背景
- 前回ALBERTを回帰でfine-tuningして予測器を作成しました
- 作成したcheckpointが推論時にどのあたりに注目しているのかAttentionを可視化して分析していきます
実際に書いたコード
import torch
from transformers import AutoTokenizer
from albert_for_regression import AlbertForRegression
from consts import PRETRAINED_MODEL_NAME, VERSION, MODEL_PATH
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
tokenizer = AutoTokenizer.from_pretrained(PRETRAINED_MODEL_NAME)
# attentionを出力するため、AlbertForRegressionでAlbertをloadする箇所で output_attentions=Trueとする
# AlbertModel.from_pretrained(model_name, output_attentions=True)
model = AlbertForRegression(PRETRAINED_MODEL_NAME)
config = model.albert.config
# 学習したモデルをcheckpointをロードする
model.load_state_dict(
torch.load(MODEL_PATH, map_location=torch.device('cpu'))
)
model.eval()
# 分析対象のテキスト
# 文字列は適当です
texts = [
'[無料]今すぐ申し込みで最大50,000ポイントもらえる[munaitaカード]',
'これ一つで大丈夫!munaitaカードで贅沢三昧',
]
tokenized_list = tokenizer(
texts, padding='max_length', truncation=True,
max_length=config.max_position_embeddings)
# 対象文字列indexを指定
i = 0
with torch.no_grad():
attention_list = []
input_ids = tokenized_list['input_ids'][i]
attention_mask = tokenized_list['attention_mask'][i]
# 3つ目がattentionsの場合
_, _, attentions = model(
input_ids=torch.tensor(input_ids)[None],
attention_mask=torch.tensor(attention_mask)[None]
)
# attentionsのshapeは (12, 1, 12, 512, 512)
# (bert_layer_size, batch_size, head_size, seq_len, seq_len)です
# bert_layerの最終層のみを対象とします
attention = attentions[-1][0]
# headerレイヤーは全て足し上げる
# tokenは30に収まるので見やすいように40, 40にsliceします
sum_attention = torch.sum(attention, dim=0)[:40, :40]
# [CLS]のAttention分布をoutput_listに追加
output_list.append(sum_attention[0].numpy())
# 列毎の平均をoutput_listに追加
column_sums = sum_attention.mean(dim=0)
output_list.append(column_sums.numpy())
# output_listをcsvで出力
df = pd.DataFrame(output_list)
df.to_csv('output.csv', index=False)
plt.figure(figsize=(8, 6))
sns.heatmap(sum_attention, cmap='viridis')
plt.show()
出力方法
ChatGPTによると、ALBERTのAttentionの解釈では以下のことに注目するべきと言っています
-
- [CLS]トークンのATTENTION
-
- 他のトークンのAttention(各列のAttentionの平均)
Attention全体のヒートマップと、1と2を可視化していきます


結果
結果1. [無料]今すぐ申し込みで最大50,000ポイントもらえる[munaitaカード]
対象の文字列は [無料]今すぐ申し込みで最大50,000ポイントもらえる[munaitaカード] です
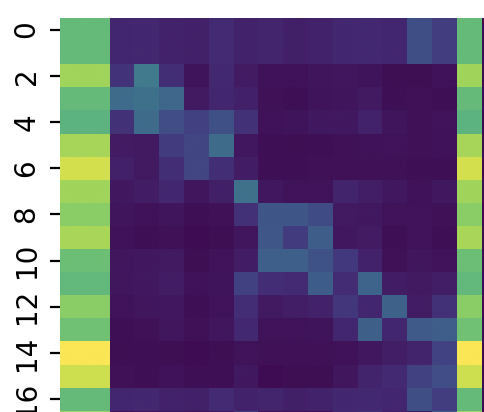
まずはトークン同士のAttentionのヒートマップ

青: [CLS]トークンのATTENTION と 赤: 他のトークンのAttention(各列のAttentionの平均) のグラフ

ポイント もらえる カード などが高いAttentionになっていることが確認できます
結果2. これ一つで大丈夫!munaitaカードで贅沢三昧
トークン同士のAttentionのヒートマップ
青: [CLS]トークンのATTENTION と 赤: 他のトークンのAttention(各列のAttentionの平均) のグラフ
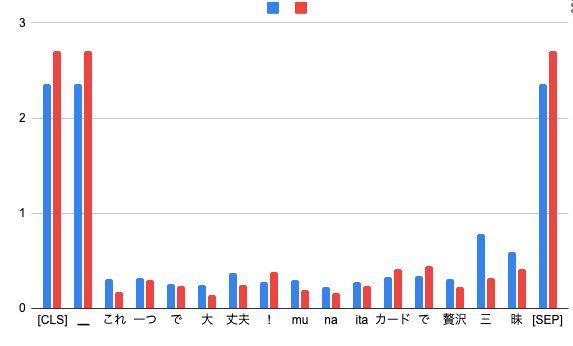
[CLS]と[SEP]トークンにAttentionが集まっていることがわかります。これはよくあるケースのようです。
なぜでしょうか。
[CLS]と[SEP]のAttentionが大きくなる理由
ChatGPTに聞いてみました
BERTのself-Attentionを分析した際、やのAttentionが大きくなっていました。これはなぜですか?
BERTモデルにおける トークンや トークンが大きなAttentionを受ける理由は、それらがモデルのアーキテクチャとトレーニングプロセスに由来しています。
[CLS]トークン
文全体の代表: (Classify)トークンは、BERTが文章分類タスクを行う際に使用されます。このトークンは、入力されたテキスト全体の「要約」や「代表」として機能するため、モデルは文全体の文脈を反映するためにこのトークンに大きく注目します。
トレーニングのターゲット: BERTのトレーニング中には、特に文章分類タスク(例えば、感情分析)において、[CLS] トークンの出力が直接的なターゲットとなることが多いです。そのため、モデルはこのトークンを重視するように最適化されます。[SEP]トークン
文の区切り: (Separator)トークンは、文の終わりや、異なる文や文章セグメントの間の区切りを示します。このトークンが高いAttentionを受けるのは、モデルが文の区切りや構造を理解する上で重要だからです。
複数文の理解: 特に、複数の文を含む入力(例:質問応答タスクや文章対の分類タスク)においては、各文の関係を理解するために トークンが重要になります。注意点
モデルの注意分散: これらの特別なトークンが高いAttentionを受けることは、BERTが重要な文の区切りや文全体の意味を捉えるためにこれらのトークンに大きく依存していることを示しています。しかし、これは必ずしも他のトークンが無視されているわけではありません。モデルは他の多くのトークンにも注目しており、文脈全体の理解に貢献しています。
TransformerベースのモデルのAttentionは直感的ではないことが多く、その解釈は非常に複雑です。したがって、Attentionの大きさはあくまでモデルの内部状態の一側面を反映しているに過ぎず、モデルの判断全体を説明するものではありません。
まとめ
Attentionを可視化してどんなものか見てみました。
可視化した結果、あまり直感に一致するものではありませんでした。
Attentionの解釈は難しく、単純なものではないらしいということがわかりました。
参考