調べもの中にリンク切れページや、削除済みページに出会いすぎてイライラしてたのでchrome拡張機能の作り方の勉強のついでに404のページに対抗する拡張機能を作ってみました。
github: https://github.com/mugi111/page-not-found-detector
作り方
まずはmanifestファイルを作成していきます。
出来上がりは↓のようになります。
{
"manifest_version": 2,
"name": "404 DETECTOR",
"description": "",
"version": "1.0.0",
"content_scripts": [{
"matches": ["http://*/*", "https://*/*" ],
"js": ["script.js"],
"css": ["style.css"]
}],
"background": {
"persistent": true,
"scripts": ["background.js"]
},
"browser_action": {
"default_title": "404 detector",
"default_popup": "popup.html"
},
"permissions": [
"tabs",
"webNavigation",
"background",
"http://*/*",
"https://*/*"
]
}
下がそれぞれの項目の詳細です。
| プロパティ名 | 概要 | |
|---|---|---|
| manifest_version | マニフェストのバージョン | |
| name | 拡張機能の名前 | |
| description | 拡張機能の説明 | |
| version | 拡張機能のバージョン | |
| content_script | matches | スクリプトの読み込みを行うページの指定 |
| js | 読み込まれるjavascript | |
| css | 読み込まれるcss | |
| background | persistent | 永続化の有無 |
| scripts | バックグラウンドで読み込まれるスクリプト | |
| browser_action | default_title | バーに表示されるときの名前 |
| default_popup | バーのアイコンをクリックしたときに開くhtml | |
| permissions | 拡張機能に与える権限 |
当初の予定
最初はgoogleの検索結果一覧のリンクに対して存在しないリンクに対してマークをつけようとしていました。
こんな感じでcontent_scriptで指定したscript.jsから、リンクのリストをchrome.runtime.sendMessageを使用してbackground.jsに送信していました。
background.jsのほうでchrome.runtime.onMessage.addListenerで設定しておくことでchrome.runtime.sendMessageを拾うことができるようになります。
ページの存在の確認については、XMLHttpRequestでレスポンスのステータスコードを見ることで確認しようとしてました。
var atags = document.getElementsByTagName("a");
var hrefs = [];
for (let index = 0; index < atags.length; index++) {
href = atags.item(index).href;
chrome.runtime.sendMessage({href});
hrefs.push(atags.item(index).href);
};
console.log("hello", hrefs);
const ping = (url) => {
var xhr = new XMLHttpRequest();
xhr.onreadystatechange = () =>{};
xhr.open("GET", url, true);
try {
xhr.send(null);
} catch (err) {
console.log(err);
}
}
chrome.runtime.onMessage.addListener(
async function(request, sender, callback) {
console.log(request);
ping(request.href);
}
);
結果
ここで何が起こったかというと、、、
見慣れたあいつが出てきました。
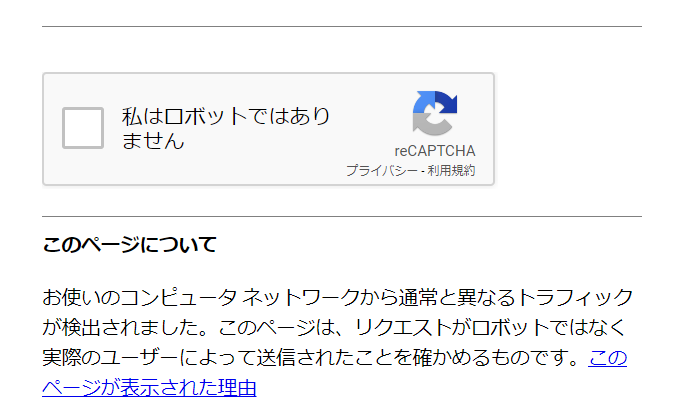
「お使いのコンピュータ ネットワークから通常と異なるトラフィックが検出されました。このページは、リクエストがロボットではなく実際のユーザーによって送信されたことを確かめるものです。」
だそうです。。
引っかかったところ
最初script.jsからリクエストを送信していたところ、
CORB(Cross Origin Read Block)ではじかれまくりました。

回避策
background.jsからリクエストを送ることで回避できました。
別の案
ここでそこら辺のリンクに無差別にリクエストを投げるのはやめようと思い、飛ぶ先のリンクだけに絞りました。
chrome.webNavigation.onCommitted.addListenerでwebNavigationのonCommittedを拾うようにしました。
webNavigation参考ページ
ページの存在の確認は当初の案と同じ方法をとりました。
ステータスコードが404だった場合はtabIdを指定してgoBackメソッドを呼び出すことでブラウザバックさせています。
urlはurlMacthesでhttpかhttps(一般的なページ..?)のみを拾うようにしました。これは、chrome://settingsやchrome://extensionsのような特に拾わなくていいようなページを除外したかったためです。
const ping = (url) => {
var xhr = new XMLHttpRequest();
xhr.onreadystatechange = () =>{};
xhr.open("GET", url, false);
try {
xhr.onload = function () {}
xhr.send();
return xhr.status;
} catch (err) {
console.error(err);
}
}
chrome.webNavigation.onCommitted.addListener((details) => {
if (details.frameId !== 0){
return;
}
const status = ping(details.url);
console.log(status);
if(status === 404) {
chrome.tabs.goBack(details.tabId);
}
}, {url: [{urlMatches: "http://*/*"}, {urlMatches: "https://*/*"}]});
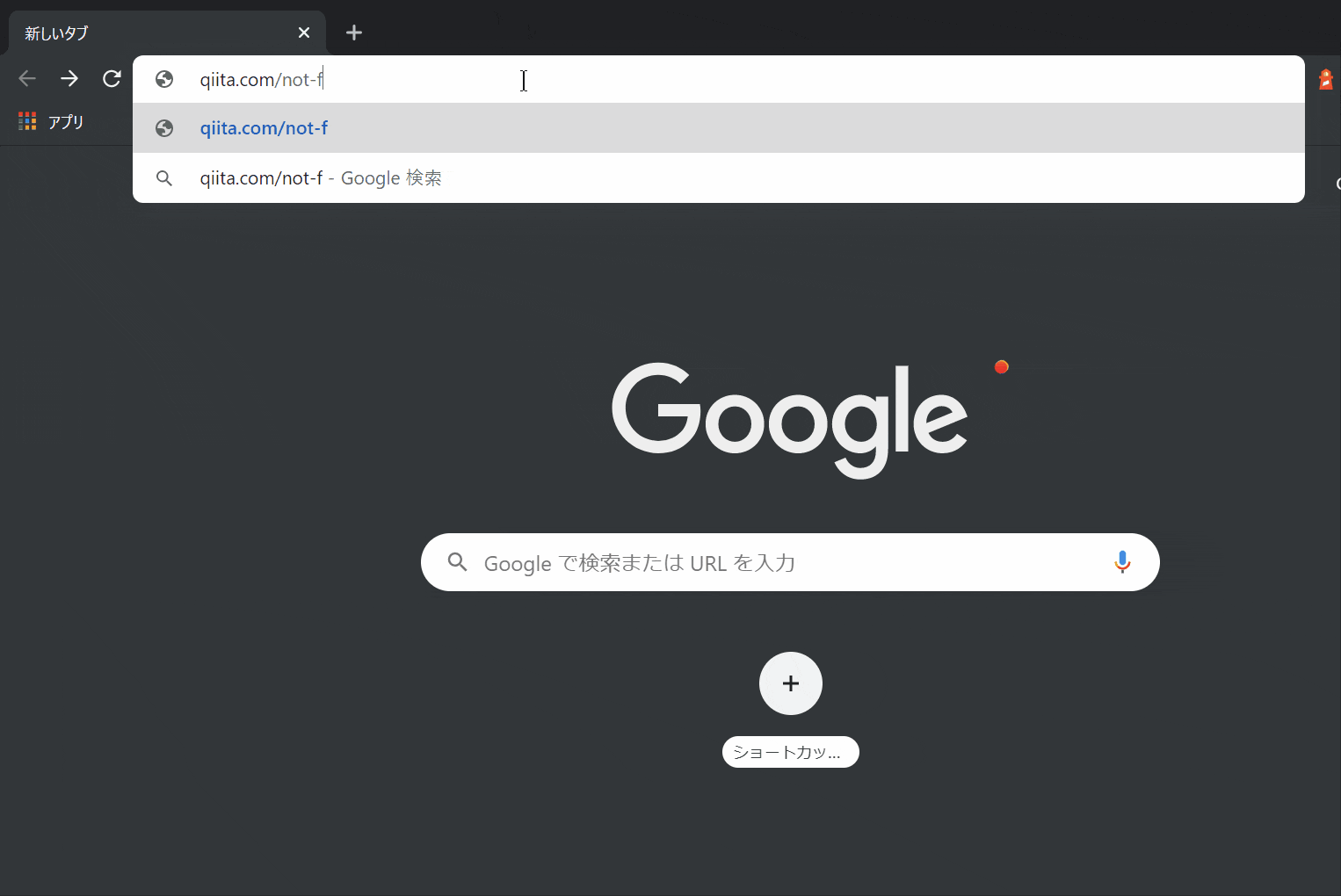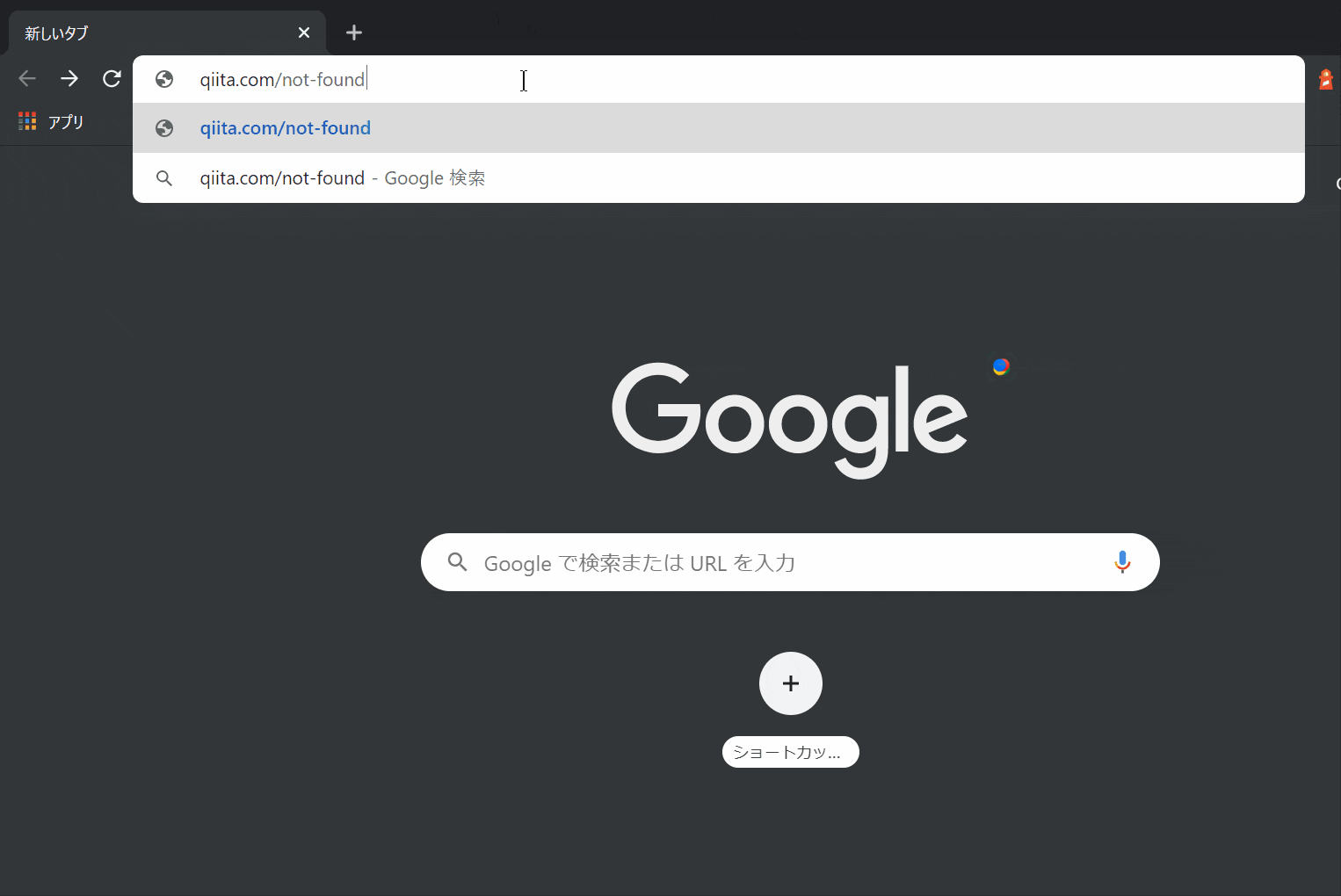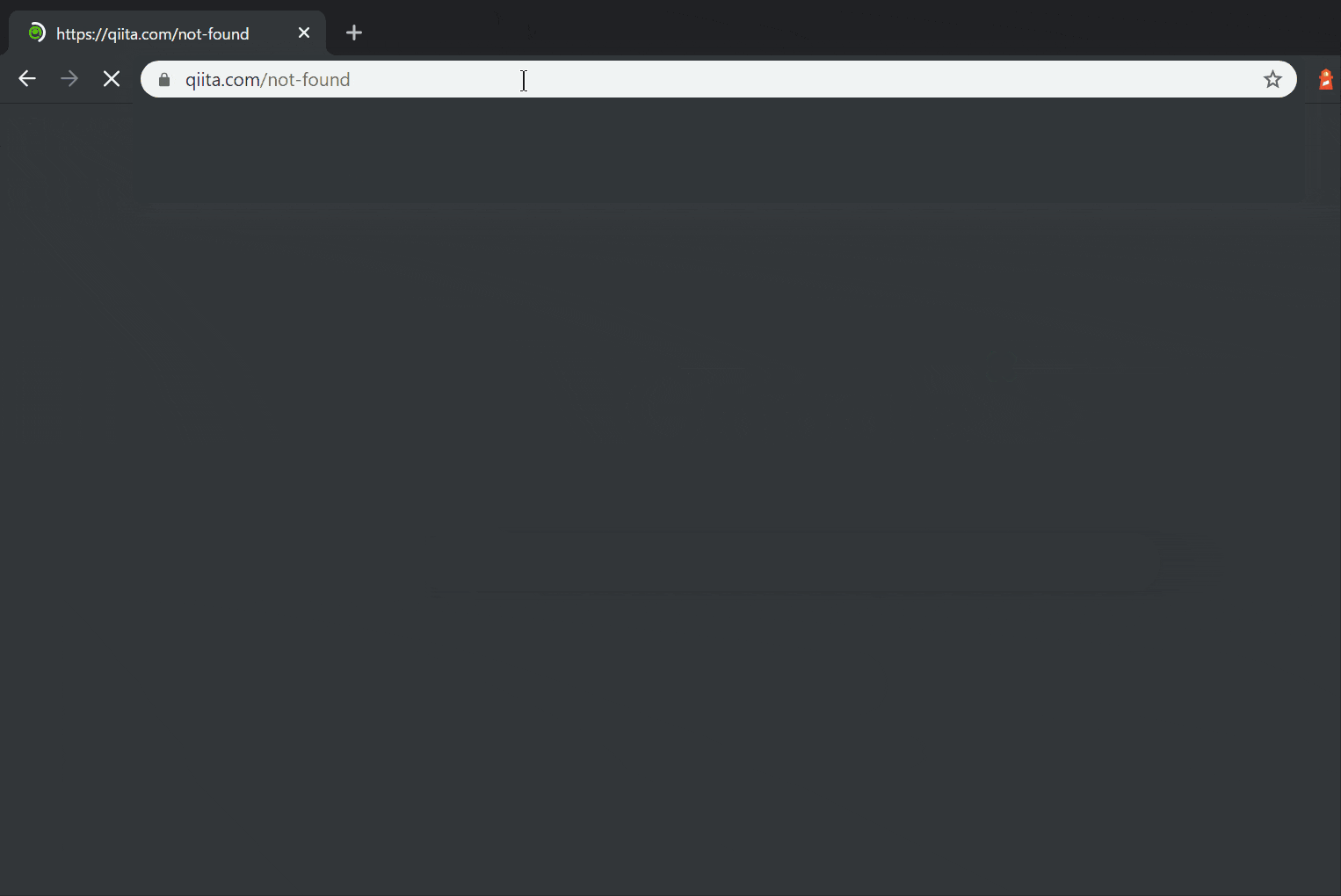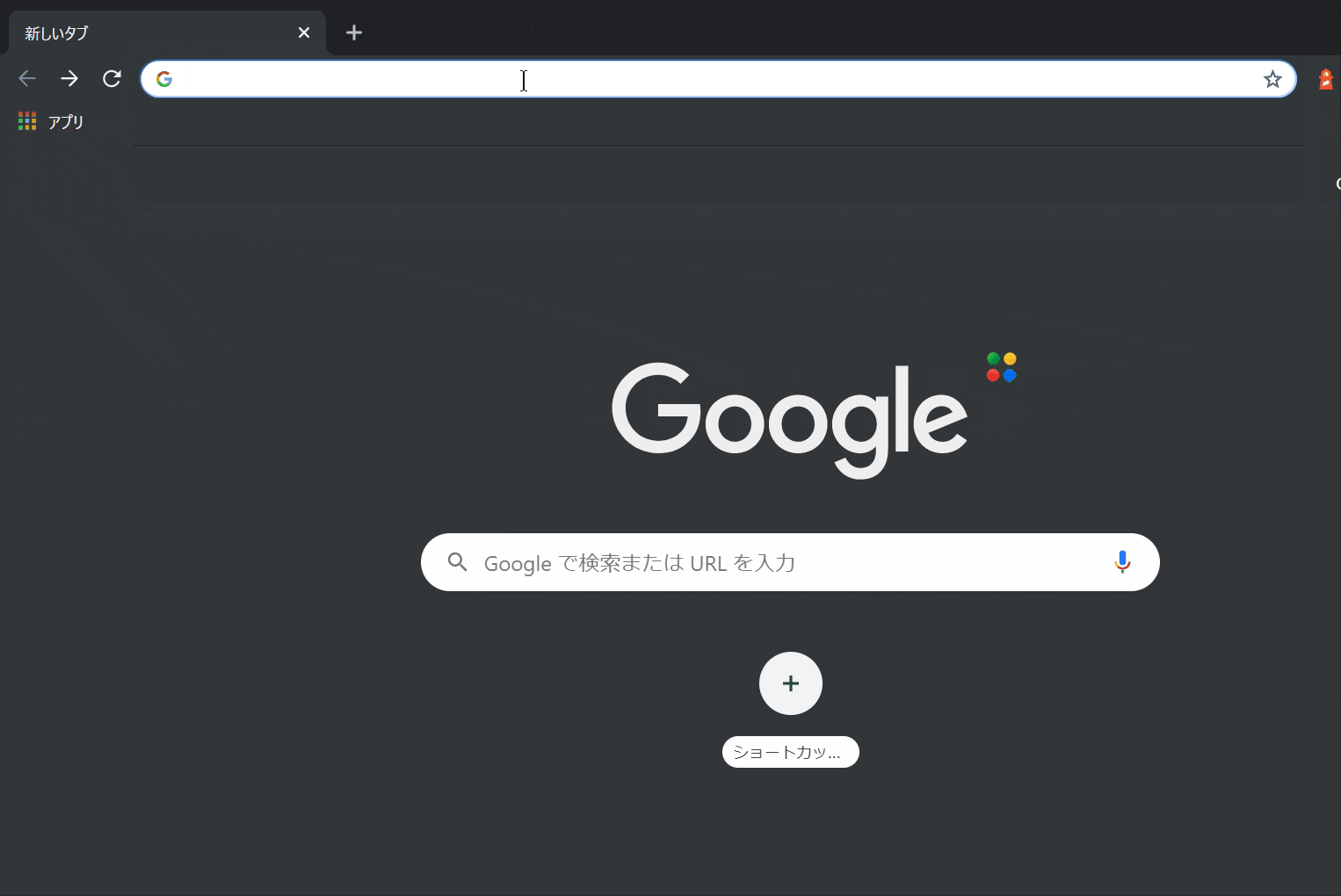
動作はこんな感じです。
存在しないページに飛ぼうとすると強制的にブラウザバックされます。
これでキーボードを壊す心配もありません。
