はじめに
こんにちは、mucunです。
この連載では、「機械学習」をなるべく直感的で分かりやすく説明することを心掛けています。
今回の記事は、「機械学習」を実現するためのアルゴリズムと、その実用に向けた周辺事情について話をしたいと思います。
一体どんな風に「機械学習」は行われるのか?
実用に向けては、どんなことに気を付けなくてはならないか?
この記事を読むことで、その辺りの知識が身に着くかと思います。
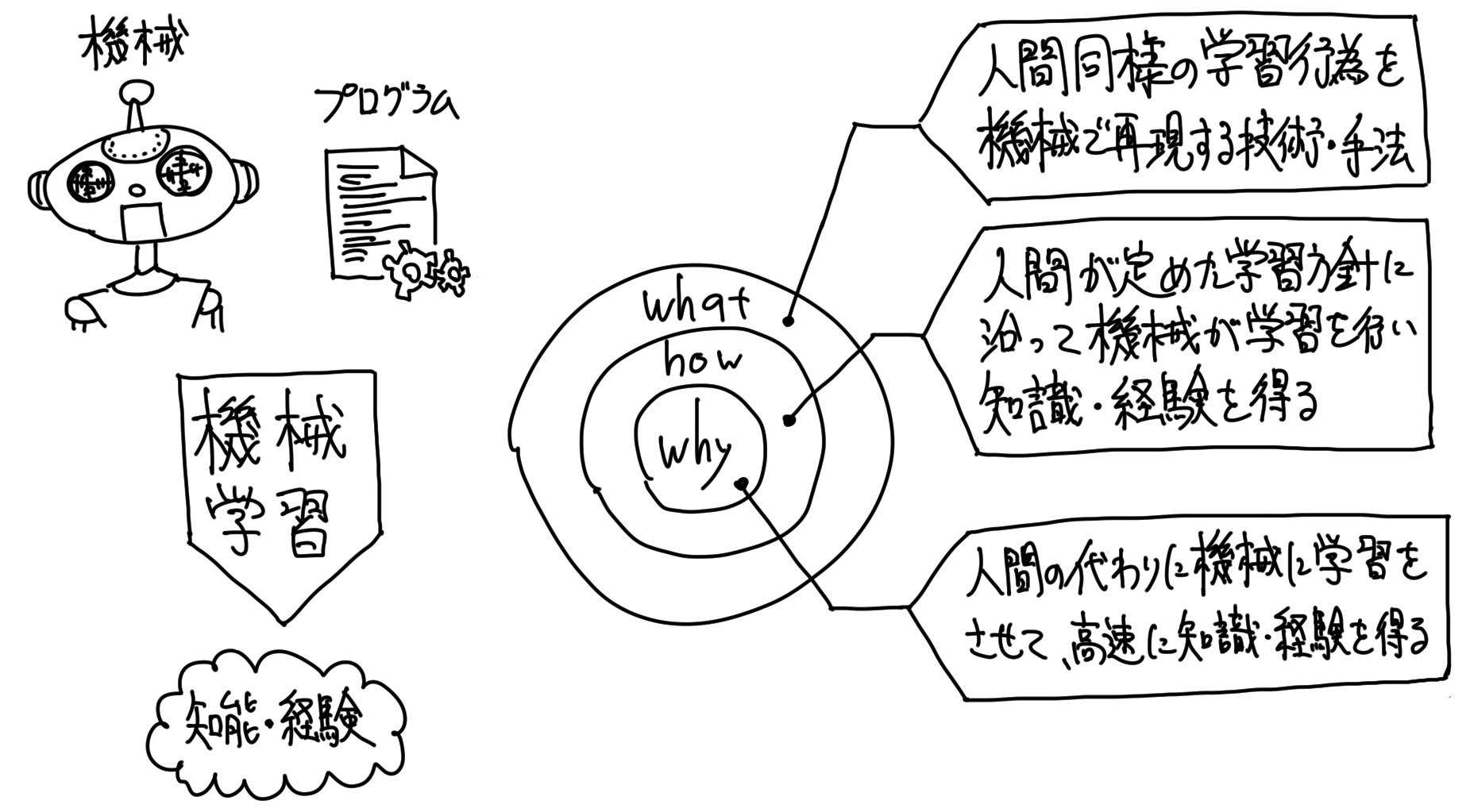
「機械学習」はどう行われるか?
第1回の記事で、「機械学習は、機械に代わりに学習してもらうこと」と説明をさせてもらいました。
それは「why(目的)」を問われた時の説明です。
今回は「how(方法)」について掘り下げたいと思います。
最も直感的なアルゴリズム「決定木」で体感
最も説明も理解もし易い、直感的な機械学習アルゴリズムに「決定木」というものがあります。
「決定木」という学習の方法です。
他にも機械学習アルゴリズムは沢山ありますが、先ずは「決定木」を通して、機械学習アルゴリズムを体感してもらいたいと思います。
このアルゴリズムの中に、他の機械学習アルゴリズムと共通する考え方が沢山含まれています。
尚、今回説明する内容は本質には迫っているものの、少し抽象的な内容とします。
厳密なアルゴリズムの詳細説明は別途行いますので、今回は先ず気軽に読み進めてもらえばと思います。
「決定木」は、データに対して幾つかの条件・判断基準を適用し、予測結果を絞り込んでいくアルゴリズムです。
判断基準とは、医者が患者に対して行う問診のようなものです。
「熱がありますか?」「喉が痛いですか?」「吐き気がありますか?」と質問を重ねて病状を特定する、それと同様のことをデータに対して行うものです。
データに対して問診を行い、データの性質を予測する訳です。
例を示します。
以下のようなデータがあったとします。
| 名前 | 身長 | 髪の長さ | 髭の濃さ | 性別 |
|---|---|---|---|---|
| Aさん | 170 |
|
濃い(50%) | 男 |
| Bさん | 180 |
|
少し(10%) | 男 |
| Cさん | 160 |
|
やや濃い(30%) | 男 |
| Dさん | 150 |
|
ほんの少し(5%) | 女 |
| Eさん | 170 |
|
無し(0%) | 女 |
このデータから「男女」を判別するための「決定木」を作るとします。
出来上がる「決定木」は、以下のようになります。

この「決定木」はデータを元に、コンピュータが自動的に算出して作り上げたものです。
「決定木」生成の学習アルゴリズムは、一言で言うと「試行錯誤」
どうやって「決定木」が生成されたのか、その学習アルゴリズムを説明します。
ザックリ一言で言うと、「色々な条件を試した内、たまたまデータの分別が上手くいった「決定木」を採用した」という感じです。
「決定木」の学習アルゴリズムは、無数の試行錯誤を行った経験の中から、最良のものをチョイスする仕組みなのです。

「決定木」の条件分岐の決め方
もう少し具体的に話をしていきます。
「決定木」には条件式による分岐が幾つか存在します。

その分岐条件は、以下のように決めます。
- 条件を設定する項目を「身長」「髪の長さ」「髭の濃さ」からランダムに選択する
- 選択した項目に対して、ランダムに条件値を設定する
- 設定した条件でもって、「男女」がどのくらい上手く分けられたかを測定する
- 測定した精度を、現在の最高記録とする
- また新たに、条件を設定する項目を「身長」「髪の長さ」「髭の濃さ」からランダムに選択する
- 選択した項目に対して、ランダムに条件値を設定する
- 設定した条件でもって、「男女」がどのくらい上手く分けられたかを測定する
- 測定した精度を、現在の最高記録と比較して、良い記録であれば記録を更新する
- (同様のことを繰り返す…)
- 最高精度を記録した選択項目・条件値を、分岐条件として設定する
以上です。
どうでしょうか?
結構、行き当たりバッタリな方法ですよね。
これを「男女」判定に適用してみると、学習している様子の1例は以下のようになります。
名前 身長 髪の長さ 髭の濃さ 性別 Aさん 170cm 3cm 50% 男 Bさん 180cm 20cm 10% 男 Cさん 160cm 5cm 30% 男 Dさん 150cm 15cm 5% 女 Eさん 170cm 30cm 0% 女
- 条件を設定する項目として、ランダムに「身長」を選択した
- 「身長」に対して、ランダムに「155cm」という条件値を設定した
- 設定した条件でもって、「男女」がどのくらい上手く分けられたかを測定した

- 一方のグループの「男」の割合と、もう一方のグループの「女」の割合の平均値を精度とした
- 上の例だと、一方の「男」の割合を0%、一方の「女」の割合を25%として、平均分別割合を12.5%とも捉えることができるが、そちら側の捉え方ではなく、割合が高くなる側の捉え方の87.5%を精度とした
- この精度の捉え方だと、最低の精度が50%、最高の精度が100%となる
- 測定した精度「87.5%」を、その時点での最高記録とした
- また新たに、条件を設定する項目として、ランダムに「髪の長さ」を選択した
- 「髪の長さ」に対して、ランダムに「10cm」という条件値を設定した
- 設定した条件でもって、「男女」がどのくらい上手く分けられたかを測定した

- 測定した精度「83.4%」を、その時点での最高記録「87.5%」と比較すると、後者の方が良い記録であったので、最高記録を「87.5%」のままとした
- また新たに、条件を設定する項目として、ランダムに「髭の濃さ」を選択した
- 「髭の濃さ」に対して、ランダムに「7%」という条件値を設定した
- 設定した条件でもって、「男女」がどのくらい上手く分けられたかを測定した

- 測定した精度「100%」を、その時点での最高記録「88.8%」と比較すると、前者の方が良い記録であったので、最高記録を「100%」に更新した
- その時点での最高精度を記録した「髭の濃さ:7%」を、分岐条件として設定した
以上です。
実際の様子を見ると、よりイメージが湧きやすいかと思います。
分別したデータを、更なる分岐条件で分別する
ここまでで「決定木」の分岐条件の決め方が分かったかと思います。
その理解で、「決定木」の学習アルゴリズムの8割が理解できています。
データ全体に対して1つ目の分岐条件を決め、データを分別させることができたなら、次はその分別データに対しての2つ目・3つ目の条件を決めます。

更には、2つ目・3つ目の条件にて分別されたデータに対して、分岐条件を決めていきます。
こうして、データ分別を繰り返していき、分別精度が100%になったら学習の終了となります。
或いは、「決定木」の深さを予め設定しておき、その深さまでデータを分別したら学習を終了とします。
深さとは、データが辿る分岐条件の数のことです。

「ランダム」との付き合い方について
「決定木」の学習アルゴリズムに含まれる「ランダム」との付き合い方についての話をします。
ランダムとは、その時その時で結果が変わるということである為、それが学習アルゴリズムに含まれる「決定木」は、学習結果が毎回異なるものとなる可能性があります。
生成の度、異なる「決定木」が生成される可能性があるということです。
極端な話をすると、ある時は精度の高いものが生成され、ある時は精度が低いものが生成される可能性もあるので、ここは注意が必要です。
何度か「決定木」を生成してみて、最も精度の高いものを採用すると良いでしょう。
分岐条件探索の際に、ランダムな条件値を設定するアルゴリズム部分については、途方もなく大きな値や小さな値を設定しても、データは上手く分けられない為、選択した条件項目の最大値・最小値の間に納まる値をランダムに設定するのが一般的です。
また、ランダムな条件項目選択と条件値設定について、先程の説明ではそれを3回ずつ実施していましたが、本来はもっと多数の試行をします。
データ項目・データ数が多いと、なかなか良い分岐条件が見つからなかったりする為です。
しかし、試行回数を増やし過ぎると、学習に時間がかかってしまうデメリットもありますので、そこは調整が必要です。
一般的に、時間対効果の高いポイントが存在するので、徐々に増やしながら調整をしていくと良いです。
かける時間が少ない場合には、時間と精度上昇の関係が如実ですが、かける時間が多くなってくると、時間をかけても精度があまり変わらなくなってきます。
その中間ポイントを、何度か「決定木」を生成してみる際の学習設定とすると、時間帯効果の高い試験研究を実施することができます。

尚、ランダムというものを機械学習のアルゴリズムとして含んでいるアルゴリズムと、そうでないアルゴリズムが存在します。
「決定木」は、ランダムを含むタイプのアルゴリズムとなります。
ランダムを含むアルゴリズムと、そうでないもの違いは、アルゴリズムのポリシーだと考えて下さい。
プロ野球の選手に、バットをユラユラと揺らしながら構えるタイプのバッターがいれば、ピタッと静かに構えるタイプがいるのと同じようなものです。
そうした方が良い精度が出せるからそうしているのです。
精度を出すための癖といっても良いです。

「決定木」の条件分岐を、ランダム試行で探索するのではなく、計画的試行で探索する
精度を出すための癖であるランダムは、そうした方が精度が出るためにそうしているのあって、実はランダム性をアルゴリズムに含むのは必須ではありません。
むしろ、厳密に計画をすることができれば、ランダム性を含まない方が分析精度が高くなることが期待できます。

「決定木」に関しても、上手く計画すれば、ランダム性を含まずに分岐条件を探索することが可能です。
項目選定を全項目総当たりで選定するようにしたり、条件値設定を一定間隔で刻んだ設定値を順繰りに設定するようにする等、ルールをカチッと決めてしまって学習を行うのです。
以下、データ再掲と、計画的に分岐条件の探索をしている例です。
名前 身長 髪の長さ 髭の濃さ 性別 Aさん 170cm 3cm 50% 男 Bさん 180cm 20cm 10% 男 Cさん 160cm 5cm 30% 男 Dさん 150cm 15cm 5% 女 Eさん 170cm 30cm 0% 女
試行回数 条件項目選定 条件値設定 分別精度 1回目 身長 155cm 87.5% 2回目 身長 165cm 58.3% 3回目 身長 175cm 75% 4回目 髪の長さ 10cm 88.8% 5回目 髪の長さ 17.5cm 58.3% 6回目 髪の長さ 25cm 87.5% 7回目 髭の濃さ 7.5% 100% 8回目 髭の濃さ 15% 88.8% 9回目 髭の濃さ 25% 88.8%
計画的に試行すると、説明性と網羅性が高くなるというメリットがあります。
「どういう試行を経て、「決定木」が作られたのか?」、「どんな条件が棄却されたのか?」などの疑問に対する答えが明確です。
逆に言うと、ランダム試行の場合、説明性と網羅性は低くなってしまいます。
出来上がった「決定木」の精度や信ぴょう性の保証が、ランダムゆえに保証できないのです。
しかし、ランダム試行には、何も考えずにパッと実施できるという手軽さがメリットとしてあります。
計画的試行には、固定観念から局所的な偏った試行で終わってしまうリスクや、計画を立てるという作業の増加が生じてしまうことがデメリットとなるのです。
これら方針は一長一短であり、目的に合わせた方針のチョイスをする必要があります。
私としては、先ずはランダム試行でやってみて、高い精度が出せなかったり、分岐条件の信ぴょう性確認が必要となった場合に、追加で計画的試行をやってみる方針が良いかと思います。
できあがった「決定木」を実用する
できあがった「決定木」は、そのまま眺めてても「大したもんだなぁ」と見飽きないものですが、真の価値は実用することで発揮されます。
実用とは、過去のデータから導出した「決定木」によって、未知のデータの予測をすることです。
例えば、過去の天候の傾向から未来の天候を予測したり、過去の指紋データから此度の指紋が本人かどうかを推定したりすることです。

学習に使用していないデータでの予測精度こそが、真の予測精度
未知のデータでの予測が真の目的である為、過去のデータにものすごく当てはまる「決定木」ができたとしても、それが未知のデータで精度を発揮しなければ、その「決定木」に価値はありません。
実際に、学習に使うデータでは高い精度を発揮する法則性でも、未来のデータに対しては「からっきしダメ」ということは、機械学習全般として結構あることです。
ですので、未知のデータに対しても普遍的に通用する、ロバスト(頑健)な法則性を導出する必要があります。
つまり、学習に使うデータでの分別精度が高いことは真の嬉しさではなく、未知のデータでの予測精度が高いことが真の嬉しさなのです。
学習に使うデータでは分別制度が高いのだけど、未知のデータに対しては予測精度が低くなってしまうという場合の理由としては、以下の3つが考えられます。
【未知のデータで予測精度が出ない理由】
- そもそも学習に使うデータの中に、目的を果たすための法則性が潜在していなかった
- 学習に使ったデータが非常に少量であった為に、その少量データと同じ傾向を持つ一部のデータにしか通用しない法則性が抽出されてしまった
- 抽出された法則性が過剰に厳密で、適切な遊びやワビサビが無い法則性となってしまった
これらは機械学習を行う上で、必ずぶち当たる壁になります。
非常に大事なポイントとなりますので、1つ1つ説明させてもらおうと思います。
未知のデータで予測精度が出ない理由1つ目「そもそも法則性が無い」
- そもそも学習に使うデータの中に、目的を果たすための法則性が潜在していなかった
コンピュータサイエンス分野で「ゴミを入力しても、ゴミしか出力されない(GIGO:Gabage In Gabege Out)」という言葉があります。
機械学習にも該当する言葉です。
何の脈絡もないゴミのようなデータを入力に機械学習をしても、何の説明性もないゴミのような法則性しか出てきません。
データ分析の実施目的とデータ選定の勘所が合っていなかったりすると、このパターンの現象が起こりえます。
例えば、データで極端に表すと、こんな形です。
| 日付 | 東京の降水量 | 東京の気温 | 日経平均株価の変動 |
|---|---|---|---|
| 3/1 | 晴れ(0mm) | 15℃ | 上昇 |
| 3/2 | 晴れ(0mm) | 16℃ | 下降 |
| 3/3 | 晴れ(0mm) | 17℃ | 上昇 |
| 3/4 | 晴れ(0mm) | 18℃ | 下降 |
| 3/5 | 晴れ(0mm) | 19℃ | 上昇 |
「日経平均株価の変動」を予測するという目的を立てて、このデータに対して「決定木」を作ろうとした場合、どうやっても上手く行きません。
「東京の降水量」は全て値が同じなので、条件による分別はできません。
「東京の気温」についても、どうも「日経平均株価の変動」とは関係がなさそうです。
一方は増減しているのに対して、一方は上がったり下がったりしています。
こういうパターンの場合、そもそもデータの中に法則性が無く、導出そのものが難しいのです。
未知のデータで予測精度が出ない理由2つ目「データ数不足による偏った法則性導出」
- 学習に使ったデータが非常に少量であった為に、その少量データと同じ傾向を持つ一部のデータにしか通用しない法則性が抽出されてしまった
機械学習を行う前提として、「過去のデータに見られるデータ傾向は、未知のデータにも見られるハズだ」という仮説があります。
機械学習を行う上で、この仮説への答えは必ずYESでなくてはなりません。
そうでなければ、機械学習を行う意義が真っ向から否定されてしまいます。
イメージとしては下記です。
過去のデータと未知のデータが同じ傾向を持っているというイメージです。
この仮説が満たされるのであれば、機械学習は100%上手く行きます。

未知のデータでの予測精度が出ない理由の2つ目は、学習に使うデータが少量である為に、その仮説が否定されたパターンです。
イメージとしては下記です。

「データ傾向A・C・D」の傾向を持つデータが、学習に使うデータに含まれていない場合、機械学習は「データ傾向A・C・D」に関する知識を得ることができません。
そして、未知のデータでの予測について「データ傾向A・C・D」のデータに関しては、予測を外してしまう可能性が高くなります。
例えば、このパターンを極端なデータで表すと以下です。
| 名前 | 身長 | 髪の長さ | 髭の濃さ | 性別 |
|---|---|---|---|---|
| Fさん | 175cm | 3cm | 30% | 男 |
| Gさん | 180cm | 5cm | 40% | 男 |
| Hさん | 185cm | 7cm | 50% | 男 |
| Iさん | 145cm | 40cm | 0% | 女 |
| Jさん | 150cm | 50cm | 1% | 女 |
| Kさん | 155cm | 45cm | 2% | 女 |
先程の「男女」判別を行うデータについての追加データです。
このデータだけで見ると、男性は「身長が高め・髪が短め・髭が濃め」という傾向を持ち、女性は「身長が低め・髪が長め・髭が薄め」という傾向を持ちます。
非常にありがちな傾向です。
この6件のデータから、機械学習による法則性抽出を行う場合、そのありがちな傾向からしか「男女」分別の基準を導出されません。
そんな法則性で予測をする場合、未知のデータとして、身長が低めの男性や、髪が短めの女性が現れた場合、正しい判断をするのが難しくなります。
学習に使うデータ量が少ない為に、いわゆる珍しい特徴を持ったデータが、学習に使うデータに含まれないことが原因です。
この辺りの話は、一般には、データの「誤差」についての議論となります。
珍しいデータ傾向のことを「誤差」と表現します。
「男女」の判別で言えば、平均的な男性・女性と比較して、女性らしい特徴を持つ男性や、男性らしい特徴を持つ女性のことが「誤差」と表現されます。
機械学習を行う場合、この「誤差」も考慮して学習を行うことが理想的です。
つまり、珍しい特徴を持つデータも含めて学習を行うということです。
未知のデータ計測時の珍しいデータ発生割合が、100人に1人であった場合、少なくとも学習に使うデータには100件のデータは欲しいことになります。
確率的に、少なくとも1件は、珍しい特徴を持つデータを、学習に使うデータに含ませたいからです。
そして、その確率も、あくまで確率です。
珍しい特徴を持つデータを、学習に使うデータに安定的に含ませようとすると、200件、いや、1,000件はデータが欲しくなってしまいます。
予測精度低下を防ぐには、学習に使うデータがなるべく多いことが望ましく、逆に、学習データが少ないことは、予測精度低下に繋がってしまう可能性があるのです。
未知のデータで予測精度が出ない理由3つ目「過剰に厳密な法則性導出(過学習)」
- 抽出された法則性が過剰に厳密で、適切な遊びやワビサビが無い法則性となってしまった
機械学習をする上でぶち当たる壁の中でも、最も悩まされる課題の中に「過学習」というものがあります。
「過学習」とは、ザックリ言うと「学習のし過ぎ」です。
学習に使うデータでの分別精度向上を頑張りすぎた結果、『本質的でない/汎用的でない/俯瞰的でない』という法則性が導出されてしまう現象で、結果的に未知のデータでの予測精度が発揮されないのです。
データの例にとって、「過学習」について説明をします。
| 日付 | 気温 | ビールの売上 |
|---|---|---|
| 去年の7/1 | 25℃ | 低 |
| 去年の7/15 | 29℃ | 高 |
| 去年の8/1 | 33℃ | 高 |
| 去年の8/15 | 31℃ | 低 |
| 去年の9/1 | 28℃ | 高 |
| 去年の9/15 | 23℃ | 低 |
あるスーパーにおけるビールの過去の売上が、上記のようだったとします。
基本的に、気温が高い日にビールの売上が高く、気温が低い日にビールの売上が低い傾向があります。
しかし、「去年の8/15」に少々例外的な日があります。
気温が高かったにも関わらず、ビールの売上が低かったのです。
先程説明をした「誤差」と言える日です。
このデータにて、分別制度を高めるべく十分に時間をかけて「決定木」を生成した場合、以下のようになります。

グラフは、気温毎に対する予測ステータスです。
人間は「去年の8/15」の売上を見ると、「誤差」であることに感覚的に気付くことができますが、機械はそんなことお構いなしなので、グラフのような予測を行ってしまいます。
基本的に、気温が高い日にビールの売上が高く、気温が低い日にビールの売上が低い傾向があるという勘所が無い訳です。
この予測グラフでは、未知のデータに対する予測が上手く行かないことは明白でしょう。
これが「過学習」と言われる現象です。
英語では「過学習」のことを、「Over Fitting」と言います。
学習に使うデータに過剰に合わせてしまうから「Over Fitting」です。
対策として、節度のある合わせ「Well Fitting」を行うことが大事なのですが、その方法は少し込み入った話になりますので、別途説明をします。
未知のデータで予測精度を出すための方法について
ここまでの説明で、未知のデータで予測精度が出ない理由について理解してもらえたかと思います。
それでは、これらの問題はどう解決すれば良いでしょうか?
最も有効な手段は、データを無限に収集することです。
無限の種類のデータを、無限に細かい時間間隔で、無限数ずつ集めるのです。
それができれば、データの偏りという概念は無くなります。
一般的にも、学習に使うデータが増えることで、未知のデータでの予測精度が向上する傾向にあります。
無限とまでは言わなくとも、出来うる限りのデータ収集に努めることが、未知のデータでの予測精度向上につながります。

しかし、データを集めることは現実的には難しいこともあります。
収集コスト(金銭・時間)や、収集実現性(対象データを収集するセンサーが無い)などの問題からです。
その場合には、今あるデータの中で対策を打つ必要があります。
今あるデータで打つ対策、その最もポピュラーな方法として、データを「学習用」と「評価用」に分けるという方法があります。
全体のデータを、例えば「70%:30%」などの任意の割合で、学習に使用する「学習用データ(Train Data)」と、学習に使用せず評価のみに使用する「評価用データ(Validation Data・Test Data)」とに分けるのです。
そうすることで、機械は「評価用データ」の中身を知らずに法則性を導出することとなる為、その法則性での予測精度を「評価用データ」で測定すれば、それが未知のデータでの予測精度の推定値となる訳です。

機械学習を行う前提には、「過去のデータに見られるデータ傾向は、未知のデータにも見られるハズだ」という仮説があると、先程話をしました。
この「学習用データ」と「評価用データ」に分ける方法も、その考えに則っています。
「評価用データ」での精度評価を行わない場合は、未知のデータでの精度保証が全くできていません。
「評価用データ」での精度評価を行うことで、未知のデータでの精度保証が事前に図れる訳です。
システムに組み込むのは学習結果だけ
さて、「評価用データ」での精度も高い「決定木」ができたとして、それを実用に向けてシステムに組込むとします。
それは、「決定木」による予測を用いて、人間の判断作業を機械に置き換えたり、今まで気付かなかった法則性から新しいサービスを実現する、ということです。
そのシステム組込みはどう実現すれば良いかと言うと、学習結果だけを組込めば良いです。
つまり、学習のアルゴリズムをシステムに搭載する必要はなく、学習のアルゴリズムによって導出された法則性である「決定木」だけを搭載すれば良いということです。
機械学習は、学習のアルゴリズムこそ難しいですが、導出された法則性は一般的にそう難しくありません。
「決定木」についても、条件分岐を幾つかプログラムに書き重ねれば、予測ができます。
ですので、計算処理としても負荷の高い学習の処理は、性能の高いコンピュータで実施をする必要があったりしますが、予測はそう高性能でないコンピュータでも実施が可能となります。
「決定木」以外の代表的なアルゴリズム
今回の説明では、機械学習のアルゴリズムとして「決定木」を紹介しましたが、他にも機械学習のアルゴリズムは多数存在します。
その幾つかを紹介します。
ざっと有名どころをマッピングすると以下の図のようになります。
(手書きの為、汚くてスイマセン、、、)

縦軸が有名度合いで、横軸がアルゴリズムの拡張度合いを表しています。
上に位置するほど頻繁に使われている手法で、右に位置するほど複雑なアルゴリズム、という感じです。
矢印で繋がっているアルゴリズム同士は、自分の独断で関係づけた「源流形」と「発展形」の関係性です。
矢印の元が発展して、矢印の先のアルゴリズムが生まれただろう、という勝手な予測で引いた関係性です。
しかし、アルゴリズムの内容的には概ねその関係性になっていますので、恐らくそうなのではないかと思います。
勉強する順番も、矢印を辿るように順に行なっていくと理解がしやすいので、その順で理解を進めるのがオススメです。
紹介した「決定木」は、かなり源流的なアルゴリズムです。
その発展系の「Random Forest(ランダム フォレスト)」は結構有名で、よく使われています。
よく耳にする「Deep Learning(ディープラーニング)」は、元々、回帰分析を端に発し発展したアルゴリズムです。
ある日、パッと生まれたものではなく、旧来の機械学習アルゴリズムの発展形として存在します。
その為、「Deep Learning」を理解しようとと思ったら、源流の「回帰分析」から理解を進めると捗ります。
1つ1つの詳細なアルゴリズムについては、別途説明をしたいと思います。
機械学習によって、人間は学習を行う必要がなくなるか?
機械が学習をするようになると、人間が学習を行う必要が無くなるのではと考える方がいるかと思います。
しかし、そんなことはありません。
理由は、以下の2つです。
- 人間が逐一指示を与えてあげないと、機械は機械学習が実践できない
- 人間が自然と行っている応用的な思考が、まだ機械学習には行えていない
1つ目の理由については、第2回の記事に書かせてもらっているので、そちらを参照下さい。
ザックリ言うと、機械はまだまだ自走的には学習を実施できないのです。
それは、抽象的な概念も理解できない為です。
逐一具体的な指示を発行する必要があります。
その為、人間は「いかに機械を上手く使うか?」ということについて、学習を続けていく必要があります。
むしろ、機械学習によって拡がっているコンピュータの可能性について、今まで以上に深く考え抜く必要性が生まれています。
2つ目の理由については、そのままで、機械には知識の応用ができない、ということです。
人間は例えば、汎用的な知識を、具体的な行動に応用することができます。
例えば、物理を学習して、それをスポーツに応用することができます。
和食の料理人が培った調理の知識を応用して、美味しい洋食を作ることができます。
それが機械にはできません。
あくまで、参考となるデータと、そのデータから達成した目的を、人間に与えられた上で、限定的な世界での法則性を導くことしか、機械学習によっては実践されないのです。
その為、そこは人間が機械を上手くリードして、機械学習の価値を引き出すべく、機械のマネジメントを行う必要があるのです。
尚、この2つの理由については、「今のところは」という注釈がつきます。
限られた思考とはいえ、機械が学習する、というところまでは最早実現されています。
更に、人間的と言われる思考アルゴリズムが上手く紐解かれ、それをプログラムに表現することができたならば、機械が自発的に応用を始めるという次なる時代がやってくることでしょう。
機械の学習と、人間の学習の質の違い
ここで、機械にできる学習とは一体何なのかを整理しておきましょう。
機械学習とは、人間の代わりに機械が学習を行ってくれることです。
その代わってくれる学習とは、一体どんなものなのか?
一言で言うと、集中思考な学習です。
これについては、以下の記事を参考にさせてもらいました。
集中思考とは、いわゆる「1+9=[?]」の答えを解く考え方です。
機械が人間よりも得意なのは、この答えが1つしか無い問題を解くということです。
「=」記号の左側のことを左辺、右側のことを右辺と言います。
人間が左辺をお膳立てできれば、右辺を導くのは機械にとってお茶の子さいさいです。
人間よりも遥かに高速に、全くのミスなく計算することができます。
そして、先程話したような人間にしかできない思考が何かというと、集中思考の逆、拡散思考です。
それは、「[?]+[?]=10」の答えを解く考え方です。
これについては、答えは無数に存在します。
この結果として10が欲しい場合の手段や、方法論を考えることが、今のところは人間にしかできない考え方なのです。
ですので、集中思考を機械にお願いしながら、人間は拡散思考に集中する、この連携が大事で、それを如何に上手く行うかが、これからの時代の効率的な思考方法となると私は考えています。
要するに、人間と機械の「学習分担」が主流になるということです。
ニュースなどでしばしば記事にされる「AIに置き換わる人間の仕事」も、この辺りの話でしょう。
よりクリエイティブな思考が、人間に求められているのです。
最後に
今回の記事では、機械学習のアルゴリズムについて「決定木」を軸に話しさせてもらったと共に、その実用に向けた注意や、人間と機械の「学習分担」について触れさせていただきました。
ここまで読んでくださった方、ありがとうございました! m(>人<)m