はじめに
こんにちは、mucunです。
この連載では、「機械学習」をなるべく直感的で分かりやすく説明することを心掛けています。
まだ「機械学習」のことを知らない人も、知ってはいるけども知識に自信が無い人も、この連載を通して理解を深めてもらいたいと思っています。
今回の記事は、「機械学習」の発展を支えるコンピュータ技術の進歩について触れたいと思います。
昨今になって、「AIブーム」と囃し立てられ注目を浴びている「機械学習」のルーツは意外に古く、最近の流行はむしろコンピュータ技術の発展が原動力となっているところが大きいです。
この記事を読むことで、その辺りの事情通になってもらえればと思います。
かつてのIT黎明期がそうであったように、「AIブーム」は世界的に乗らなくてはならない波となっています。
「IoT(Internet of Things)」と併せて、それによって「第4次産業革命」が起こると言われているほどです。
そんな、世界的な大ムーブメントと「機械学習」との関係性についても、この記事で触れたいと思います。
コンピュータの使い途を追求した結果が、「機械学習」というアルゴリズム
コンピュータがそもそも生まれたのは、計算の自動化・高速化のためです。
今となっては考え難いですが、昔はコンピュータどころか電卓すら無かったので、全て人間が手動で計算する他なかったのです。
現代では、至る所でコンピュータが計算を代行してくれています。
なんとまあ便利な世の中になったものです。
とはいえ、全ての計算をコンピュータが代行してくれている訳ではありません。
いわゆる単純計算、例えば「1+9=[?]」の解を求めるような計算は代行してくれていますが、依然として複雑な計算、例えば「[?]+[?]=10」の解を解くような問題は、まだまだコンピュータでの実現ができていません。
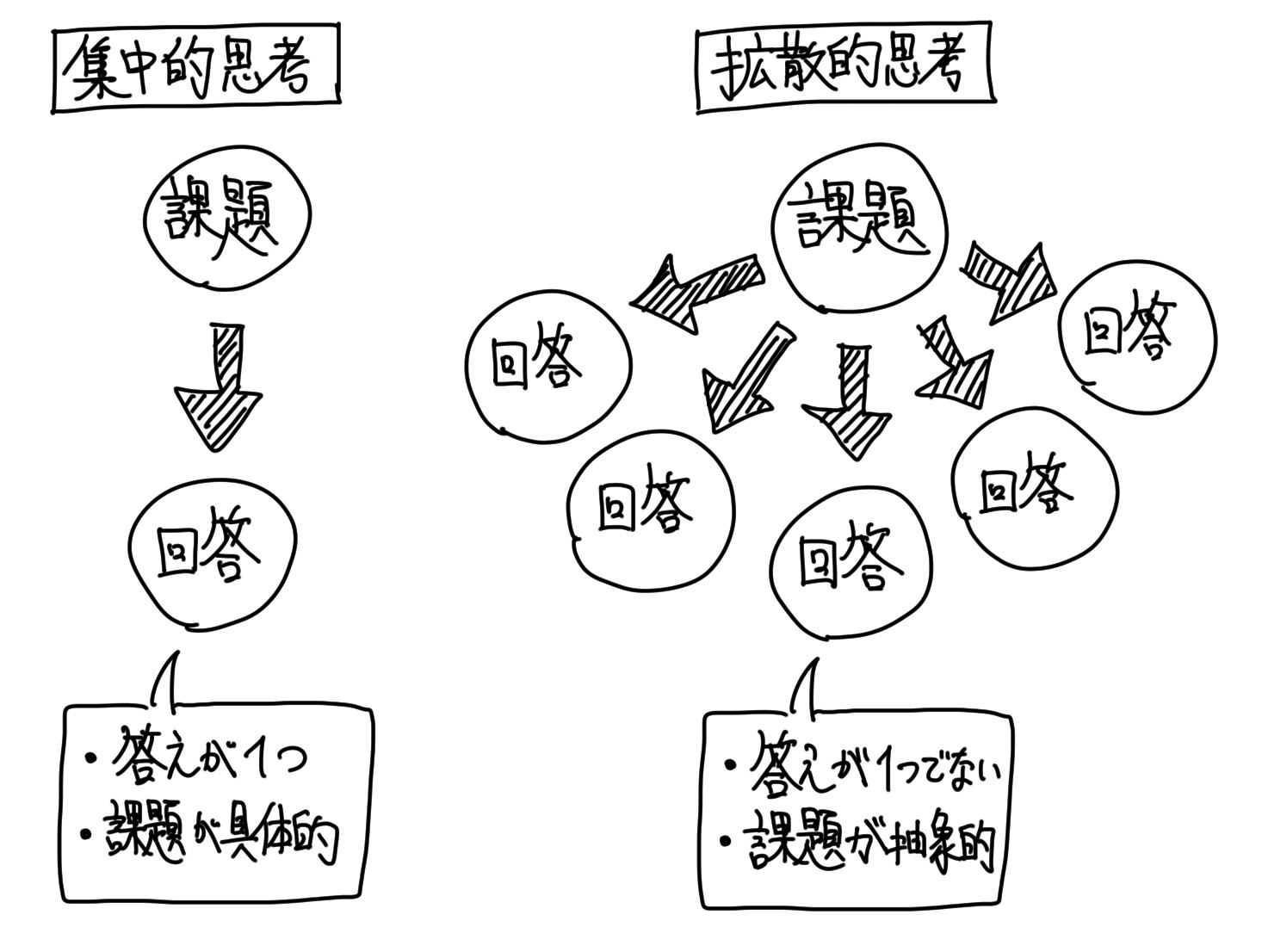
これを第3回の記事では、集中思考・拡散思考という表現を使い、説明をしました。
機械は「1+9=[?]」を解くような集中思考は得意だが、「[?]+[?]=10」を解くような拡散思考は苦手なのです。
しかし、この課題をアルゴリズムという考え方が解決しつつあります。
アルゴリズムとはザックリ言うと、「人間が複雑に捉えている計算を、単純な計算の積み重ねに置き換えること」で、それによってコンピュータ上で複雑な計算を実現することができるようになるのです。
この辺りの話は、第2回の記事にて話をさせてもらいました。
そして、アルゴリズムの中でも、上級レベルのアルゴリズムとして「機械学習」があります。
従来、アルゴリズムは人間が設計をして、人間がプログラムに書き起こして、コンピュータに実行をお願いしていました。
しかし、「機械学習」はその設計とプログラム実装すら、コンピュータに行ってもらおうというものです。
言ってみれば、ある種のアルゴリズムを自動的に構築するアルゴリズム、ということになります。
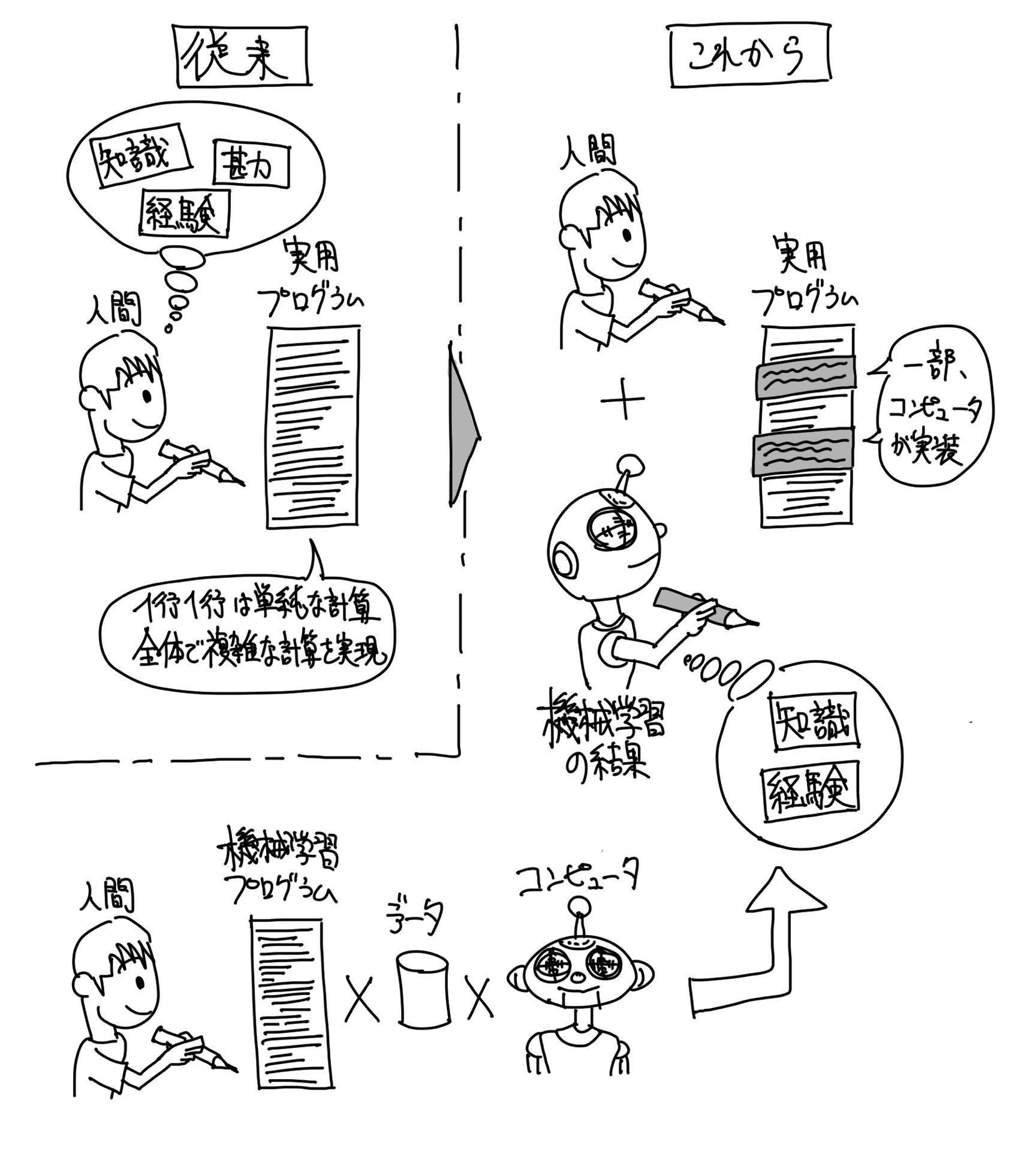
「機械学習」のアルゴリズムについては、それを実行方法を人間が考えて、人間がプログラムに書き起こす必要があるものですが、昨今になってそのプログラムがどんどんと無料でWEB開放されてきています。
最新のアルゴリズムが論文とセットでリリースされることも多く、「機械学習」を行いたい人がプログラムを1から書き上げる必要が無くなってきているのです。
シェア文化というか、オープンソース文化ですね。
この流れによって、人間が従事している仕事はどんどんコンピュータに置き換えられていくと言われています。
特に集中思考型の仕事は、真っ先に置き換えられるでしょう。
人間の仕事はコンピュータに奪われてしまう形になります。
そうした時に、人間に求められるのは、更なる優れたアルゴリズムの構築です。
アルゴリズム構築は、いわば状況の先読みと対処を積み上げていく作業です。
いかに複雑なアルゴリズムを構築し続けられるかが、コンピュータとの差別化要素となってくるでしょう。
具体的な数値で見るコンピュータ技術の発展
コンピュータも、直ぐに今の形のような高性能なものであった訳ではありません。
昔は計算速度が遅くて、「機械学習」に必要な計算を現実時間内に終わらせることは夢のまた夢でした。
wikiのスーパーコンピュータ技術史によれば、1964年にアメリカで作られたスーパーコンピュータ「CDC 6600」の計算速度は3MFLOPSだったそうです。
FLOPSは「FLoating point Operations Per Second」の略で、1秒間に浮動小数点演算が何回できるかを表したものです。
この値が大きいほど計算速度が速いということになります。
尚、基本的には理論値(このぐらいの速度が出るだろうという推定値)で求められますが、実測する場合には掛け算と足し算を同数ずつ実行します。
M(mega)は、1Mが「$10^6$」という数値を表す記号なので、およそ50年前の1964年のスーパーコンピュータは、1秒間の浮動小数点演算回数が3×「$10^6$」=300万回だったということです。
そして、なんとお値段は800万ドルもしたそう。
とても仕事用に従業員に配れるレベルではありません。

しかし、値段が高いとはいえ、50年前でも1秒間に300万回も計算ができたのか、、、と、関心してしまう人も多いかと思います。
ですが、その関心は現代のコンピュータの値段と計算速度を知ると吹っ飛びます。
現代のコンピュータは、10万円位の一般のコンピュータの計算速度でも、3MFLOPSの1,000倍である3GFLOPSを優に上回ります。
ちなみに、1G(giga)は、「$10^9$」を表す記号です。
値段も計算速度も全くスケールが変わってしまっているのです。
そして、現代のスーパーコンピュータについては更に桁が違います。
2017年6月時の世界のスーパーコンピュータランキング1位は、中国の「Sunway TaihuLight(神威太湖之光)」で、その計算速度はなんと93PFLOPSです。
1P(peta)は、「$10^15$」を表す記号です。
つまり、50年前のスーパーコンピュータの310億倍高速になっているのです。
そんなコンピュータの計算速度向上が、「機械学習」の実現を支えています。
「機械学習」は一般にかなりの計算量を要するものです。
それこそ一昔前までは、スーパーコンピュータでないと計算が現実時間内に終わらない、というレベルの計算量でした。
しかし、過去のスーパーコンピュータが、現代においては安価に手に入る為、その限りではなくなってきました。
現代は、誰でも「機械学習」を実行できる時代になってきているのです。
参入者が増えることで急速に進化した「機械学習」アルゴリズム
誰でも「機械学習」が実行できる時代になって、「機械学習」のアルゴリズムが急速にしました。
「機械学習」アルゴリズムの精度向上を研究する場合、「機械学習」をして、その精度を測定し、更なる精度向上に向けてのアイデアを考え、それを適用して再び「機械学習」をし、、、という繰り返し、「研究サイクル」が必要になります。
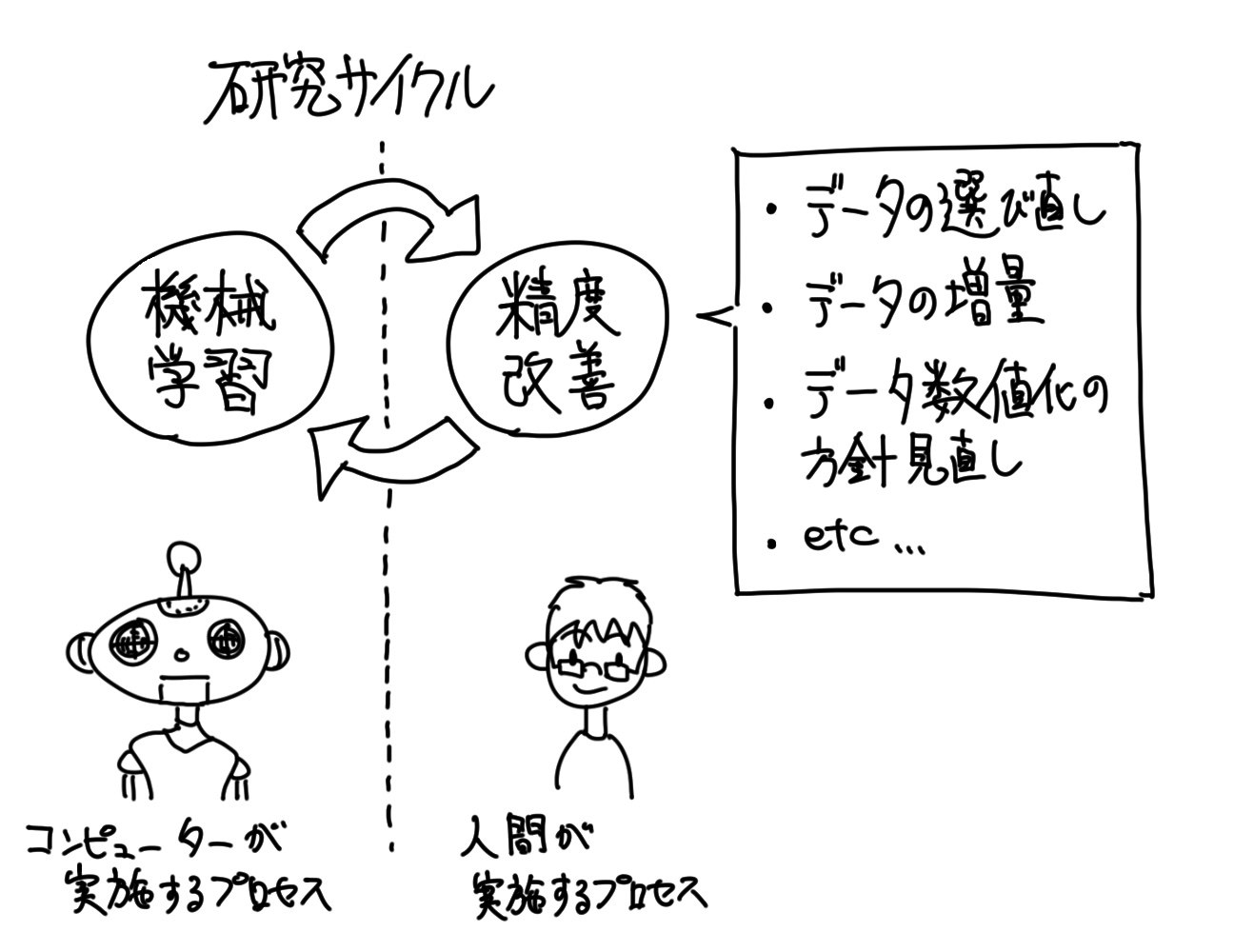
そうして色々なアイデアを試すことで、精度向上を実現させるアルゴリズムが生まれていくのですが、その際に「研究サイクル」のスピードは非常に重要です。
「研究サイクル」を一回回すのに30分かかる場合、研究に24時間かかりっきりでも48回しか「研究サイクル」を回せません。
しかし、「研究サイクル」を一回回すのに3分しかかからない場合には、2時間ちょっとで100回の「研究サイクル」を回すことができます。
更には、「研究サイクル」を一回回すのに10秒しかかからない場合には、20分弱で100回の「研究サイクル」を回すことができ、1日の間に十分なアイデアを試せるようになります。
「研究サイクル」を1回回すのにかかる時間の内、「機械学習」のプロセスにかかる時間は、完全にコンピュータの計算速度に依存します。
そして、旧来のコンピュータの計算速度においては、「研究サイクル」における「機械学習」にかかる時間の方が比重が大きく、ボトルネックとなっていました。
しかし、現代ではコンピュータの計算速度が向上した為、逆に人間の「精度改善」の方がボトルネックになってきています。
そういう状況になると、「精度改善」のアイデアをいくつ生み出せるかというアイデア勝負になってきます。
そして、一般のコンピュータでも機械学習を行えるようになってきている現代においては、誰でもそのアイデア合戦に参戦することができるようになってきているのです。
arXivという世界的に有名な論文投稿サイトがありますが、そこでの「機械学習」関連論文の投稿数について調べてくれているサイトがありました。
以下の図が、「機械学習」関連論文投稿数の推移です。
<出典:https://medium.com/@karpathy/a-peek-at-trends-in-machine-learning-ab8a1085a106>
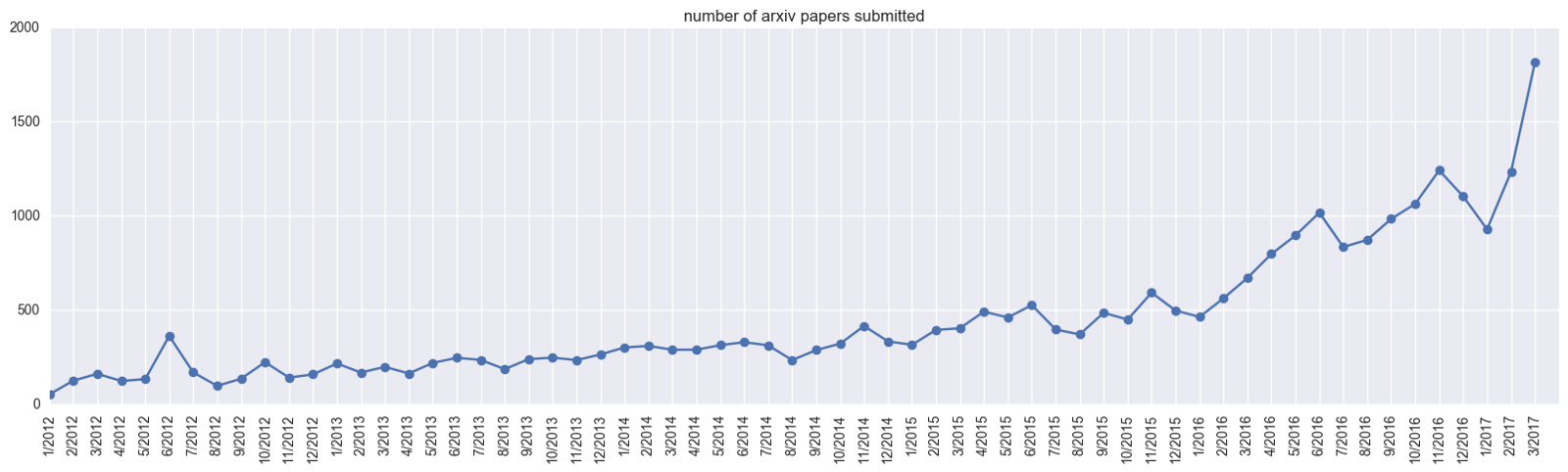
横軸が時間で、2012年1月から2017年3月までの期間を示しています。
縦軸が、概ね「機械学習」関連の論文数を示しています。
2012年1月というと、既に「AIブーム」が始まっていますが、その時と比較しても2017年まででどんどん投稿数が増えています。
別の記事もありました。
投稿先等について詳しいことは書かれていませんが、1996年から2016年までで論文の数が9倍に増えているという記事です。
<出典:https://www.weforum.org/agenda/2017/12/charts-artificial-intelligence-ai-index/>
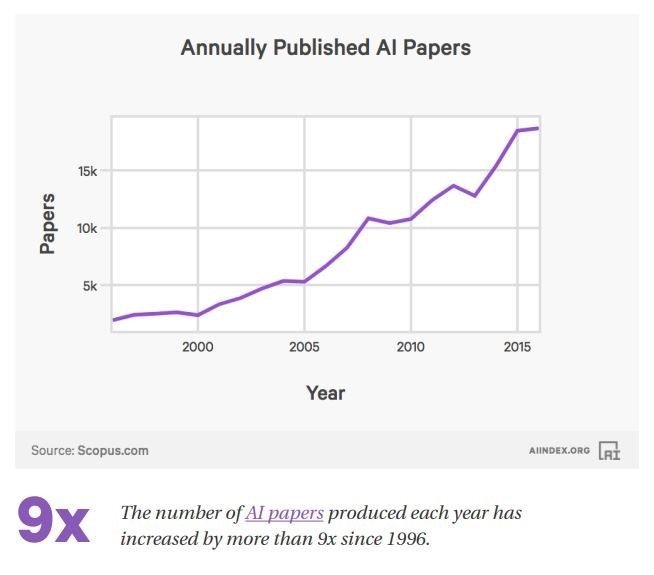
コンピュータの計算速度向上と低価格化によって、このような状況が生まれ、それに伴って「機械学習」アルゴリズムもどんどん進歩しているのです。
「機械学習」との関係性が深い「IoT(Internet of Things)」
「AIブーム」を後押しする要素として、「IoT(Internet of Things)」があります。
「IoT(Internet of Things)」とは、今までアナログで動いてきた機械やモノにセンサーを繋いで、それらの状態をデジタルデータにて管理をし、更にそれらをインターネットに繋げるなどして情報連携を行うことで、互いに連携・制御し合う仕組みのことを言います。
センシング技術とネットワーク技術の発達により、この発想が生まれました。
例えば、工場の機械や、家庭の家電製品などの状況が、全てデジタルデータで収集・管理されて、互いに連携・制御し合うのです。
工場の機械が異音を発し始めたら、それを収音センサーが感知してメンテナンス推奨へと繋げたり、スマホの位置情報と家電が連携して、家に帰ってくる時点で自動的に部屋が温まっていたり、お風呂が沸いていたりするようなイメージです。
テーマごとに「Smart Factory」や「Smart House」など、「Smart 〇〇」と表現したりします。
「Smart 〇〇」に関する良い画像があったので、それを引用させていただきます。
「IoT」については、ただデータを収集・管理するだけでは勿体ないと言われており、そこに「機械学習」を絡めることで真の価値が発揮されると言われています。
上手くデータを使って、機器の故障を未然に予測したり、生産プロセスの最適化をしたりすることが期待されています。
そうして、「機械学習」と「IoT」がセットで注目されています。
「IoT」×「機械学習」=「第4次産業革命」
特に製造業に関わる「IoT」については、「IoT」×「機械学習」で「第4次産業革命」が生まれると言われています。
かつて、「第1次(蒸気機関)」・「第2次(電気技術)」・「第3次(エレクトロニクス)」と、人間を様々な労働から解放してきた「産業革命」ですが、「第4次産業革命」は更なる労働の解放をもたらすと言われています。
ちなみに、wikiの絵がパッと見で分かりやすいので引用させていただきます。
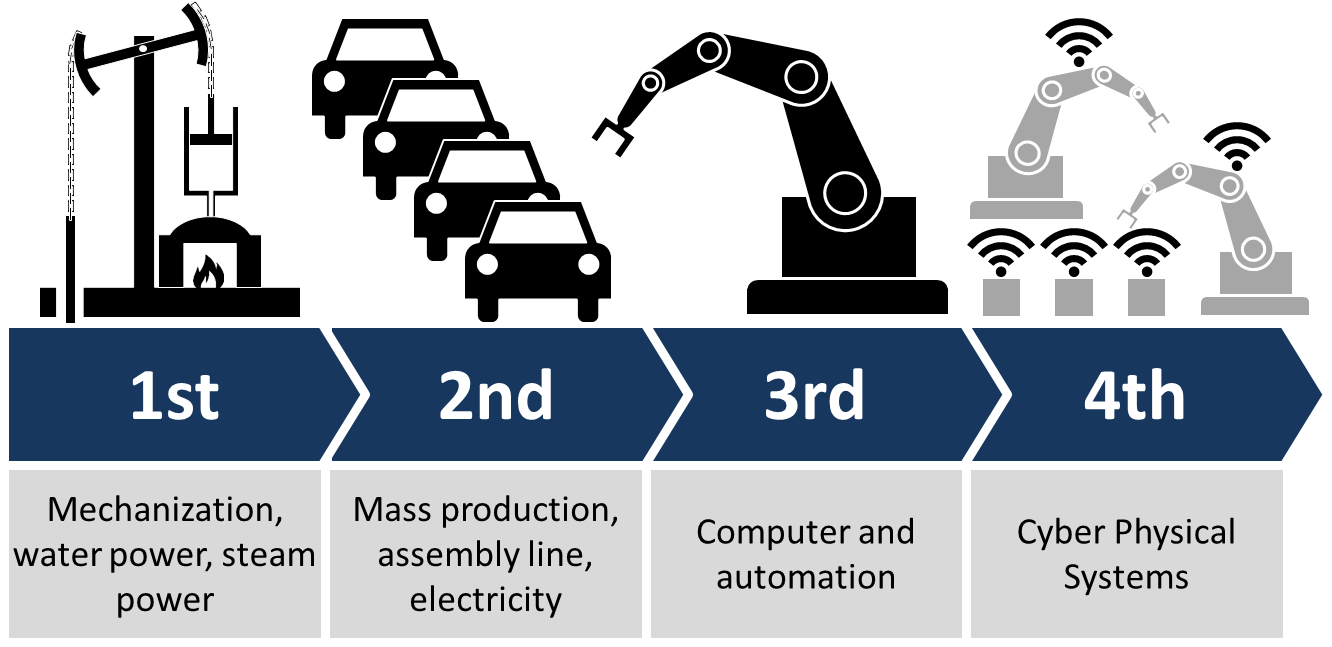
先程も説明したように、「機械学習」によって人間の仕事の大半が置き換えられようとしています。
それが特に製造業において如実に現れるであろうと言われているのです。
対象は、集中思考型の作業です。
一度コツを掴んでしまえば、後はその反復というような作業が、集中思考型の作業になります。
既に一部の作業については、ロボットによるオートメーションが進んでいますが、それは人間が愚直にアルゴリズムを設考えて作り上げたものに関してです。
これからは、これまで上手くアルゴリズムに落とし込めなかった作業が、どんどん「機械学習」によってアルゴリズムに落とし込まれることが期待されています。
過去にもあった「AIブーム」
今正にホットな「AI」・「機械学習」ですが、過去にもそのブームはありました。
しかし、考案されたアルゴリズムに、かつてのコンピュータは計算速度で付いて来れなかったために、ブームは去っていきました。
理論は間違っていなかったのですが、それを現実時間内に終わらせる手段が無かったのです。
それはそれは、「絵に描いた餅」と揶揄されたそうです。
(「AI」や「機械学習」という言葉は、微妙にニュアンスが違う言葉なのですが、その整理については、別の回で説明をさせていただきます…)
そして、今再びの「AIブーム」という訳ですが、どうもバブルではなさそうな雰囲気です。
先程来説明してきたコンピュータの進化が、強くブームを支えているのです。
しかし、コンピュータの速度が「機械学習」を行うに十分な速さか?と問われると、私の感覚では正直なところ時期尚早という感覚を持っています。
特にデータ量が多い場合や、複雑な「機械学習」を実施する際などは、一般のコンピュータのスペックではなかなかな時間がかかってしまいます。
研究サイクルがなかなか回せず、取り組むのがツラい課題というものが、割と多く存在します。
それでも、今回の「AIブーム」はバブルじゃないと、私も感じているのですが、その理由はコンピュータ性能に加えて、別の理由だと思っています。
今回の「AIブーム」がバブルじゃなさそうな3つの理由
今回の「AIブーム」がバブルじゃなさそうな理由として、私は以下の3つがあると思っています。
- 「従来技術がちょうど煮詰まっていたから」
- 「差別化を図りたいシステムエンジニアとプログラマーが本気でキャッチアップをしているから」
- 「AIの本質的な面白さに、のめり込んでいる人が結構いるから」
1つ目の理由「従来技術がちょうど煮詰まっていたから」についてですが、先ず現状としてIT技術は、「もうこれ以上何を積み上げれば良いんだろう?」という程に、成熟しきってしまった様相がありました。
もはや、人間の考案によるアルゴリズム構築は、かなりの範囲で実現がされており、新しくサービスを作ろうにも似たり寄ったりのものしか作れない、差別化が難しい状態でした。
「機械学習」は、そんな従来IT技術の限界を突破する可能性を秘めています。
昨今は「機械学習」による実用例も、どんどん発表されています。
IT技術に携わっている人にとっては、見過ごす訳にはいかない技術という訳です。
一般のPCでも「機械学習」が実践できるとなれば尚更です。
2つ目の理由「差別化を図りたいシステムエンジニアとプログラマーが本気でキャッチアップをしているから」については、1つ目の理由の派生です。
従来IT技術の可能性を革新する技術をいち早くキャッチアップして、自らのの評価を高めようとするシステムエンジニアやプログラマーが、どんどん増えているのです。
特に、これまでのIT技術で実現できることは、誰がやっても凡そ横並びで差別化が難しかったという背景もあり、そこから脱却したいプレイヤーが切磋琢磨しているのです。
実際に、「機械学習」を使いこなせるエンジニアの獲得競争は始まっており、私が聞いたアメリカの某世界的大手企業の例では、有名大学で「機械学習」の研究をしていた優秀な学生を初任給3,000万で雇ったとか…
「機械学習」による分析は「腕っぷし」によって分析精度の良否に差が出てくる為、その位払っても惜しくはないという判断なのでしょう。
そうなってくると、キャッチアップに走る人達が増えてくるのは、極々必然的な流れという訳です。
「腕っぷし」についての詳細な議論は、別の回で行いたいと思います。
最後の3つ目の理由「AIの本質的な面白さに、のめり込んでいる人が結構いるから」については、そもそも「AI」や「機械学習」がやっていて面白い、というシンプルな理由です。
紀元前6世紀に、かの著名なピタゴラスは「万物は数なり」という言葉を残しました。
時を経て17世紀前半、かの著名なガリレオ・ガリレイは「自然の書物は数学の言語によって書かれている」という言葉を残しました。
これらの意味は、自然現象は全て数学で説明できる、ということです。
また、20世紀前半、かの著名なアルベルト・アインシュタインは、「神はサイコロを振らない」という言葉を残しました。
これは、全ての現象は偶然でなく必然によって引き起こされている、という意味です。
逆を言えば、現象の発生要因を厳密に追及していけば、現象を100%説明することが可能だという訳です。
そして、更に時を経て21世紀、そんな過去の偉人達の考え方を検証すべく、即ち、全ての現象の法則性を紐解くべく、発明されたのがコンピュータであり、「機械学習」です。
「AI」の実践は、そんな人類総出のビッグプロジェクトに携わることであり、人類がこれまで積み上げてきた叡智に触れることです。
そこには、本質的な学びの面白さがあります。
実際、お金よりも名声よりも、単純に面白いからと「AI」や「機械学習」に取り組んでいる人が、私の周りにも多いです。
そんな訳で、今回の「AIブーム」はバブルではなく、弾けずに世の中に定着すると、私は考えています。
今は全般的に「試験研究」段階、いずれ「実用」段階に移行した際に必要とされる人材
参加プレイヤーが増えてきている「機械学習」領域ですが、まだまだ黎明期であり、実用まで舵を切っている例はそう多くありません。
プレスされている「機械学習」事例についても、検証段階で高い精度を出すことができた、と発表しているものがほとんどです。
ですが、近い将来、「機械学習」を用いたサービスはどんどん増えていくことでしょう。
そんな状況になった時には、「機械学習」そのもののの有識者は勿論のこと、「機械学習」を用いたサービスを企画できる人材や、「機械学習」をシステムやアプリに組込むための知識を有している人材などの需要が高まってくることでしょう。
できればブームが本格化する前に、知識をキャッチアップできていると良いでしょう。
その為には、時間をやりくりして勉強することは勿論、どう関わっていくかというスタンスを定めて、集中的にキャッチアップしていくことが理想的かと思います。
「機械学習」の知識は幅が広く、人1人が一生をかけても網羅的にキャッチアップすることは難しいです。
選択と集中、そのセンスが問われます。
「機械学習の中でも、私は〇〇が得意です。」と胸を張って言えるポイントを持つべく、向き合っていくことが必要という訳です。
最後に
今回の記事はここまでとなります。
ここまで読んでくださった方、ありがとうございました。m(_ _)m
私としても、「機械学習」との向き合い方に確証的なものはなく、常に情報を集めながら軌道修正を繰り返していますが、今回の記事は今時点での私の考えについての備忘録として書かせていただきました。
ご意見等ある方がいらっしゃれば、是非是非ディスカッションさせていただけますとありがたいです。