0. TL;DR
イベントで32ビットマイコンをいただいたので一通りのチュートリアルを完了させました。
チュートリアル中ではDeepGestureプロジェクトが引用されており、自分の理解の整理のために、このチュートリアルの全体感を書き出します。
DeepGestureの機能拡張とかIoT化に取り組みたいと思っているのですが、それらは今後の課題です。
1. はじめに
ウェアラブルってロマンがありますよね。ITコンサル業に携わっていると、最近はウェアラブルデバイス上で推論を行うことが当然のような空気すら感じます。ウェアラブルではないのですが、ちょうど仕事でIoTのエッジ側で推論を行う案件を手伝うことになりました。そんなころ、connpassでちょうどいい感じの勉強会を見つけました。
プレゼント有!超小型STM SensorTile Kit 組込Edge AI体験ハンズオン!
基本的にプログラミングセンス皆無の私ですが、ハンズオンならコピペで乗り切れるかなという邪な気持ちもありつつ、まぁひとつの勉強だと思い参加しました。
初心者なので、内容の拙さについてはご容赦ください。
理解度は「完全に理解した」の2歩前くらいかなと思っています。
2. 前提知識
間違えたっていいじゃないか 人間だもの
2.1 DeepGestureって何?
元論文が手に入らなかったので、GitHubのソースを見てください。
↓つまり、ウェアラブルデバイスの加速度センサー(ACC)とジャイロセンサー(GYRO)からそれぞれxyz軸の成分を取り出し(つまり6種の時系列データを利用して)、9種類の動作を識別するというもので
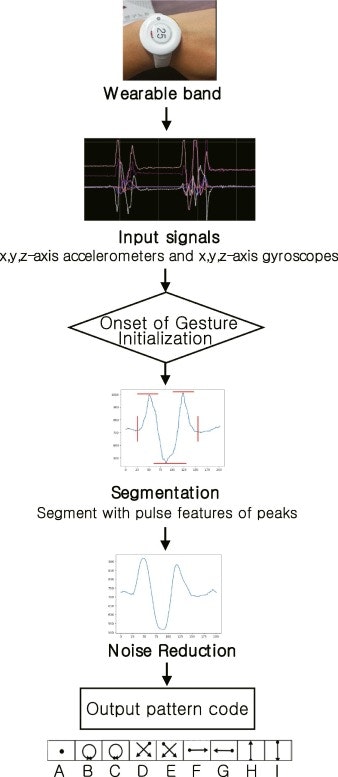
↓こんな感じのNeural Networkを設計して
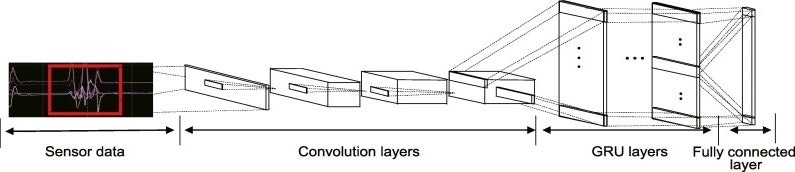
↓こう実装されたものであるようです。
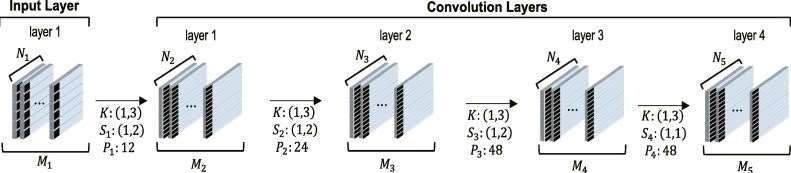
解説を放棄したとか言わないで(汗)
2.2 STM32って何?
STM32は、STMicroelectronics社の32ビットマイコンのファミリです。STM32Cubeという必要なソフトウェア一式や開発環境が整備されており、文書も公式から潤沢に提供されており、非常にディベロッパーフレンドリーなマイコンのようですね。
今回は、イベントでいただいたSTM32L476RGT6というボードとSTEVAL-STLKT01(以下、SensorTile)というたくさんのセンサが乗った開発キットを使っています。
ただ、マイコン未経験者としては、このあたりのの関係性がよくわかりません。STEVAL-STLKT01はセンサ集まりということですが推論をするにはこれだけあれば十分なので、STM32L476RGT6はソースのデプロイをする際にPCとSensorTileを繋ぐ役しか果たしていないような...?
↓SensorTileは腕時計のように装着します。(この画像は広いもので私の腕ではありません。)

3. 動作方法
もしもこれらのマイコンを持っている方がいれば、勉強会のサイトで公開されている資料を見れば、一通りは理解できると思います。
ざっくりと、
- STM32CubeIDEで、STM32 Firmwareをビルドする(この時にデプロイもされるよう)
- スマホアプリ"ST BLE Sensor"でSensorTileと接続し、ログを残すセンサーとラベルを設定する
- SensorTileを身に着けて動く(アプリで現在の推論結果がわかりますが、イマイチなところとして現在のバージョンでは最大で6ジェスチャまでしか推論結果が表示できません。しかも、結構なラグがあるように思います。)
- ログが保存されたmicroSDカードをPCに繋ぎ、train_model.pyをのインプットデータに加えてretrainする
- 生成されたNN_gesture.h5をSTM32CubeIDEのプロジェクトに加え、STM32 Firmwareを再ビルドする。
- 以降、ステップ2~5を繰り返す
小さなハマりどころはいくつかありましたが、今回は割愛しています。文字にすると超ざっくりですね...
4. 学習過程
学習はNN_model_Keras.py
の中で行っています。下が主要な処理ですね。
from keras.models import Sequential
from keras.layers.core import Dense, Activation #, Dropout
from keras.layers.recurrent import LSTM #, SimpleRNN
from keras.layers.wrappers import TimeDistributed
from keras.layers import Convolution2D,Dropout,Flatten ,Reshape, Bidirectional, Lambda, GRU, Permute
from keras.layers.normalization import BatchNormalization
# from keras.callbacks import ModelCheckpoint
# import os
# import datetime
## Model
def create_model(args):
#k: kernel size, s: stride, @: channel
#conv1: k1x5s1x2@6
#conv2: k1x3s1x1@12
#conv3: k1x3s1x1@12
#conv4: k1x3s1x2@24
#conv5: k1x3s1x1@24
#conv6: k1x3s1x2@32
#conv7: k1x3s1x1@32
#gru1,2,3,4: h256@16
#FCN: 256
hyperparams = [[6,5,2],[12,3,1],[12,3,1],[24,3,2],[24,3,1],[32,3,2],[32,3,1]]
model = Sequential()
for param in hyperparams:
model.add(Convolution2D(filters=param[0], kernel_size=(param[1],1), strides=(param[2],1),
padding="same",
input_shape=(args.seq_length,args.n_axis, 1)))
model.add(BatchNormalization())
model.add(Activation('tanh'))
model.add(Dropout(0.25))
#model.add(Permute(dims=(2,1,3)))
model.add(Reshape((model.output_shape[1], model.output_shape[2] * model.output_shape[3])))
for i in range(args.n_layers - 1):
model.add(BatchNormalization())
model.add(GRU(args.n_cells, return_sequences=True))
model.add(BatchNormalization())
model.add(GRU(args.n_cells, return_sequences=False))
model.add(BatchNormalization())
model.add(Dropout(0.25))
model.add(Dense(args.n_classes, activation='softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.summary()
return model
上記のスクリプトは部分抜粋&コメントを一部訂正しています。ネットワーク構成は元論文の画像と異なりますね。ソースのコメントを察するに、かなり苦労してチューニングしているように見えます。チャネル数が全体的に減った一方、畳み込み層が4層→7層に増え、結果的に計算量は増加しているはずです。。。
精度の違いも検討してみたいところですね。
時間が確保できなかったので、本日はここまで!
4. おわりに
うまく時間を工面できず、なんとも半端な投稿になってしまい残念です。とはいえ、多少なりとは技術的な内容で、Advent Calendarに参加できてよかったです(小並感)
折角なので誰かの参考になればいいなと思います!
後編に続く(はず)。