かいつまんで言えば、「mecab-ipadic-NEologdがすごいという話」です。(すでに同名のタイトルの記事があったので別方向からアプローチしてみました。)
mecab-ipadic-NEologd
形態素解析ライブラリMeCabで最初に用いる辞書にmecab-ipadicがありますが、その辞書は2007年ごろに整備されたもので長らく更新されていませんでした。
インターネット上で公開されている最新のキーワード等を加えたmecab-ipadic-NEologdが公開されています。
文章の長さを取得する
本題です。
Wordなどには文章の文字数を表示する機能があります。
しかし、日本語は漢字とかなの入り混じった文章のため、文字数自体が文章の長さとは言い切れない場合があります。(それを利用して文字数を切り詰めたり、水増ししたりでき、Twitterや文字数規定のあるレポートなどでお世話になるわけですが…。)
特にスピーチをする場合、この文章はいったいどれぐらいの時間がかかるのだろう?となり、事前に何回か読むことで時間を計る必要が出てきます。(慣れた人であれば文章の文字数から大体の時間は推測できるらしいですが…。)
読み上げる際の長さを左右する要素を考えてみると、文章の長さを決定するのは読み仮名の長さとほぼ等しいと推測することができます。
従来のmecab-ipadicでは辞書に含まれない単語が出てくると不正確な読み仮名を割り当ててしまい、実用性があるとはいえませんでした。
しかし、mecab-ipadic-NEologdを用いるとほぼ正確な形で読み仮名を得ることができ、実用に足るツールとなりました。
SEPSpeechTools
v0.0.1(必ず2つのZIPをダウンロードしてください。また、設定から辞書(dict)を指定してください。)
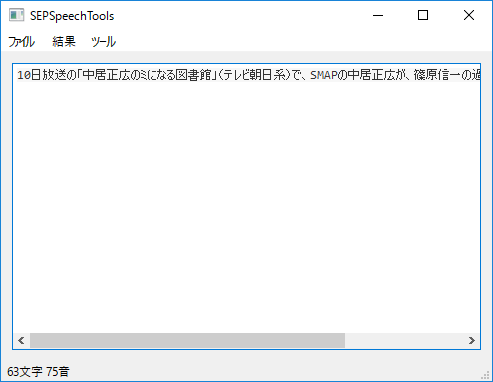
テキストボックスに文章を貼り付けると文章の文字数に加えて音数を表示します。
音数の算出方法は以下の通りです。
- 拗音(
ゃゅょ等)を0母音とします。 - 促音(
っ)を0.5母音として数えます。 - 記号のうち、句点(
。)や長音(ー)といったタイミングに関わるものを1母音として数えます。 - その他の記号は0母音として扱います。
- 読みの取得できない未知の単語については文字数をそのまま適用します。
どのように読み仮名を得たのかルビで確認する機能も付けました。
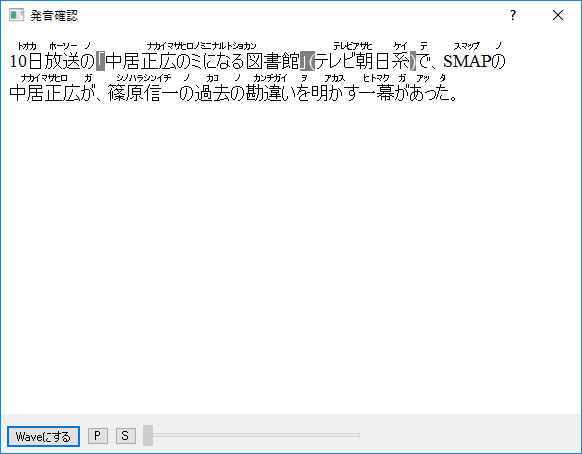
さらに、「Waveにする」ボタンを押すことで機械音声で読み上げたWaveファイルを出力する機能も付けました。
機械音声プログラムは棒読みちゃんに付いていた旧版のAquesTalkライブラリをハックして使ってみました。(旧版のライセンスをざっと読む限りは再配布可能であると理解したのですが、間違っていたら改めます。AquesTalk2というのも気になっているので…。)
ソフトウェアのライセンスはGPLv3で公開しています。
だいぶニッチなソフトウェアですがpull-reqや機能要望お待ちしています。