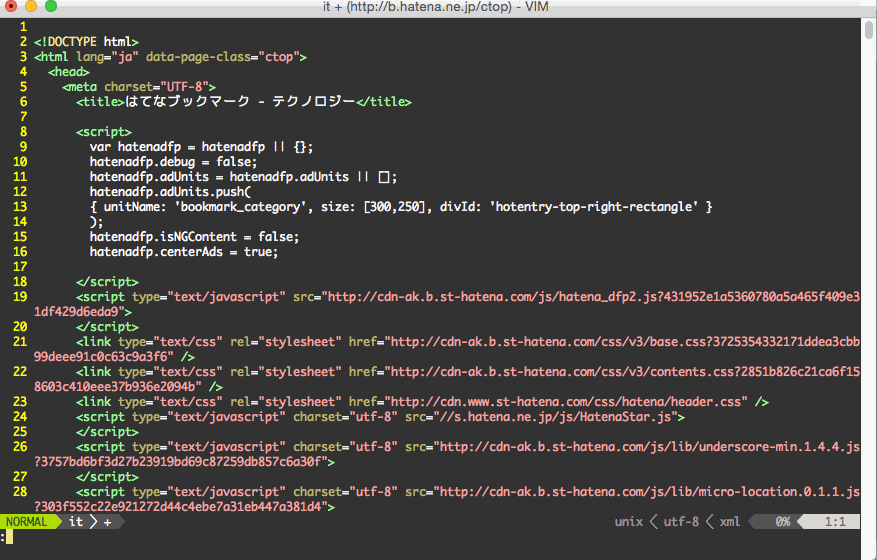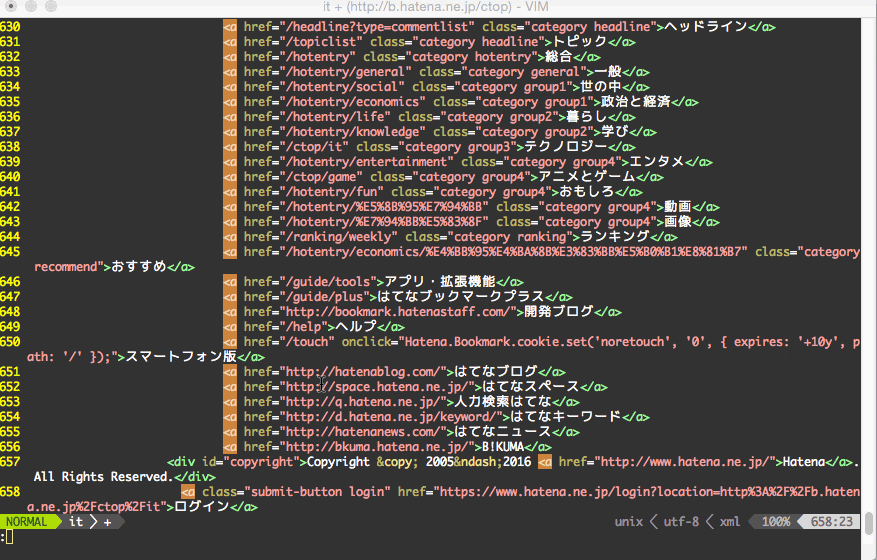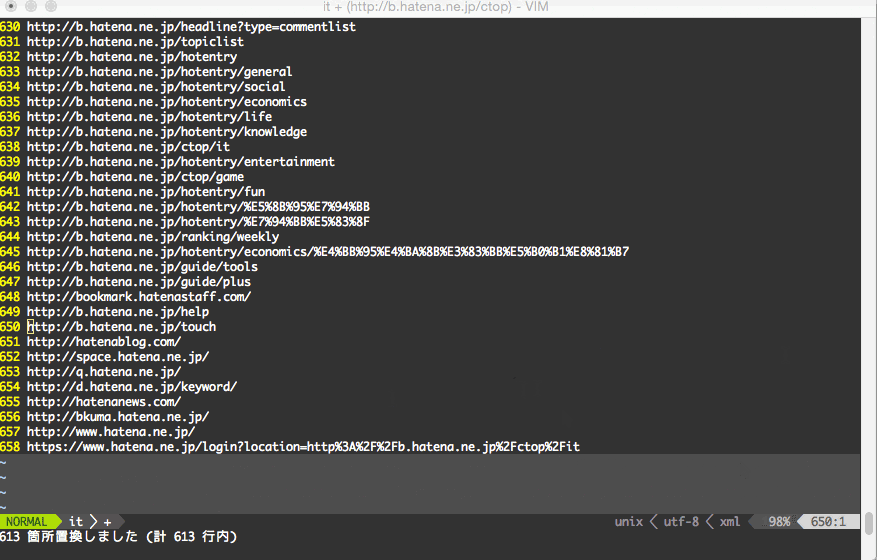
:%s/^.*href="\([^"]*\)"[^>]*.*$/\1/
# 完全URLにしたいなら
:%s/^\//http:\/\/b.hatena.ne.jp\//
↓結果
解説
データ取得
# フォーマット
:e <url>
# 例:はてぶのページ取得
:e http://b.hatena.ne.jp/ctop/it
HTML整形
:%s/></>\r</g | filetype indent on | setf xml | normal gg=G
フィルタリング
# フォーマット:指定したパターンにマッチしない行を削除
:%v/<パターン>/d
# 例:aタグを含まない行を削除
:%v/<a/d
データの整形
# フォーマット
:%s/<置換前パターン>/<置換後パターン>/gc
# 例:hrefの中身だけを抽出(それ以外の部分は削除)
:%s/^.*href="\([^"]*\)"[^>]*.*$/\1/gc
# 例2:相対URLを絶対URLに置換
:%s/^\//http:\/\/b.hatena.ne.jp\//
おまけ
取得したURLを元にして再度スクレイピングしたいなら以下を実行
# ヤンク
yy
# ヤンクしたURLをペーストして新しいタブで開く
:tab new <url>
# あとは上の項目を繰り返し実施するだけ