はじめに
Python初心者が一通りデータ分析のコーディングをしてみることを目標にこちらのブログを書いています。
Aidemyは自身のキャリアチェンジのためにIT系のスキルを身につけたいと考え、受講を決めました。データ分析講座を受講しているのはゼロからものを作るよりも、なぜこの事象が起きたのか、ということを考えるほうが好きなためです。
正直まだまだわからないことの方が多く躓きそうな場面もありますが、ひとまず学んだことをアウトプットする第一歩としてこのブログを書いています。
※このブログはAidemy Premiumのカリキュラムの一環で、受講修了条件を満たすために公開しています
本記事の概要
想定読者:Pythonでのデータ分析初学者で、とりあえずデータ分析をやってみたい方。
この記事に書くこと、わかること:自転車屋の顧客予測を行います。具体的にはこちらのデータセットを使用し、顧客数予測の回帰モデルを実装します。
作成したプログラム
今回のテーマ
今回のブログでは自転車屋の顧客予測を行いました。
現在小売業に従事しており、顧客数は商品発注や作成のために参考にしたい数値です。まずは簡単な分析からスタートして実務に少しでも役立てばと思いこのテーマを選定しました。
またAidemyの教材に加えて以下の書籍を参考にしています。
Pythonで儲かるAIをつくるー赤石雅典 著
実行環境
Google Colab
Python 3.10.12
事前準備
必要なライブラリをインストールしておきます。
また、matplotlibで日本語表記できるように日本語化もあわせて行います。
# ライブラリのインストール
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# matplotlibの日本語化
!pip install japanize-matplotlib | tail -n 1
import japanize_matplotlib
データ読み込み
まずはデータを読み込みます。今回はUCI Machine Learning RepositoryのBike Sharingデータセットを用いています。
上記のリンクからデータセットをローカル環境(Google Drive)にダウンロードしました。
Google Driveに保存されているファイルをGoogle Colabで扱うためには以下のコードを書いてアクセス権を付与してもらいます。
# データ読み込み
# ドライブへのマウント
from google.colab import drive
drive.mount('/content/drive')
# ドライブからファイルを読み込む
df = pd.read_csv('/content/drive/MyDrive/bike_sharing_day.csv')
実際のデータは以下の通り。
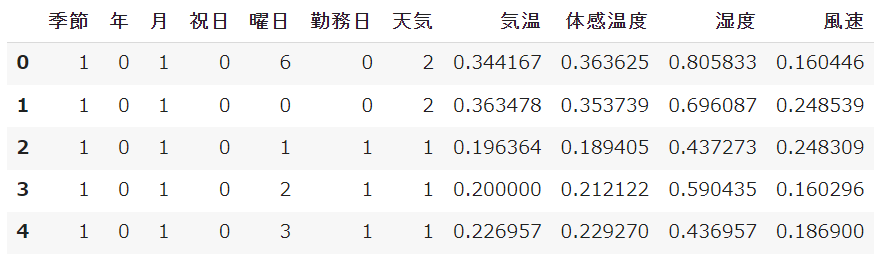
display(df.head())

この中でinstantは連番のデータで予測に不要のため削除します。また、列名を日本語にして理解しやすくしておきます。
# instant は連番。予測で不要なので削除
df = df.drop('instant', axis=1)
# 列名の日本語化
columns = [
'日付', '季節', '年', '月', '祝日', '曜日', '勤務日', '天気',
'気温', '体感温度', '湿度', '風速',
'臨時ユーザー利用数', '登録ユーザー利用数', '全体ユーザー利用数'
]
# 列名を日本語に置き換え
df.columns = columns
display(df.head())

instantが削除され、列名も日本語になっていることが確認できました。
データ確認と前処理
dfに格納されたデータがどんなものかを見ていきます。
# shape関数
print(df.shape)
結果
(731, 15)
# データ型の確認
df.dtypes
結果
日付 object
季節 int64
年 int64
月 int64
祝日 int64
曜日 int64
勤務日 int64
天気 int64
気温 float64
体感温度 float64
湿度 float64
風速 float64
臨時ユーザー利用数 int64
登録ユーザー利用数 int64
全体ユーザー利用数 int64
dtype: object
# 欠損値の確認
df.isnull().sum()
結果
日付 0
季節 0
年 0
月 0
祝日 0
曜日 0
勤務日 0
天気 0
気温 0
体感温度 0
湿度 0
風速 0
臨時ユーザー利用数 0
登録ユーザー利用数 0
全体ユーザー利用数 0
dtype: int64
欠損値はなく綺麗なデータであること、ほとんど数値データであることが見受けられました。ここから前処理はせずに分析作業へ進もうと思います。
データ分割
もともとのデータを目的変数・説明変数に分割したのち、さらに訓練データ・検証データに分割していきます。
# まずは説明変数を分割する
# 回帰の時に数値のみにしたいため、日付の情報も併せて落とす。
x_all = df.drop(['日付', '臨時ユーザー利用数', '登録ユーザー利用数', '全体ユーザー利用数'], axis=1)
説明変数はユーザー利用数と日付以外のすべてを説明変数とします。日付はデータ型がオブジェクト型となっているのでここで落としています。
x_all.shape
結果
(731, 11)
x_all.head()
無事に抜き出したい説明変数のみを抜き出すことができました。
# 目的変数への分割
y_all = pd.Series(data = df['全体ユーザー利用数'])
今回は全体ユーザー利用数を目的変数として設定します。
このデータセットにはバイクシェアリングのサービスに登録しているユーザーの貸出数(登録ユーザー利用数)と、登録していないユーザー(臨時ユーザー利用数)の貸出数と、それを合わせた貸出数が含まれています。今回は登録ユーザーと臨時ユーザーを合わせた数(全体ユーザー利用数)を予測していきます。
y_all.shape
結果
(731,)
y_all.head()
結果
985
801
1349
1562
1600
Name: 全体ユーザー利用数, dtype: int64
問題なく分割されたことがわかりました。
続いて訓練データと検証データに分割していきます。
今回はまずわかりやすい方法を採用することにしたのでホールドアウト法での分割を試みています。
ホールドアウト法は非常にシンプルな分割方法で、与えられたデータセットを2つに分割します。パラメータとしてtest_sizeは0.2、random_stateは42に設定しています。
# 訓練データと検証データの分割
# ホールドアウト法
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x_all, y_all, test_size = 0.2, random_state=42)
# 分割結果の確認(要素数)
print(x_train.shape)
print(x_test.shape)
print(y_train.shape)
print(y_test.shape)
結果
(584, 11)
(147, 11)
(584,)
(147,)
shape関数で確認すると、しっかり分割されているのがわかります。
アルゴリズムの選択
前述したとおり今回は全体ユーザー利用数を予測する回帰分析を行います。
初めに評価へ使うr2scoreをインストールしておきます。
# 回帰分析なので評価用のr2scoreを先にインストールしておく
from sklearn.metrics import r2_score
ここでは以下のアルゴリズムをそれぞれ実行し、一番評価の高いアルゴリズムを採用していきます。
線形回帰
まずはシンプルな線形回帰から行っていきます。
# シンプルな線形回帰
from sklearn.linear_model import LogisticRegression
alg_LR = LogisticRegression(random_state=42)
# 学習
alg_LR.fit(x_train, y_train)
# 予測
y_pred_LR = alg_LR.predict(x_test)
# 評価
score_LR = r2_score(y_test, y_pred_LR)
print(f'score: {score_LR:.04f}')
結果
score: 0.4124
スコアは0.4124とあまり高くない模様。x軸に正解データ、y軸に予測結果を設定した散布図も見ていきます。
#正解データと予測結果を散布図で比較
plt.figure(figsize=(6,6))
y_max = y_test.max()
plt.plot((0,y_max), (0, y_max), c='k')
plt.scatter(y_test, y_pred_LR, c='b')
plt.title(f'正解データと予測結果の散布図(全体ユーザー利用数)\
R2={score_LR:.4f}')
plt.grid()
plt.show()
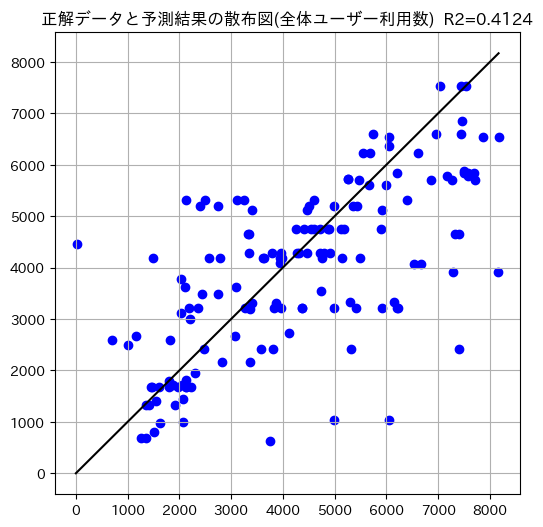
全体的に予測結果が散らばっており、あまり当てはまりがよくないことが見受けられます。
Lasso回帰
続いてLasso回帰を行います。
# ラッソ回帰
from sklearn.linear_model import Lasso
alg_lasso = Lasso(random_state=42)
# 学習
alg_lasso.fit(x_train, y_train)
# 予測
y_pred_lasso = alg_lasso.predict(x_test)
# 評価
score_lasso = r2_score(y_test, y_pred_lasso)
print(f'score: {score_lasso:.04f}')
結果
score: 0.8257
先ほどよりもスコアが上昇しました。散布図も見ていきます。なお、コードに関しては前述したものとほぼ同じですので割愛します。
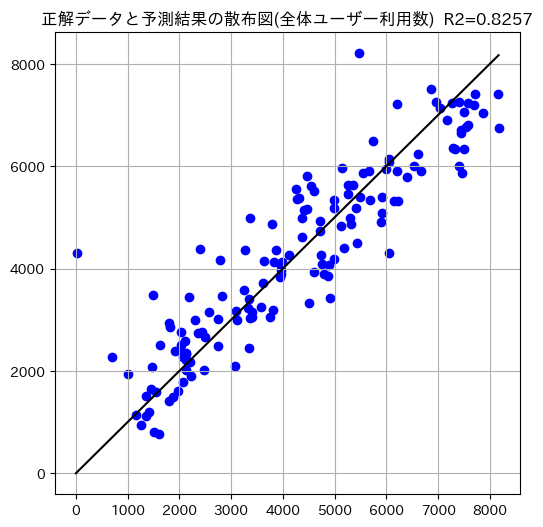
先ほどよりも精度があがっていることが見受けられます。
Ridge回帰
続いてRidge回帰です。
# リッジ回帰
from sklearn.linear_model import Ridge
alg_ridge = Ridge(random_state=42)
# 学習
alg_ridge.fit(x_train, y_train)
# 予測
y_pred_ridge = alg_ridge.predict(x_test)
# 評価
score_ridge = r2_score(y_test, y_pred_ridge)
print(f'score: {score_ridge:.04f}')
結果
score: 0.8230
Lasso回帰とほぼ変わらない精度で予測ができました。
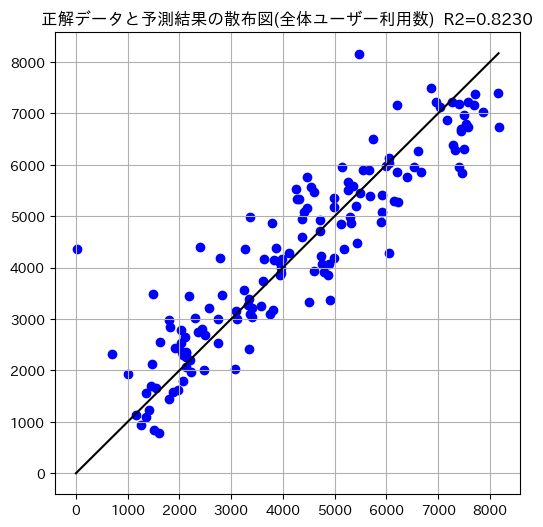
散布図からもおおむね同じような予測をできたことがみてとれます。
ElasticNet回帰
続いてElasticNet回帰。
# ElasticNet回帰
from sklearn.linear_model import ElasticNet
alg_EN = ElasticNet(random_state=42)
# 学習
alg_EN.fit(x_train, y_train)
# 予測
y_pred_EN = alg_EN.predict(x_test)
# 評価
score_EN = r2_score(y_test, y_pred_EN)
print(f'score: {score_EN:.04f}')
結果
score: 0.3940
スコアはぐっと下がり一番低い数値となってしまいました。
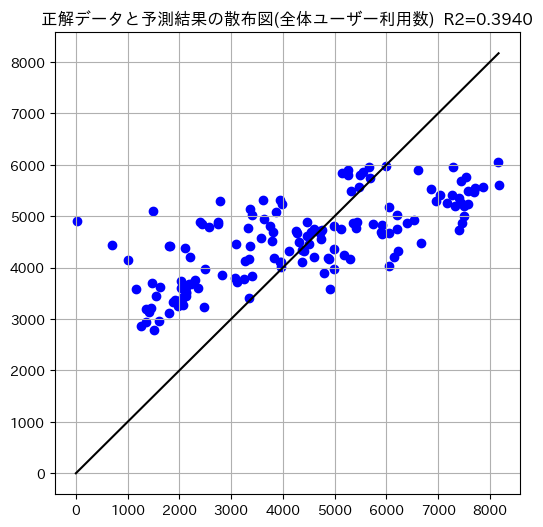
散布図を見るとわかる通り、ある一定の範囲に予測結果がとどまっており、精度が上がっていません。
LightGBM
最後にLightGBMを試します。Kaggleなどで多く使われている手法で比較的精度が高く予測できるそうです。
# LightGBMも試してみる
# ライブラリの読み込み
import lightgbm as lgb
# LightGBMで学習するためのデータ形式に変換
lgb_train = lgb.Dataset(data=x_train, label=y_train)
lgb_test = lgb.Dataset(data=x_test, label=y_test)
# ハイパーパラメータを定義
params = {
'objective':'regression', # 回帰であればregression
'verbosity': -1, # コマンドライン出力しない設定
'random_state': 42
}
# モデルの構築・学習
alg_lgb = lgb.train(params, lgb_train, valid_sets=[lgb_test])
# テストデータで予測
y_pred_lgb = alg_lgb.predict(x_test)
# 評価
score_lgb = r2_score(y_test, y_pred_lgb)
print(f'score: {score_lgb:.04f}')
結果
score: 0.8861
今までで一番高いスコアが出ました!
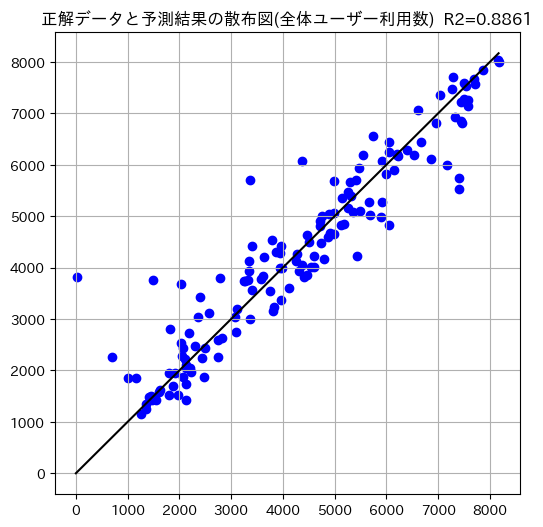
散布図も今までの中で最も直線に近い部分へ予測結果が集まっています。
ここまで5つのアルゴリズムを試してみた結果、LightGBM が一番当てはまりのいいアルゴリズムであることがわかりました。
以降では LightGBM のパラメータをチューニングすることでさらなる精度向上を目指します。
チューニング
LightGBMは多くのパラメータを持つため最大限の効果を出すためにパラメータチューニングが必要になります。
Aidemyの教材のほかに下記のリンクを参考に以下のコードを作成しました。
なお、前述のLightGBMはホールドアウト法で分割したデータを用いて検証しましたが、今回はK-Fold法での実装を行います。
まずは何もチューニングしない状態でモデルを構築していきます。
# データフレームの加工
df2 = df.copy()
df2 = df2.drop(['日付', '登録ユーザー利用数', '臨時ユーザー利用数'], axis=1)
データフレームを使えるように加工をしておきます。
# K-FoldによるLightGBMの実装
from sklearn.model_selection import KFold
cv = KFold(n_splits=10, random_state=42, shuffle=True)
verification = pd.DataFrame()
verification['y_test'] = df2['全体ユーザー利用数']
for train_idx, test_idx in cv.split(df2):
x_train = df2.iloc[train_idx, :-1]
y_train = df2.iloc[train_idx, -1]
x_test = df2.iloc[test_idx, :-1]
y_test = df2.iloc[train_idx, -1]
model = lgb.LGBMRegressor()
model.fit(x_train, y_train)
verification.loc[test_idx, 'y_pred'] = model.predict(x_test)
# 評価
score = r2_score(verification['y_test'], verification['y_pred'])
# 散布図の描画
plt.figure(figsize=(5,5))
plt.scatter(verification['y_test'], verification['y_pred'])
plt.title(f'予測結果 R2={score:.4f}')
plt.grid()
plt.show()
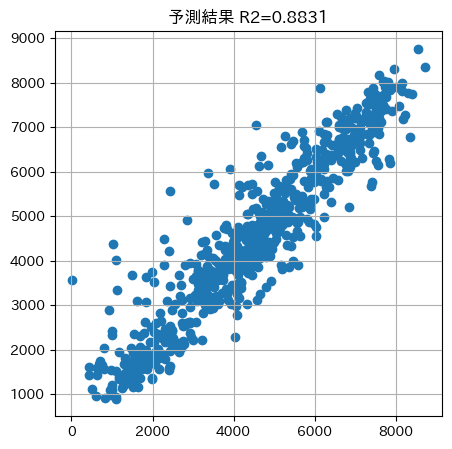
次にハイパーパラメータをチューニングしていきます。LightGBMはハイパーパラメータが多いため、Optunaを使用して最適化していきます。
以下のようなコードを前述した記事を参考にしながら記述しました。
import optuna
def objective(trial):
params = {
'reg_alpha': trial.suggest_float('reg_alpha', 1e-8, 10.0, log = True),
'reg_lambda': trial.suggest_float('reg_lambda', 1e-8, 10.0, log = True),
'num_leaves': trial.suggest_int('num_leaves', 2, 1000),
'colsample_bytree': trial.suggest_float('colsample _bytree', 1e-8, 1.0),
'subsample': trial.suggest_float('subsample', 1e-8, 1.0),
'subsample_freq': trial.suggest_int('subsample_freq', 1, 100),
'min_child_samples': trial.suggest_int('min_child_samples', 5, 1000)
}
from sklearn.model_selection import KFold
cv = KFold(n_splits = 10, random_state = 0, shuffle = True)
import lightgbm as lgb
verification = pd.DataFrame()
verification['y_test'] = df2['全体ユーザー利用数']
for train_idx, test_idx in cv.split(df2):
x_train = df2.iloc[train_idx, :-1]
y_train = df2.iloc[train_idx, -1]
x_test = df2.iloc[test_idx, :-1]
y_test = df2.iloc[train_idx, -1]
model = lgb.LGBMRegressor(**params)
model.fit(x_train, y_train)
verification.loc[test_idx, 'y_pred'] = model.predict(x_test)
return r2_score(verification['y_test'], verification['y_pred'])
sampler = optuna.samplers.TPESampler(seed=0)
study = optuna.create_study(sampler = sampler, direction='maximize')
study.optimize(objective, n_trials = 100)
print("best_value", study.best_value)
print("best_params", study.best_params)
結果
best_value 0.8908486301014537
best_params {'reg_alpha': 1.120428070522783e-06, 'reg_lambda': 0.20476301059620997, 'num_leaves': 555, 'colsample _bytree': 0.81912224402665, 'subsample': 0.9492393076870879, 'subsample_freq': 50, 'min_child_samples': 14}
無事に最適なパラメータを発見できました!
それでは先ほどのコードに最適なパラメータを入れて再度予測精度を確認します。
# パラメータ最適化で得られたハイパーパラメータを用いて再度予測精度を確認する
from sklearn.model_selection import KFold
cv = KFold(n_splits = 10, random_state = 42, shuffle = True)
import lightgbm as lgb
verification = pd.DataFrame()
verification['y_test'] = df2['全体ユーザー利用数']
for train_idx, test_idx in cv.split(df2):
X_train = df2.iloc[train_idx, :-1]
y_train = df2.iloc[train_idx, -1]
X_test = df2.iloc[test_idx, :-1]
y_test = df2.iloc[train_idx, -1]
model = lgb.LGBMRegressor(reg_alpha = 1.120428070522783e-06,
reg_lambda = 0.20476301059620997,
num_leaves = 555,
colsample_bytree = 0.81912224402665,
subsample = 0.9492393076870879,
subsample_freq = 50,
min_child_samples = 14
)
model.fit(X_train, y_train)
verification.loc[test_idx, 'y_pred'] = model.predict(X_test)
# 評価
score = r2_score(verification['y_test'], verification['y_pred'])
# 散布図の描画
plt.figure(figsize=(5,5))
plt.scatter(verification['y_test'], verification['y_pred'])
plt.title(f'予測結果 R2={score:.4f}')
plt.grid()
plt.show()
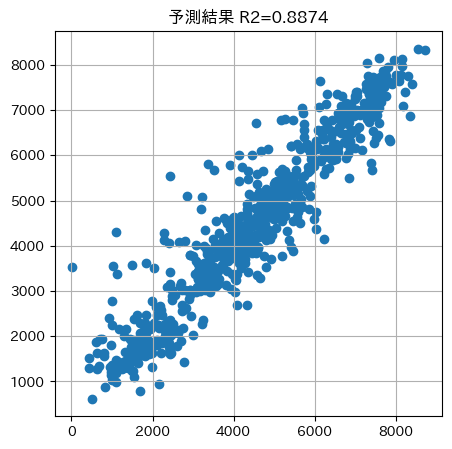
何もチューニングしない場合より少し精度が上がりました!ホールドアウト法でデータを分割した予測精度からもほんの少しですがあげることができました。
今後の活用
今回は自分が今できるアウトプットとしてこちらのブログを書いていきました。一つのデータセットでも様々な方法からデータ分析ができることを身をもって感じる時間でした。
探索の試行回数を増やしたり、特徴量エンジニアリングを行うなどさらに予測精度をあげられるのではないかと考えたため、さらにチューニングの技術をあげていきます。
おわりに
知識をインプットする段階ではなんとなくわかった気になっても、いざ自ら書こうと思うとどこから手をつけていいかわからず右往左往していました。無事に書き上げられて安心しています。
このブログを書き上げてようやくデータ分析の入口に立つことができた気がします。ただそれと同時に学ぶことの多さにも気づくことができました。まだまだ初心者ですが胸張ってデータ分析できる人材といえるように日々努力していきます。