1 はじめに
本稿では線形変換の観点から眺めた主成分分析を解説し、主成分得点と主成分負荷量がどのような意味を持つのか、そしてそれらの関係がどのように導かれるのかを考察する。
なお、本稿の記事は「統計学実践ワークブック」の23章「主成分分析」の内容に基づき、著者が考察を行った結果をまとめたものである。
2 主成分の意味
主成分とは、データ $\boldsymbol{x}$ を固有ベクトル $\boldsymbol{u}_{j}$(方向の直線) に降ろした足、すなわち新基底 $\boldsymbol{u}_{j}$ から見た特徴量のことで、$j$ 番目の固有値 $\lambda_{j}$ に対応する固有ベクトル $\boldsymbol{u}_{j} (\in \mathbb{R}^{p})$ と$p$個の特徴量からなる元の変数 $\boldsymbol{x} = \left( x_{1}, \cdots ,x_{p} \right)^T$ との内積を変数 $y_{j}$ で表し、第 $j$ 主成分 (principal component) という。
y_{j} = \langle \boldsymbol{x}, \boldsymbol{u}_{j} \rangle
= x_{1} u_{1,j} + \cdots x_{p} u_{p,j}
\quad・・・\quad(1)
Fig.1 に示すように、データ $\boldsymbol{x}$ は、特徴量空間の一点で表される。特徴量空間の各座標軸は、データを特徴づける $p$ 個の特徴量(特徴量$1$~特徴量$p$)の値を示す座標軸である。たとえば、データ $\boldsymbol{x}$ を学生、特徴量を国語 ($x_1$) 、数学 ($x_2$) 、理科 ($x_3$) 、社会($x_4$) の点数とする(学生を各教科の点数で特徴づけた訳である)と、特徴量空間の各座標軸はそれぞれ国語、数学、理科、社会(の点数)である。
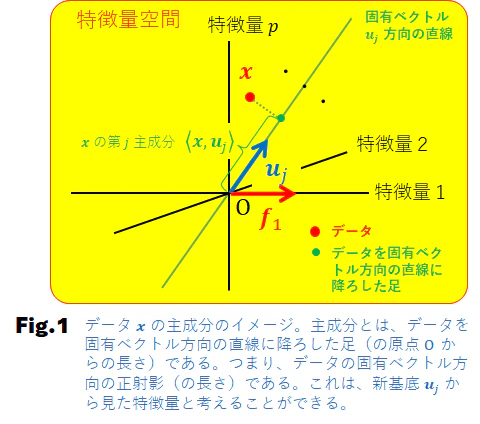
$\boldsymbol{u}_{j} (j=1, \cdots, p)$ を $j$ 番目の固有ベクトル(固有ベクトルは、中心化された元データ行列 $X_C$ から作られる共分散行列 $S$ を固有値分解することで得られる)とすると、 $\boldsymbol{u}_{j}$ 方向の直線に、データ $\boldsymbol{x}$ から降ろした足(Fig.1 の緑色の点)の原点 $O$ からの距離(長さ)を主成分(正確には第 $j$ 主成分)という。図から分かるように、主成分はデータ $\boldsymbol{x}$ を固有ベクトル(方向の直線)に正射影したものである。
特徴量空間の各座標軸方向に単位ベクトルをとり、それらを $\boldsymbol{f}_{1}, \cdots, \boldsymbol{f}_{p}$ とする。つまり、 $\boldsymbol{f}_{1}$ は特徴量$1$方向にとった単位ベクトル、 $\boldsymbol{f}_{2}$ は特徴量$2$方向にとった単位ベクトル、・・・である。これら $\boldsymbol{f}_{1}, \cdots, \boldsymbol{f}_{p}$ を基底ベクトル(あるいは単に基底)と呼ぶ。各基底ベクトルは、各特徴量の方向を表しており、データ $\boldsymbol{x}$ と $j$ 番目の基底 $\boldsymbol{f}_{j}$ の内積 $\langle \boldsymbol{x}, \boldsymbol{f}_{j} \rangle$ はデータの $j$ 番目の特徴量を表している。
いま、特徴量空間の基底を $\boldsymbol{f}_{1}, \cdots, \boldsymbol{f}_{p}$ から、共分散行列 $S$ の固有ベクトル $\boldsymbol{u}_{1}, \cdots, \boldsymbol{u}_{p}$ に変更することを考えてみよう(基底変換)。そうすると、データ $\boldsymbol{x}$ はどのように見えるだろうか。基底を変えても $\boldsymbol{x}$ は $\boldsymbol{x}$ なので、向きも長さも変わらない。しかし、データ $\boldsymbol{x}$ の成分表示(特徴量の値)は変わる。なぜなら、基底が $\boldsymbol{f}_{1}, \cdots, \boldsymbol{f}_{p}$ の場合はデータ $\boldsymbol{x}$ の第 $j$ 成分は、データ $\boldsymbol{x}$ と第 $j$ 基底 $\boldsymbol{f}_{j}$ の内積 $\langle \boldsymbol{x}, \boldsymbol{f}_{j} \rangle$ であったものが、基底が $\boldsymbol{u}_{1}, \cdots, \boldsymbol{u}_{p}$ になると、データ $\boldsymbol{x}$ の第 $j$ 成分は、データ $\boldsymbol{x}$ と変更後の第 $j$ 基底 $\boldsymbol{u}_{j}$ の内積 $\langle \boldsymbol{x}, \boldsymbol{u}_{j} \rangle$ に変わるからである。このように考えると、主成分は変換後の新しい基底からデータを眺めているという描像が描けるだろう。なお、新しい基底は旧基底の合成になっていることに注意したい。旧基底は、たとえば国語が第1基底、数学が第2基底、・・・といった具合に特徴量が明確であったが、新基底は、たとえば第1基底である $\boldsymbol{u}_{1}$ は国語が20%、数学が40%、・・・などと、旧基底が混ざり合っている。
3 主成分得点
データ行列 $X$ の第 $i$ 行ベクトル $\boldsymbol{x}_{i} = \left( x_{i,1}, \cdots, x_{i,p} \right)^{T}$ を前頁の(1)式に代入した
y_{i,j} = \langle \boldsymbol{x}_{i}, \boldsymbol{u}_{j} \rangle
= x_{i,1} u_{1,j} + \cdots x_{i,p} u_{p,j}
\quad・・・\quad(2)
を、($i$ 番目のデータ $\boldsymbol{x}_{i}$ の $j$ 番目の特徴量に対する)主成分得点 ( principal component score ) という。

3.1 主成分得点の意味
主成分得点は、前頁で説明した主成分を具体的な観測データに対して求めた値である。前頁の(1)式を
y_{j} = g(\boldsymbol{x}) = \langle \boldsymbol{x}, \boldsymbol{u}_{j} \rangle
\quad・・・\quad(3)
と関数表記した場合、関数の引数である $\boldsymbol{x}$ に具体的なデータ(例えば $i$ 番目のデータ $\boldsymbol{x}_{i}$ )を代入したものが(データ $\boldsymbol{x}_{i}$ の)主成分得点である。(2)式で $y$ の添え字が $i, j$ となっているのは、$i$ 番目のデータの特徴量 $j$ に対する主成分得点を意味する。
全データ $\boldsymbol{x}_{1}, \cdots, \boldsymbol{x}_{n}$ に対する特徴量 $j$ の主成分得点を並べたベクトルを $\boldsymbol{y}_{j}$ とおく。すなわち
\boldsymbol{y}_{j} = \left( y_{1,j}, \cdots, y_{n,j} \right)^{T}
= \left(
\langle \boldsymbol{x}_{1}, \boldsymbol{u}_{j} \rangle, \cdots,
\langle \boldsymbol{x}_{n}, \boldsymbol{u}_{j} \rangle
\right)^{T}
=X_{C} \boldsymbol{u}_{j}
\quad・・・\quad(4)
ここで、 $X_C$ は中心化されたデータ行列である(Fig.3)。
X_C = \left[ \boldsymbol{x}_{1} \cdots \boldsymbol{x}_{n} \right]^{T}
= \left[ \boldsymbol{\breve{x}}_{1} \cdots \boldsymbol{\breve{x}}_{p}
\right]
\quad・・・\quad(5)

4 線形変換から見た主成分分析
(4)式は、$\boldsymbol{u}_{j}$ から $\boldsymbol{y}_{j}$ への線形変換とみなせる。ここで、線形変換に対応する行列は $X_C$ である(Fig.4参照)。

共分散行列 $S$ は、中心化された元データ $X_C$ を使って次式のようにあらわされる。
S = \frac{1}{n-1} X_{C}^{T} X_{C}
\quad・・・\quad(6)
$S$ の $j$ 番目の固有値を $\lambda_{j}$、 対応する固有ベクトルを $\boldsymbol{u}_{j}$ とすると、
S \boldsymbol{u}_{j} = \lambda_{j} \boldsymbol{u}_{j}
\quad・・・\quad(7)
となるが、(6)式と(4)式を用いると次のように変形できる。
\begin{equation}
\begin{split}
\lambda_{j} \boldsymbol{u}_{j}
&=
S \boldsymbol{u}_{j}
=
\left( \frac{1}{n-1} X_{C}^{T} X_{C} \right) \boldsymbol{u}_{j} \\
&=
\frac{1}{n-1} X_{C}^{T} \left( X_{C} \boldsymbol{u}_{j} \right)
=
\frac{1}{n-1} X_{C}^{T} \boldsymbol{y}_{j}
\quad・・・\quad(8)
\end{split}
\end{equation}
Fig.4a は(4)式を図示したもので、Fig.4b は(4)式を $\boldsymbol{u}_{j}$ から $\boldsymbol{y}_{j}$ への線形変換とみなして、特徴量空間上の固有ベクトル $\boldsymbol{u}_{j}$ をデータ空間上の主成分得点ベクトル $\boldsymbol{y}_{j}$ に写像している様子を描いたものである。そして、この線形変換に対応する行列はデータ行列 $X_C$ である。
Fig.5a は(8)式を図示したもので、Fig.5b は(8)式を $\boldsymbol{y}_{j}$ から $\lambda_{j} \boldsymbol{u}_{j}$ への線形変換とみなして、データ空間上の主成分得点ベクトル $\boldsymbol{y}_{j}$ を、特徴量空間上の固有ベクトル $\boldsymbol{u}_{j}$ を(対応する固有値である)$\lambda_{j}$ 倍したベクトル $\lambda_{j} \boldsymbol{u}_{j}$ に写像している様子を描いたものである。そして、この線形変換に対応する行列はデータ行列 $X_C$ を転置したものを $n−1$ で割った $\frac{1}{n-1}X_{C}^{T}$ である。


5 主成分負荷量
元の変数(と言ってもデータベクトル $\boldsymbol{x}_{i} = \left( x_{i,1}, \cdots, x_{i,p} \right)^{T} \in \mathbb{R}^{𝑝} \quad (i=1, \cdots, 𝑛)$ ではなく、特徴量ベクトル $\boldsymbol{\breve{x}}_{k} = \left( x_{1,k}, \cdots, x_{n,k} \right)^{T} \in \mathbb{R}^{n} \quad (k=1, \cdots, p)$ であるが)と第 $j$ 主成分 $\boldsymbol{y}_{j}$ との相関係数($r_{y_{j},x_{k}}$)を主成分負荷量( principal component loading )という。
この主成分負荷量を求めるには、(8)式を使う。
$X_{C}^{T} = \left[ \boldsymbol{x}_{1} \cdots \boldsymbol{x}_{n} \right]$ を(8)式の最後の項に代入すると
\begin{equation}
\begin{split}
\lambda_{j} \boldsymbol{u}_{j}
&=
\frac{1}{n-1} X_{C}^{T} \boldsymbol{y}_{j}
=
\frac{1}{n-1}
\left[ \boldsymbol{x}_{1} \cdots \boldsymbol{x}_{n} \right]
\boldsymbol{y}_{j} \\
&=
\frac{1}{n-1}
\begin{pmatrix}
x_{1,1} & \cdots & x_{n,1} \\
\vdots & \ddots & \vdots \\
x_{1,p} & \cdots & x_{n,p} \\
\end{pmatrix}
\begin{pmatrix}
y_{1,j} \\
\vdots \\
y_{n,j} \\
\end{pmatrix}
=
\frac{1}{n-1}
\begin{pmatrix}
\sum_{i=1}^{n} x_{i,1} y_{i,j} \\
\vdots \\
\sum_{i=1}^{n} x_{i,p} y_{i,j} \\
\end{pmatrix} \\
&=
\frac{1}{n-1}
\begin{pmatrix}
\langle \boldsymbol{\breve{x}}_{1}, \boldsymbol{y}_{j} \rangle \\
\vdots \\
\langle \boldsymbol{\breve{x}}_{p}, \boldsymbol{y}_{j} \rangle \\
\end{pmatrix}
=
\frac{1}{n-1}
\begin{pmatrix}
Cov \left[ \breve{x}_{1}, y_{j} \right] \\
\vdots \\
Cov \left[ \breve{x}_{p}, y_{j} \right] \\
\end{pmatrix}
\quad・・・\quad(9)
\end{split}
\end{equation}
となる。(9)式の第 $k$ 行に注目すると
\lambda_{j} u_{k,j} = Cov \left[ \breve{x}_{k}, y_{j} \right]
\quad・・・\quad(10)
となる。したがって、特徴量ベクトル $\boldsymbol{\breve{x}}_{k}$ と(第 $j$ )主成分 $\boldsymbol{y}_{j}$ の相関係数は
r_{y_{j},x_{k}}
=
\frac{Cov \left[ \breve{x}_{k}, y_{j} \right]}
{\sqrt{V \left[ \breve{x}_{k} \right] V \left[ y_{j} \right] }}
\quad・・・\quad(11)
となるが、
V \left[ \breve{x}_{k} \right]
=
\frac{1}{n-1} \boldsymbol{\breve{x}}_{k}^{T} \boldsymbol{\breve{x}}_{k} = s_{k,k}
\begin{equation}
\begin{split}
V \left[ y_{j} \right]
&=
\frac{1}{n-1} \boldsymbol{y}_{j}^{T} \boldsymbol{y}_{j}
=
\frac{1}{n-1} \left( X_{C} \boldsymbol{u}_{j} \right)^{T} X_{C} \boldsymbol{u}_{j}
=
\frac{1}{n-1} \boldsymbol{u}_{j}^{T} X_{C}^{T} X_{C} \boldsymbol{u}_{j} \\
&=
\boldsymbol{u}_{j}^{T} \left( \frac{1}{n-1} X_{C}^{T} X_{C} \right) \boldsymbol{u}_{j}
=
\boldsymbol{u}_{j}^{T} S \boldsymbol{u}_{j}
=
\boldsymbol{u}_{j}^{T} \lambda_{j} \boldsymbol{u}_{j}
=
\lambda_{j} \boldsymbol{u}_{j}^{T} \boldsymbol{u}_{j} \\
&= \lambda_{j}
\end{split}
\end{equation}
なので、これらと(10)式を(11)式に代入すると主成分負荷量(特徴量ベクトル $\boldsymbol{\breve{x}}_{k}$ と第 $j$ 主成分 $\boldsymbol{y}_{j}$ の相関係数)は次のようになる。
r_{y_{j},x_{k}}
=
\frac{Cov \left[ \breve{x}_{k}, y_{j} \right]} {\sqrt{s_{k,k} \lambda_{j} }}
=
\frac{\lambda_{j} u_{k,j}} {\sqrt{s_{k,k} \lambda_{j} }}
=
\frac{\sqrt{ \lambda_{j} } u_{k,j}} {\sqrt{s_{k,k}}}
\quad・・・\quad(12)
5.1 主成分負荷量の意味
主成分負荷量の意味を考察する。主成分負荷量は、特徴量ベクトル $\boldsymbol{\breve{x}}_{k}$ と第 $j$ 主成分 $\boldsymbol{y}_{j}$ の相関係数であった。
特徴量ベクトル $\boldsymbol{\breve{x}}_{k}$ はデータ行列 $X_{C}$ の第 $k$ 列の列ベクトルで、その成分表示は
\boldsymbol{\breve{x}}_{k}
=
\left(
x_{1,k}, \cdots, x_{n,k}
\right)^{T}
である(Fig.6 参照)。


これは、Fig.1 に示す特徴量空間の $k$ 番目の基底(座標軸方向の単位ベクトル)$\boldsymbol{f}_{k} = \left( 0,\cdots,1,\cdots, 0 \right)^{T}$ をデータ行列 $X_{C}$ の右から掛けることによって取り出すことができる。すなわち
\boldsymbol{\breve{x}}_{k}
=
X_{C} \boldsymbol{f}_{k}
\quad・・・\quad(13)
一方、第 $j$ 主成分 $\boldsymbol{y}_{j}$ は全データ $\boldsymbol{x}_{1},\cdots,\boldsymbol{x}_{n}$ の特徴量 $j$ の主成分得点を並べたベクトルで、(4)式で与えられる。
(13)式と(4)式を線形変換の観点から眺めると、特徴量ベクトル $\boldsymbol{\breve{x}}_{k}$ は、特徴量空間の $k$ 番目の基底 $\boldsymbol{f}_{k}$ を行列 $X_{C}$ で線形変換した写像で、第 $j$ 主成分 $\boldsymbol{y}_{j}$ は、特徴量空間上の $j$ 番目の固有ベクトル $\boldsymbol{u}_{j}$ を行列 $X_{C}$ で線形変換した写像であることがわかる。
すなわち、主成分負荷量(特徴量ベクトル $\boldsymbol{\breve{x}}_{k}$ と第 $j$ 主成分 $\boldsymbol{y}_{j}$ の相関係数)は、新旧基底間の相関($u_{k,j}$)をデータ空間に写像して眺めたものという描像を描くことができる(Fig.7)

6 まとめ
6.1 固有ベクトルと主成分ベクトルの関係
$\boldsymbol{u}_{j}$ と $\boldsymbol{y}_{j}$ は座標変換を通して出会う。

6.2 共分散行列は Self-Attention に似ている

データ行列 $X_C$ の列ベクトル $\boldsymbol{\breve{x}}_{k}$ は、特徴量 $k$ の埋め込みベクトルとみなせる。$\boldsymbol{\breve{x}}_{k}$ と $\boldsymbol{\breve{x}}_{j}$ の内積は特徴量 $k$ と特徴量 $j$ の類似度を表している。したがって、共分散行列 $S$ の $k$ 行 $j$ 列の成分 $s_{k,j}$ は、Transformer の Attention 機構の類推から特徴量ベクトルの Self-Attention 重みとみなすことができる。
共分散行列 $S$ の第 $k$ 行ベクトルを $\boldsymbol{s}_{k} = \left( s_{k,1}, \cdots, s_{k,p} \right)^{T}$ とおくと、特徴量ベクトルの加重平均
s_{k,1} \boldsymbol{\breve{x}}_{1} + \cdots + s_{k,p} \boldsymbol{\breve{x}}_{p}
=
\sum_{j=1}^{p} s_{k,j} \boldsymbol{\breve{x}}_{j}
=
\boldsymbol{s}_{k}^{T} X_{C}^{T}
=
\left( X_{C} \boldsymbol{s}_{k} \right)^{T}
は、Transformer の類推から他の特徴量との関連を反映した「潜在空間」における $k$ 番目の特徴量を表しているものと考えられる。ただし、主成分分析の場合、これが何を意味しているのか、今のところわからない。
これについてさらに深く知りたい人は「主成分分析と自己注意機構」をご覧いただきたい。
6.3 主成分得点ベクトルは観測データを固有ベクトル方向に射影して得られる
主成分得点ベクトル
\boldsymbol{y}_{j} =
\begin{pmatrix}
\boldsymbol{x}_{1}^{T} \boldsymbol{u}_{j} \\
\vdots \\
\boldsymbol{x}_{n}^{T} \boldsymbol{u}_{j} \\
\end{pmatrix}
=
\begin{pmatrix}
\boldsymbol{x}_{1}^{T} \\
\vdots \\
\boldsymbol{x}_{n}^{T} \\
\end{pmatrix}
\boldsymbol{u}_{j}
=
X_{C} \boldsymbol{u}_{j}
\quad・・・\quad(15)


6.4 主成分負荷量は新旧基底間からみた特徴量ベクトルの相関だった
主成分負荷量
r_{y_{j},x_{k}}
=
\frac{Cov \left[ \breve{x}_{k}, y_{j} \right]} {\sqrt{s_{k,k} \lambda_{j} }}
=
\frac{\lambda_{j} u_{k,j}} {\sqrt{s_{k,k} \lambda_{j} }}
=
\frac{\sqrt{ \lambda_{j} } u_{k,j}} {\sqrt{s_{k,k}}}
\quad・・・\quad(12)
【この観点からの主成分負荷量の導出】(別解)
\boldsymbol{y}_{j} = X_{C} \boldsymbol{u}_{j}
\quad・・・\quad(16)
\boldsymbol{\breve{x}}_{k} = X_{C} \boldsymbol{f}_{k}
\quad・・・\quad(17)
これらを使うと、 $k$ 番目の特徴量ベクトル $\boldsymbol{\breve{x}}_{k}$ と第 $j$ 主成分得点ベクトル $\boldsymbol{y}_{j}$ の内積は次のように計算できる。
\begin{equation}
\begin{split}
\boldsymbol{\breve{x}}_{k}^{T} \boldsymbol{y}_{j}
&= \left( X_{C} \boldsymbol{f}_{k} \right)^{T} X_{C} \boldsymbol{u}_{j}
= \boldsymbol{f}_{k}^{T} X_{C}^{T} X_{C} \boldsymbol{u}_{j}
= \boldsymbol{f}_{k}^{T} (n-1) S \boldsymbol{u}_{j} \\
&= (n-1) \boldsymbol{f}_{k}^{T} \lambda_{j} \boldsymbol{u}_{j}
= (n-1) \lambda_{j} \boldsymbol{f}_{k}^{T} \boldsymbol{u}_{j}
= (n-1) \lambda_{j} u_{k,j}
\quad・・・\quad(18)
\end{split}
\end{equation}
ここで、(6)式と(7)式を使った。
(18)式を使うと
Cov \left[ \breve{x}_{k}, y_{j} \right]
=
\frac{1}{n-1}
\boldsymbol{\breve{x}}_{k}^{T} \boldsymbol{y}_{j}
=
\frac{1}{n-1} (n-1) \lambda_{j} u_{k,j}
=\lambda_{j} u_{k,j}
となり、(12)式の2項目から3項目の導出ができた。

8 おわりに
主成分分析を線形変換からの観点から考察を行い、主成分得点や主成分負荷量の意味を考え、それらの関係を導いた。
参考文献
- 日本統計学会 (編集):日本統計学会公式認定 統計検定準1級対応 統計学実践ワークブック. 学術図書出版社, 2020.