はじめに
この記事では、Pythonを使用してCommunications Miningにデータをインポートする方法を見ていきます。
この知識を再適用して、ソースコードを修正し、どのシステムからでも任意のタイプのファイルをアップロードできます。
Communications MiningへのデータのインポートにはAIユニットが消費されます。ここで使用されているデータセットには10件のレビューが含まれています。したがって、手順を正確に実行すれば、プロセスは10つのAIユニットを消費するはずです。
※ 同じデータセットを複数回インポートしても、追加のAIユニットは消費されません。
ユースケース
ここで紹介する仮想のユースケースでは、既存のCommunications Miningデータソースにホテルのレビューが含まれたCSVファイルをインポートします。
ホテルのレビューは、無人ロボットでスクレイピングされ、ローカルのCSVファイルに保存されました。
Pythonを使用してローカルのCSVファイルを開き、その内容をCommunications Miningが期待するJSONLファイル形式に変換し、既存のCommunications Miningデータソースにアップロードします。
プロジェクトファイル
プロジェクトには以下のファイルが含まれています。
| ファイル名 | 説明 |
|---|---|
| dataset.csv | 10件のホテルレビューが含まれているローカルのCSVファイル。 |
| requirements.txt | このプロジェクトに必要なPythonのライブラリとバージョンが含まれている要求ファイル。 |
| cm-upload-sync-raw.py | このプロジェクトの主なPythonのコードファイル。 |
プロジェクトファイルはこのレポジトリからダウンロードできます。
data.csvファイル形式
CSVファイルのスキーマは以下の通りです。
| Column | データタイプ | 説明 |
|---|---|---|
| ID | 数値 | 各レコードの数値の一意の識別子。 |
| ホテル名 | テキスト/文字列 | ホテルの名前。 |
| 名前 | テキスト/文字列 | レビューを提供する人の名前。 |
| 世代 | テキスト/文字列 | レビュアーの性別/年齢層。 |
| 投稿日 | 日付 | レビューが投稿された日付。 |
| 個人評価 | 数値 | レビュアーによって与えられた個人評価。 |
| コメントURL | テキスト/文字列 | 特定のウェブサイトの詳細なコメントやレビューにリンクするURL。 |
| タイトル | テキスト/文字列 | レビューのタイトル。 |
| コメント | テキスト/文字列 | レビュアーによる詳細なコメントやレビュー。 |
| コメントHTML | HTML | HTML形式で提供されるレビュアーによる詳細なコメントやレビュー(HTMLタグを含む)。 |
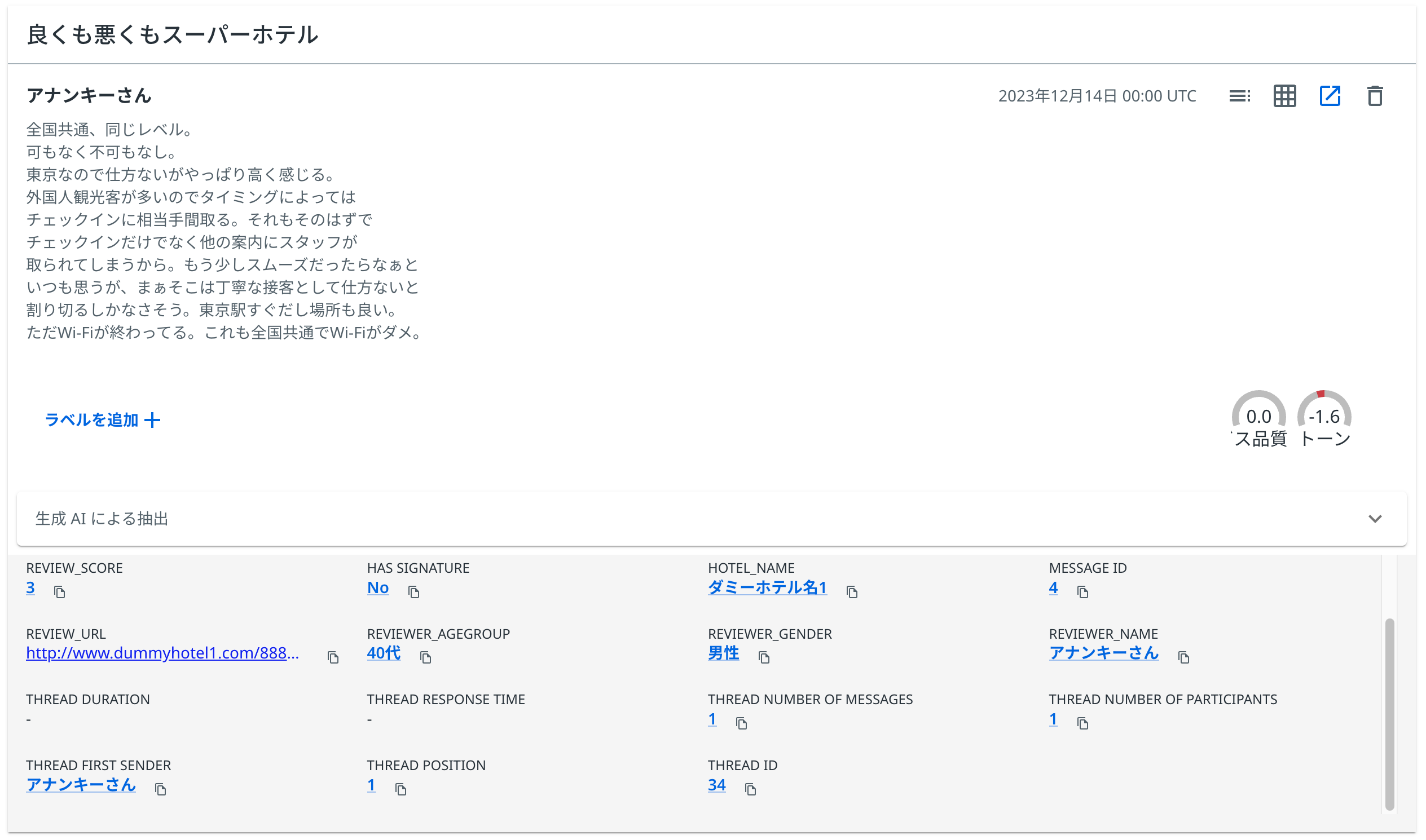
dataset.csvサンプル
以下にファイルからの一つのサンプルを示します。
| 列 | 値 |
|---|---|
| ID | 4 |
| ホテル名 | ダミーホテル名1 |
| 名前 | アナンキーさん |
| 世代 | 男性/40代 |
| 投稿日 | 投稿日:2023/12/14 |
| 個人評価 | 3 |
| コメントURL | http://www.dummyhotel1.com/88852230 |
| タイトル | 良くも悪くもスーパーホテル |
| コメント | 全国共通、同じレベル。 可もなく不可もなし。 東京なので仕方ないがやっぱり高く感じる。 外国人観光客が多いのでタイミングによっては チェックインに相当手間取る。それもそのはずで チェックインだけでなく他の案内にスタッフが 取られてしまうから。もう少しスムーズだったらなぁと いつも思うが、まぁそこは丁寧な接客として仕方ないと 割り切るしかなさそう。東京駅すぐだし場所も良い。 ただWi-Fiが終わってる。これも全国共通でWi-Fiがダメ。 |
| コメントHTML | <p>全国共通、同じレベル。<br/>可もなく不可もなし。<br/>東京なので仕方ないがやっぱり高く感じる。<br/>外国人観光客が多いのでタイミングによっては<br/>チェックインに相当手間取る。それもそのはずで<br/>チェックインだけでなく他の案内にスタッフが<br/>取られてしまうから。もう少しスムーズだったらなぁと<br/>いつも思うが、まぁそこは丁寧な接客として仕方ないと<br/>割り切るしかなさそう。東京駅すぐだし場所も良い。<br/>ただWi-Fiが終わってる。これも全国共通でWi-Fiがダメ。</p> |
インポートがうまくいけば、Communications Miningに以下のようなメッセージが表示されるはずです。
Requirements.txt
Requirements.txtには以下の内容が含まれています。
html2text==2020.1.16
Requests==2.31.0
-
Requestsを使用して、Communications MiningのAPIを使用してデータをアップロードするためのPOSTリクエストを送信します。 -
html2textを使用して、HTML形式の内容/メッセージがあるかどうかを確認します。存在する場合、それをリクエストに含めます。
コードの概要
このファイルは明らかにプログラミングのベストプラクティスに従っていません 😅。プロセスを理解するための簡単な参考材料としてご覧ください。
まず、以下にコード全体を掲載し、それから部分ごとに見ていきましょう。
import csv
import json
import os
import sys
import uuid
from datetime import datetime
import requests
from html2text import html2text
MAX_BATCH_SIZE = 256
ERRORS_FOLDER = "errors"
# 下記をご自身の<組織名>と<テナント名>に置き換えてください。
BASE_URL = "https://cloud.uipath.com/<組織名>/<テナント名>/reinfer_"
# 以下を自分の<プロジェクト名>と<ソース名>に置き換える。
# 空白は "-" に置き換えられる
SOURCE = "<プロジェクト名>/<ソース名>"
# 環境変数にREINFER_TOKENを追加している場合は、以下の行を利用してください。
# TOKEN = os.environ["REINFER_TOKEN"]
# そうでない場合は、以下を利用してください。
TOKEN = "YOUR API TOKEN"
# フィールドマップ
ID_REVIEW = 0
HOTEL_NAME = 1
REVIEWER_NAME = 2
REVIEWER_GENDER_AGEGROUP = 3
REVIEW_DATE = 4
REVIEW_SCORE = 5
REVIEW_URL = 6
REVIEW_TITLE = 7
REVIEW_PLAIN = 8
REVIEW_HTML = 9
# REVIEW_HTMLカラムにテキストが含まれているかチェックする
def html_body_exists(row):
review_html = row[REVIEW_HTML].strip()
body_exists = html2text(review_html).strip() != ""
return body_exists
# 各行の前処理(ストリップ、日付列のテキスト除去、日付/時刻のフォーマット)
# Communications MiningのAPIが期待するJSON形式でデータを返す
def row_to_document(row):
id_review = row[ID_REVIEW].strip()
hotel_name = row[HOTEL_NAME].strip()
reviewer_name = row[REVIEWER_NAME].strip()
reviewer_gender, reviewer_agegroup = row[REVIEWER_GENDER_AGEGROUP].strip().split('/')
review_date = row[REVIEW_DATE].strip().replace('投稿日:', '')
review_score = row[REVIEW_SCORE].strip()
review_url = row[REVIEW_URL].strip()
review_title = row[REVIEW_TITLE].strip()
review_plain = row[REVIEW_PLAIN].strip()
review_html = row[REVIEW_HTML].strip()
timestamp = datetime.strptime(review_date, "%Y/%m/%d")
timestamp_str = timestamp.strftime("%a, %d %b %Y %H:%M:%S %z")
return {
"raw_email": {
"body": {"html": review_html}
if html_body_exists(row)
else {"plain": review_plain},
"headers": {
"parsed": {
"Date": timestamp_str,
"From": reviewer_name,
"Message-ID": id_review,
"Subject": review_title,
}
},
},
"user_properties": {
"string:Hotel_Name": str(hotel_name),
"string:Reviewer_Name": str(reviewer_name),
"string:Reviewer_Gender": str(reviewer_gender),
"string:Reviewer_AgeGroup": str(reviewer_agegroup),
"number:Review_Score": int(review_score) if (review_score != '') else 0,
"string:Review_URL": str(review_url),
},
}
documents = []
# データをCommunications Miningにアップロードする
def upload_batch(documents):
response = requests.post(
f"{BASE_URL}/api/v1/sources/{SOURCE}/sync-raw-emails",
headers={"Authorization": f"Bearer {TOKEN}"},
json={
"documents": documents,
"transform_tag": "generic.0.CONVKER5",
},
)
if response.status_code != 200:
print("❌❌❌\n\nAPI呼び出しエラー\n\n❌❌❌")
# errorsフォルダが存在しない場合は作成する
if not os.path.exists(ERRORS_FOLDER):
os.makedirs(ERRORS_FOLDER)
with open(ERRORS_FOLDER + "/" + str(uuid.uuid4()), "a") as error_dump:
error_dump.write(json.dumps(documents) + "\n")
return
print(json.dumps(response.json(), indent=2, sort_keys=True))
# 長い文字列を含むセルを処理するために必要
csv.field_size_limit(sys.maxsize)
# 現在のパスを取得
os.getcwd()
with open("sources/dataset-small.csv") as csvfile:
reader = csv.reader(csvfile)
for idx, row in enumerate(reader):
if idx == 0:
print("ヘッダー行のスキップ")
continue
if idx % 100 == 0:
print(f"処理済み{idx}行")
documents.append(row_to_document(row))
if len(documents) >= MAX_BATCH_SIZE:
upload_batch(documents)
documents = []
upload_batch(documents)
コードの詳細
上記コードのいくつかの部分を直しましょう。
BASE_URLについて
# 下記をご自身の<組織名>と<テナント名>に置き換えてください。
BASE_URL = "https://cloud.uipath.com/<組織名>/<テナント名>/reinfer_"
BASE_URL はCommunications Mining環境のURLです。その構成はhttps://cloud.uipath.com/<組織名>/<テナント名>/reinfer_。
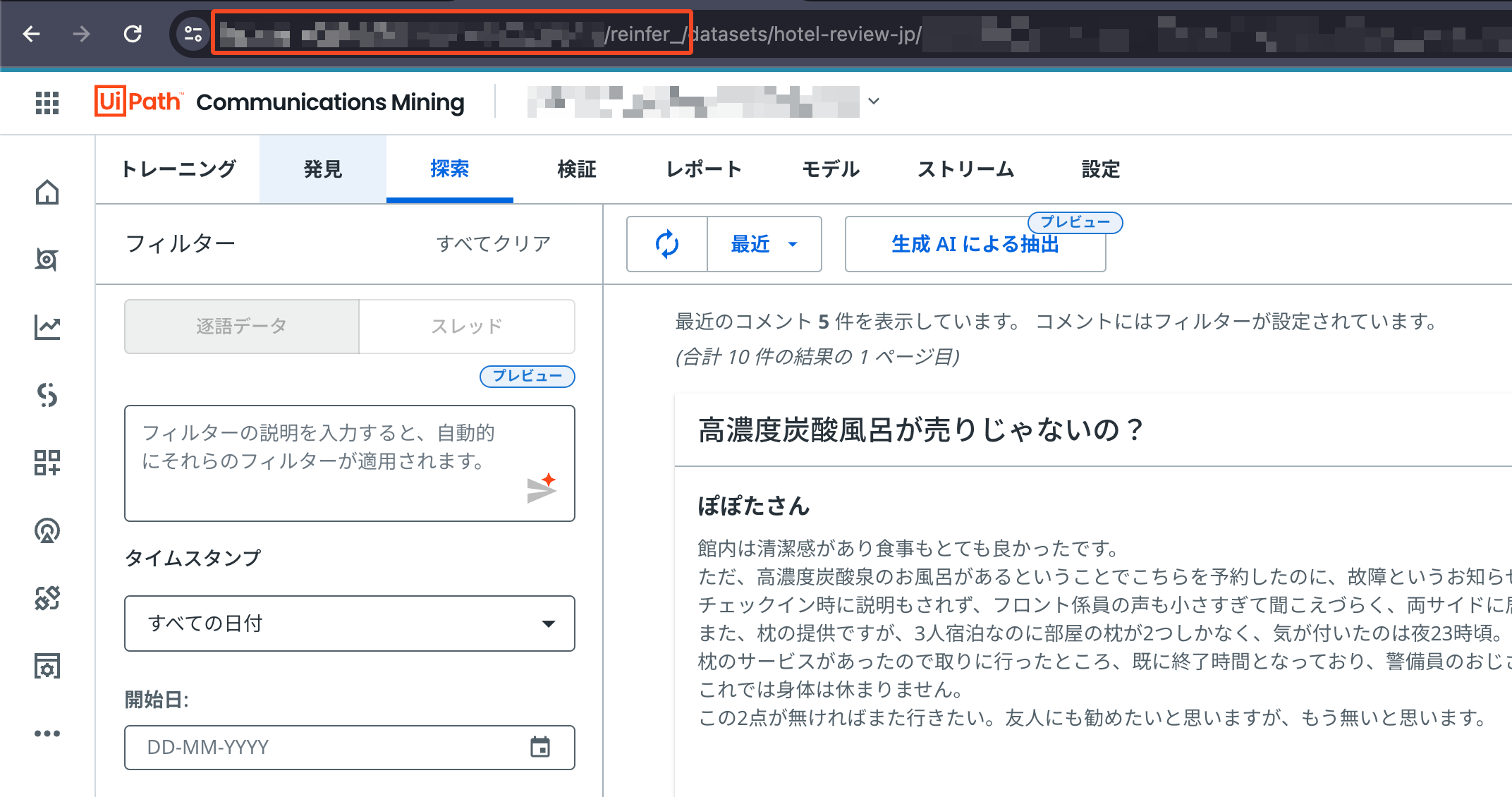
SOURCEについて
# 以下を自分の<プロジェクト名>と<ソース名>に置き換える。
# 空白は "-" に置き換えられる
SOURCE = "<プロジェクト名>/<ソース名>"
**SOURCE**にはターゲット・データ・ソースの名前を指定します。その構成は<プロジェクト名>/<ソース名>。こちらの例ではhotel-review-jp/hotel-reviews-jpとします。自分のソース名は以下のスクリーンショットで確認できます。
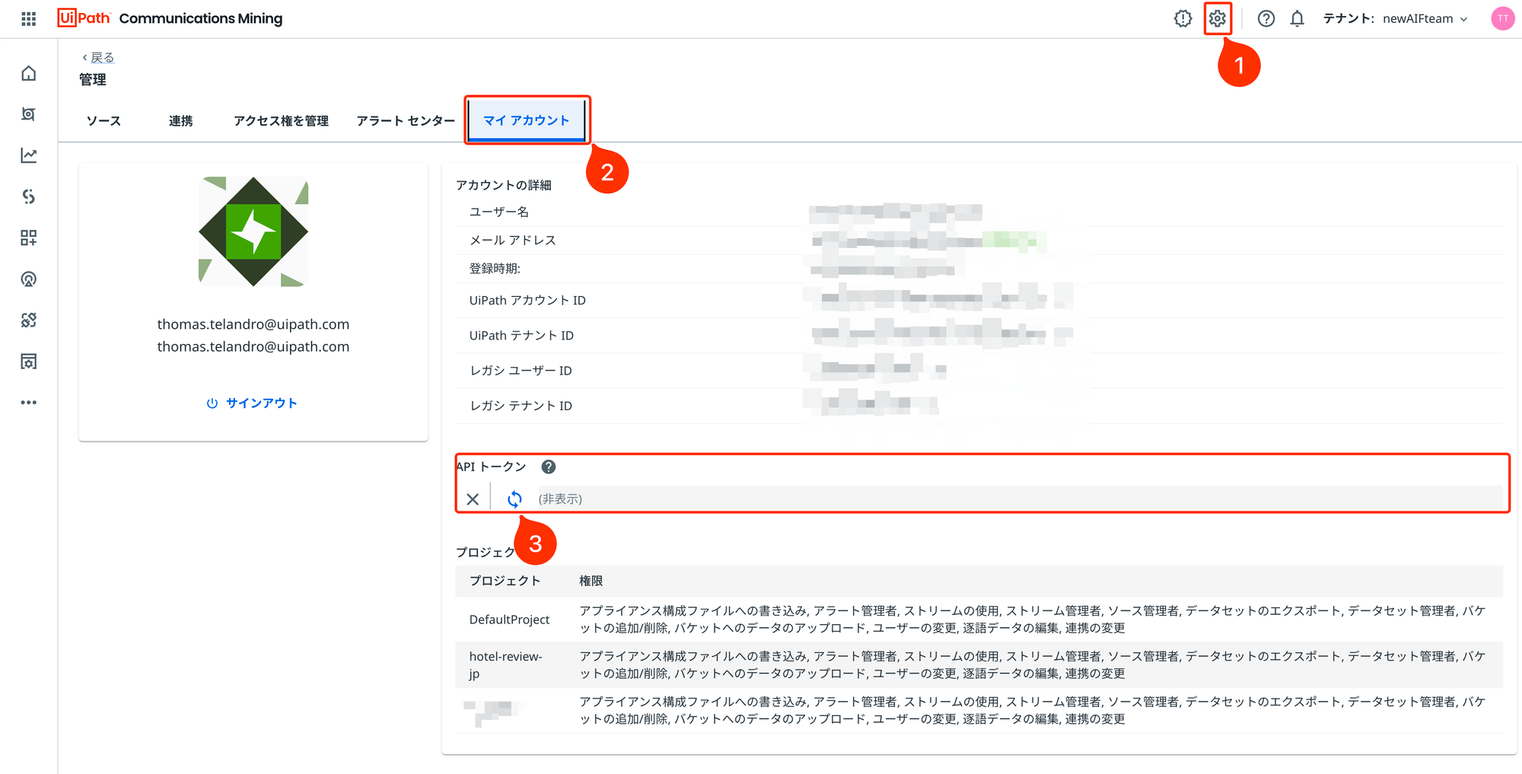
TOKENについて
# 環境変数にREINFER_TOKENを追加している場合は、以下の行を利用してください。
# TOKEN = os.environ["REINFER_TOKEN"]
# そうでない場合は、以下を利用してください。
TOKEN = "YOUR API TOKEN"
**TOKEN**はCommunications MiningのAPIトークンです。すでにお持ちの方はそれをお使いください。まだ持っていない場合は、以下のスクリーンショットのように生成することができます。
フィールドマッピングについて
フィールドのマッピングは以下のように行われる。
# フィールドマッピング
ID_REVIEW = 0
HOTEL_NAME = 1
REVIEWER_NAME = 2
REVIEWER_GENDER_AGEGROUP = 3
REVIEW_DATE = 4
REVIEW_SCORE = 5
REVIEW_URL = 6
REVIEW_TITLE = 7
REVIEW_PLAIN = 8
REVIEW_HTML = 9
フィールドマッピングでは、単純にカラム番号を変数にマッピングします。例として、ID_REVIEWはCSVファイルの最初のカラムです。これは上で定義したスキーマを反映しています。
CSVファイルのすべてのフィールドをマッピングする必要はありません。インポートしたいフィールドをCommunications Miningソースにマッピングするだけです。
user_properties について
では、user_propertiesを見てみよう。
"user_properties": {
"string:Hotel_Name": str(hotel_name),
"string:Reviewer_Name": str(reviewer_name),
"string:Reviewer_Gender": str(reviewer_gender),
"string:Reviewer_AgeGroup": str(reviewer_agegroup),
"number:Review_Score": int(review_score) if (review_score != '') else 0,
"string:Review_URL": str(review_url),
},
user_properties は、メッセージのメタデータとして Communications Mining に表示されます。このデータはモデルに使用されますが、検索やレポートダッシュボードなどのフィルタリングに活用することもできます。
これらは文字列 string または数値 number(intまたはfloat)でなければなりません。そのタイプによって、Communications Miningで適用できる機能(フィルタータイプなど)が変わります。
sync-raw-emailsのAPIについて
最後に、ここではAPI sync-raw-emailsについて見ていきましょう。
# データをCommunications Miningにアップロードする
def upload_batch(documents):
response = requests.post(
f"{BASE_URL}/api/v1/sources/{SOURCE}/**sync-raw-emails**",
headers={"Authorization": f"Bearer {TOKEN}"},
json={
"documents": documents,
"transform_tag": "generic.0.CONVKER5",
},
)
データをソースにアップロードする API には、sync と sync-raw-emails という 2 つのメジャーな API があります。
-
syncは、データにHTML形式が含まれていない場合に使用します。たいていの場合は、メール以外のデータをアップロードすることになるであろう。 -
sync-raw-emailsは、データにHTML形式や署名が含まれている場合に使用します。このAPIを通じてインポートされたデータは、HTMLのレンダリング対応や署名発見の前処理されます。Communications MiningはHTMLを正しくレンダリングし、署名を見つけ、メッセージのデフォルトビューから隠そうとします(表示にすることもできます)。
今回のケースでは、ウェブレビューをインポートしていますが、それらにはHTML形式の列が含まれていたため、sync-raw-emailsを使うことにしました。
syncを使用する場合、JSONフォーマット異なるので、注意してください。APIリファレンスはこちらで確認できます。
クイックリファレンス
Communications MiningのAPIs
-
Communications MiningのAPIs
- そこにはいくつかのチュートリアルと参照材料があります。
スレッド付きのデータセットについて
多くの場合(SFDC、電子メール)、メッセージはしばしばスレッドにグループ化されます。メッセージをリンクするために、データセットには同じスレッドのメッセージに共通のスレッドIDがあります。
以下では、スレッドを扱うために追加する必要がある行を強調表示しています。スレッドID列の名前が THREAD_IDとしましょう。
# [...]
# フィールドマッピング
THREAD_ID = 01234 # 値を保持する任意の列番号。
# [...]
def row_to_document(row):
# [...]
thread_id = row[THREAD_ID].strip() # <---- こちら
# [...]
return {
"raw_email": {
"body": {"html": review_html}
if html_body_exists(row)
else {"plain": review_plain},
"headers": {
"parsed": {
"Date": timestamp_str,
"From": reviewer_name,
"Message-ID": id_review,
"References": f"<{thread_id}>", # <---- こちら
}
},
},
"user_properties": {
[...]
},
}
現在、メッセージ付きのもう一つのシンプルなダミーのユースケースを準備中です。これらのケースを扱いやすくするために、近いうちにそれを共有します。
対応したいファイルがあれば、コメントにてお気軽にご相談ください。