はじめに
こんにちは、mucunです。
この連載では、「機械学習」をなるべく直感的で分かりやすく説明することを心掛けています。
まだ「機械学習」のことを知らない人も、知ってはいるけども知識に自信が無い人も、この連載を通して理解を深めてもらいたいと思っています。
今回よりの3回の記事にて、「機械学習」を適用するために必要なプロセスについて、説明したいと思います。
プロセスを「序盤」・「中盤」・「終盤」と3つのグループに分けて、それらを1回ごとに説明していきます。
今回は、「序盤」のプロセスについて説明をします。
「そうだ 機械学習、しよう。」というノリで「機械学習」はできない
有名なJR東海のCMに「そうだ 京都、行こう。」というものがあります。
ふと思いついて、新幹線でフラっと京都へ…
京都を身近に感じられる、素敵なコンセプトですよね。
「機械学習」も、「そうだ 機械学習、しよう。」というノリで始められれば良いのですが、そうはいきません。
然るべき準備が必要です。
データ分析の仕事をやっていると、「適当に指示をすると、人間の代わりによろしくやってくれるんでしょ?」という「機械学習」に対する誤解、つまり、「そうだ 機械学習、しよう。」にしばしば遭遇しますが、それはちょっと難しいのです。
確かに、よろしくやってくれる部分はあります。
ただし、そこには前提条件が山ほど付いてきます。
「然るべき前提条件をクリアすれば、ある一部の計算処理についてよろしくやってくれる」というのが正しい認識なのです。
また、「機械学習」を行うためには、「然るべき準備」に加えて、導出された結果を注意深く検証する必要もあります。
「然るべき準備」が誤っていると、トンチンカンな結果を機械が返してくるからです。
その為、データ分析を行う人間が、何から何まで分析に関わるもの全てを、しっかりとマネジメントしなくてはなりません。
そして、分析作業のほとんどは「機械学習」そのものにかかる時間ではなく、準備や結果検証にかかる時間となります。
旅行で言えば、パックプランなどは使わずに、綿密に計画してから旅行に向かった上で、ミスの無い行程を辿れているかどうかを常にチェックするという形です。
フラっとは行けないのです。
即ち、「そうだ 機械学習、しよう。」ではなく、「よ~し、準備万端だ いよいよ機械学習、しよう。」でなくてはならないのです。
「機械学習」を実施するためのプロセスと、「序盤」・「中盤」・「終盤」のグループ分け
第1回の記事にて、「機械学習」を用いたデータ分析全体を行うための、必要プロセスについて説明しました。
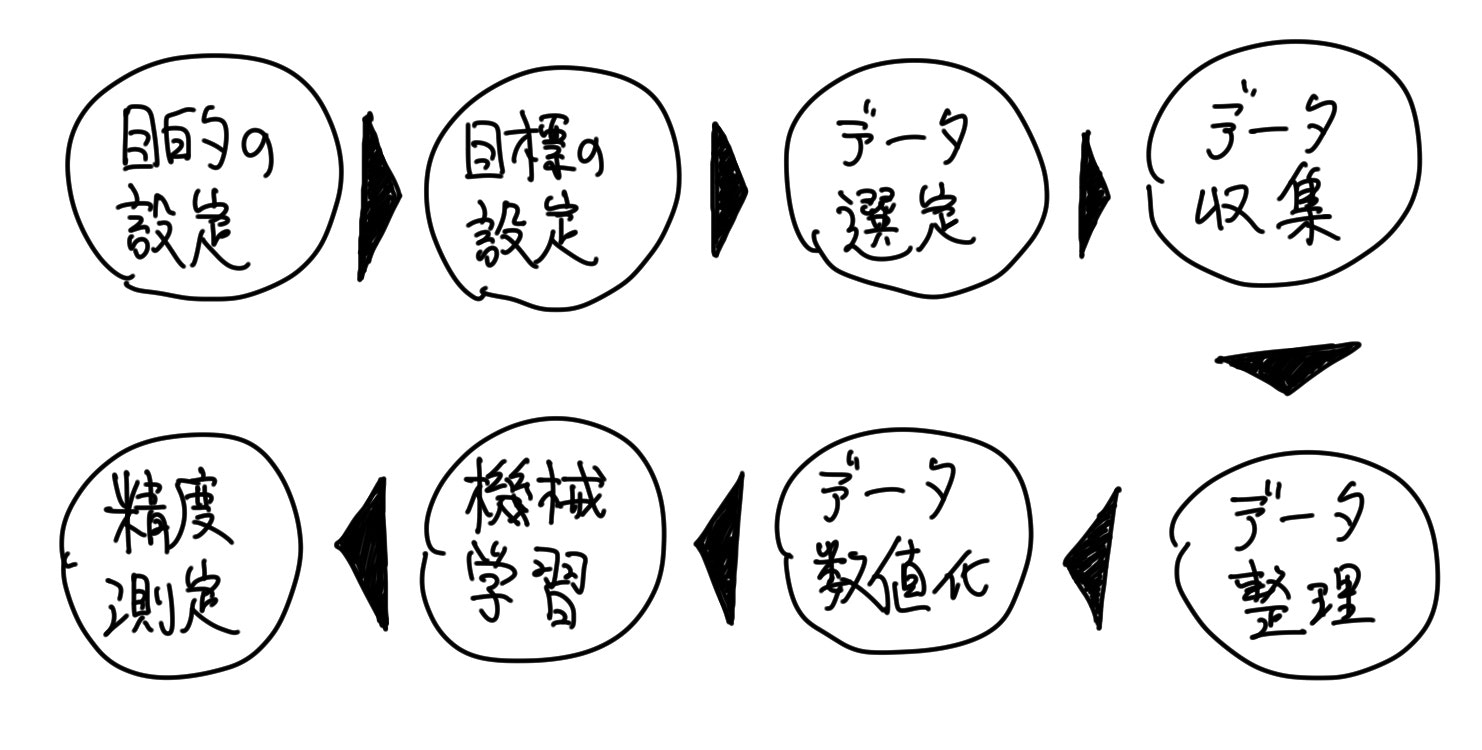
これらのプロセスは、「機械学習」を仕事で使っている人は意識的に、或いは、無意識的に辿っているものです。
当たり前っちゃあ当たり前なプロセスなのですが、何れかプロセスをスキップして分析を進める(意識的か無意識的かに拠らず)と、分析作業における「漏れ」や「無駄」が起きやすいです。
予めカチッと意識しておいた方が、効率良く分析が進められます。
また、プロセスは初心者向けのガイドラインという訳ではなく、分析素養に関わらず意識した方が良いものです。
これを意識して分析を行う「機械学習」初学者と、これを意識せず闇雲に分析を行う「機械学習」有識者とで、前者の方が高い評価を受けるに至った例を、私は何度か目にしました。
プロセスに沿って進めることで、報告内容も理路整然としますし、戻りも少ない為にシンプルに改善を繰り返すことができる為です。
尚、プロセスは、大きく「序盤」・「中盤」・「終盤」の3つのグループに分けられます。
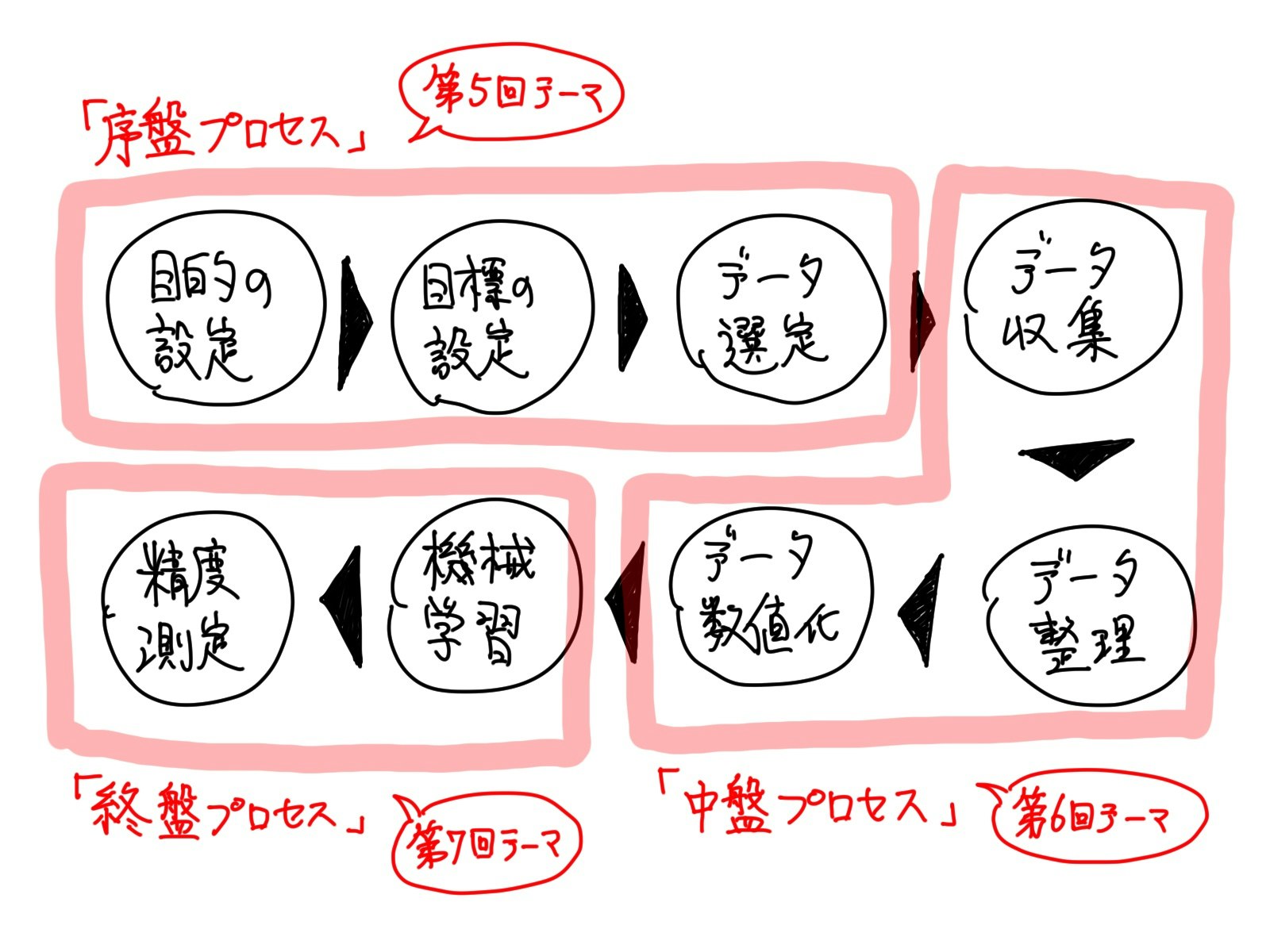
「序盤」は、計画を行うプロセスグループ。
「中盤」は、準備を行うプロセスグループ。
「終盤」は、「機械学習」実行と結果検証、という感じです。
今回の記事では、「序盤」プロセスについて、掘り下げて話をしたいと思います。
「機械学習」を用いたデータ分析を行うための、意義や仮説立てを行うフェーズです。
以降のプロセスについては次回、次々回とに分けて説明をさせていただきます。
プロセス1つ目「目的の設定」
それでは、最初のプロセス「目的の設定」から説明していきます。
最も根本的なプロセスであり、目的の筋の良さこそが分析の成功の種であることは、言うまでもありません。
目的を設定することは意外に難しいものです。
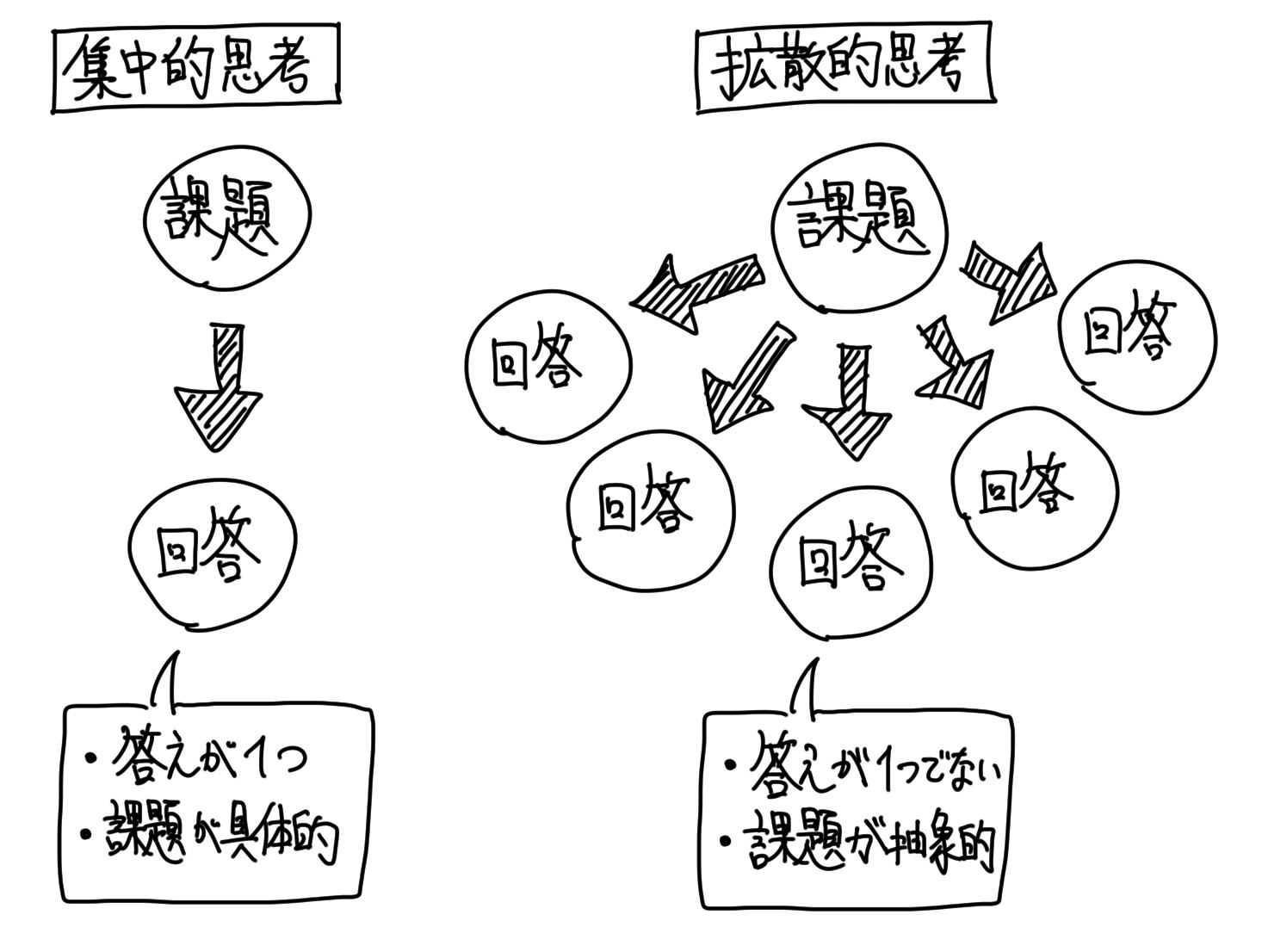
いわゆる拡散思考が必要なプロセスです。
「機械学習」というものを中心に置いて、そこから「どんなサービスが生まれるか?」「どんな自動化が行えるか?」「どんな発見ができるか?」という「機械学習の使用目的」を考えるということです。
ちなみに、拡散思考は人間にしかできない芸当だというを、第3回の記事にてさせてもらいました。
機械は「1+9=[?]」を解くような集中思考は得意だが、「[?]+[?]=10」を解くような拡散思考は苦手なのです。
このプロセスは、人間が取り組まなくてはならないプロセスになります。
「機械学習」を中心に置いて、「機械学習」によって生まれる新しい価値を考える。
そんな風にして「機械学習」の目的を考える際に、「機械学習」の知識を所持しているに越したことはありません。
調理ノウハウがあった方が、与えられた食材から料理のアイデアがポンポン浮かび易いように、「機械学習」のノウハウがあった方が、「機械学習」の応用アイデアがポンポン浮かび易いのです。
この原理から、先ずは「機械学習」について座学で学び始める、という人が多いかと思います。
しかし、必ずしも「機械学習」の知識やノウハウが無いと、その応用アイデアを創出できない訳ではありません。
即ち、「機械学習」の知識やノウハウが無くても、「機械学習」を用いる「目的の設定」は行えます。
知識無しでの実践に臨むことを嫌がる人もいると思いますが、そういう純粋な状態だからこそ、生まれる発想もあると思いますし、座学を先んじて行うことによって、先行事例に考えが引っ張られてしまい、発想が凝り固まってしまうこともあります。
また、実践と座学を交互に繰り返す方が、学習も捗るものです。
スポーツにて、試合と練習を繰り返すようなものです。
「機械学習」の知識やノウハウが無くても、「機械学習」の「目的の設定」を行うコツですが、それは「機械学習」のシンプルな根本的性質を知り、それに沿ってアイデアを発想する、というものです。
それは「機械学習」が唯一実践できる「予測」というものを軸に、「目的の設定」を行うというものです。
この方法は、発想の凝り固まってしまった頭を解きほぐすエクササイズにもなるかと思います。
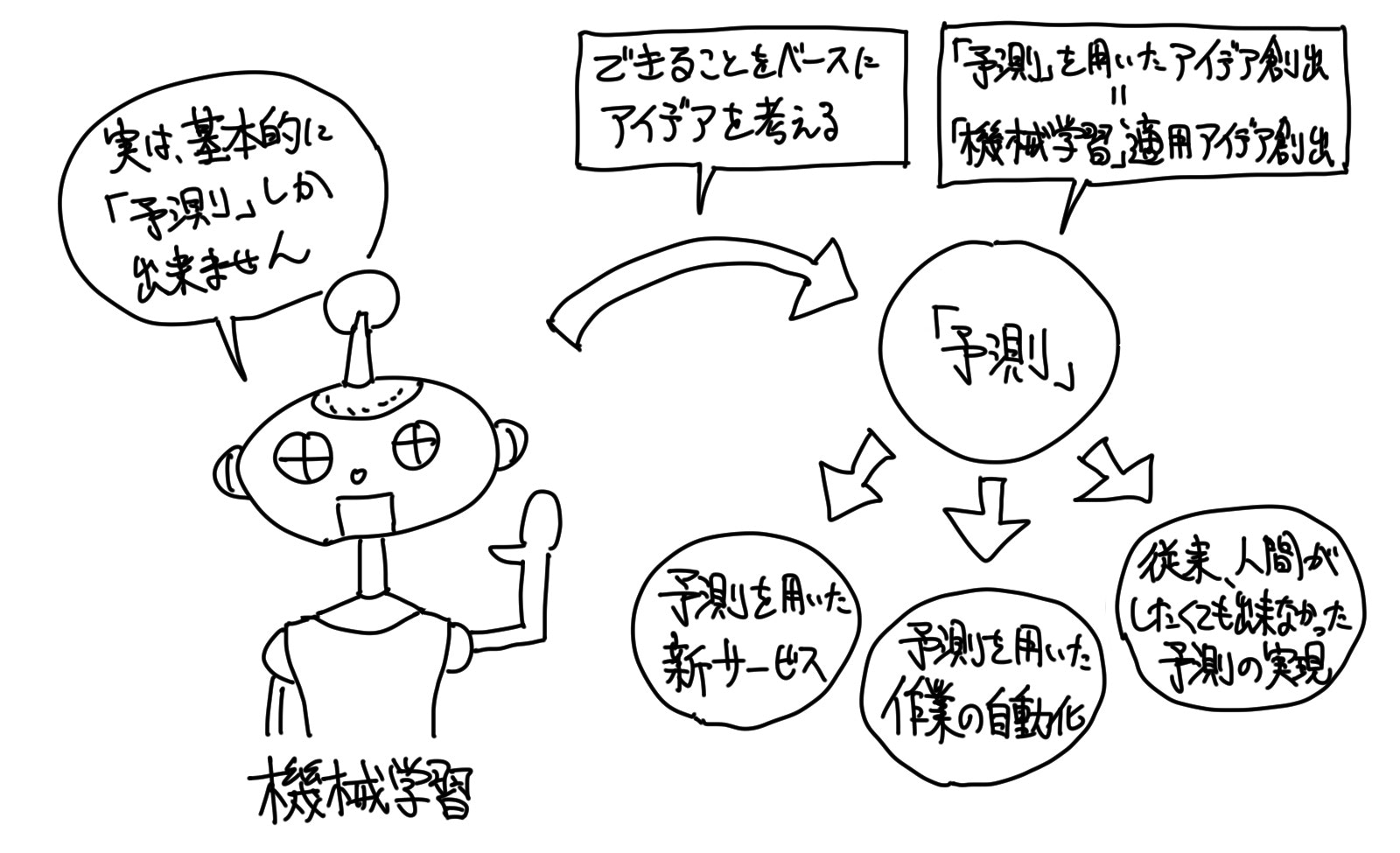
基本的には、「予測」しかできない「機械学習」
「機械学習」にできることは、大まかに言ってしまえば「予測」だけです。
「目的の設定」を行うコツとして、この「機械学習」における大前提を知っておくことが大事です。
細かく掘り下げていくと「予測」以外に実現できることもあるのですが、それらも「予測」からの派生です。
「予測」を行うことが「機械学習」の肝なのです。
もしも、私が誰かに、「なぜ機械学習を行うのか?(Why Machine Learning? What is Machine Learning for?)」と聞かれたら、「予測のため」と答えます。
「予知」や「予想」と言っても良いでしょう。
これから起こることを計り知る、推し量るということです。
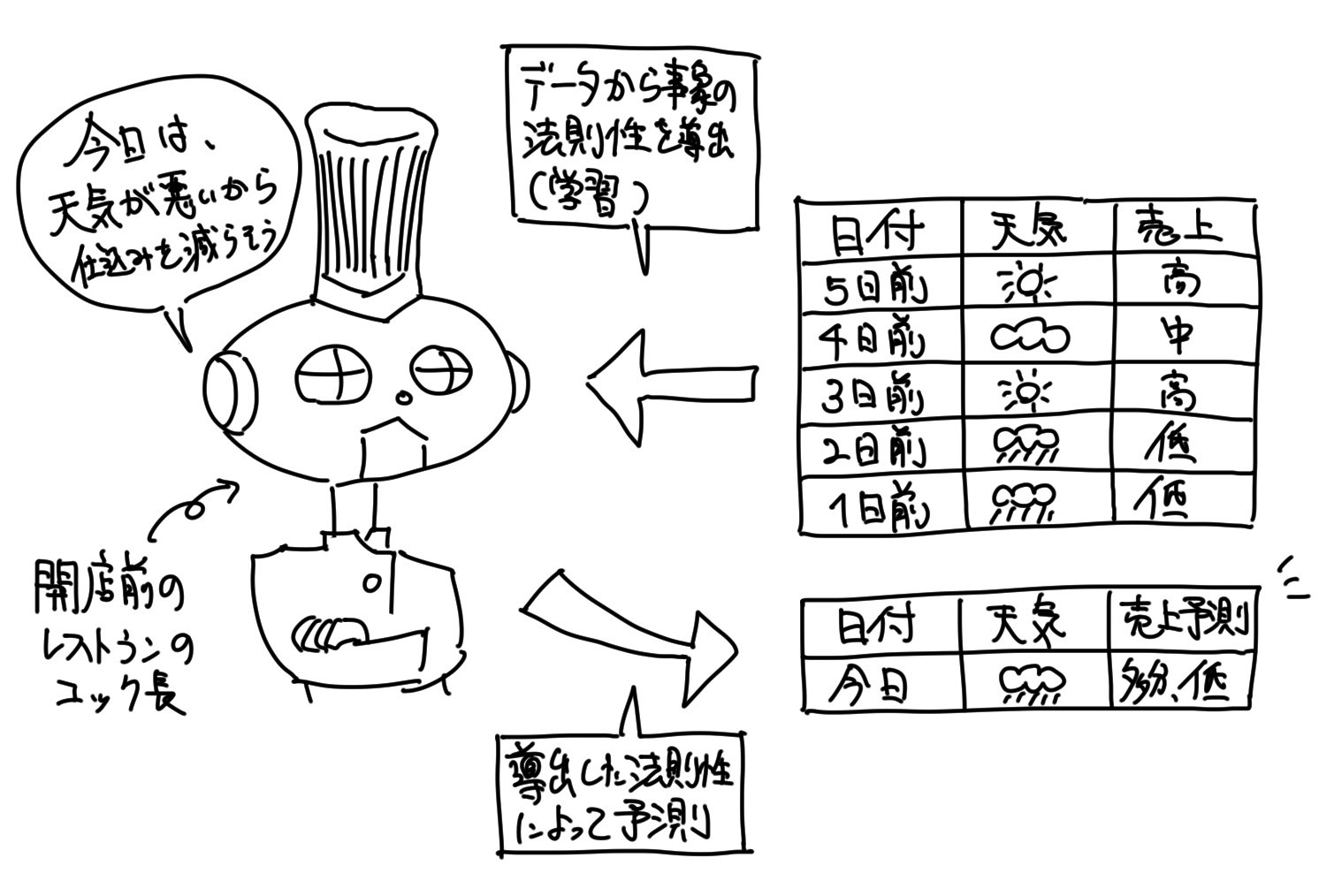
「機械学習」は、その「予測」を行うための知識の収集を、データから学習することによって実現します。
それは、これまで人間が行ってきた「学習」というものです。
それを人間に代わって、機械が実践する訳です。
尚、「予測」を行うための必要な知識の収集とは、事象の法則性導出をデータから行うことに他なりません。
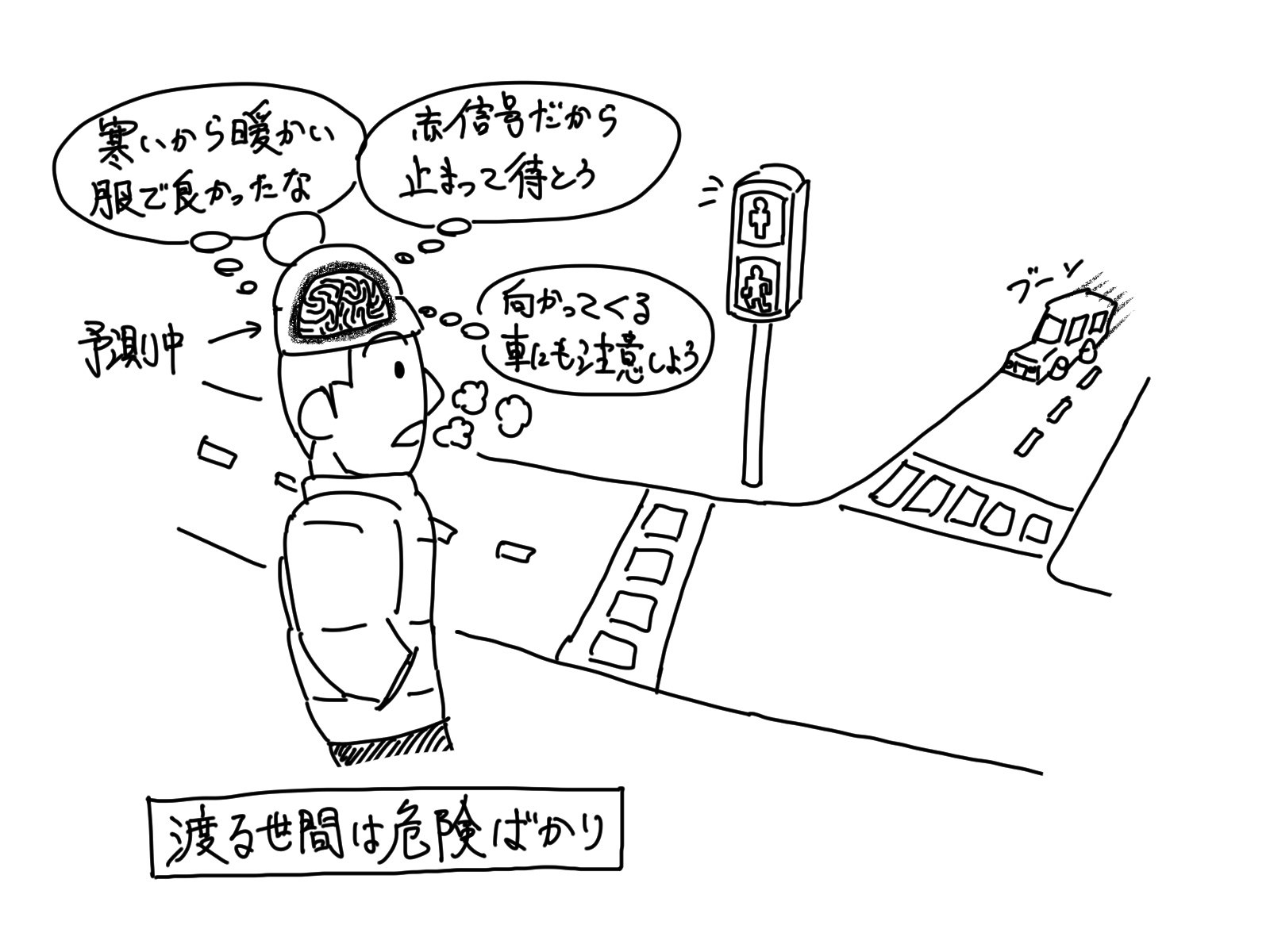
「予測」を行うことは、生き物全般にとっての根源的な学習の目的です。
生きるために、食べるために、怪我をしないために、ひいては、利得を得るため等々。
それら実現のために、生き物は皆、様々な「予測」を行います。
学習によって得られる情報や、経験、知識は、全てこの「予測」を行うためのものです。
もし、情報・経験・知識無しに「予測」を行う場合、全ての行動はギャンブル性を持ちますし、情報ありきでの行動に比べて圧倒的に成功率が下がります。
総じて、危険性が高くなるのです。
人間、或いは、生き物全般は、「予測」というものを頼りに危険性を回避し、生きています。
その為、「予測」のための情報収集は、生き物にとっての生きるための根源的な学習と言えるのです。
「予測」のための知識を得ることが「機械学習」である為、「予測によって実現できることは何か?」という投げかけは、「機械学習によって実現できることは何か?」という投げかけと同じことになります。
そして、その答えが「機械学習」の活用アイデア、つまり、「機械学習」を使う目的となります。
「予測」によって生まれる嬉しさについて考えれば「目的の設定」ができるのです。
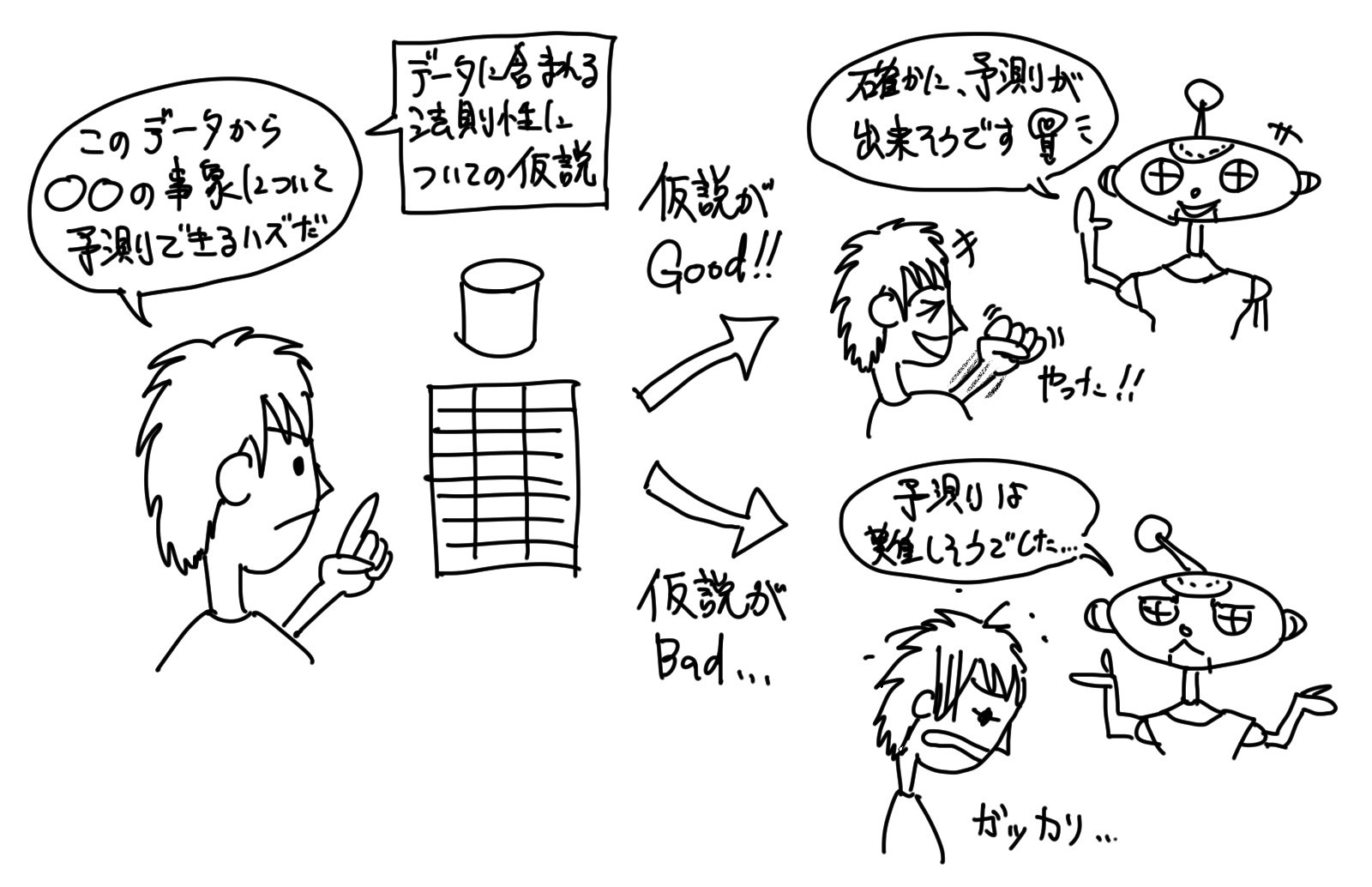
尚、データから「予測」についての知識を得るので、そもそもデータには、何らか事象を説明するような法則性が含まれている必要があります。
例えば、人間がそのデータを見た時に、何かしらの「予測」ができるようなデータであれば、「機械学習」によって「予測」のための知識が得られる可能性は高くなります。
データに「予測」のための法則性が含まれていない場合には、「機械学習」による知識の獲得は失敗に終わります。
そこには何の有効な情報も無いからです。
この辺りに関しては、データに所望の法則性が含まれるか否かを、人間が「予測」する必要があります。
手元にある「既存データ」を軸に考えても良い
「予測」を軸にアイデア発想するのが、いまいちピンとこない方は、「既存データ」を軸にアイデア発想するのも良いでしょう。
既に手元に存在するデータから、抽出できそうな法則性などを推察し、それによって「予測」できそうなものから、アイデアを発想すれば良いのです。
少し発想の軸を変えるだけですが、既に存在する具体的なデータから発想した方が考えやすいという方もいるでしょう。
「予測できると嬉しいこと」から「その予測をするためのデータ」を探すのか、「既存のデータ」から「その既存のデータから予測できそうなこと」を探すかの違いです。
ここで、これから取得することが予定されているデータ、つまり「非既存データ・未取得データ」については、注意が必要です。
データ取得に関するコストが低い場合、かつ、そのデータに対する知識やノウハウが既に豊富にある場合には、それを軸に発想することに、特に問題は無いかと思います。
そして、その発想したアイデアに高い価値があれば、少ないコストを払って、分析に舵を切るべきでしょう。
しかし、データ取得に多くのコストを要する場合や、「未取得データ」に対して無知な場合には、それを軸にした発想を避けた方が良いでしょう。
自信を伴わない、高コストな「攻めの戦略」は、非常にリスクが高いという訳です。
また、データ分析はやってみるまで、結果が分からない側面があります。
何も結果が出てこないというリスクが、常に存在しています。
その為、少なくとも仮説に自信が生まれるまでは、取り組むべきではないと私は考えます。
「目的の設定」を行う際に役立つツールや考え方
「目的の設定」、即ち、「機械学習」活用のアイデア発想方法は様々あります。
例えば、以下のページに紹介されるようなものが、非常に有用です。
アイデアの発想フレームワーク7選
https://creive.me/archives/6722/
アイデアを出す正攻法 6 選とアイデアに困った時の奥の手 3 選
https://navi.dropbox.jp/idea
一瞬で劇変させるアイデアの出し方11選
http://re-sta.jp/how-to-put-out-ideas-891
基本的な考え方から、一定のフレームに沿って考える「フレームワーク」など、様々なものが紹介されています。
「ブレインストーミング」や「なぜなぜ分析」等は非常に有名な方法であり、シンプルでありながらも非常に有用な発想法だと思います。
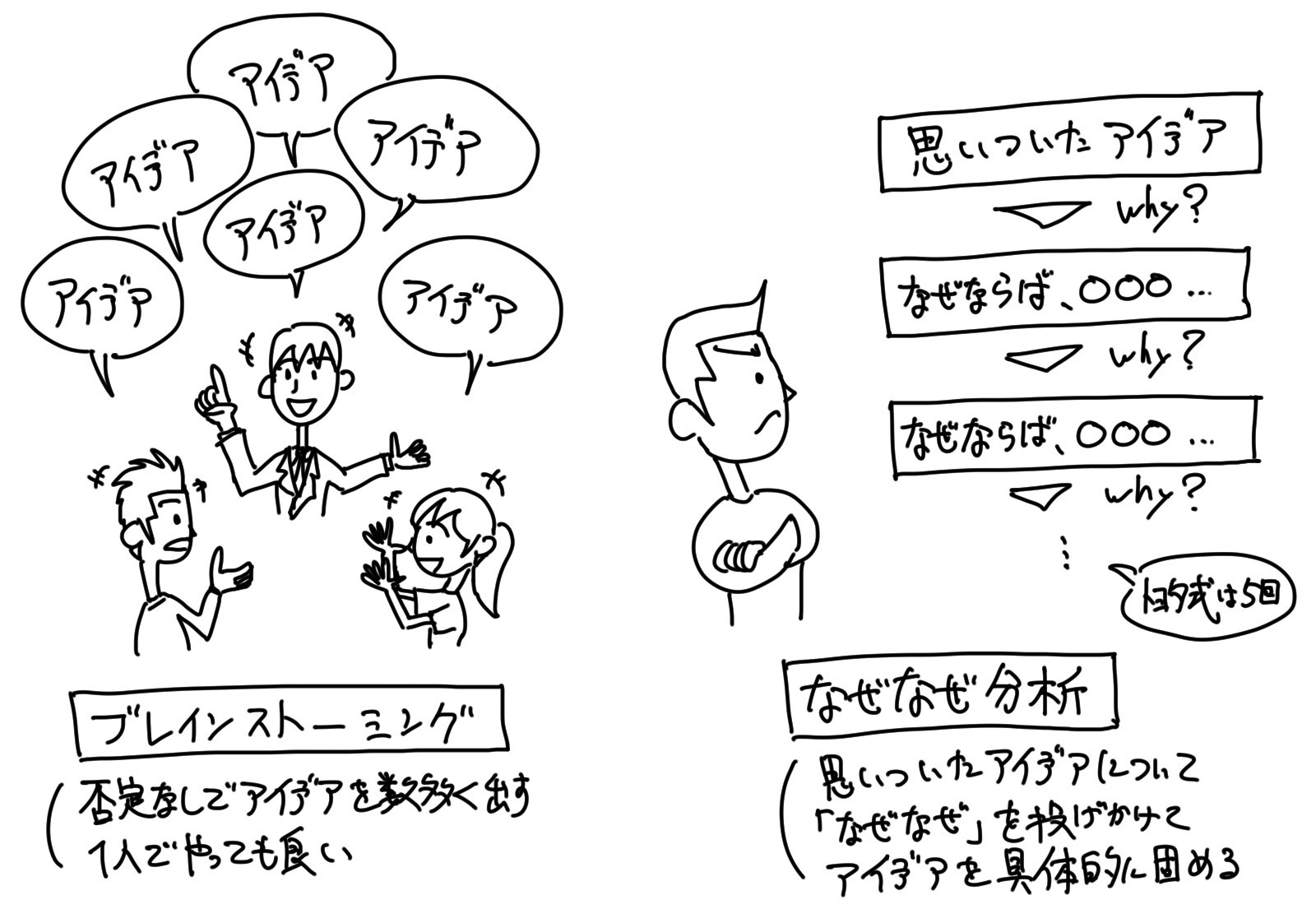
また、「機械学習」の活用目的は、とかくメルヘンになってしまったり、フワッとしてしまいがちです。
「機械学習」で実現できることの幅が広いゆえのことですが、目的は明確に設定する方が、分析の成功確率が高くなります。
より具体的に決めるのです。
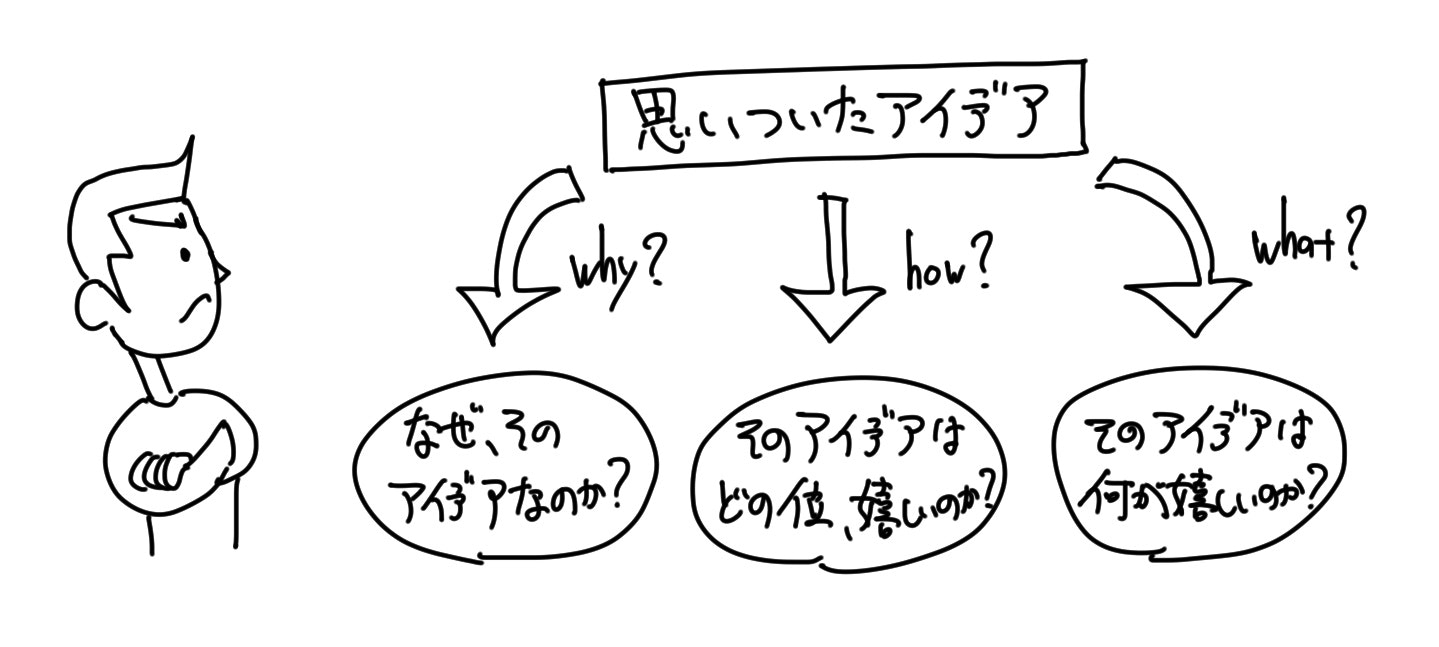
例えば、「希望点列挙法」や「欠点列挙法」を行う際は、それによって発想されたアイデアに対して、「なぜなぜ分析」で考えを引き締めるアプローチなどをすると良いでしょう。
「なぜなぜ(why?)」だけでなく、「どの位どの位(how much profit?)」「何何(what data?)」なども一緒に分析すると良いでしょう。
「機械学習」における2つのアイデア発想アプローチ
また、「機械学習」におけるアイデア発想については、大きく2通りのアプローチがあります。
それは、以下の2つです。
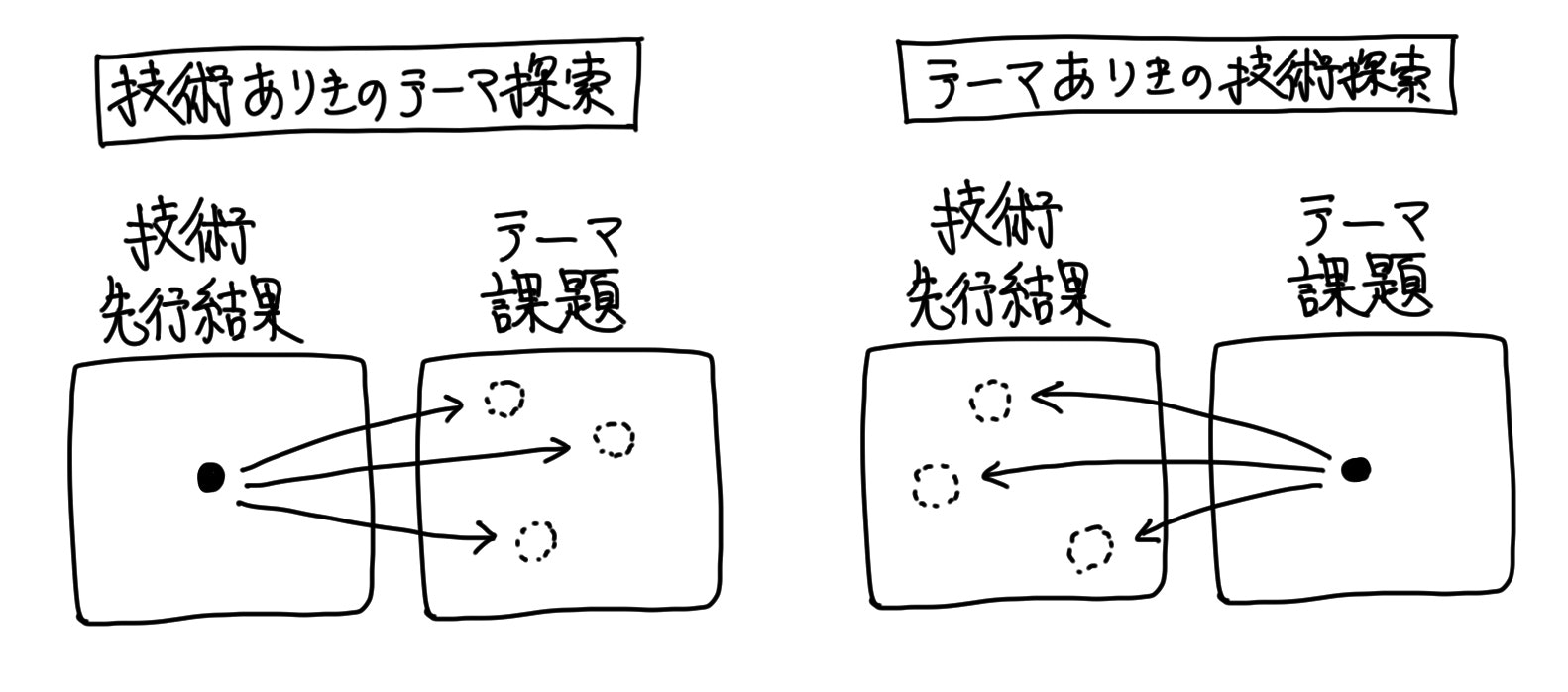
「アプローチ1:技術ありきのテーマ探索」
過去に事例のあるテーマや、研究段階のテーマについて、そこで使われている「機械学習」の技術実現を、他テーマに適用する
「アプローチ2:テーマありきの技術探索」
過去に事例のないテーマについて、適用できる「機械学習」の要素技術を模索する
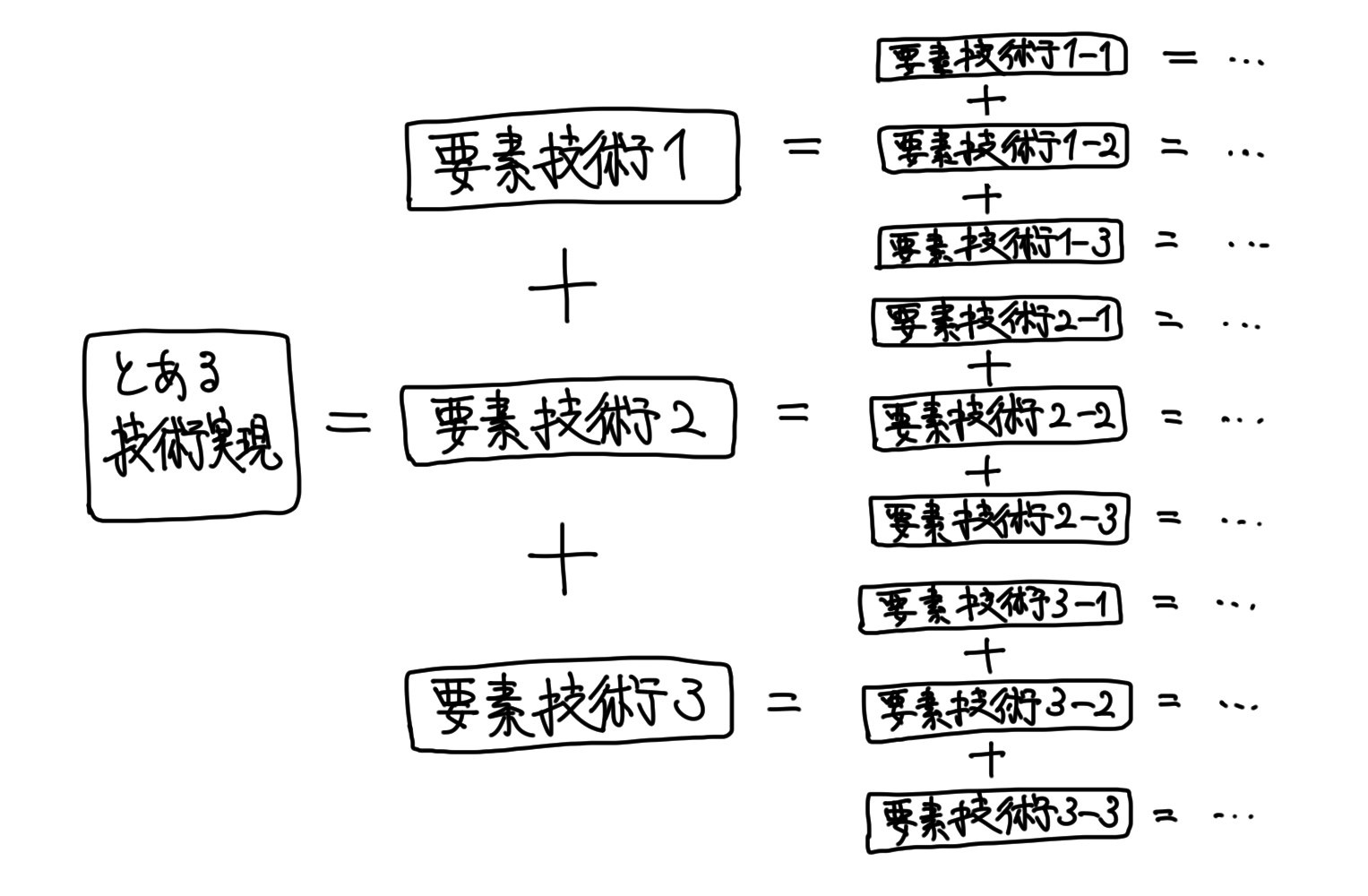
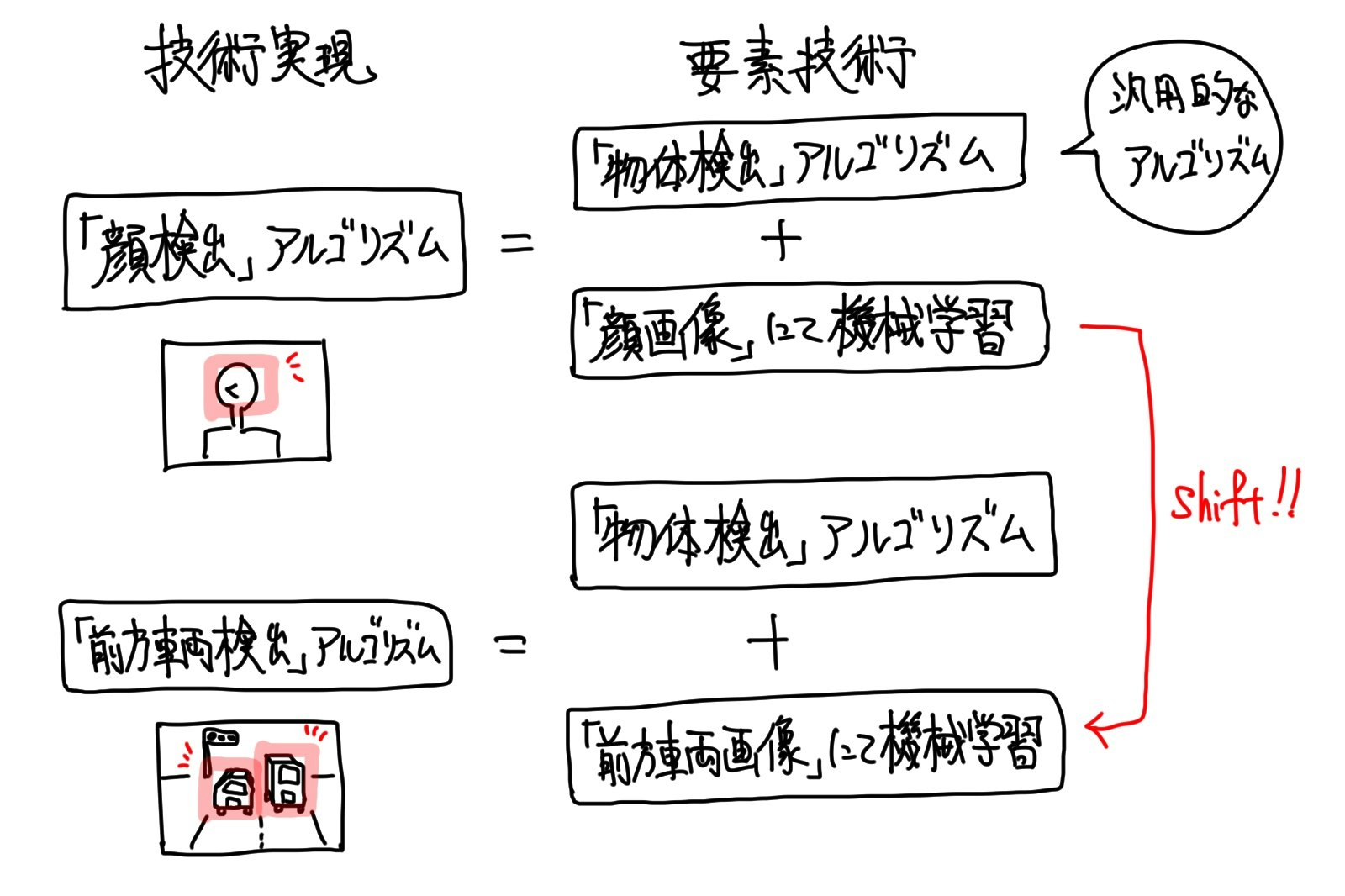
先ず、上記の「要素技術」という言葉について触れます。
「要素技術」とは、大枠の技術を構成する個々の技術のことです。
抽象的な技術実現の内にある、それを実現するための具体的な個別の実現技術のことです。
抽象的な技術実現は、一段具体的な実現技術から構成されるものであり、その具体的な技術もまた、更に一段具体的な実現技術から構成されるものです。
その一段具体的な実現技術のことを、「要素技術」と言います。
何かしらの技術実現を、別テーマへ応用する場合には、「要素技術」から把握している必要があります。
把握している「要素技術」が幾段にも深ければ、より広い範囲での応用が可能となります。
例えば、最近のスマフォではすっかりお馴染みの、カメラアプリにおける「顔検出」機能で言うと、「物体検出」アルゴリズムが「要素技術」となります。
「顔検出」は、カメラ画像で撮影した画像に対して、「顔」を検出するためにチューンナップされた「物体検出」アルゴリズムを適用して、画像中のどこに「顔」が映り込んでいるかを見つけるものです。
「顔」を検出するためのチューンナップは、「機械学習」等によって行われます。
沢山の「顔」画像を見せて、それらに共通する法則性を導出することによって、カメラ画像中から「顔」を探せるようになるのです。
「顔」以外にチューンナップすれば、例えば、自動車CMなどでお馴染みの「前方車両検出」や「道路の白線検出」や「歩行者検出」などの応用も可能となります。
さて、アプローチの話に戻すと、上記のカメラアプリの例は、一般的なテーマとして元々盛んに研究されてきた「顔検出」の技術実現を、そのまま製品に組み込んだ例であり、「アプローチ1」のアイデア発想になります。
論文やニュース等で発表される技術をウォッチして、それを新しいサービスや、既存のサービスの置き換えに使えないかを模索するアプローチです。
技術実現ありきで、それを横展開できるテーマを模索する訳です。
一般的に、「機械学習」の適用というと「アプローチ1」のような適用の仕方をイメージする方が多いかと思いますが、それとは真逆のアプローチが「アプローチ2」です。
逆というのは、技術実現から課題に当てはめていく「アプローチ1」に対して、逆に課題から適用できる「機械学習」技術を模索するアプローチという意味です。
「アプローチ1」よりも守備範囲が広く、汎用的なアプローチです。
実際、これまでに「機械学習」についての論文やニュース等で発表されてきた技術は、世の中にある課題の内の極々一部を解決したに過ぎず、ニッチな課題への適用は「アプローチ1」では難しいことが多いです。
その為、どうしても解決したいニッチな課題があり、そこに「機械学習」を適用させようとする場合、その解決方法が発表されるのを待って適用するか、自ら「機械学習」の適用方法を考えて解決するかの2択となります。
その前者が「アプローチ1」であり、後者が「アプローチ2」です。
「目的の設定」のための「アプローチ1:技術ありきのテーマ探索」との向き合い方
技術ありきの「アプローチ1」は、技術的な成功は保証されている為、その心配をせずにビジネスに向き合うことができます。
「機械学習」の実現性検証に時間をかける必要は無く、それをどうビジネスに活かすか、どう顧客の嬉しさに繋げるか、そんなテーマ探索に集中することができる訳です。
しかし、一方で「天下一アイデア大会」の様相を呈します。
皆が、その確立された技術を応用せんと群がってしまい、どうしてもレッドオーシャンとなってしまうのです。
よって、このアプローチにて、ビジネスを成功させるにはスピード感を持って取り組まなくてはなりません。
行動力と、発想力と、実装力を持って、とにかく早く形にすることが成功の秘訣です。
或いは、セブン&アイ・ホールディングスの鈴木敏文さんのような、誰も思いつかないようなアイデアでもって、周りを出し抜く必要があります。
そういったことが得意な方や、アイデア思考が好きな方には、非常に向いているアプローチかと思います。
「目的の設定」のための「アプローチ2:テーマありきの技術探索」との向き合い方
テーマありき「アプローチ2」は、「この課題が解決すれば確実に利益が見込める」というようなビジネス的な成功が保証されている為、その心配をせずにデータ分析に集中することができます。
「どんなデータを使えば良いか?」「どんな機械学習アルゴリズムを適用すれば良いか?」といったことにのみ知恵を絞り、良い分析結果さえ出せば良いのです。
しかし、これは「機械学習」について、ある程度深く知ってなくては実現できないアプローチです。
Alpacaという「株価予測」アプリを作っている会社がありますが、彼らは画像識別用のアルゴリズムを、「株価予測」に適用するためにコンバートしたといいます。
勿論、画像識別アルゴリズムをそのまま適用する訳ではなく、何段か上位(原理に近い側)の要素技術を「株価予測」という課題に適用したのです。
(恐らく、画像と株価推移に共通する視覚的な捉え方を見出して、適用したところ上手くいったというアプローチかと思われます。)
「アプローチ2」では、そんな研究要素の強い試みを経て、結果にコミットするストイックさが求められます。
裏を返せば、いくらトライしても上手い分析結果に辿り着けないことも往々にしてあります。
或いは、実用には今ひとつ精度が足りない場合などもあります。
また、結果として、しばしば労働集約型な働き方に陥ったりします。
そんなリスクが多く潜伏しているのが「アプローチ2」です。
しかし、「機械学習」で良い結果が出ないリスクについては、緩和するコツが1つあります。
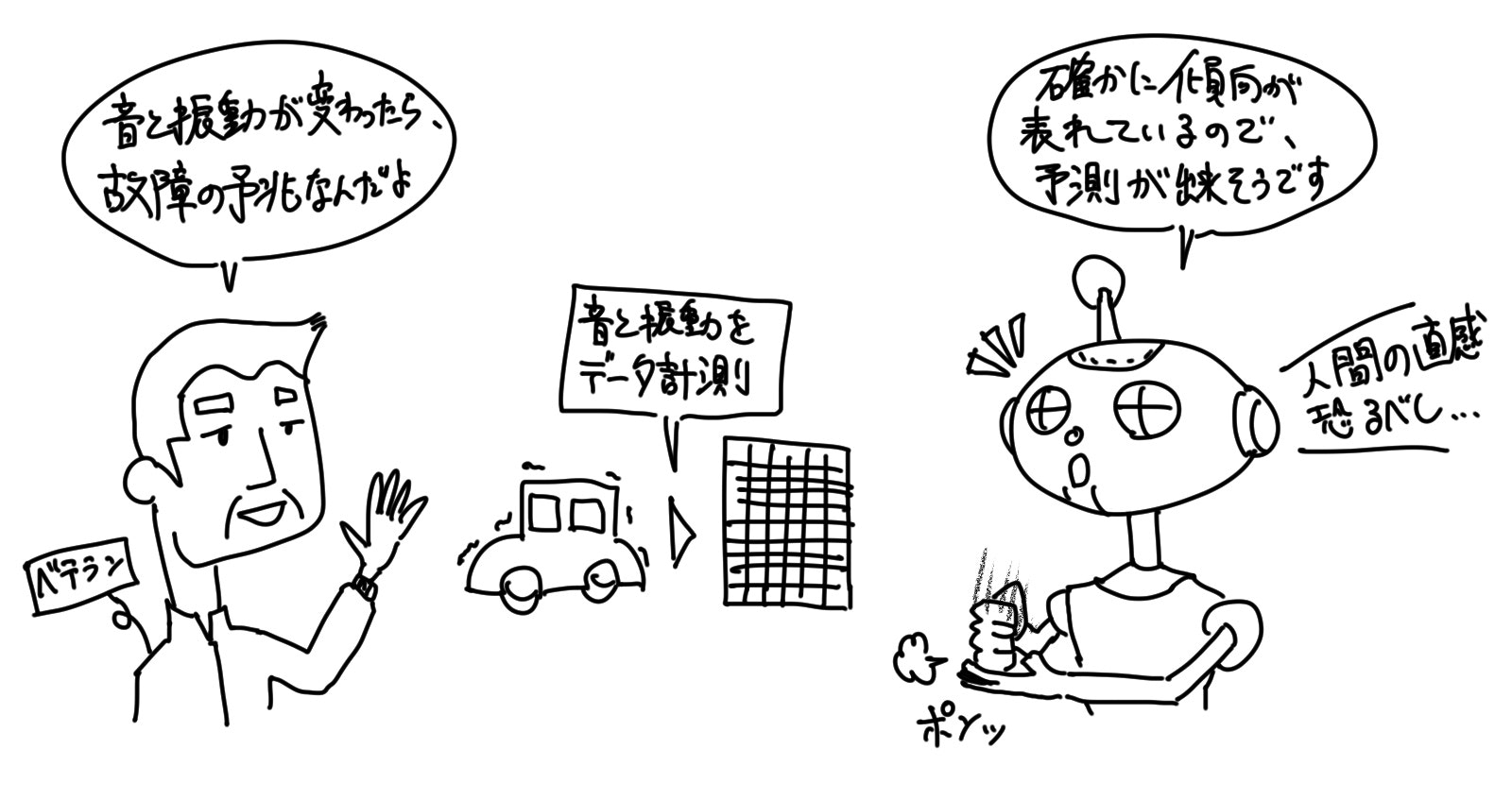
そのコツは、「機械学習」を適用しようとしている課題を、逆に人間ならば解決できるかどうかを考えてみる、というものです。
何だか、ニワトリタマゴのような話ですが、「人間にできるならば、機械にも判断できる」という論理が、「機械学習」の成否判定基準によく使われます。
例えば、ベテランの方が「データのこの辺を見ると、何となく分かるんだよ」という風に、直感的に答えを見出せるような課題であると「機械学習」の適用が上手くいきやすいのです。
人間を模している「機械学習」だけあって、人間が直感や経験にて解決できる課題は、「機械学習」でも解決ができるという考え方です。
画像識別や、自然言語処理などの課題は、その最たる例といえます。
逆を言えば、人間がいくら考えても、全く解決の糸口が見当たらないような課題や、解決策の仮説が立てられないような課題などは、「機械学習」で解決できないことが多いです。
その辺りの見極めは、「アプローチ2」を実践する上で非常に重要です。
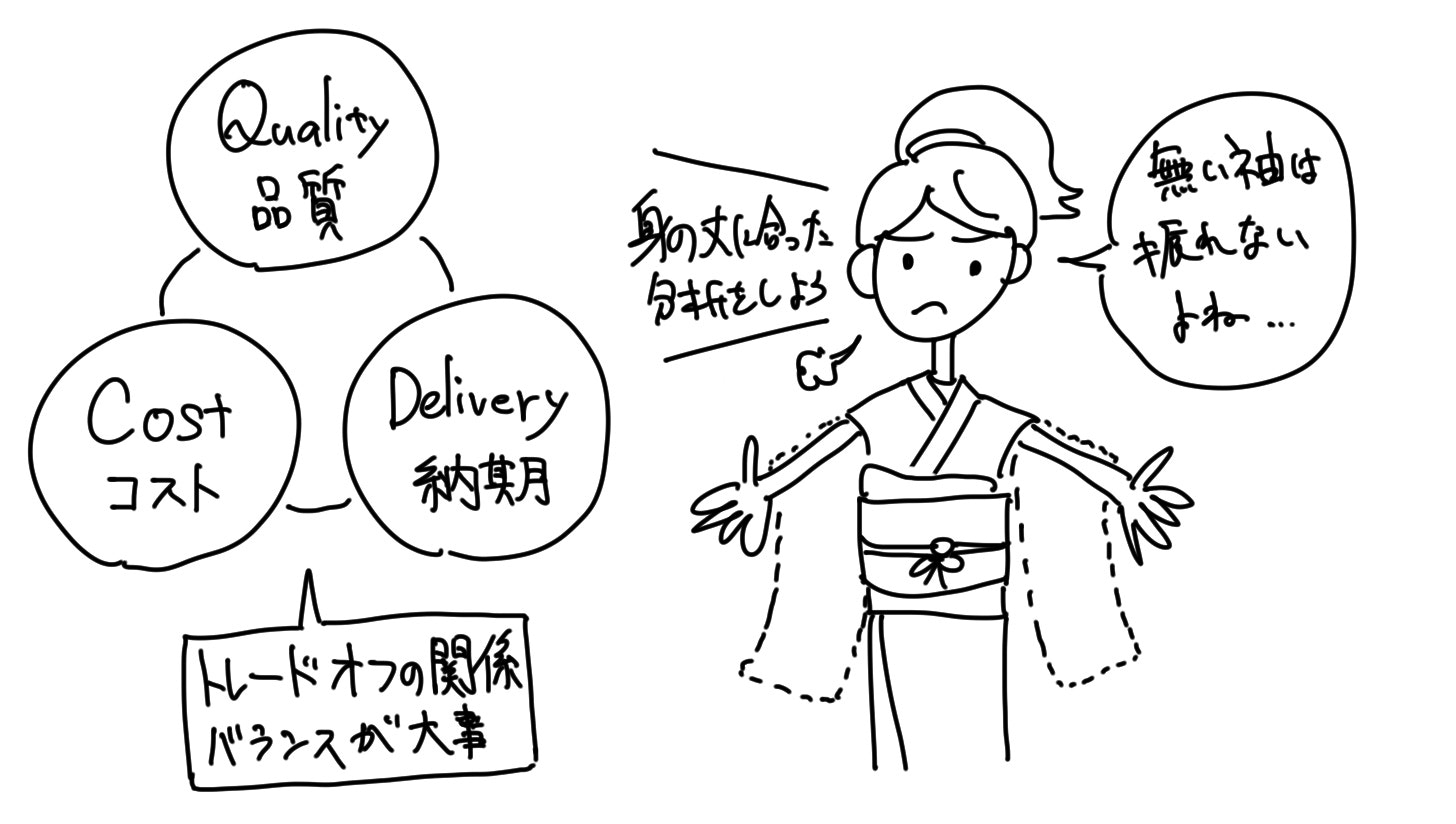
「目的の設定」ができたら最後にQCDを確認する
晴れて「機械学習」を適用する「目的の設定」が完了したら、最後にQCDを確認します。
QCDとは、「Quality Cost Delivery」の頭文字を取った用語で、データ分析業務であれば、「Quality:品質は担保できるか?」、「Cost:単価に見合った成果を担保できるか?利益は確保できるか?」、「Delivery:納期は担保できるか?」という視点でのセルフチェックを行うためのものです。
要するに、無謀な「目的の設定」がなされていないかを確認するのです。
基本的には、どうやってもトライアル&エラー要素が含まれてしまうのがデータ分析の特性ですが、そもそもQCDのバランスが良くない目的に取り組むことは問題があります。
特に、顧客よりデータ分析を依頼されて実施する場合は、尚更です。
品質の担保できる、コストに見合った分析を、期間内に終えなければなりません。
どうしてもチャレンジブルな「目的の設定」を行う場合や、どうしてもコスト度外視の「目的の設定」を行う場合には、その状況を関係者間で共有した上で、過度な期待をせずに「機械学習」適用に挑戦する形で進めていく必要があるでしょう。
「機械学習」というバズワードに乗っかったコンセプトベースの目的はNG
最後の最後に、「目的の設定」に関して、念を推しておきたいことがあります。
それは、「機械学習が流行っているから、機械学習を用いた分析を何かしらやってみたい」というコンセプトベースのトライアルには十分に注意をする必要がある、ということです。
新しいものに挑戦することは決して悪いことではありません。
むしろ、評価すべきことでしょう。
注意が必要なのは、「目的の設定」が先行事例やニーズをベースとしていない場合に、例え分析が上手くいったとしても、それがビジネス的な恩恵に繋がらないことを、予め認識しておくことです。
或いは、ビジネス的な恩恵を得たいのであれば、「目的の設定」はしっかりと行わなくてはならず、仮にそれを飛ばして分析を進めても、それは「目的の設定」のためのプレトライアル(お試し分析)になるかと思います。
つまりは、紹介させていただいているデータ分析プロセスは、必ず順番に実施する必要があるもので、基本的にはスキップができないものです。
飛ばしたプロセスは必ず、後に実施が要求されることとなります。
ただし、後に控えるプロセスを意識しながら、前段のプロセスを実施していくというような、イメージを先行させる方針は、むしろ良いかと思います。
問題は、実際に着手してしまった場合の手戻りです。
データ分析は、非常に手間と時間のかかる作業となるので、なるべく無駄な手戻りが無いよう取り組むべきです。
プロセス2つ目「目標の設定」
さて、「目的の設定」が完了したら、次に行うプロセスは「目標の設定」です。
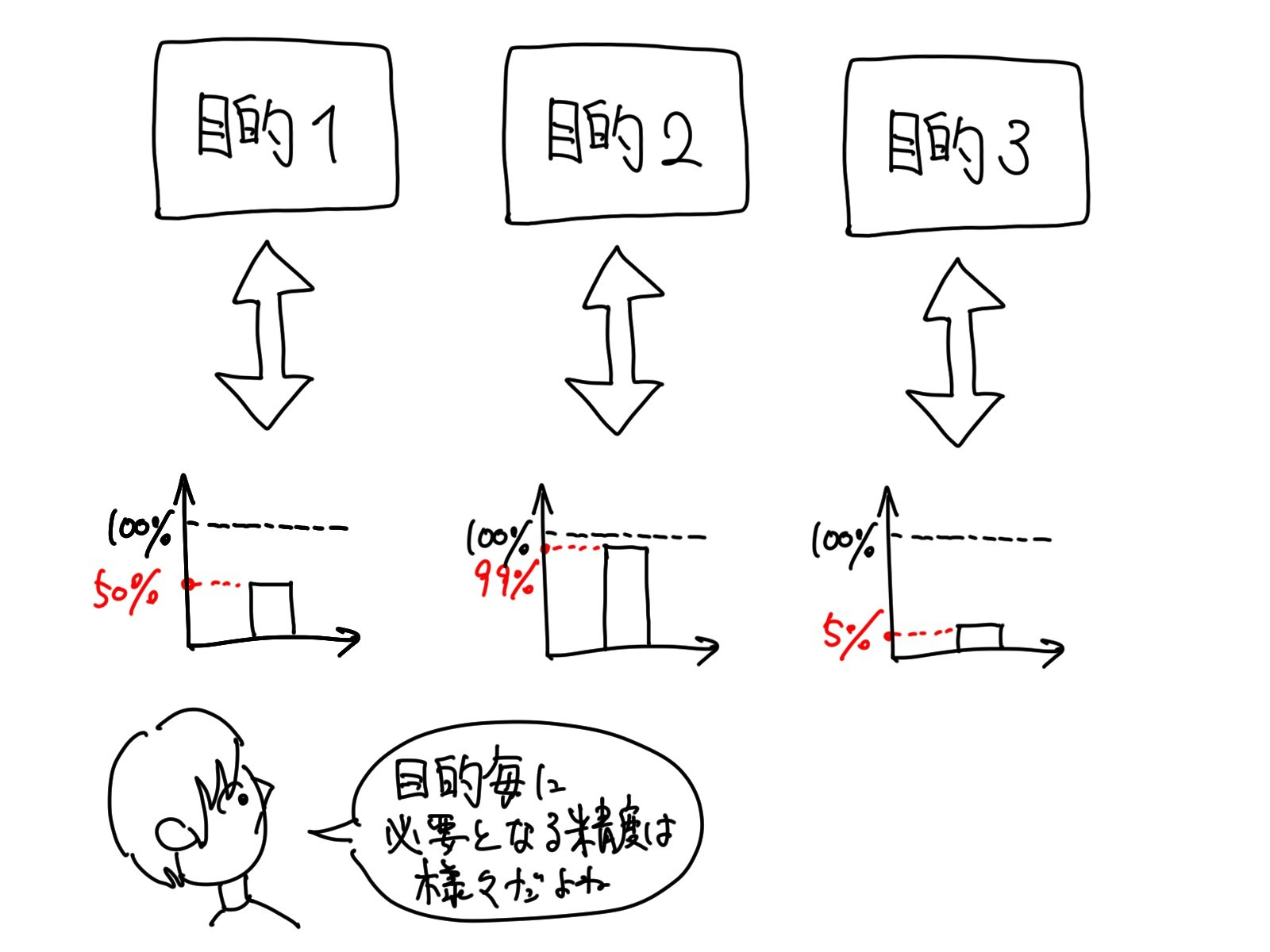
「目標の設定」は、「機械学習」による分析の精度がどの位まで引き出せたら実用に耐え得るか、を考えるプロセスです。
例えば、WEB上でお買い物ができる「Amazon.com」について考えてみます。
「Amazon」には、ある商品を購入すると、関連・類似商品の購入も推奨してくれるレコメンド機能というものがあります。
例えば、過去に購入したマンガ本の新刊発行時に推奨をしたり、包丁を購入した際に砥石の併せ買いを推奨したりするのがレコメンド機能です。
このレコメンド機能に、「機械学習」が使われています。
レコメンド機能は性質として、「推奨して買ってもらえたらラッキー」という広告的なものですので、「機械学習」による「予測」の精度は、10%程でも万々歳というものでしょう。
10回レコメンドした内の1回は買ってもらえるわけですから。
むしろ、精度を追求するあまり、リリースが遅れて機会損失してしまうことの方がリスクです。
ですので、例えば、少し緩めに「目標:予測精度5%」というような目標が制定できます。
また、自動運転に向けて自動車に搭載される「走行レーン(道路)認識」「前方車両認識」「歩行者認識」などの機能についても考えてみます。
これらは、車載カメラで撮影される映像から、その車両の周辺状況を把握するための機能です。
それら認識結果から、自動的に車体にブレーキをかけたり、スピードを調整したりする訳です。
人の命に関わる機能になりますので、できるだけ100%に近い精度を求める必要があります。
ですので、例えば、「目標:予測精度99%」というように厳しめの目標を設定します。
未知のデータに対して、100%の「予測」精度というのは難しい
「機械学習」によって導出するデータの法則性は、実運用してからの未来のデータに対して「予測」精度が高くある必要があるという話を、当該連載の第3回の記事にてさせてもらいました。
未知のデータに対する「予測」精度が高くないと、実運用してからの価値が全くないのです。
その為、「目標の設定」にて掲げる精度については、その度合を抽象的に設定するにしろ、具体的に設定するにしろ、未知のデータに対する「予測」精度を基準としなければなりません。
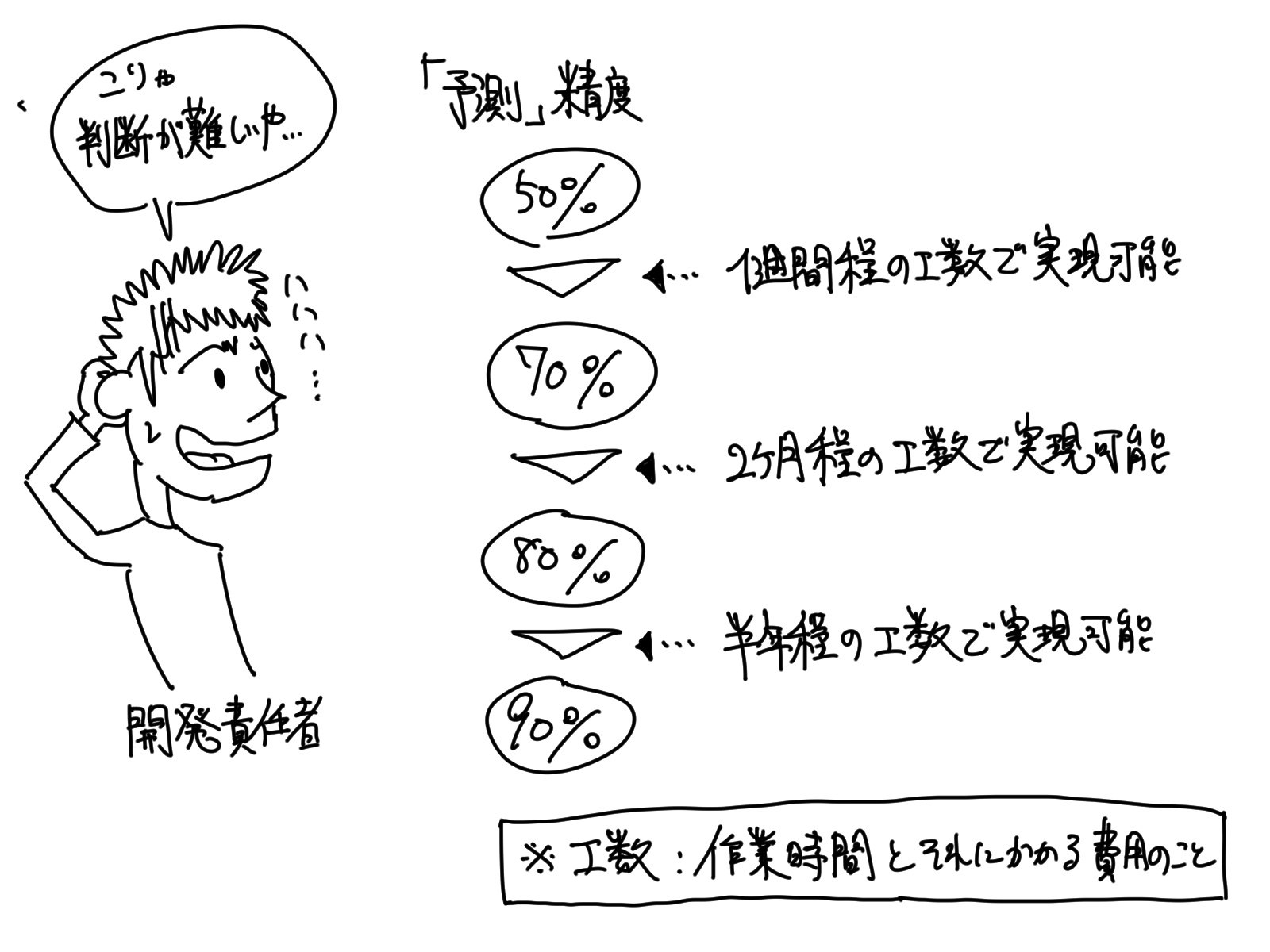
その「予測」の精度についてですが、全くの「予測」ミスを許さないサービスに適用するからと、「目標:予測精度100%」と設定するのは避けた方が良いです。
データには少なからず誤差が含まれることもあり、なかなか100%の精度を引き出すことは難しいです。
以下に、かけるコストと精度の関係性をグラフで示します。
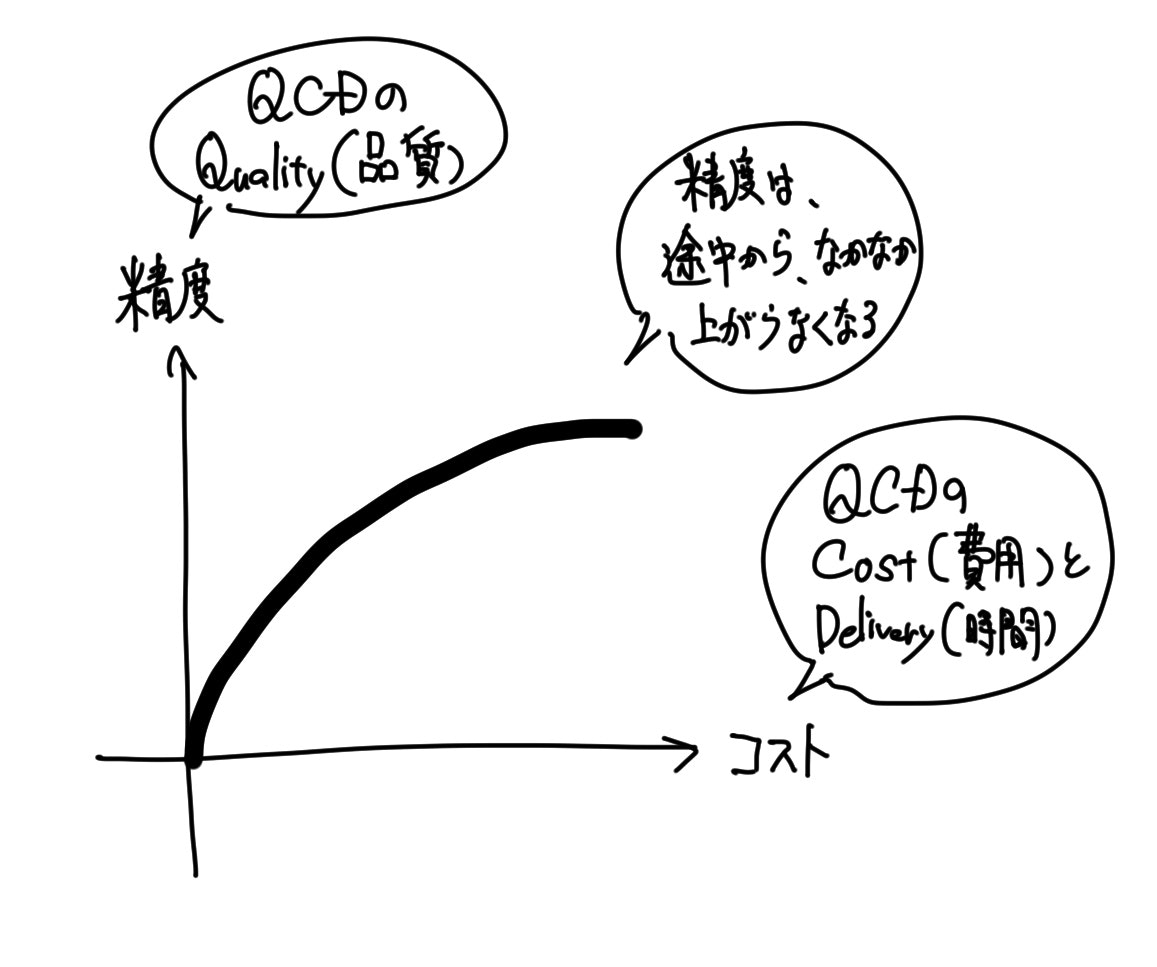
その為、サービスの運用方針を見直して、予測精度の不完全性をフォローするなどした方が賢明です。
或いは、自動運転関連の研究開発よろしく、超多額の投資を行う準備があれば話は変わってきますが、身近な課題に対して「機械学習」を適用する場合には、そんな余裕もなく、QCDを鑑みた現実解に落とし込む必要があります。
プロセス3つ目「データ選定」
「目的の設定」と「目標の設定」を終えましたら、次は「データ選定」を行います。
序盤プロセスの中での、最終プロセスとなります。
「データ選定」では、「設定した目的を果たすためには、どんなデータを使えば良いか」ということを考えます。
つまり、分析対象のデータを何にするかを決めるのです。
仮に、あなたが社内の情報システム部門のメンバーだったとして、課題として「スパムメール対策」を抱えているとします。
そして、その課題を解決すべく、「機械学習」による「予測」を用いてスパムメールを識別する仕組みを構築し、その仕組みを社員のパソコンにインストールさせて、メールを開く前に「このメールはスパムメールである確率が高いです」という通知をしてくれるようにしよう、と考えました
<図>
その為、「機械学習」を用いる目的は、「目的:スパムメールの識別」と設定しました。
目標の「予測」精度は、10個飛んで来たスパムメールの内の7〜8個が自動で弾ければ良いだろう、と考え、70%と設定することにしました。
一方で、スパムメールじゃないメールが飛んで来た時に、それをスパムメールだと誤識別されても困るので、その誤識別率を1%以下とすることも目標に加えることにしました。
よって、目標は「スパムメールをスパムメールと識別する正解率を70%以上、通常メールを通常メールと識別する正解率を99%以上」と設定しました。
ここまでは、「データ選定」よりも前のプロセスになります。
そして、次に「データ選定」のプロセスを実行します。
設定した目的を果たすために、どんな情報があった方が良いか、という観点で必要なデータを考えるのが、このプロセスで行うことです。
このプロセスに関しても、拡散型思考が必要となり、ブレインストーミング的に次々と連想していく必要があります。
スパムメールの識別をするために、先ずは「スパムメールの文面」「スパムメールの送り元」「スパムメールが受信時間」などのデータは必要でしょう。
なぜなら、「1兆円が当たりました!」なんていうか文面があったら、スパムメールである確率が非常に高いですよね。
「abcdefgvwxyz@spam.com」なんていう、あたかも自動生成したような送り元アドレスも、スパムと判断する材料になりそうです。
深夜時間帯に受信されたメールも、疑ってかかった方が良いかもしれません。
或いは、スパムメールに関する被害がニュースなどで取り上げられているタイミングだと、可能性が高くなるかもしれないので、その情報もあると良いかもしれません。
或いは、季節性も関係あるかもしれないので、日付情報や気温や湿度もデータ取得できると良いかもしれません。
或いは、…という感じで連想していきます。
<図>
また、通常メールに関する同様のデータも必要です。
スパムメールと通常メールを相互に分析することによって、それらの間にある差がハッキリする為です。
<図>
そうして、関係ありそうなデータを見繕っていって、スパムメールの「予測」のための知識、即ち「スパムメールの法則性」を導出するために、必要であろうデータを選定するプロセスが「データ選定」です。
「必要そうなデータ項目リスト」を作成することが、このプロセスのゴールとなります。
ちなみに、話は逸れますが、スパムメールの由来はあのスパムからだそうです。笑
スパムメールの由来
https://moto-neta.com/it/spam-mail/
先ずは、関係がありそうなデータ項目を、なるたけ多く選定した方が良い
「データ選定」を行う際には、なるべく多くのデータ項目を選定することをオススメします。
それが分析を成功に導くコツです。
なぜ多く集めた方が良いかについては、より多くの穴を開けた方が、温泉を掘り当てる確率が上がる原理と同じです。
「下手な鉄砲、数撃ちゃ当たる」と言っても良いでしょう。
どのデータにどのくらいの法則性が埋もれているかを、事前に見積もることはできません。
その為、なるべく多くのデータ項目をピックアップした方が、後に導出される法則性が「予測」精度の高いものとなる可能性が高いのです。
<図>
尚、関連として、「データマイニング」という言葉があります。
「データマイニング」とはデータからの知識獲得のことを言います。
特に、想定外の発見的な知識獲得のことを指すことが多く、正に「データ地盤からの知識温泉採掘」というニュアンスです。
「データマイニング」の詳しい説明は、wikiを参照ください。
次に、リソースと相談しながらデータを絞っていく
なるべく多くのデータ項目を選定することをオススメしておいて何なのですが、次にリソースと相談しながら項目を削っていくことをオススメします。
「リソースとの相談」とは、大きく以下の2つの観点です。
- 計算リソースとの相談:手持ちのコンピュータにて、十分なスピードで分析処理が実施できるデータ項目数・量であるか?
- 資源リソースとの相談:データを取得するのにかかるコスト(資金・労力・時間)が許容範囲内であるか?
「計算リソースとの相談(①データ項目数)」
「計算リソースとの相談」は、分析に要する時間との相談です。
一般に、分析対象のデータ項目数が倍に増えれば、分析に要する時間は単純計算で倍の時間となります。
「人によるデータ確認」や、「機械学習の学習処理」などの全ての分析作業について、それぞれ概ね倍の時間かかってきます。
ここにデータ項目数と、分析に要する時間との関係を示します。
<図>種類数とは
しかし、先程説明したように、それによって精度が上がることもまた事実であり、この辺りの兼ね合いが重要です。
少なくても精度が上がりきらない、多いと時間がかかり過ぎるというトレードオフに対する兼ね合いです。
できるだけ主要なデータ項目だけを残し、関係性が薄そうな項目は削る、ということが出来れば理想的です。
<図>
尚、このトレードオフの兼ね合いについては、手持ちのコンピュータの処理速度や、どの位丁寧にデータ確認するかという分析方針や、分析精度目標によっても変わります。
特に、高い識別精度を求められる場合には、どうしても大量のデータ項目が選定する必要があります。
その場合、処理の高速なハイスペックコンピュータを使用したり、データの確認などはある程度ラフに行うなどして、嵩んでしまう分析時間の短縮を試みることが求められます。
画像識別などはその最たる例です。
<図>
「計算リソースとの相談(②データ量)」
「計算リソースとの相談」は、データ量についても考慮します。
データ項目数はデータの種類の数でしたが、データ量はそれぞれの項目毎の過去の履歴数・レコード数です。
一般にデータ量が多い程、分析精度は上がる傾向にあります。
<図>
データ量についても、その数が多い程、分析にかかる時間は増えていきます。
しかし、ここに大事なポイントがあり、かかる時間が増えるのはコンピュータの処理時間増加が主となります。
というのも、「機械学習」の処理時間やデータ参照の負荷が増えるものの、「人によるデータ確認」にかかる時間は、そう変わらない為です。
なぜならば、「人によるデータ確認」は一般的に、その統計量(平均・標準偏差・最大値・最小値など)や、内容を一目で確認できるようサマリーした図(プロット図・ヒストグラム図など)によって確認するからです。
この「人によるデータ確認」の方針は、データ分析における鉄板の方針です。
サマリーされた情報は、概ねデータ量を問わず一定量のものですので、確認にかかる時間もデート量を問わず概ね一定となります。
<図>
ですので、データ量との兼ね合いについては、ハイスペックコンピュータを持っている場合には、あまり考える必要がありません。
逆に、チープなコンピュータである場合には、処理速度を観察しながら、データを絞る必要性を考える必要があります。
データを取り込むだけで、コンピュータの物理メモリ容量(処理用データを、一度に取り込める容量のこと)が一杯になることも珍しくありません。
<図>
「資源リソースとの相談(コスト:資金・労力・時間)」
「資源リソースとの相談」は、このプロセスにおいても、先程来説明しているQCD観点でのチェックを行うということです。
「Quality」は高い程良いのですが、それを高めるために、分不相応に高い費用が必要であるとか、労力がかかり過ぎるとか、時間がかかり過ぎるなどといった状況は避けたいものです。
研究成果によって、そのコスト支出を取り戻すことができれば良い、つまり、ペイできれば良いですが、ペイできる強い自信が無い限りは、先ずは抑え目で様子を見た方が良いでしょう。
その実践を表す「スモールスタート」や「アジャイル開発」といった言葉があります。
「スモールスタート」は、最初は小さな規模で始めて、上手くいくようなら徐々に事業規模を大きくしていくという考え方です。
「アジャイル開発」は、小規模に抑えた開発工程を高速にグルグル回しながら、少しずつ開発対象に改善の肉付けを行なっていき、最終的には大規模な開発にまで仕上げるという考え方です。
分析プロセスに当てはめていえば、「目的の設定」から「精度測定」までのプロセスをザッと実施して、課題がありそうなプロセスに戻って改善をして、そこから「精度測定」までのプロセスを再びザッと実施して…というサイクルを繰り返すイメージです。
この2つの考え方が、データ分析には向いています。
結果にどうしても未知性を含んでしまう「機械学習」が間に入っていれば尚更です。
サイクルを回す毎に、「機械学習」で実現できそうなレベル感が見えてくるのです。
<図>
「スモールスタート」や「アジャイル開発」を適用することで、「資源リソースとの相談」は自ずと実現されます。
「データ選定」の仮説に自信が無い場合には、それを適用するのが良いでしょう。
もし、設定した目的に関わるデータが見つからなかったら、「目的の設定」プロセスに戻る
「データ選定」について、設定した目的に対して有効そうなデータが無かった場合や、「アジャイル開発」的にザッとプロセスを回してみた結果に何の兆しも無かった場合には、「目的の設定」のプロセスに戻ることをオススメします。
つまり、元の目的は捨てるということです。
データが無かった場合は、言うまでもないでしょう。
プロセスが前に進めないので、目的を変えざるを得ないのです。
ザッとプロセスを回した結果に何に兆しも無かった場合は、悩ましいですが、データに目的を果たすための情報が含まれていない(つまり、「データ選定」の当たりが外れている)か、分析方針の仮説が的を射ていない(つまり、データ分析の実力不足)かのどちらかです。
前者の場合は、実質、データが無かった場合と同じ状況ということです。
後者の場合、データについて詳しい方や、分析の知識に長けている方に相談して、プロセス回しを何度か再挑戦してみて、それでも兆しが見えてこないようであれば、諦めて別の目的に舵を切るべきかと思います。
何度挑戦するかは、仕事観やポリシーの話になるかと思います。
最後に
という訳で、今回はデータ分析の序盤プロセス「目的の設定」「目標の設定」「データの選定」について話をさせていただきました。
データ分析に成功の花を咲かす種植え作業といえるプロセスです。
序盤プロセスを気合入れて行っておくと、中盤・後半のプロセスでの成功率も高くなるかと思います。
ここまで読んでくださった方、ありがとうございました。m(_ _)m