この記事は2024年6月7日に弊社ブログにて公開されたものを移植したものです。
古い情報が含まれている可能性がありますのでご注意ください。
本記事ではGoogle Cloud のSpeech-to-Textを、GoogleColaboratoryで実行します。基本動作をさせた後、モデル適応機能も使ってみます。Speech-to-TextのAPIをPythonで叩いてみたい方や、追加機能を試したい方は是非ご覧ください。
Speech-to-Textを始める前に
Google CloudのSpeech-to-Textを利用するにはGoogleアカウントが必要です。また新規でSpeech-to-Text V1 APIを利用する際、無料クレジット $300 分と 1 か月あたり 60 分間まで音声の文字変換と分析が無料となっています。
利用枠を使い切っている場合は、料金がかかってきますのでご注意ください。Speech-to-Textの料金はこちらこちらからご確認ください。
Speech-to-Textの設定
GoogleColaboratoryで動かす前に、Speech-to-Textを利用できるように準備します。公式のHow To動画もあるので、こちらもプロジェクトの設定の際に参考にしてみてください。
- Google Cloudプロジェクト作成を作成する
- Cloud Speech-to-Text APIを有効にする
- 作成したプロジェクトのコンソールを開く
- API とサービスを開く
- 認証情報を開く
- 認証情報を作成し、サービスアカウントを選択
- サービス アカウントの詳細を入力
- 作成したアカウントを選択
- キーを選択、鍵を追加、新しい鍵の作成を選択
- キーのタイプをJSONにし作成、JSONファイルをダウンロード
音声認識の実行手順
ノートブックを新規作成を押します。

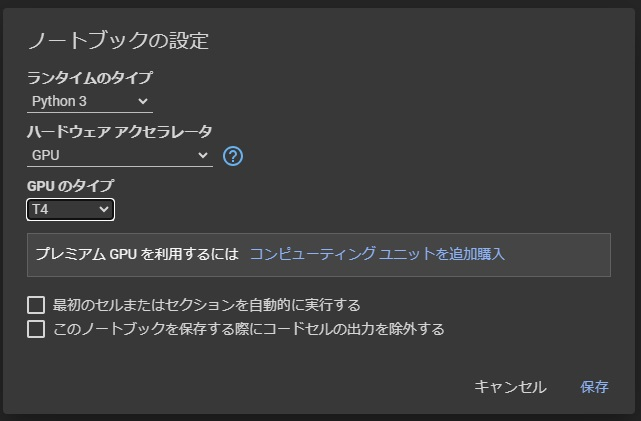
上のメニューから 編集>ノートブックの設定 を選択します。
ハードウェア アクセラレータをGPUに変更し、保存を押します。
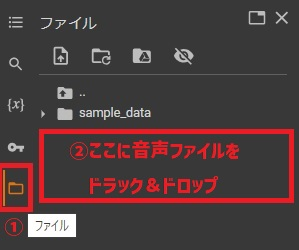
GoogleColaboratoryのセッションストレージに音声ファイルとJSONファイル配置していきます。
左のバーのファイルをクリックし、開いた箇所(下記画像の赤枠部分)へ音声認識させたい音声ファイルをドラック&ドロップします。
GoogleColaboratoryに必要事項を書いていきます。
まずライブラリをインストールします。
!pip install --upgrade google-cloud-speech
コードは公式のgitに掲載されているQuick Startをベースに、一部変更して利用します。アクセスキー、シークレットアクセスキー、音声ファイルのパスは各自のものに書き換えてください。
import os
import wave
import io
from google.cloud import speech
voice_file_path = '音声ファイルパス'
api_key_path = 'キーのファイルパス'
fr = 24000
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = api_key_path
# サンプリングレートを確認
with wave.open(voice_file_path, 'rb') as f:
fr = f.getframerate()
# 音声ファイルを読み込み
with io.open(voice_file_path, 'rb') as f:
content = f.read()
# 音声データを設定
audio = speech.RecognitionAudio(content=content)
config = speech.RecognitionConfig(
encoding=speech.RecognitionConfig.AudioEncoding.LINEAR16,
sample_rate_hertz=fr,
language_code='ja-JP',
)
# Speech-to-Text API クライアントを作成
client = speech.SpeechClient()
# 音声認識を実行
response = client.recognize(config=config, audio=audio)
# 結果を出力
for result in response.results:
print(result.alternatives[0].transcript)
実行してみます。今回自分で用意した音声は『本日の東京の天気は晴れ。明日の大阪の天気は曇りです。』という音声なのでどのような結果が出るでしょうか。

無事音声が認識されました、認識内容も問題ありません。
句読点機能を使う
enable_automatic_punctuationの項目をTrueに設定すると句読点の自動挿入を有効にすることができます。実際にやってみましょう。
config = speech.RecognitionConfig(
encoding=speech.RecognitionConfig.AudioEncoding.LINEAR16,
sample_rate_hertz=fr,
language_code='ja-JP',
enable_automatic_punctuation=True, # 句読点の自動挿入を有効にする
}])

実行結果です、句読点が入り読みやすくなりました。
モデル適応機能を使う
Cloud Speech-to-Textにはモデル適応機能があります。
モデル適応機能を使用すると、提案される可能性がある他の候補よりも、Speech-to-Text が特定の単語やフレーズをより高い頻度で認識するように設定できます。たとえば、音声データに「weather」という単語が含まれているとします。Speech-to-Text が「weather」という単語を検出した場合、「whether」よりも多く「weather」と文字変換されることが理想的です。この場合は、モデル適応を使用して「weather」と認識するように Speech-to-Text にバイアスをかけることができます。
モデル適応により音声文字変換の結果を改善する
モデル適応を実感するために用意した音声は『えいせいのかんきょうはもんだいありません』という音声です。とりあえず何も設定せずに音声認識し、何と認識されるか確認しましょう。

何も設定していないと今回の『えいせい』は『衛星』と認識されました。ではモデル適応機能を利用し『えいせい』を『衛生』と認識してもらうようにしましょう。speech_contextsにphrasesとboostを設定します。
config = speech.RecognitionConfig(
encoding=speech.RecognitionConfig.AudioEncoding.LINEAR16,
sample_rate_hertz=fr,
language_code='ja-JP',
# enable_automatic_punctuation=True, # 句読点の自動挿入を有効にする
# スピーチアダプテーションを追加
speech_contexts=[{
'phrases': ['衛生'], # 認識を強化したい単語やフレーズ
'boost': 10.0 # ブーストの度合い(1.0から20.0の範囲で指定)
}])
設定し終えたので実行しましょう。

無事に『えいせい』を『衛生』と認識してもらうことができました。
終わりに
本記事では、Google CloudのSpeech-to-Textを利用して、Google Colaboratory上で実行する方法について説明しました。またモデル適応機能の利用で、特定の単語やフレーズをより正確に認識しやすくなること可能となり、音声認識技術の応用範囲が広がることをお見せすることができたと思います。